paimon实时数据湖教程-写入与事务原理
写在前面
学习目标:
-
理解 Flink 数据通过 Sink 写入 Paimon 的完整生命周期。
-
掌握 Paimon 中数据文件、清单文件、清单列表和快照文件这四种核心文件的作用及关联关系。
-
阐述 Paimon 如何利用 Flink 的 Checkpoint 机制实现两阶段提交(2PC),保证端到端的数据一致性。
-
能够通过示例代码,将 Flink 数据流写入 Paimon 表。
先决条件:
-
了解 Flink DataStream API 和 Checkpoint 机制的基本概念。
-
了解分布式系统中事务的基本概念(如 ACID)。
-
具备基础的 SQL 和 Java/Scala 编程能力。
我们来深入探讨 Apache Paimon 最核心的部分之一:写入与事务原理。我们每天都在使用数据湖,将海量数据写入其中,但有没有想过,Paimon 是如何保证在分布式、高并发的环境下,每一次写入都是准确无误、不丢不重的?比如,当 Flink 作业在写入过程中突然失败,Paimon 是如何保证数据不会出现“半成品”状态的?
本章将揭开 Paimon 写入过程的神秘面纱,我们将从一次写入的生命周期开始,了解其底层的四大文件类型,并最终掌握其保证数据一致性的“法宝”——两阶段提交协议。
1 实现原理:一次写入的生命周期
一次写入操作,尤其是在流式处理场景下,并不是简单地将数据追加到某个文件中。为了实现可回滚、可时间旅行的原子性提交,Paimon 设计了一套精密的元数据管理机制。
1.1 原理图解:从 Flink Sink 到 Paimon Writer
当一个 Flink 作业向 Paimon 表写入数据时,其内部流程可以简化为以下几个关键步骤。数据首先在 Flink 的 Sink 任务中被处理,然后交由 Paimon 的 Writer 组件进行实际的写入和预提交操作,最终由一个全局的 Committer 完成事务的最终提交。
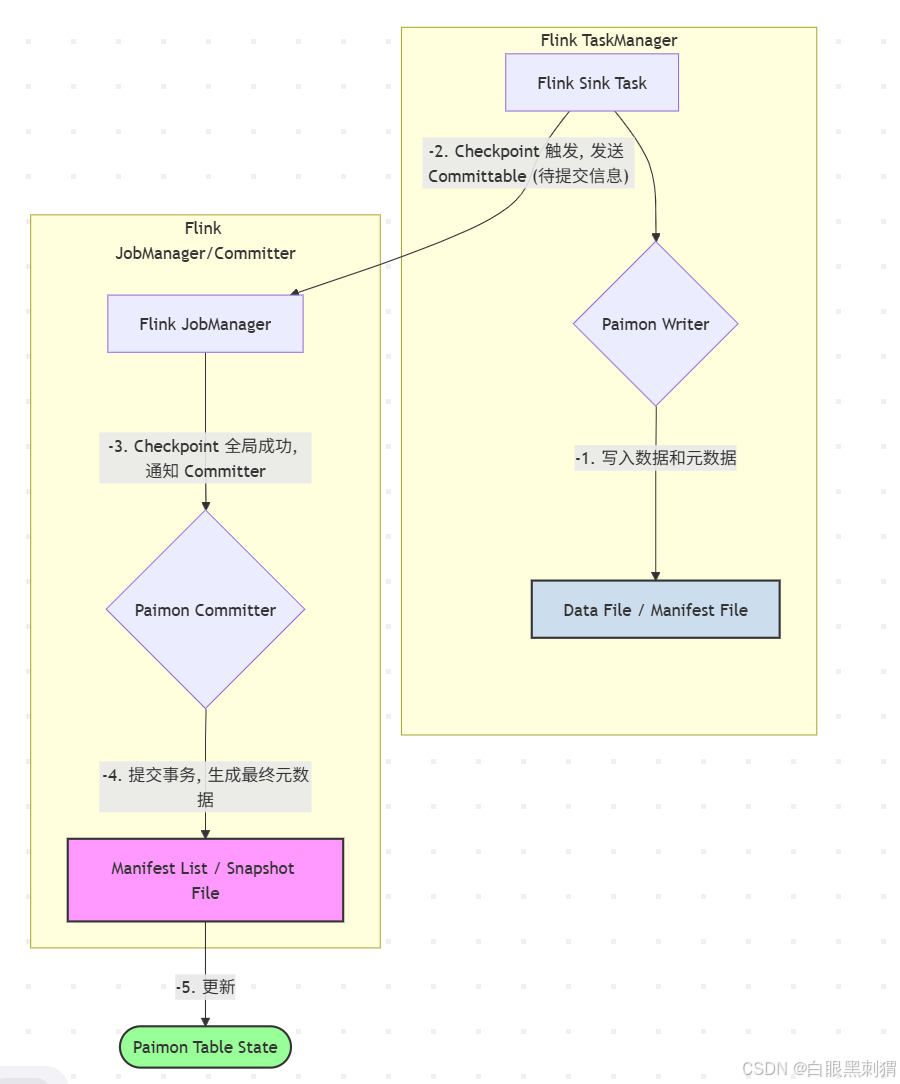
流程讲解:
-
数据写入 (在 Flink Sink Task 中):
-
Flink 的 Sink Task 接收上游数据。
-
内部的
Paimon Writer将这些数据写入到数据文件(如 Parquet 或 ORC 格式)。这些文件是不可变的。 -
同时,Writer 会生成一个或多个清单文件 (Manifest File),记录本次写入中 "增加" 或 "删除" 了哪些数据文件。
-
-
预提交 (Pre-commit):
-
当 Flink 触发 Checkpoint 时,Sink Task 会完成当前批次数据的写入,并准备好对应的清单文件。
-
它将这些清单文件的信息打包成一个
Committable对象,发送给 Flink 的 JobManager。这个阶段可以看作是“我准备好了,随时可以提交”。
-
-
全局提交 (Commit):
