不用再手动维护定位器!给你的Selenium框架装上AI“眼睛”(Web篇)
本文介绍如何利用AI视觉技术增强Selenium测试框架,通过多模态模型让自动化测试像人类一样看懂页面元素。详细演示了构建AI_Locator类的完整过程,包括截图处理、API调用和结果解析,实现用自然语言描述定位元素。该方法可显著降低因UI变更导致的维护成本,但需权衡执行速度、API成本和隐私问题。
大家好。我和大家一样,以往都受到了在做UI自动化测试时,出现了定位器频繁失效的困扰。每次到了前端发布新版本,UI界面稍作调整,自动化脚本可能就没用了。不得不花费大量时间去检查、调整那些XPath和CSS Selector。这不仅仅是重复劳动,也是效率的消耗。
接下来,就和大家分享一个实用的方法:如何为Selenium测试框架,装上一双AI的“眼睛”,让它能像人一样“看懂”页面,从而大幅降低定位器的维护成本。希望能帮助你理解,并能在自己的项目中尝试应用。

一、AI如何“看见”并理解页面?
那么,AI是如何解决这个问题的呢?
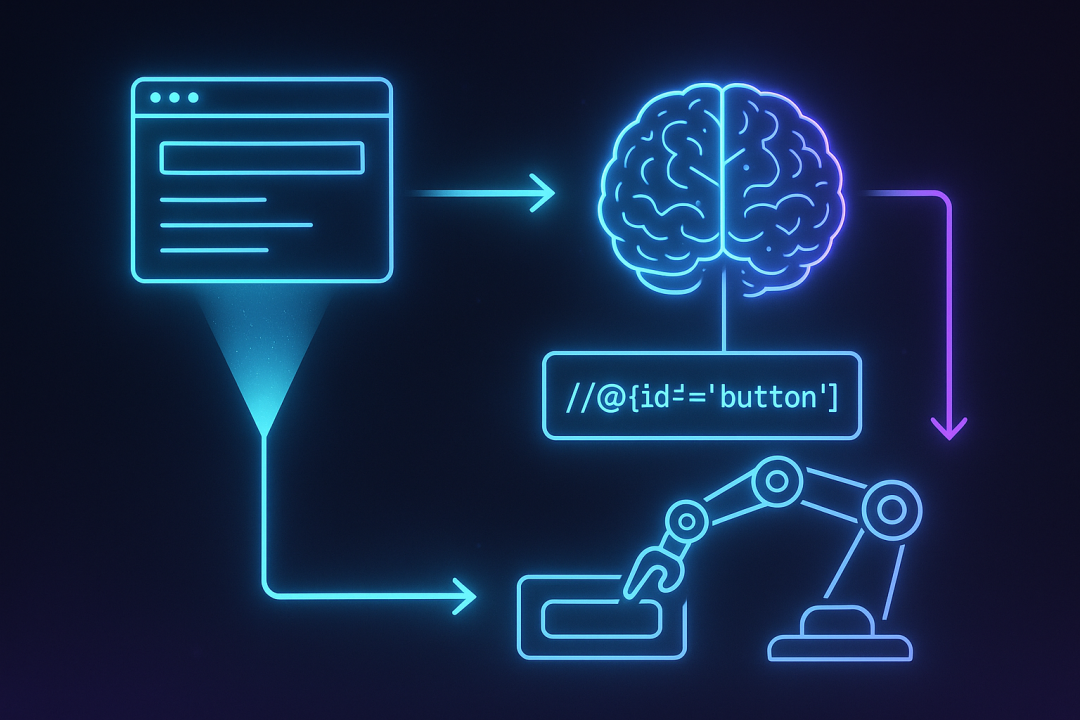
想象一下,你要让一位不懂代码的朋友帮你点击“登录”按钮,你不会告诉他:“请找到那个<div>标签下的、class为'btn-primary'的<button>元素”。你会直接说:“请点击那个蓝色的‘登录’按钮”。
AI定位器的原理与此类似。它不再仅仅依赖DOM的结构化数据,而是结合了视觉信息(页面长什么样)和上下文信息,来理解你的指令。
通过这种方式,我们从描述“代码地址”,转向了描述“业务意图”。无论按钮的颜色、位置、DOM结构怎么变,只要它在视觉上仍然能被识别为“登录按钮”,AI就有很大概率能找到它。
二、实战演练:为Selenium装上“AI的眼睛”
为了清晰地展示其内部工作原理,我们将直接编写一个简化的AI_Locator类,它会调用多模odal模型的API来完成定位。
第一步:环境准备
首先,你需要安装必要的Python库。
# 安装Selenium
pip install selenium
# 安装用于发起API请求的库
pip install requests当然,还需要一个能访问的多模态模型API(后面以谷歌的Gemini为例),并获取对应的API Key,后面会提到。
第二步:编写包含AI请求的测试脚本
我们来对比一下传统写法和AI写法的区别。下面的“AI增强写法”将包含一个自定义的AI_Locator类,用于揭示AI定位的内部逻辑。
传统写法:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化WebDriver
driver = webdriver.Chrome()
driver.get("一个示例登录页面的URL")
