LLM的自我中毒与去毒:9月1日将施行《人工智能生成合成内容标识办法》,这个必须了解
模型崩溃”指的是在生成式模型训练中,不断使用模型自身或其他模型生成的内容作为训练数据,导致模型逐代偏离真实数据分布,从而引发性能退化的问题(维基百科IBMShumailov 等人在《Nature》对该现象进行了系统描述,并指出其由三种误差累计导致: 统计近似误差(sampling error) , 功能表达误差(functional expressivity error) , 学习误差(learn
引言
2025 年 9 月 1 日起,中国网信办等部门联合发布的《人工智能生成合成内容标识办法》将正式施行,要求对 AI 合成内容进行显性标识,以防止公众被“污染”信息误导(政府网,CCTV)。

人工智能生成合成内容标识办法 (1)

人工智能生成合成内容标识办法 (2)

人工智能生成合成内容标识办法 (3)
这项新规的出台并非偶然——过去一年中,研究发现,即便仅有 0.01% 的训练数据被虚假信息污染,也可能使模型有害输出比例飙升 11.2%,引发连锁效应(中新网)。而伴随“AI 垃圾内容”(AI Slop)在网络平台的泛滥(Wiki),越来越多低质合成信息正在回流至训练语料,推动模型逐代退化甚至陷入“模型崩溃”(Model Collapse)和“模型自噬紊乱”(MAD)(Nature)。这场看似技术细节的危机,实际上关乎 AI 生态的健康与未来的智能质量。

"Garbage Out" from Nature magazine
什么是“模型崩溃”(Model Collapse)?
核心定义与机理
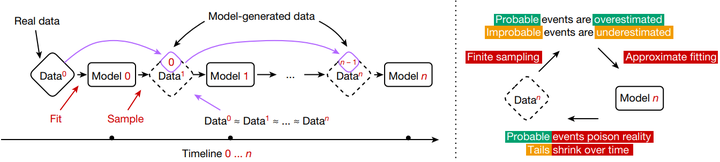
Model collapse setting
Shumailov 等人在《Nature》对该现象进行了系统描述,并指出其由三种误差累计导致: 统计近似误差(sampling error) , 功能表达误差(functional expressivity error) , 学习误差(learning error)(Nature)。例如,Emily Wenger在Nature的《AI produces gibberish when trained on too much AI-generated data》给出一个模型崩溃的案例(如下图所示)。
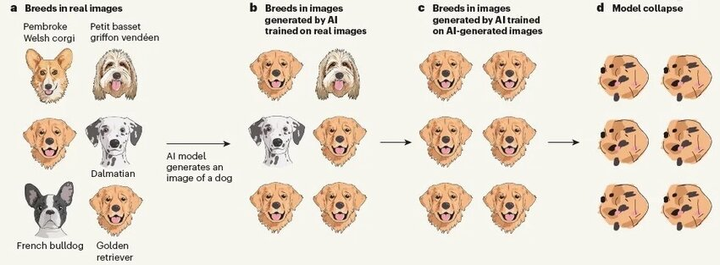
Generative AI models are trained on their own outputs
数学基础与研究扩展
-
基于简单高斯模型,研究揭示即使仅为一维或多维正态分布,随着训练代数增加,模型输出会逐步偏离原始分布——这一演变可通过 Wasserstein‑2 距离形式化分析(维基百科)。如下说明:

Wasserstein-2 distance
如上第一式E(期望)说明每一代的有限样本量M都会带来采样误差,这些误差不会被下一代完全消除,而是逐代相加累积 ; 第二式Var(方差)表明不仅每代自身的波动(第一项)会影响结果,代与代之间的误差相互作用(第二项)也会放大整体不确定性。
