大模型性能指标的监控系统(prometheus3.5.0)和可视化工具(grafana12.1.0)基础篇
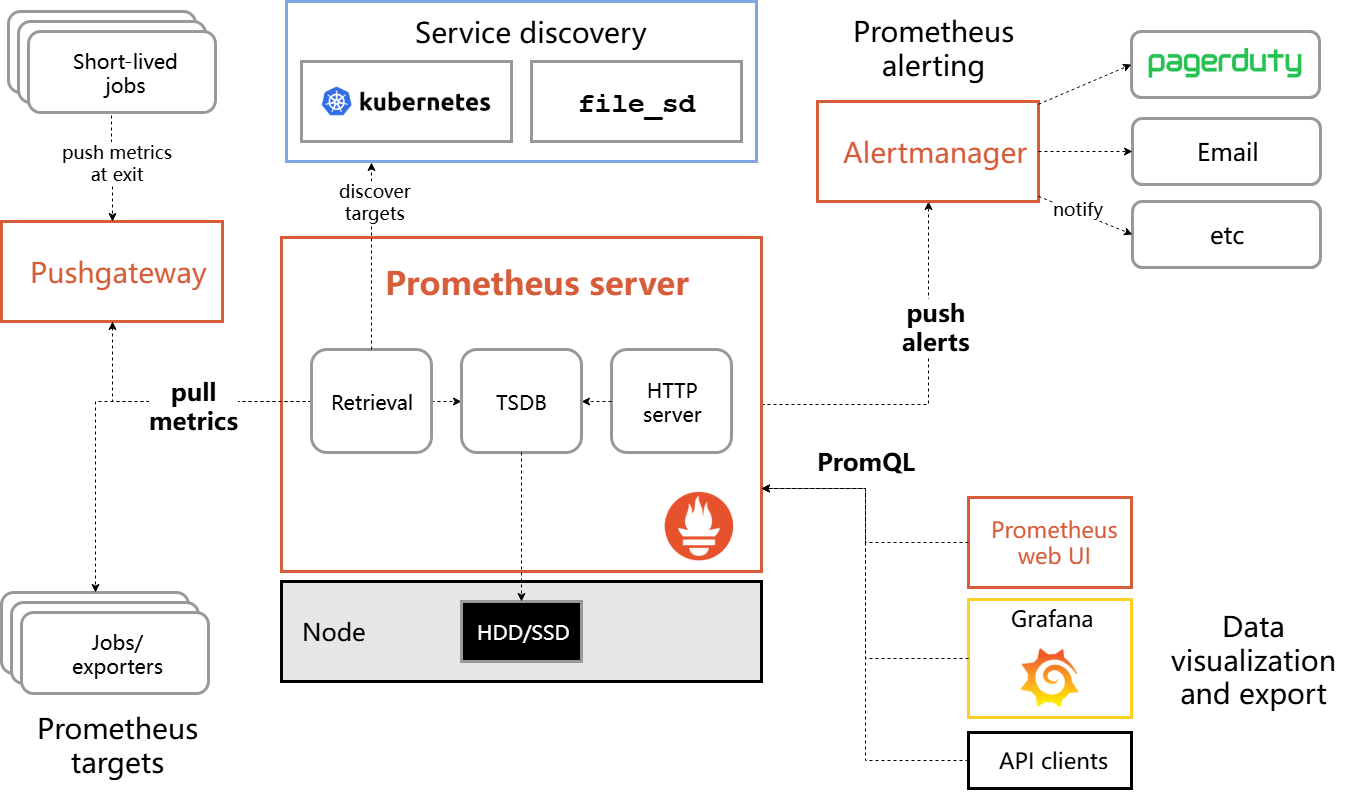
Prometheus是云原生计算基金会项目,是一个系统和服务监控系统。它以给定的时间间隔从配置的目标收集指标,评估规则表达式,显示结果,并在观察到指定条件时触发警报。Prometheus与其他指标和监控系统的区别在于:多维数据模型(由度量名称和键/值维度集定义的时间序列)PromQL,一种强大而灵活的查询语言不依赖分布式存储;单个服务器节点是自主的用于时间序列收集的HTTP拉取模型通过中间网关支持
一、什么是prometheus
Prometheus是云原生计算基金会项目,是一个系统和服务监控系统。它以给定的时间间隔从配置的目标收集指标,评估规则表达式,显示结果,并在观察到指定条件时触发警报。
Prometheus与其他指标和监控系统的区别在于:
- 多维数据模型(由度量名称和键/值维度集定义的时间序列)
- PromQL,一种强大而灵活的查询语言
- 不依赖分布式存储;单个服务器节点是自主的
- 用于时间序列收集的HTTP拉取模型
- 通过中间网关支持推送时间序列,用于批处理作业
- 通过服务发现或静态配置发现目标
- 多种绘图和仪表板支持模式
- 支持分层和横向联盟
二、部署prometheus
2.1下载:
docker pull prom/prometheus:latest
2.2运行
# 宿主机创建目录
mkdir -p /mnt/data/app/prometheus/data
# 授予读写权限
chmod -R 777 /mnt/data/app/prometheus/data
#运行容器
docker run --name prometheus -dit -p 9090:9090 \
--ulimit stack=-1:-1 --ulimit memlock=-1:-1 --privileged --cap-add=ALL --security-opt seccomp=unconfined -e TZ=Asia/Shanghai \
-v /etc/localtime:/etc/localtime:ro \
-v /etc/timezone:/etc/timezone:ro \
-v /mnt/data/app/prometheus/data:/prometheus \
-v /mnt/data/app/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus:latest \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus \
--storage.tsdb.retention.time=15d \
--web.enable-lifecycle
2.3相关参数说明
2.3.1配置文件相关
|
参数 |
说明 |
|
--config.file="prometheus.yml" |
指定主配置文件路径,默认为 prometheus.yml,包含 scrape 配置、rule files、alerting 等。 |
|
--config.auto-reload-interval=30s |
自动检测配置文件变化并热重载的间隔时间(需配合 --web.enable-lifecycle 使用)。 |
2.3.2监听与网络
|
参数 |
说明 |
|
--web.listen-address=0.0.0.0:9090 |
Web UI、API 和指标暴露的监听地址和端口。可重复设置多个监听地址。 |
|
--web.read-timeout=5m |
HTTP 请求读取超时时间,防止连接长时间空闲。 |
|
--web.max-connections=512 |
允许的最大并发连接数。 |
|
--web.max-notifications-subscribers=16 |
实时通知订阅者最大数量(如 Alertmanager 通知流)。 |
2.3.3 外部访问与路由
|
参数 |
说明 |
|
--web.external-url=<URL> |
当 Prometheus 被反向代理时,用于生成正确的外部访问链接(如 https://prom.example.com/metrics)。 |
|
--web.route-prefix=<path> |
内部路由前缀,默认取自 --web.external-url 的路径部分。 |
|
--web.user-assets=<path> |
