大模型实战初-dify+大模型双本地(实验室服务器)部署
1.下载这里我选择的是1.7.02.解压3.安装3.1修改端口由于实验室服务器还有其他网站服务,而dify默认的web服务会占用80端口,所以在安装之前还需要修改配置,网上我看到一些教程提到是docker/.env文件,但事实上没有.env,而是有一个 .env.example文件,但根据后面安装的步骤来看.env.example会复制为.env的(建议直接将这个文件就改为.env),查看其中内容
一.dify部署
1.下载
Tags · langgenius/dify · GitHub
这里我选择的是1.7.0
2.解压


3.安装
3.1修改端口
由于实验室服务器还有其他网站服务,而dify默认的web服务会占用80端口,所以在安装之前还需要修改配置,网上我看到一些教程提到是docker/.env文件,但事实上没有.env,而是有一个 .env.example文件,但根据后面安装的步骤来看.env.example会复制为.env的(建议直接将这个文件就改为.env),查看其中内容有
...
...
# HTTP port Docker 容器内部 Nginx 监听的端口(默认80)
NGINX_PORT=80
# SSL settings are only applied when HTTPS_ENABLED is true 可选调整 HTTPS 端口
NGINX_SSL_PORT=443
...
...
# ------------------------------
# Docker Compose Service Expose Host Port Configurations 对外映射的 HTTP 端口
# ------------------------------
EXPOSE_NGINX_PORT=80
EXPOSE_NGINX_SSL_PORT=443
...
...
容器内外端口映射最好保持一致,防止混淆
我修改如下
NGINX_PORT=8005
NGINX_SSL_PORT=443
EXPOSE_NGINX_PORT=8005
EXPOSE_NGINX_SSL_PORT=443
没有修改SSL是因为emmm,他说了“ when HTTPS_ENABLED is true”但是NGINX_HTTPS_ENABLED=false,所以这个其实不用改因为不会生效的,当然如果你需要ssl服务的话,设置NGINX_HTTPS_ENABLED=true然后去修改端口就行了
3.2 开始安装
cd docker
cp .env.example .env
docker compose up -d结果是
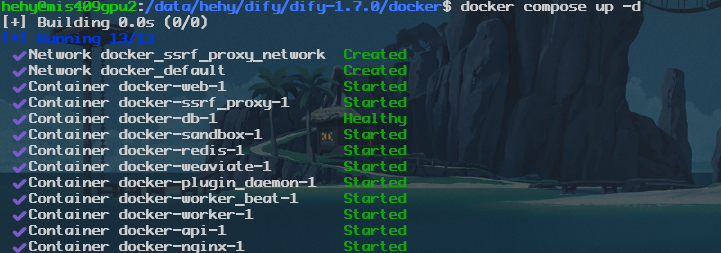
看一下端口
hehy@mis409gpu2:/data/hehy/dify/dify-1.7.0/docker$ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:1.7.0 "/bin/bash /entrypoi…" api About a minute ago Up 57 seconds 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db