-
Flink JobManager 收集到所有任务的
Committable后,确认 Checkpoint 全局成功。 -
它会通知一个指定的 Paimon Committer 任务。
-
Committer 收集所有 Sink Task 发来的
Committable(即所有待提交的清单文件),将它们汇总到一个清单列表 (Manifest List) 文件中。 -
最后,Committer 创建一个快照文件 (Snapshot File),该文件指向刚刚创建的清单列表。
-
-
原子切换:
-
快照文件的创建是一个原子操作。一旦新的快照文件成功生成,整个事务就被视为成功提交。查询 Paimon 表的 Reader 会通过最新的快照文件来发现这次新写入的数据。
-
1.2 文件关系与生成过程
Paimon 的事务性是通过这四种核心文件之间的层级关系来保证的。
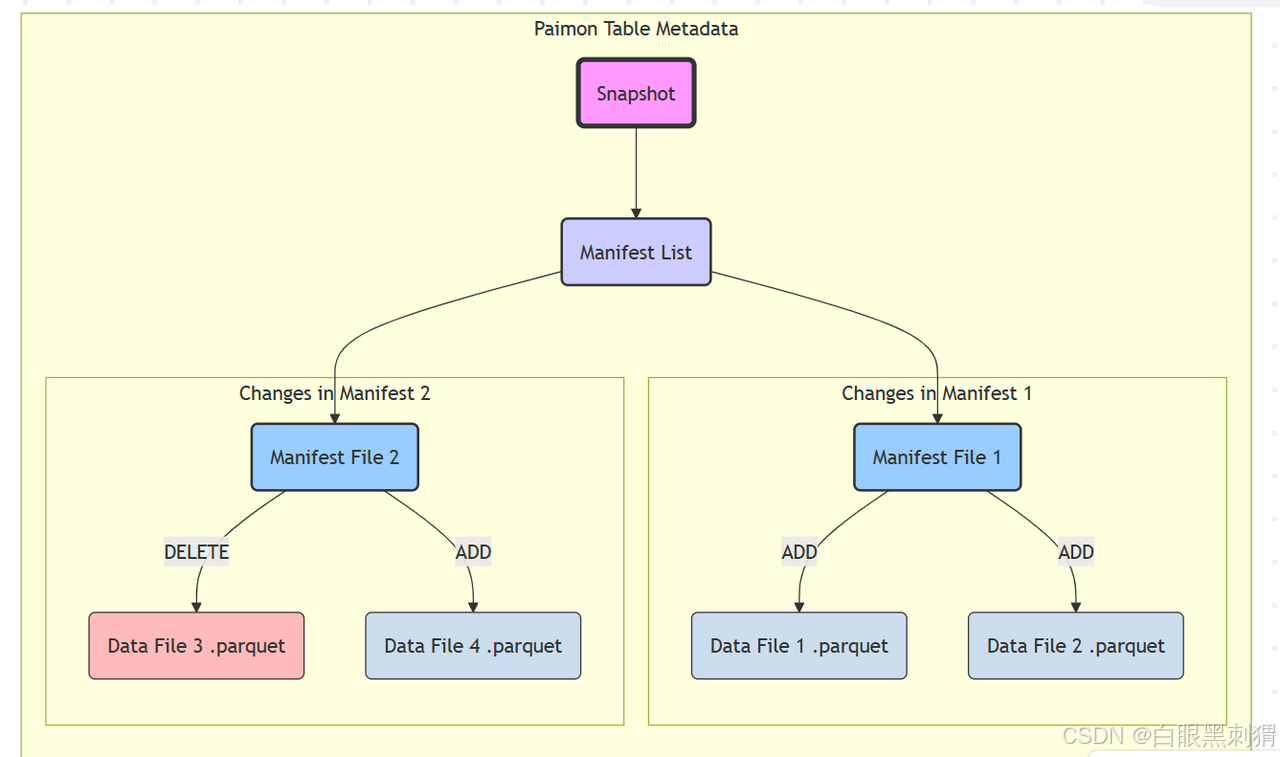
文件详解:
-
数据文件 (Data File)
-
作用:存储表的真实行数据。通常是列存格式,如 Parquet 或 ORC。
-
特点:不可变。一旦写入,就不会被修改。更新或删除操作是通过写入新的数据文件(包含更新后的数据)和记录旧数据文件被废弃来实现的。
-
示例:
s3://bucket/path/to/table/bucket-0/part-a=1,part-b=2-uuid.parquet
-
-
清单文件 (Manifest File)
-
作用:记录一个 "变更集 (Changeset)"。它是一个元数据文件,内容是一个列表,列出了哪些数据文件被添加 (ADD) 或删除 (DELETE)。
-
生成:由
Paimon Writer在 Flink Sink Task 中生成,对应一次 Checkpoint 中一个 Task 的写入内容。 -
为什么需要它?:将成千上万个小的数据文件变更,聚合到一个清单文件中,避免上报给 Committer 的信息过于零散。
-
示例:
s3://bucket/path/to/table/manifest/manifest-uuid
-
-
清单列表 (Manifest List)
-
作用:记录一次完整提交(一个 Snapshot)所包含的所有清单文件。
-
生成:由
Paimon Committer生成。它收集本次提交中所有 Writer 生成的清单文件,并将它们的路径记录到清单列表中。 -
为什么需要它?:一个 Flink 作业可能有多个并发的 Sink Task,每个 Task 都会产生自己的清单文件。清单列表将这些并行的变更聚合成一个原子单元。
-
示例:
s3://bucket/path/to/table/manifest/manifest-list-uuid
-
-
快照文件 (Snapshot File)
-
作用:代表一次成功的、原子的提交。它是 Paimon 表在某个时间点的完整状态。查询的入口点。
