Spark 学习笔记(一)概念,demo入门
spark参考文档
https://spark.apache.org/docs/latest/rdd-programming-guide.html
对比Hadoop MapReduce: https://doctording.blog.csdn.net/article/details/78467216
-
Hadoop MapReduce 每次计算的中间结果都会存储到 HDFS 的磁盘上;而 Spark 的中间结果可以保存在内存,在内存中进行数据处理,内存放不下了会写入本地磁盘,而不是 HDFS。
-
Spark 可以通过将流拆成小的 batch,来提供 Discretized Stream 处理交互式实时数据。
-
Spark 引入了基于 RDD 的抽象,数据处理逻辑的代码非常简短,且提供了丰富的Transformation(转换,用于创建新的 RDD)和Action(执行,用于对 RDD 进行实际的计算)操作及对应的算子,很多基本的操作(如 filter, union, join, groupby, reduce)都已经在 RDD 的 Transformation 和 Action 中实现。
-
Spark 中的一个 Job 可以包含 RDD 的多个 Transformation 操作,在调度时可以根据依赖生成多个Stage(阶段)。
-
RDD 内部的数据集在逻辑上和物理上都被划分为了多个Partitions(分区),每一个 Partition 中的数据都可以在单独的任务中被执行,而 Partition 不同的 Transformation 操作需要 Shuffle,被划分到不同的 Stage 中,要等待前面的 Stage 完成后才可以开始。
-
Spark 中还存在CheckPoint机制,这是一种基于快照的缓存机制,如果在任务运算中,多次使用同一个 RDD,可以将这个 RDD 进行缓存处理,在后续使用到该 RDD 时,就不需要重新进行计算。
spark 基础问题?
- rdd(Resilient Distributed Datasets, 弹性分布式数据集) 的概念,特征?
- rdd 如何创建?
- rdd的操作:
transformations&actions? - closures (闭包) ?
- Local & cluster modes(不同模式的差别和运行差异)
- Shuffle 操作
- RDD Persistence ?
- Which Storage Level to Choose? 如何存储?
- Shared Variables & Broadcast Variables(共享变量 & 广播变量)
- Accumulators (累加器)
- task
spark sql
https://spark.apache.org/docs/latest/sql-programming-guide.html
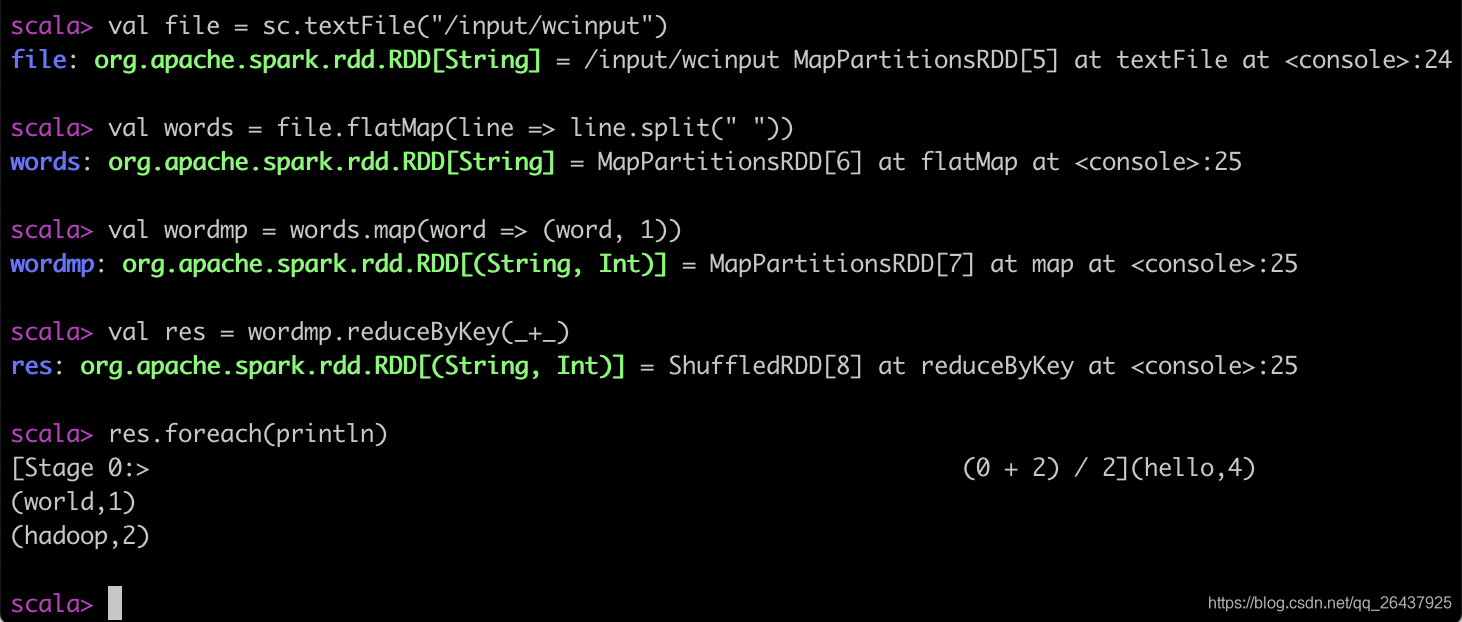
spark shell word count 例子
# spark-shell
scala> val file = sc.textFile("/input/wcinput")
file: org.apache.spark.rdd.RDD[String] = /input/wcinput MapPartitionsRDD[5] at textFile at <console>:24
scala> val words = file.flatMap(line => line.split(" "))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at flatMap at <console>:25
scala> val wordmp = words.map(word => (word, 1))
wordmp: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at map at <console>:25
scala> val res = wordmp.reduceByKey(_+_)
res: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[8] at reduceByKey at <console>:25
scala> res.foreach(println)
[Stage 0:> (0 + 2) / 2](hello,4)
(world,1)
(hadoop,2)
scala>