time.sleep(2) # 等待页面加载
# 定位元素并操作
driver.find_element(By.XPATH, '//*[@id="username"]').send_keys("testuser")
driver.find_element(By.CSS_SELECTOR, 'input[type="password"]').send_keys("password123")
driver.find_element(By.XPATH, "//button[contains(text(), '登录')]").click()
time.sleep(5)
driver.quit()增加AI写法:
我们将代码分为三个逻辑部分,使其结构更清晰。

第1部分:准备工作台 (导入库)
# --- 步骤1: 导入必要的库 ---
import base64 # 用于对截图进行Base64编码,方便在JSON中传输。
import requests # 用于向AI模型的API发送HTTP请求。
import os # 用于从环境变量中安全地读取API Key。
from selenium import webdriver # Selenium WebDriver的核心。
from selenium.webdriver.common.by import By # Selenium的定位策略。
import time # 提供时间相关的功能,如暂停。这部分代码的作用就是将我们这次任务需要用到的“工具包”(在Python中称为“库”或“模块”)一次性全部导入进来。这样做的好处是让代码结构清晰。
第2部分:打造核心工具 (定义AI定位器类)
# --- 核心逻辑: 定义AI定位器类 ---
# 这个类封装了所有与AI交互的逻辑。
class AI_Locator:
# 初始化方法,创建AI_Locator实例时调用。
def __init__(self, driver, api_key):
self.driver = driver # 保存WebDriver实例,用于操作浏览器。
self.api_key = api_key # 保存API Key。
# 构建请求的API地址,这里以Google Gemini为例。
self.api_url = f"https://generativelanguage.googleapis.com/v1beta/models/gemini-pro-vision:generateContent?key={self.api_key}"
# 主要方法,通过调用AI模型来定位元素。
def find_element(self, user_prompt):
"""
使用多模态AI模型,根据自然语言描述来定位网页元素。
"""
print(f"AI正在尝试定位: '{user_prompt}'...")