-
内容:指向一个清单列表 (Manifest List),还包含 schema ID、提交时间等元数据。
-
生成:由
Paimon Committer在事务的最后一步原子性地创建。文件名是一个递增的数字,如1,2,3... -
原子性保证:文件系统(如 HDFS, S3)的
rename或create操作通常是原子的。Paimon 先将快照内容写入一个临时文件,然后原子性地重命名为最终的快照文件名。只要这个文件出现,就代表事务成功。 -
示例:
s3://bucket/path/to/table/snapshot/1
-
2 实现原理:两阶段提交协议 (2PC)
两阶段提交(Two-Phase Commit, 2PC)是保证分布式系统事务原子性的经典协议。Paimon 巧妙地将 Flink 的 Checkpoint 机制与 2PC 结合,实现了流式写入的端到端 Exactly-Once。
-
协调者 (Coordinator): Flink JobManager
-
参与者 (Participants): Flink Sink Tasks (及内部的 Paimon Writer 和 Committer)
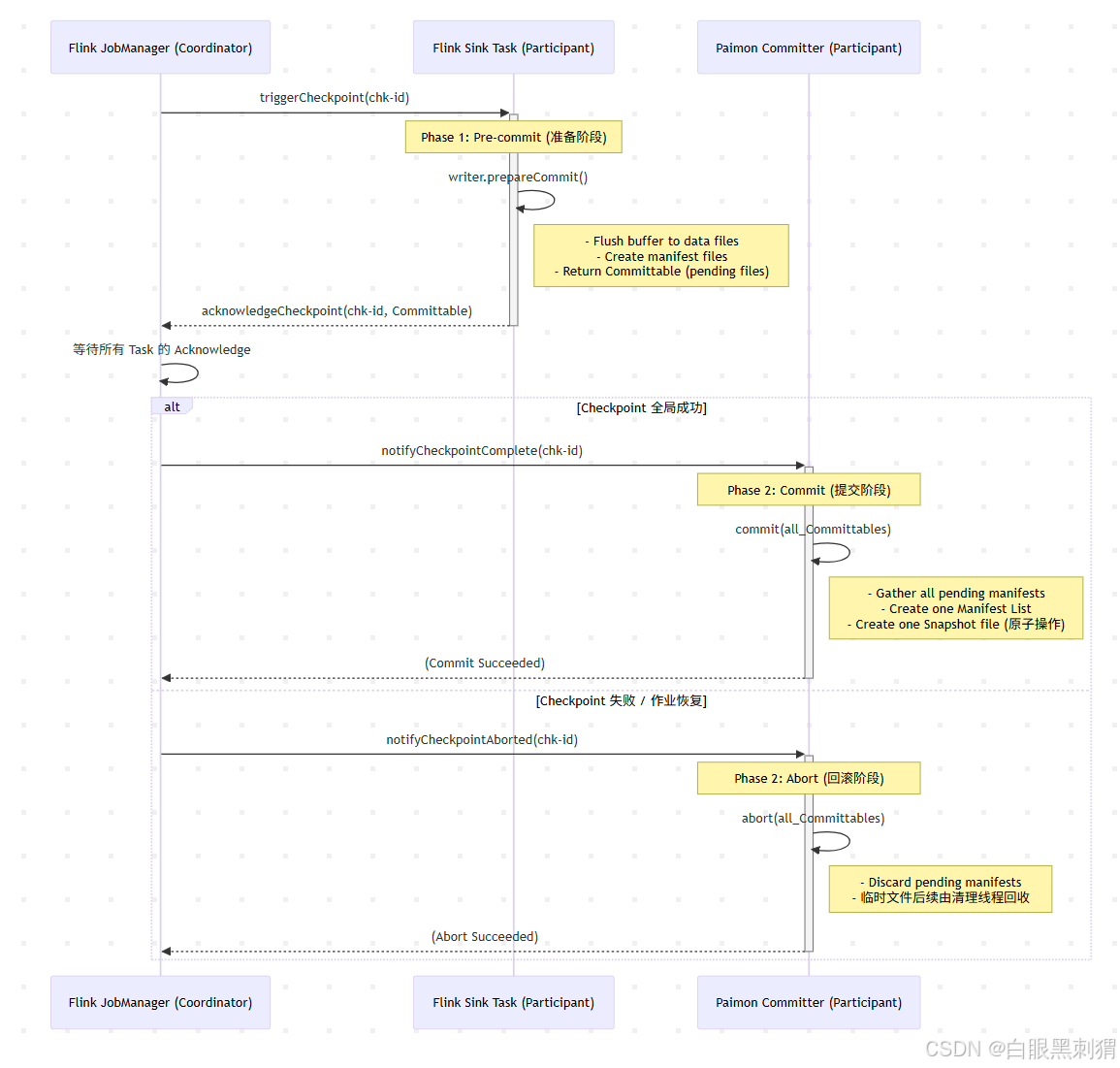
阶段一:预提交 (Pre-commit / Prepare Phase)
-
Flink JobManager 发起 Checkpoint。
-
triggerCheckpoint信号到达每个 Sink Task。 -
Paimon Writer 执行
prepareCommit():-
将内存缓冲区的数据刷写到最终的数据文件(Data File)。
-
为这些新生成的数据文件创建一个清单文件(Manifest File)。
-
关键:此时,这些文件只是“临时”或“待定”状态,对外部查询不可见。
-
将生成的清单文件信息打包成
Committable,通过 Flink 的snapshotState机制返回给 JobManager。
-
-
Sink Task 向 JobManager 回复
acknowledgeCheckpoint,表示自己的 Checkpoint 部分已完成。
阶段二:提交 (Commit Phase)
-
JobManager 成功收集到所有 Task 的
acknowledge,标志着 Checkpoint 全局成功。 -
JobManager 调用
notifyCheckpointComplete()方法,这个通知会发送给 Paimon Committer。 -
Paimon Committer 收到通知后,执行
commit():-
收集本次 Checkpoint 中所有 Sink Task 发来的
Committable。 -
将所有清单文件(Manifest Files)路径写入一个新的清单列表(Manifest List)。
-