About a minute ago Up About a minute (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx About a minute ago Up 54 seconds 0.0.0.0:443->443/tcp, :::443->443/tcp, 80/tcp, 0.0.0.0:8005->8005/tcp, :::8005->8005/tcp
docker-plugin_daemon-1 langgenius/dify-plugin-daemon:0.2.0-local "/bin/bash -c /app/e…" plugin_daemon About a minute ago Up 59 seconds 0.0.0.0:5003->5003/tcp, :::5003->5003/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis About a minute ago Up About a minute (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.12 "/main" sandbox About a minute ago Up About a minute (healthy)
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy About a minute ago Up About a minute 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate About a minute ago Up About a minute
docker-web-1 langgenius/dify-web:1.7.0 "/bin/sh ./entrypoin…" web About a minute ago Up About a minute 3000/tcp
docker-worker-1 langgenius/dify-api:1.7.0 "/bin/bash /entrypoi…" worker About a minute ago Up 55 seconds 5001/tcp
docker-worker_beat-1 langgenius/dify-api:1.7.0 "/bin/bash /entrypoi…" worker_beat About a minute ago Up 56 seconds 5001/tcp可以发现容器都映射了不同的端口,但在之前我们仅仅开放了8005,这是因为8005提供dify的web访问。而其他端口例如插件-5003,api-5001等在服务器内部即可通信了,但是其实这些端口都应该做相应的修改(防止其他同学也部署会与你冲突,当然,只有一个人就什么都不用改啦)
同时我也搜索了一下api与插件的区别,
api:由前端或者第三方系统调用
是dify提供的一个后端服务,提供RESTful 接口,用于:
- 创建应用、工作流
- 管理用户、对话历史
- 触发 AI 推理(如聊天、生成内容)
- 获取知识库内容等
插件:由Dify 平台调用