# 步骤A: 捕获当前页面截图并进行Base64编码。
screenshot_base64 = self.driver.get_screenshot_as_base64()
# 步骤B: 构建发送给AI的指令(Prompt),要求它返回一个可用的XPath。
prompt = f"""
你是一个Selenium自动化专家。请分析下面的网页截图,并为我找到描述为 '{user_prompt}' 的元素。
请只返回一个最合适的、可以直接在Selenium中使用的XPath定位器字符串。
例如: //button[@id='login-button']
不要返回任何其他解释或代码。
"""
# 步骤C: 准备API请求的数据体(Payload),包含指令和截图。
payload = {
"contents": [
{
"parts": [
{"text": prompt},
{
"inline_data": {
"mime_type": "image/png",
"data": screenshot_base64
}
}
]
}
]
}
# 步骤D: 发送API请求并获取响应。
# 使用try...except来处理可能发生的网络或解析错误。
try:
# 发送POST请求到AI模型API。
response = requests.post(self.api_url, json=payload, timeout=60)
response.raise_for_status() # 如果HTTP状态码表示错误,则抛出异常。
# 步骤E: 解析响应,提取XPath。
response_json = response.json() # 将响应的JSON文本解析为Python字典。
# 从响应数据中提取模型生成的XPath文本。
xpath = response_json['candidates'][0]['content']['parts'][0]['text'].strip()
print(f"AI返回的XPath: {xpath}")
# 步骤F: 使用AI返回的XPath定位元素。
return self.driver.find_element(By.XPATH, xpath)
except requests.exceptions.RequestException as e:
# 处理网络或HTTP请求相关的错误。
print(f"API请求失败: {e}")
return None
except (KeyError, IndexError) as e:
# 处理JSON解析错误,防止因API响应格式变更导致脚本崩溃。
print(f"解析API响应失败: {e}")
print(f"原始响应: {response.text}")