分阶段退化过程:“早期尾部消失 → 晚期整体退化”的逻辑
-
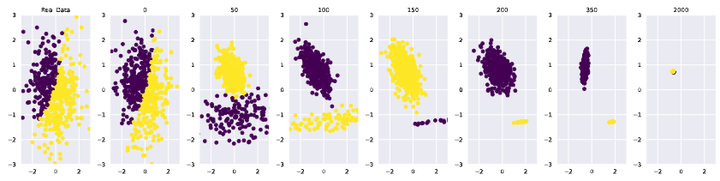
Early Collapse(早期崩溃):对尾部稀有样本敏感性下降,表现为多样性的损失,但整体表现可能未明显下降(维基百科, Nature)。 尾部样本本就稀少,有限采样噪声在这里的相对影响最大。几代迭代后,模型拟合会优先损失对尾部的刻画(W₂ 距离增加主要来自尾部差异)。例如,Shumailov等给出一个“尾巴”被割掉(cut off)的例子(arXiv)。
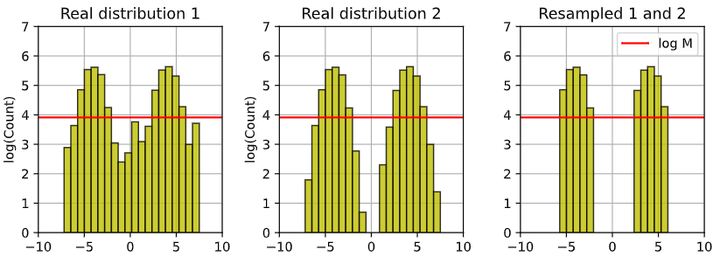
Example for early collapse
-
Late Collapse(晚期崩溃):模型输出变得高度集中、缺乏变化,难以反映真实分布(维基百科)。累积效应持续作用,方差项中的交叉积会让整个分布的形状偏离原始分布——不仅尾部,主体部分也会失真,出现整体退化。同样,Shumailov等给出一个例子(如下图,arXiv):每一代模型只用该代采样到的样本来拟合下一代(不保留之前的样本)。 采样次数 M 分别为 10、100、1000、10000,不同颜色曲线代表不同 M。左图(Mean estimation):随着迭代,均值 μ 偏离 0 的幅度逐渐累积。 右图(Standard Deviation):标准差 σ 偏离 1 的幅度同样累积,小采样量下波动更大。
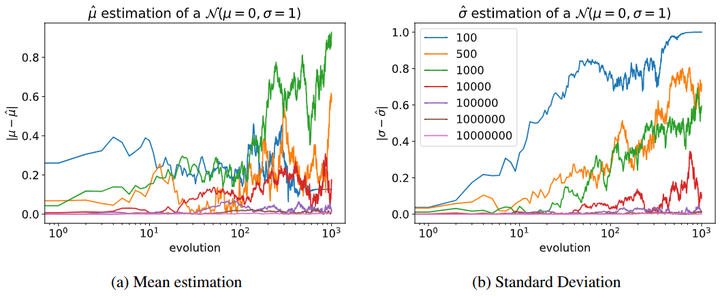
结论:如果每代只用有限样本替换原数据,误差会代际累积,导致 μ 和 σ 不可控漂移。这就是模型崩溃的典型替换型路径。
实证与危害
GMM

VAE
LLM
-
评测也会被“AI文档”污染:测试集或其近似片段混入训练语料,导致指标“虚高”。近年的综述与方法论文都把“数据污染检测/缓解”作为关键议题。arXivACL AnthologyOpenReview
什么是模型自噬紊乱(MAD)?
概念及来源
-
“Model Autophagy Disorder”由 Stanford 和 Rice University 的研究者提出,比喻模型“自噬”自身输出(如下图,如“自噬”的蛇),当完全依赖合成数据训练时,模型输出质量和多样性会逐代下降(Deepgram)。

AI Ouroboros
-
该现象的实验研究多集中于图像生成模型,通过构建纯合成训练回路效果(伪影(artifacts)被逐代放大;多样性逐渐消失。),如下两图(news.rice.edu):

Training generative artificial intelligence (AI) models on synthetic data progressively amplifies artifacts

Training generative models on biased synthetic data in a fully synthetic loop progressively loses diversity.