- 插件是一种 扩展机制,允许 Dify 调用外部服务或执行特定功能。
- 比如:调用天气 API、查询数据库、执行支付、访问企业内部系统等。
- 插件可以是:
- 内置插件(Dify 自带)
- 自定义插件(你开发并注册)
- 远程插件(符合 OpenAPI / OpenAI Plugin 规范的服务)
二.大模型部署
运行和部署大语言模型(LLM)的开源工具有很多啊,比如简单一些的Ollama,稍微企业级一些的有vLLM,具体用哪种看情况,这里我决定挑战难度稍大的vLLM。
1.大模型文件下载
大模型文件动辄就是10个g,但是偏偏vllm所提供的huggingface是外网下载的,很慢,所以用国内镜像,这里推荐
打开往下翻有他的应用教程

三种方法,第一种网页下载,emmm,我觉得很慢,非常慢,第二种huggingface-cli,我也失败了,总说huggingface-cli: command not found,最后用第三种,我觉得还是蛮快的
我这里下载的时官方模型,在后续vllm启动时有一个参数quantization ,只有当你下载的是量化模型才能加这个参数,否则就别加
2.vLLM容器部署
这部分可以参考官方教程或者问大D老师
首先下载镜像,vllm/vllm-openai:latest,直接pull,不行了下载到本地然后迁到服务器
然后运行容器(说实话不如直接问大D老师的)
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model mistralai/Mistral-7B-v0.1简单解释,-v做卷映射,model指定了vllm运行哪个大模型,有人会问vllm是集成了一些大模型,然后这里就可以直接名字指定了嘛,其实不是,他是卷映射了一个文件夹huggingface,你运行这个命令时他会检索huggingface下面有没有你要的模型,没有的话他就从huggingface网站下载,哇,这太慢了,还要科学上网,所以我问大D老师能不能指定一个路径是我下载的模型,能的兄弟能的
docker run -d --gpus all \
-p 8000:8000 \
-v /data/hehy/llm:/llm \
vllm/vllm-openai:latest \
--model /llm/Qwen3-32B \
--quantization awq \ #量化模型专用
--tensor-parallel-size 1 \
--max-model-len 1024 \
--trust-remote-code三.dify接入大模型
1.设置 > 模型供应商 >vllm

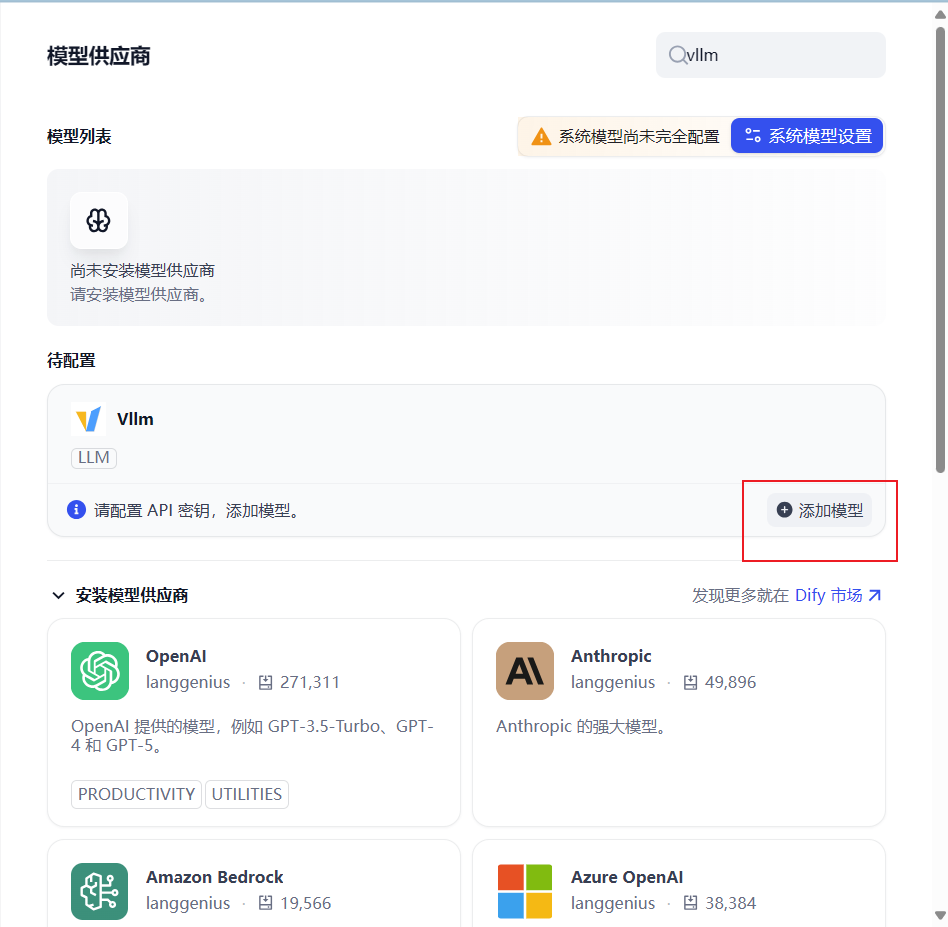
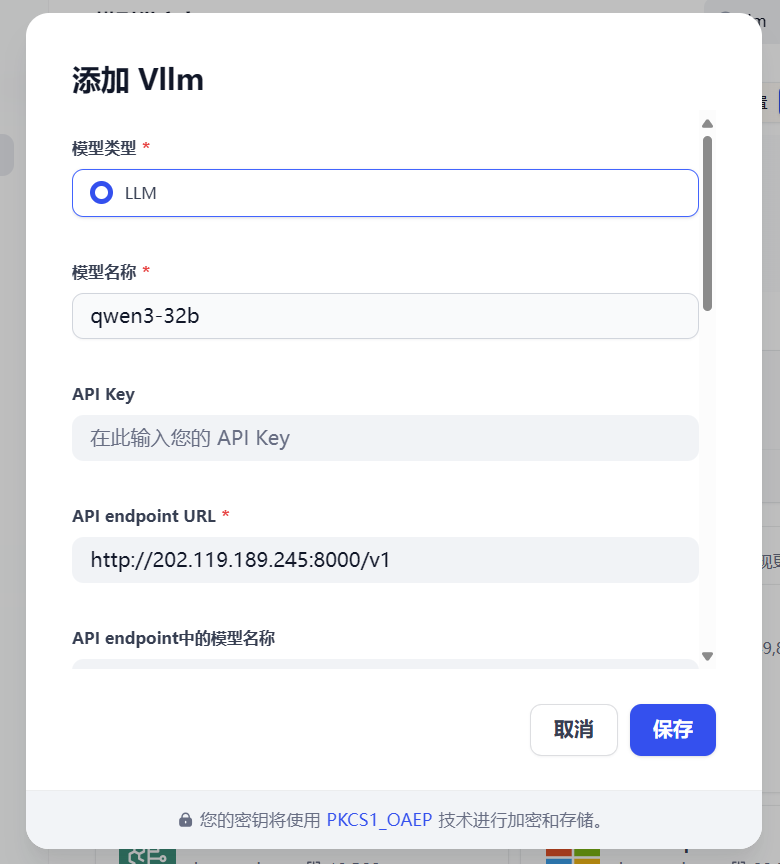
注意这里的名称不是随便填的,网上有些说是“vLLM启动时候带的大模型地址,或vLLM指定的大模型名称”之类的,我是感觉表达的不清楚,建议按以下方法做
在dify服务器上curl -v http://<大模型服务器ip>:<端口>/v1/models
得到类似以下数据
把id填进去就好了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)