用户自定义静态资源目录,可通过 /user/ 访问。 |
2.3.4功能开关
|
参数 |
说明 |
|
--web.enable-lifecycle |
启用通过 HTTP 请求进行热重载或关闭服务(如 POST /-/reload)。 |
|
--web.enable-admin-api |
启用管理 API(如删除时间序列、清理数据等),生产环境慎用。 |
|
--web.enable-remote-write-receiver |
开启接收远程写入(Remote Write)的 API 端点(/api/v1/write),常用于联邦或 Agent 模式。 |
|
--web.remote-write-receiver.accepted-protobuf-messages=... |
指定支持的 Protobuf 消息格式(兼容新旧版本)。 |
|
--web.enable-otlp-receiver |
实验性功能:开启 OTLP(OpenTelemetry Protocol)写入接口。 |
2.3.5控制台与界面
|
参数 |
说明 |
|
--web.console.templates="consoles" |
控制台模板目录路径,用于自定义图形化展示页面。 |
|
--web.console.libraries="console_libraries" |
控制台依赖的 JS/CSS 库路径。 |
|
--web.page-title="..." |
浏览器页面标题。 |
|
--web.cors.origin=".*" |
CORS 跨域策略正则表达式,默认允许所有来源。建议生产环境限制。 |
2.3.6基础存储
|
参数 |
说明 |
|
--storage.tsdb.path="data/" |
本地 TSDB 数据存储路径。 |
|
--storage.tsdb.retention.time=15d |
数据保留时间(默认 15 天),单位支持 y/w/d/h/m/s/ms。 |
|
--storage.tsdb.retention.size="..." |
数据最大磁盘占用(如 50GB),基于 2 的幂(1KB=1024B)。两者可同时设置,任一条件满足即触发清理。 |
|
--storage.tsdb.no-lockfile |
不在数据目录创建锁文件(多实例写同一目录时禁用此选项)。 |
2.3.7性能优化(实验性)
|
参数 |
说明 |
|
--storage.tsdb.head-chunks-write-queue-size=0 |
Head 区块写入磁盘队列大小,0 表示关闭队列(实验性)。 |
2.3.8Agent 模式专用存储
使用 --agent 启用 Agent 模式(轻量级采集,不支持查询、告警)
|
参数 |
说明 |
|
--storage.agent.path="data-agent/" |
Agent 模式下的 WAL 存储路径。 |
|
--storage.agent.wal-compression |
是否压缩 WAL 日志。 |
|
--storage.agent.retention.min-time |
WAL 截断时保留的最短样本时间。 |
|
--storage.agent.retention.max-time |
强制删除超过该时间的样本。 |
|
--storage.agent.no-lockfile |
Agent 模式下不创建锁文件。 |
2.3.9远程存储与读写
|
参数 |
说明 |
|
--storage.remote.flush-deadline=<duration> |
关闭或重载配置前等待远程存储刷盘的最大时间。 |
|
--storage.remote.read-sample-limit=5e7 |
单次远程读取返回的最大样本数(0 表示无限制)。 |
|
--storage.remote.read-concurrent-limit=10 |
最大并发远程读请求数。 |
|
--storage.remote.read-max-bytes-in-frame=1048576 |
流式响应中单个 Protobuf 帧的最大字节数(默认 1MB)。 |
2.3.10规则与告警(Rules & Alerts)
|
参数 |
说明 |
|
--rules.alert.for-outage-tolerance=1h |
宕机恢复后,容忍多长时间内“for”状态不清零(避免短暂重启导致误报)。 |
|
--rules.alert.for-grace-period=10m |
“for”状态恢复后的最小等待时间(仅对 for > grace period 的告警有效)。 |