核心发现
-
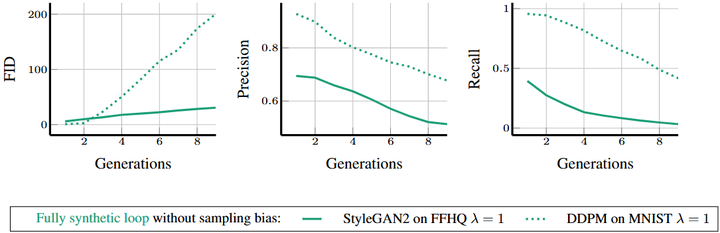
纯合成循环:若训练完全依赖合成数据,模型质量和多样性急剧下降,类似“自吃”自身信息(arXiv, news.rice.edu)。如下图所示(StyleGAN2 在 FFHQ 数据集(人脸)上的训练,以及 DDPM 在 MNIST(手写数字)上的训练。 t=1 用真实数据训练; 从 t=2 开始,训练数据全部来自前一代模型的合成样本(λ=1 表示无采样偏差,全量替换真实数据)。 FID(Fréchet Inception Distance):衡量生成图像与真实图像分布的差异(越低越好)。 Precision:生成图像的质量(高精度意味着生成样本更逼真)。 Recall:生成图像的多样性(高召回意味着覆盖的样本种类更多))。
Training generative models exclusively on synthetic data in a fully synthetic loop
左图: 随着迭代代数增加,FID 持续上升,说明生成数据分布和真实分布的差距越来越大。 DDPM(虚线)上升更快,StyleGAN2(实线)上升较慢但趋势一致。中图: 精度随代数下降,意味着生成样本质量降低(即便是看起来“正确”的样本也更假)。右图: 召回率下降更明显,尤其是 StyleGAN2,几乎趋近于 0,说明多样性严重丧失(模型生成的样本越来越单一)。
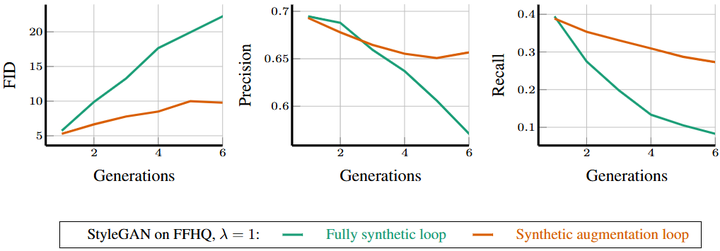
Training generative models in a synthetic augmentation loop with both fixed real and synthetic training data
然而,模型训练依赖的真实数据将马上枯竭!
文本数据或在 2026–2032 年消耗殆尽
-
一项由 Epoch.ai 等机构主导的论文调查了公共人类生成文本(即可用于训练大型语言模型的高质量互联网文本)的总储量。估算可用数据量约为 300 万亿(trillion)tokens(约 10^14–10^15 级别)(OODAloop, Epoch AI)。