创建一个新的快照文件(Snapshot),指向这个清单列表。
-
此步的快照文件创建是原子的,一旦成功,数据即对外部可见,事务完成。
-
异常处理:回滚 (Abort Phase)
-
场景:如果在预提交阶段,有任何一个 Sink Task 失败,或者 JobManager 在等待超时后仍未收齐所有
acknowledge,则 Flink 认为本次 Checkpoint 失败。 -
处理:
-
JobManager 会触发
notifyCheckpointAborted()。 -
Paimon Committer 收到回滚通知后,会忽略本次 Checkpoint 产生的所有
Committable。 -
那些在预提交阶段生成的“临时”数据文件和清单文件,因为没有被任何一个成功的快照引用,所以它们成了“孤儿文件”。Paimon 后续会有专门的清理机制来识别并删除这些孤儿文件,回收存储空间。
-
由于没有生成新的快照,所以 Paimon 表的状态没有发生任何变化,从而保证了写入的原子性。
-
-
3 示例代码演示
1. 创建 Paimon 表 (SQL)
首先,在 Flink SQL Client 中创建一个 Paimon 表。
codeSQL
-- 创建一个 CatalogCREATE CATALOG my_paimon WITH (
'type' = 'paimon',
'warehouse' = 's3://your-bucket/paimon_warehouse'
-- 如果在本地测试,可以使用 'warehouse' = 'file:/path/to/warehouse'
);
USE CATALOG my_paimon;
-- 创建一个分区表CREATE TABLE IF NOT EXISTS user_behavior (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING, -- 分区键:日期
`timestamp` BIGINT,
PRIMARY KEY (user_id, dt) NOT ENFORCED -- 定义主键以支持 Merge-On-Read
) PARTITIONED BY (dt) WITH (
'bucket' = '2', -- 分桶,提高写入性能'changelog-producer' = 'input' -- 接收 Changelog 流
);
2. Flink DataStream 写入作业 (Java)
这是一个模拟生成用户行为数据并写入 Paimon 表的 Flink 作业。
codeJava
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.flink.table.types.logical.BigIntType;
import org.apache.flink.table.types.logical.LogicalType;