return None上述代码就是把所有与AI交互的复杂逻辑(如截图、构造请求、调用API、解析结果)都封装在一个名为 AI_Locator 的“类”里面,也可以理解为“封装”。它能让我们的核心功能成为一个独立的、可复用的工具。未来在任何其他测试脚本中,我们都可以直接使用这个工具,而不用关心其内部的实现细节,大大提高了代码的可维护性。
第3部分:执行测试任务 (脚本主体)
# --- 测试脚本主体 ---
# 从环境变量中读取API Key,这是安全编码的最佳实践。
api_key = os.environ.get("GEMINI_API_KEY")
if not api_key:
# 如果未设置API Key,则抛出错误并终止执行。
raise ValueError("请设置GEMINI_API_KEY环境变量")
# 初始化WebDriver。
driver = webdriver.Chrome()
# 设置隐式等待,提高脚本稳定性。
driver.implicitly_wait(5)
# 使用try...finally确保无论测试是否成功,浏览器最终都会被关闭。
try:
# --- 测试步骤 ---
# 1. 打开目标网站
driver.get("一个示例登录页面的URL")
# 2. 创建AI_Locator的实例。
ai_locator = AI_Locator(driver, api_key=api_key)
# 3. 使用自然语言描述来定位和操作元素。
username_field = ai_locator.find_element("用户名输入框")
if username_field: # 检查元素是否成功找到。
username_field.send_keys("testuser")
password_field = ai_locator.find_element("密码输入框")
if password_field:
password_field.send_keys("password123")
login_button = ai_locator.find_element("登录按钮")
if login_button:
login_button.click()
# 暂停,以便观察结果。
time.sleep(5)
finally:
# 清理资源,关闭浏览器。
driver.quit()这部分代码清晰地描述了测试用例的具体步骤:准备环境、打开网页、使用我们刚刚打造的 AI_Locator 工具来查找元素并执行操作。将测试流程与工具的复杂实现分离开,使得测试逻辑一目了然,我们只需关心操作步骤,而无需改动AI工具的内部代码。上面提到的把谷歌的Gemini的Api Key写到第3行代码中即可。
三、优势与需要考虑的因素
在决定是否采用它之前,需要客观地看待其优缺点。