-
根据当前训练数据规模增长趋势,模型训练集预计将在 2026–2032 年之间与这一文本储备总量持平——甚至如果进行了大量“过度训练”(overtraining),这个临界点可能会更早到来。例如中点年份为 2028 年。(arXiv,Nature)
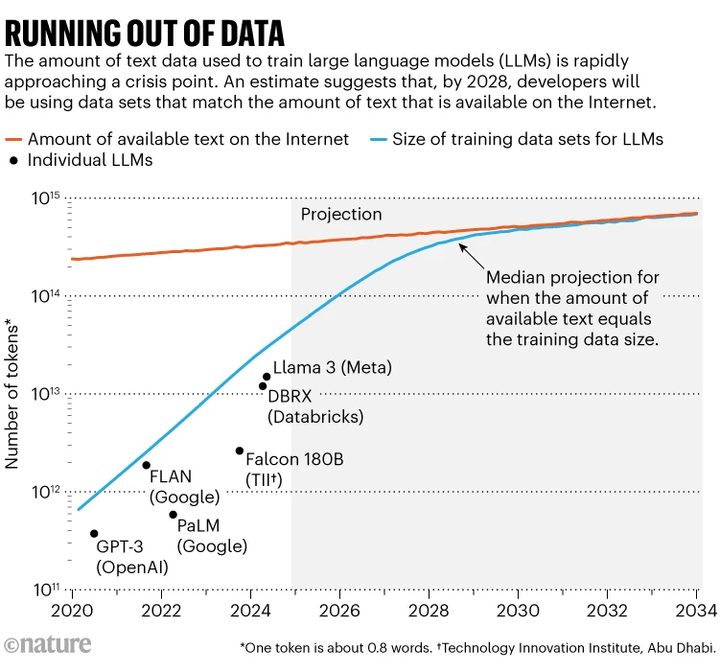
Running out of data
-
Elon Musk 曾表示,“用于训练的所有人类知识已经被耗尽”,AI 公司不得不开始大量使用合成数据,但这会引发“幻觉输出”与创意质量下降的问题。 英国图灵研究所基础 AI 总监 Andrew Duncan 指出,这种趋势可能导致“模型崩溃”(model collapse),而且过度依赖合成数据将使训练结果质量下降,缺乏创新(卫报)。

Elon Musk: ‘The cumulative sum of human knowledge has been exhausted in AI training. '
-
多个新闻报道引用以上学术预测,强调互联网免费文本有可能在 2026 年耗尽,AI 可能不得不转向使用私有、付费或 AI 生成的内容(livescience.com)。
如何解决或缓解这个问题?
模型崩溃的机制本质在于合成数据相对于原始人类数据的统计性质退化。生成模型往往会产生比训练分布“更简单”的输出:例如大模型生成的句子或图像在统计上是训练样本的“混合”,缺乏一些细节和多样性(UCLA)。如果我们用这些统计上更简单的合成数据替换真实数据来训练下一代模型,那么模型对真实分布的刻画就会越来越窄化(ICLR)。正如有研究指出的:“如果没有足够的新鲜真实数据补充,每一代模型的输出分布都会向更狭窄、更简单的方向收敛”。具体表现就是模型逐渐丧失对原始数据分布尾部部分的记忆,只能覆盖训练数据中高频、常见的模式(Nature)。
-