import org.apache.flink.table.types.logical.RowType;
import org.apache.flink.table.types.logical.VarCharType;
import org.apache.paimon.catalog.Catalog;
import org.apache.paimon.catalog.CatalogContext;
import org.apache.paimon.catalog.CatalogFactory;
import org.apache.paimon.flink.sink.PaimonSink;
import org.apache.paimon.options.Options;
import org.apache.paimon.table.Table;
import org.apache.paimon.types.DataField;
import org.apache.paimon.types.DataType;
import org.apache.paimon.fs.Path;
import java.time.Duration;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Random;
public class PaimonSinkExample {
public static void main(String[] args) throws Exception {
// 1. 设置 Flink 环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 启用 Checkpoint,这是 Paimon 事务性写入的先决条件
env.enableCheckpointing(10000); // 每 10 秒一次 Checkpoint// 2. 创建一个模拟数据源
DataStream<RowData> sourceStream = env.fromSequence(1, 1000)
.map(i -> {
Random random = new Random();
return GenericRowData.of(
i, // user_id
random.nextLong(), // item_id
StringData.fromString(random.nextBoolean() ? "click" : "purchase"), // behavior
StringData.fromString(LocalDate.now().format(DateTimeFormatter.ISO_DATE)), // dt
System.currentTimeMillis() // timestamp
);
}).returns(Types.ROW_NAMED(
new String[]{"user_id", "item_id", "behavior", "dt", "timestamp"},