它的优势:脚本稳定性高,能容忍一定程度的前端代码变更,有效减少脚本维护工作;编写效率提升,可以用更自然的方式写脚本,同时可读性好,代码即文档。
但我们同样需要考虑一些现实情况。首先是执行速度,AI分析需要网络通信和模型处理,通常比传统定位器慢,这对于追求高执行速度的场景可能是个瓶颈。其次是成本问题,调用商业大模型的API是按量付费(Gemini的免费额度是5次请求/分钟或25次请求/天,个人来说是够用的),大规模回归测试可能会带来一笔不小的开销。另外,AI的准确性并非100%,在复杂页面或歧义描述下仍有小概率识别错误或幻觉产生。最后,也是非常重要的一点,数据隐私,将页面截图发送到外部服务器,对于数据敏感的行业是必须严肃评估的风险点。
四、几点实用建议
结合我的实践经验,我建议你采用一种“混合策略”来引入AI定位器,而不是全盘替换。
-
优先用于“变化重灾区”。对于那些前端频繁迭代、元素不稳定、没有固定ID的区域,优先使用AI定位器。
-
稳定元素沿用旧法。对于像主导航栏、页脚等长期稳定、且有清晰ID的全局元素,继续使用传统定位器,以保证速度和稳定性。
-
给AI的描述要清晰准确。例如,用“页面底部的‘确认’按钮”就比单独一个“确认”要好,因为它增加了位置信息作为上下文,能帮助AI更精准地定位。
-
做好异常处理。在AI定位的代码外层,包裹
try...except逻辑。当AI定位失败时,可以尝试执行一次备用的传统定位方法,或者输出更详细的日志,便于排查。
AI为自动化测试带来的,是一种工作方式的转变,从关注“如何实现”,转向关注“业务意图”。
AI定位器不是要彻底取代传统定位器,而是在我们的工具箱中增加了一件应对“变化”的利器。希望今天的分享能为你打开一扇新的窗户。
附:获取谷歌Gemini API Key方法
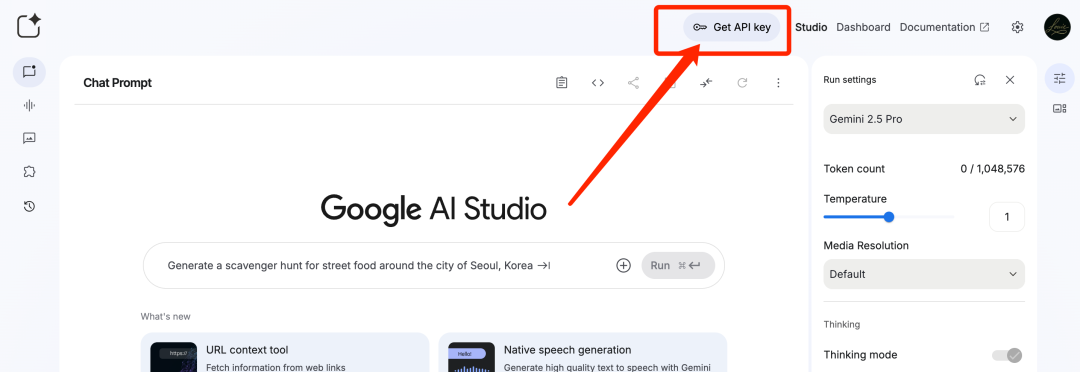
第一步:访问Google AI Studio并登录
https://aistudio.google.com/第二步:创建你的API Key
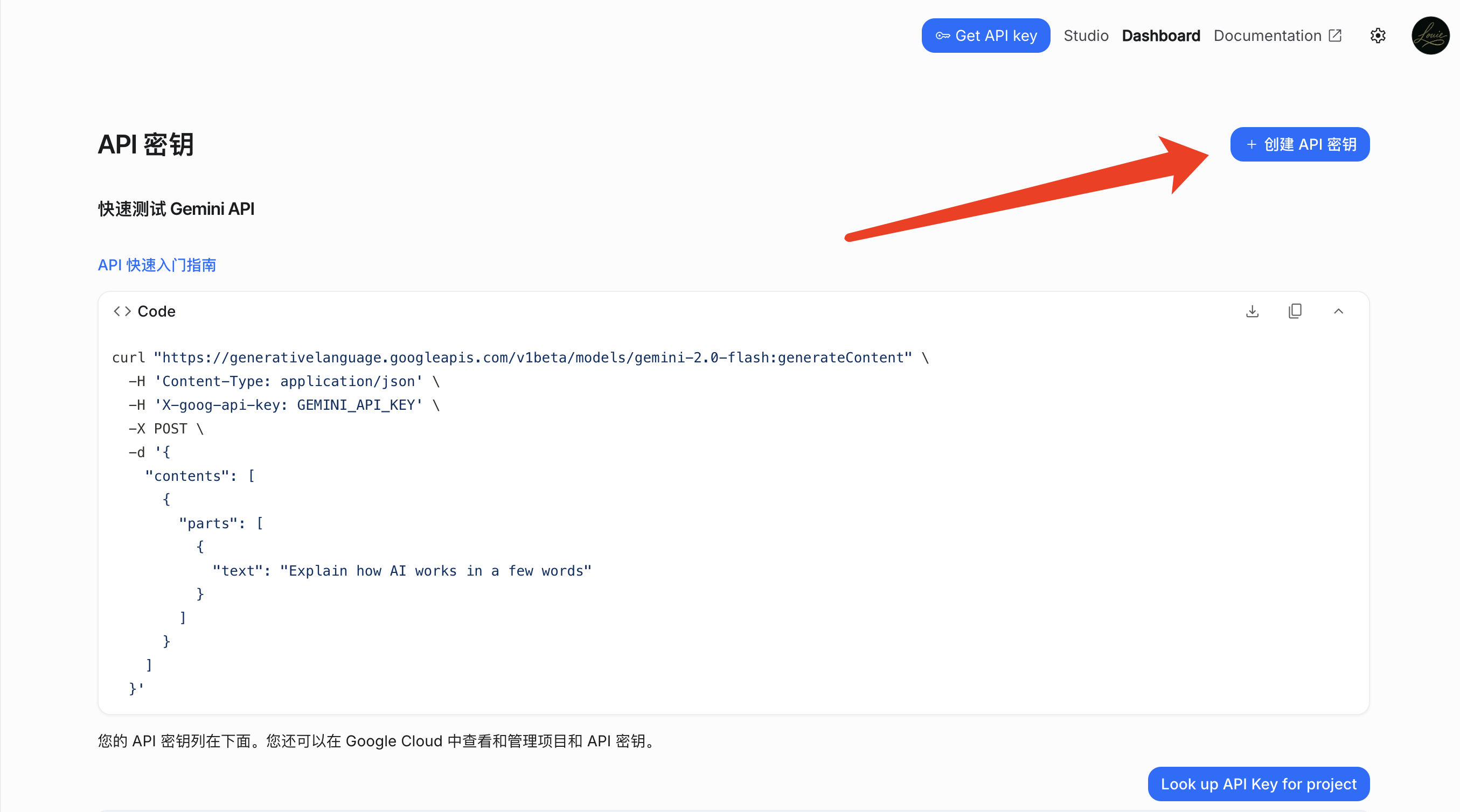
第三步:选择项目并生成密钥
在“API”密钥界面,点击“创建API密钥”
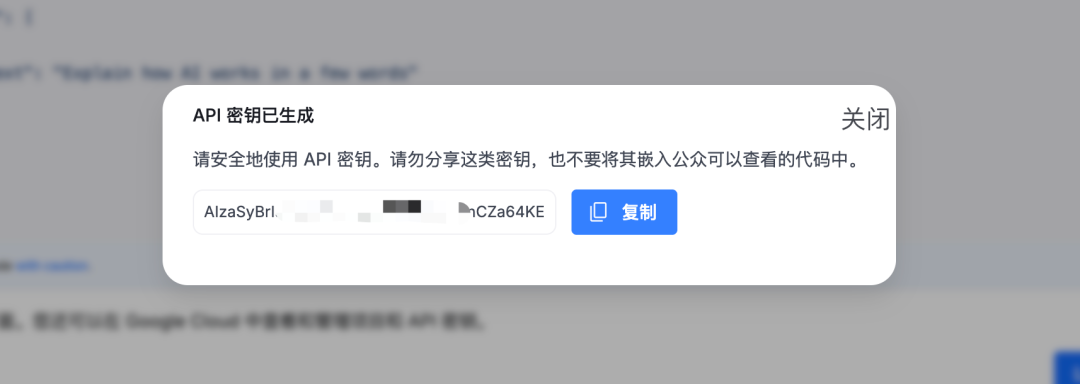
点击后,系统会自动为你生成一串由数字和字母组成的字符串,这就是你的Gemini API Key啦!
你对AI在测试领域的应用有什么看法?或者在实践中遇到了哪些问题?欢迎在评论区留言交流!
想了解更多AI干货,欢迎大家关注公众号:Pianoboi
#AI测试 #Selenium #Python #UI自动化

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)