数据质量控制:严格把关合成数据的质量,过滤掉低质量或含有偏差的生成内容。在训练中将合成数据视为次级公民,不给予与真实数据同等的权重或地位。例如,有研究提出在训练中对合成样本赋予负引导(negative guidance),即利用合成数据的分布来告诉模型哪些模式是训练中应避免过度依赖的,从而抵消合成数据潜在的偏差影响montrealethics.ai。ICLR 2025的SIMS方法正是这一思想的实现:它通过一个辅助模型专门学习合成数据的分布特征,在扩散模型生成时提供一个反向信号,将模型拉回真实数据分布(ICLR)。

SIMS
实验证明,经过这种策略,模型即使经历100次自我训练循环也没有出现性能恶化,其生成质量与仅用真实数据训练的初始模型持平。可见,通过区别对待合成数据、抑制其不良模式,可以有效防止模型走向崩溃。
-
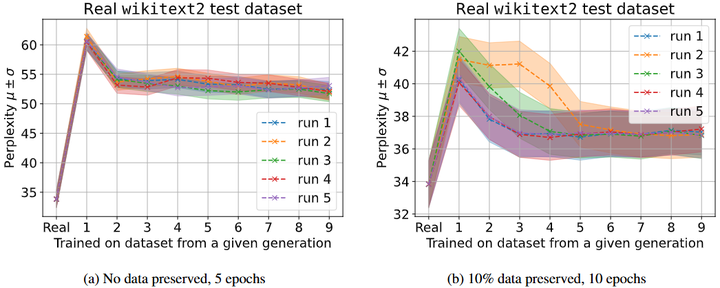
混合数据训练:确保每次迭代训练时都有足量的真实数据混入,而非完全依赖合成数据。大量研究指出,只要每代训练集里保持一定比例的人类数据,模型就能在较长时间内维持稳定。例如,一些理论分析给出了最优的混合比例:在均值和方差估计等简单情形下,当训练中赋予真实数据约61.8%(黄金比例倒数)的权重时,估计误差可最小化arxiv,arxiv。这提示在更复杂的场景中也存在一个最佳合成 vs 真实数据比使模型表现最优。
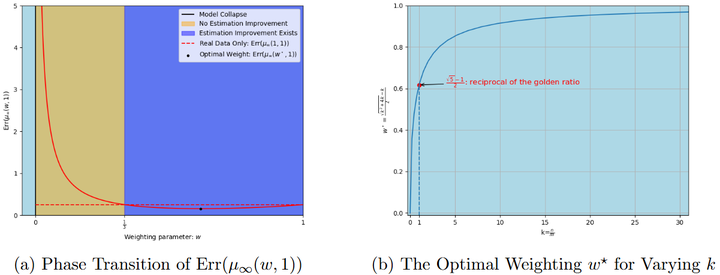
The left panel illustrates the quantitative behavior and The right panel demonstrates the quantitative relationship
相反地,Dohmatob等(2024)的“模型崩溃”研究警告(arxiv),即便合成数据比例很小,只要是非零且代际无限延续,最终仍可能导致崩溃;因此从长远看,合成数据占比必须趋近于0才能彻底避免分布退化arxiv.org。
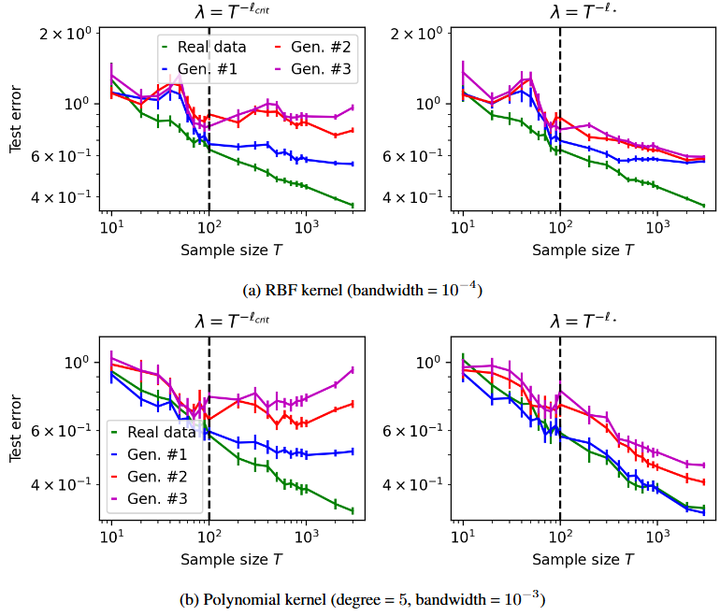
Demystifying model collapse in kernel ridge regression (power-law covariance spectrum) on MNIST.