Types.LONG, Types.LONG, Types.STRING, Types.STRING, Types.LONG
));
// 3. 获取 Paimon 表
String warehousePath = "s3://your-bucket/paimon_warehouse";
Options catalogOptions = new Options();
catalogOptions.set("warehouse", warehousePath);
CatalogContext catalogContext = CatalogContext.create(catalogOptions);
Catalog catalog = CatalogFactory.createCatalog(catalogContext);
org.apache.paimon.schema.TableSchema paimonSchema = catalog.getTable(
new org.apache.paimon.catalog.Identifier("default", "user_behavior")
).schema();
Table paimonTable = catalog.getTable(
new org.apache.paimon.catalog.Identifier("default", "user_behavior")
);
// 4. 构建 PaimonSink
PaimonSink<RowData> paimonSink = new PaimonSink<>(paimonTable);
// 5. 将数据流写入 Sink
sourceStream.sinkTo(paimonSink);
// 6. 执行作业
env.execute("Flink DataStream to Paimon Sink Example");
}
}代码讲解: - env.enableCheckpointing(10000): 这是最关键的一步。没有 Checkpoint,Paimon 的 2PC 事务就无法触发。 - PaimonSink: 这是 Paimon 提供的 Flink DataStream 连接器,它内部封装了我们前面讨论的所有逻辑:Writer、Committer 以及与 Flink Checkpoint 的交互。 - 当你运行这个作业时,可以去你的 Warehouse 路径下观察文件的变化。你会看到 snapshot 目录下的文件在每次 Checkpoint 成功后递增,同时 manifest 和数据文件目录也会不断产生新文件。
看不下去,看不懂? 没关系,我们有完整的配套视频给您详细讲解! 如果需要的话联系UP主呦!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)