spark word count java例子
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/**
* @Author mubi
* @Date 2020/5/2 10:32
*/
public class WordCount {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName(WordCount.class.getName());
sparkConf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> text = sc.textFile("/Users/mubi/words.txt");
JavaRDD<String> words = text.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
// mapToPair 操作
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
// reduceByKey 操作
JavaPairRDD<String, Integer> results = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer value1, Integer value2) throws Exception {
return value1 + value2;
}
});
List<Tuple2<String, Integer>> list = results.collect();
// 打印结果
System.out.println("1==============word:count");
for (Tuple2<String, Integer> t : list) {
System.out.println(t._1 + ":" + t._2);
}
// 键值对互换
JavaPairRDD<Integer, String> temp = results
.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple) throws Exception {
return new Tuple2<Integer, String>(tuple._2, tuple._1);
}
});
List<Tuple2<Integer, String>> list2 = temp.collect();
// 打印结果
System.out.println("2==============count:word");
for (Tuple2<Integer, String> t : list2) {
System.out.println(t._1 + ":" + t._2);
}
// 排序:按key降序,即从大到小(可以自定义对key的排序)
JavaPairRDD<String, Integer> sorted = temp.sortByKey(false)
.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple) throws Exception {
return new Tuple2<String, Integer>(tuple._2, tuple._1);
}
});
List<Tuple2<String, Integer>> list3 = sorted.collect();
// 打印结果
System.out.println("3==============word:count");
for (Tuple2<String, Integer> t : list3) {
System.out.println(t._1 + ":" + t._2);
}
sc.close();
}
}
/*
hello hadoop
hello world hello
hadoop hello
spark
1==============word:count
spark:1
hadoop:2
hello:4
world:1
2==============count:word
1:spark
2:hadoop
4:hello
1:world
3==============word:count
hello:4
hadoop:2
spark:1
world:1
*/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)