综合来说,更现实的建议是在训练调度上设定合成数据的上限比例(如不超过某一阈值arxiv.org),并持续混入新的真实数据来稀释合成内容openreview.net。
Recursively training generative models on synthetic data
实践中,这可以通过定期爬取新的人类内容、保留历代所有数据(真实+合成)而不抛弃早期多样性、或者在模型fine-tuning阶段加入真人标注的新样本等方式实现ar5iv.labs.arxiv.org。混合数据训练的核心是在数据源上保持多样性和真实性,避免模型训练语料被合成内容淹没。
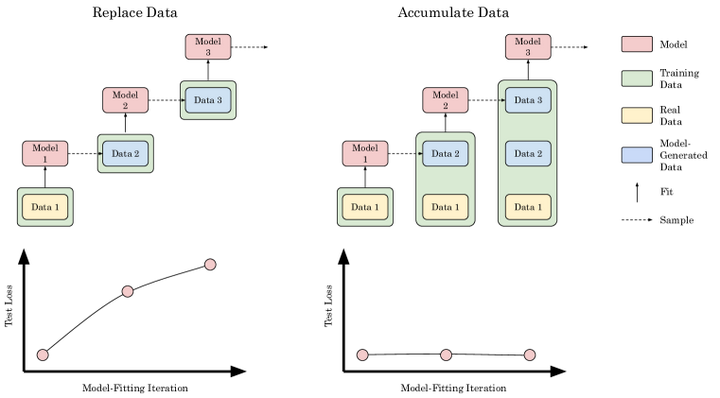
Two Settings to Study Model Collapse
-
识别并标记合成内容:开发检测器或使用水印技术,在海量训练数据中自动识别AI生成的内容,从而在数据管线中过滤或降低此类内容的权重。
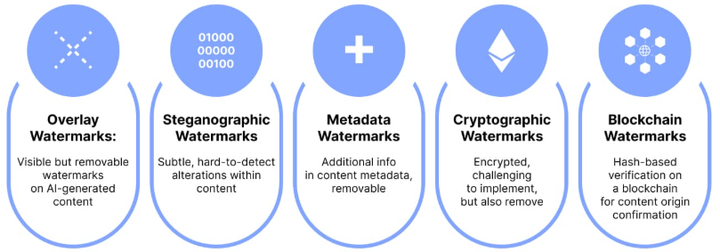
AI Watermarks
比如,可以给模型输出添加不可见的水印标记,让后续爬虫在抓取互联网数据时识别出哪些文本是模型生成的,从而避免无意中将大比例合成文本再次用于训练。在学术文献中也有对这一思路的探索,如Gray(2024)通过分析学术论文文本估计其中ChatGPT生成内容的比例dsp.rice.edu。虽然检测完全准确并不容易,但提高对合成数据的监测有助于在构建训练集时主动剔除过多的模型产出,防止无意识的数据反馈循环。另外,一些平台和法规也在倡议对AI生成内容进行显著标识,从数据源头减少合成内容混入训练集的风险,这也是我国实施《人工智能生成合成内容标识办法》的技术初衷。
-
知识注入与检索增强:针对知识和事实性信息的退化,可以采用检索增强(RAG)或知识注入的方法来弥补模型在自循环中遗忘的内容。
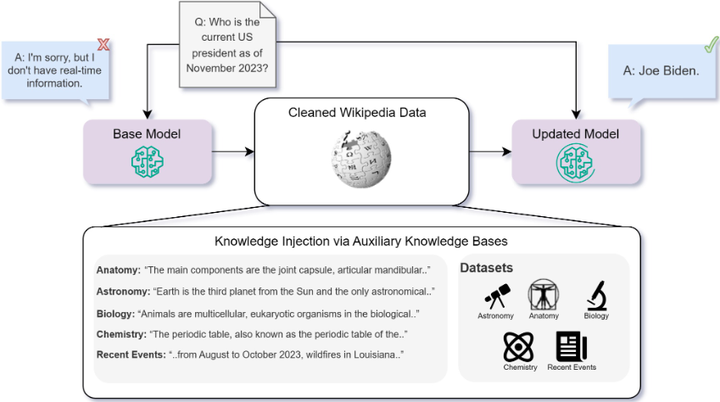
A visualization of the knowledge injection framework