|
--rules.alert.resend-delay=1m |
向 Alertmanager 重发通知的最小间隔。 |
|
--rules.max-concurrent-evals=4 |
规则评估的最大并发数(影响性能)。 |
2.3.11告警管理(Alertmanager)
|
参数 |
说明 |
|
--alertmanager.notification-queue-capacity=10000 |
发送给 Alertmanager 的通知队列容量。 |
|
--alertmanager.notification-batch-size=256 |
每批发送给 Alertmanager 的最大通知数。 |
|
--alertmanager.drain-notification-queue-on-shutdown |
关闭时是否发送完剩余告警(否则丢弃)。 |
2.3.12查询引擎(Query Engine)
|
参数 |
说明 |
|
--query.lookback-delta=5m |
查询时回溯时间窗口(解决时钟不同步问题)。 |
|
--query.timeout=2m |
查询最大执行时间,超时则中断。 |
|
--query.max-concurrency=20 |
最大并发查询数。 |
|
--query.max-samples=50000000 |
单个查询最多加载到内存的样本数,防止 OOM。 |
2.3.13运行模式
|
参数 |
说明 |
|
--agent |
以 Agent 模式运行(仅采集 + remote_write,无本地查询、无告警)。 |
|
--enable-feature=... |
启用实验性或高级功能,常见选项包括:<br>• native-histograms: 支持原生直方图<br>• exemplar-storage: 存储示例(exemplars)<br>• auto-gomaxprocs: 自动设置 GOMAXPROCS<br>• memory-snapshot-on-shutdown: 关机时保存内存快照<br>• concurrent-rule-eval: 并发执行规则 |
2.3.15自动资源管理(Go 运行时)
|
参数 |
说明 |
|
--auto-gomaxprocs |
自动设置 Go 的 GOMAXPROCS 为容器 CPU 配额(推荐容器中启用)。 |
|
--auto-gomemlimit |
自动设置 GOMEMLIMIT 以匹配容器内存限制。 |
|
--auto-gomemlimit.ratio=0.9 |
设置 GOMEMLIMIT 占容器/系统内存的比例(默认 90%)。 |
2.3.16日志配置
|
参数 |
说明 |
|
--log.level=info |
日志级别:debug, info, warn, error。调试时可用 debug。 |
|
--log.format=logfmt |
日志输出格式:logfmt(文本)或 json(便于日志收集系统解析)。 |
2.4界面
http://192.168.1.204:9090/query
三、什么是Grafana
Grafana允许您查询、可视化、提醒和理解您的指标,无论它们存储在哪里。与您的团队创建、探索和共享仪表板,并培养数据驱动的文化:
可视化:具有多种选项的快速灵活的客户端图。面板插件提供了许多不同的方法来可视化指标和日志。
动态仪表板:使用在仪表板顶部显示为下拉菜单的模板变量创建动态和可重用的仪表板。
探索指标:通过即席查询和动态深入分析来探索您的数据。拆分视图并并排比较不同的时间范围、查询和数据源。
探索日志:体验从指标切换到保留标签过滤器的日志的魔力。快速搜索所有日志或实时流式传输。
警报:为最重要的指标直观地定义警报规则。Grafana将持续评估并向Slack、PagerDuty、VictorOps、OpsGenie等系统发送通知。
混合数据源:在同一图表中混合不同的数据源!您可以在每个查询的基础上指定数据源。这甚至适用于自定义数据源。
四、部署Grafana
4.1下载
#docker pull grafana/grafana-enterprise:12.1.0-ubuntu
4.2运行
docker run -d --name grafana -p 9100:3000 grafana/grafana-enterprise:12.1.0-ubuntu
4.3登录界面
http://192.168.1.204:3100

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)