具体来说,在模型训练或推理过程中,引入一个外部知识库或搜索工具,使模型能够获取真实世界的新信息,而不完全依赖自身记忆生成下一个数据。实证研究表明,在现有知识或全新事实的获取上,RAG 持续优于无监督微调(fine‑tuning) arXiv。
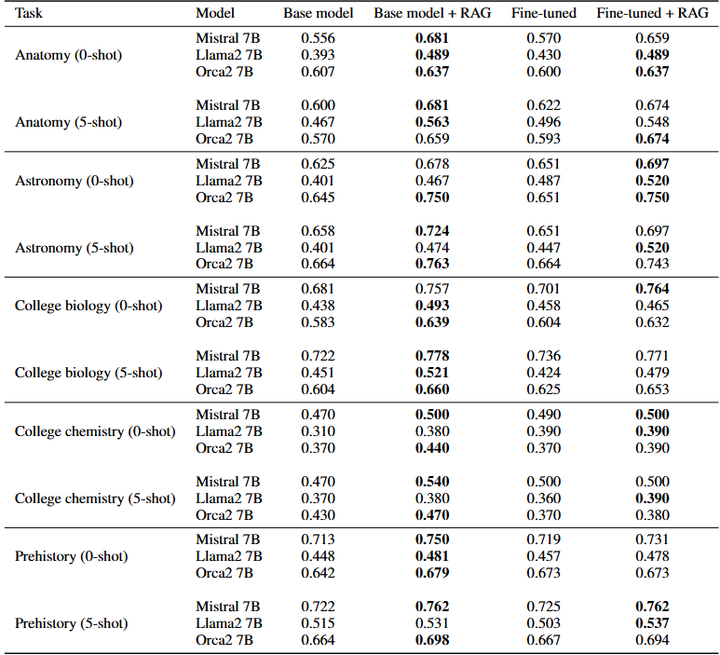
Results for the MMLU datasets
尤其对于长尾或不常见知识,RAG 提升更为显著,并通过Stimulus RAG等机制进一步优化 arXiv。
Stimulus RAG
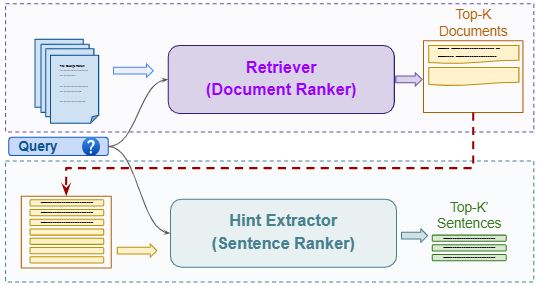
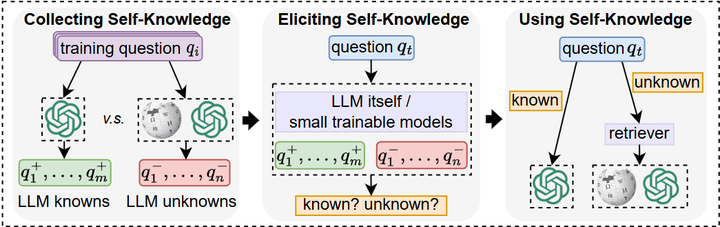
此外,在训练过程中,定期使用经过人类校验的高质量知识型数据对模型进行额外微调(如超级监督微调或参数高效微调),等同于对遗忘部分进行“补丁式注入”,恢复关键知识掌握。这种方法在教育问答系统中发挥显著作用,结合 RAG、SFT 和偏好优化提升性能约 30 % arXiv。更智能的策略还包括让模型具备“自知能力”(self‑knowledge),即判断自己是否掌握所问内容:若不确定即调用外部检索,例如 SKR 方法有所实现 arXiv。
Self-Knowledge guided Retrieval augmentation (SKR) method
还如 SeaKR(自感知知识检索)则利用模型内部不确定性动态触发检索,并优化检索内容整合,从而在关键或衰退知识场景下维持高准确性与稳定性 arXiv。
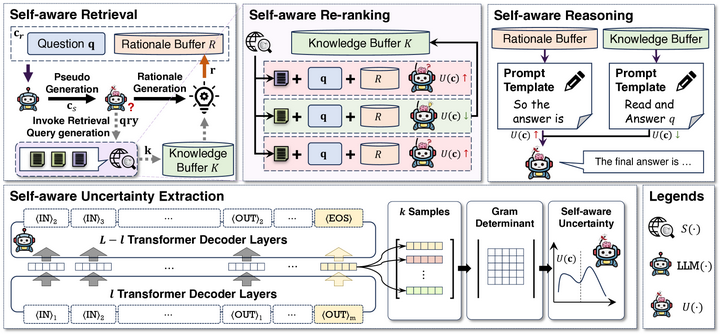
The overall framework of SeaKR
总体来看,通过RAG + 调用控制机制 + 高质量微调补丁的组合,能够有效逆转模型在自循环训练过程中因参数遗忘或合成数据偏差所致的知识缺损,确保输出权威、可靠的事实信息。
-
训练调度与反馈控制:设计更智能的训练迭代方案,对可能的崩溃迹象进行预警和纠偏。例如,研究者提出可在模型训练回路中监控模型输出分布与原始数据分布之间的距离,一旦发现分布差异扩大就调整训练数据组合或学习率,相当于在模型训练过程中加入闭环反馈控制sites.lifesci.ucla.edu。在训练中,如果检测到分布变化或训练-验证性能偏差,就动态调整训练数据组成方案(如调整真实数据与合成数据的比例)、数据增强策略或学习率。这种机制类似于控制系统中的闭环反馈:系统监测当前状态(如分布差异、性能下降),并实时调整训练条件以修正偏差。 例如,AdDA 方法在对比学习中引入闭环反馈,能根据实时反馈动态改变增强策略,让训练品质随模型“状态”保持最优,有效提升下游任务表现(ImageNet‑100 上 MoCo v2 增益超过 1%)arXiv。
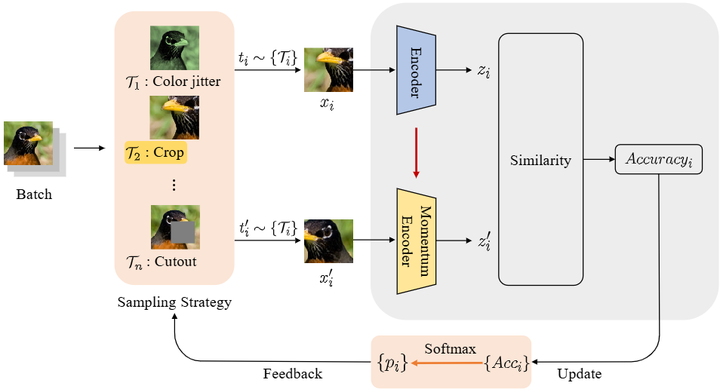
The pipeline of AdDA
在更宏观的控制场景中,self‑healing neural network 方法嵌入控制回路,在训练或部署过程中识别错误并调整神经元状态,有效抵御未预测扰动,增强模型鲁棒性jmlr.org。
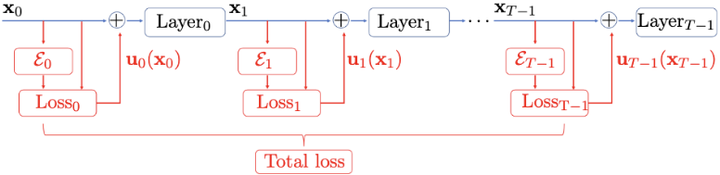
Self‑healing neural network
因此,将训练调整纳入闭环控制架构,不仅理论合理,也有实践依据:这种“动态纠偏”机制可有效稳定模型训练,在面对合成数据偏移、分布漂移或性能退化时发挥关键作用。Baraniuk等用热水器温控做比喻:当输出偏离期望时,自动切换更多冷/热(水喻指真实/合成数据)来保持平衡sites.lifesci.ucla.edu。具体实现上,这可能涉及给模型输出嵌入表示,计算不同代输出之间的多样性差异arxiv.org,或者用小型代理模型去预测下一代的性能变化,从而动态调整训练策略。另外,Gillman等(2024)在ICML提出的“自纠正的自我训练循环”方法也是类似思路:在每次迭代中引入一个校正步骤,根据模型在验证集或真实数据上的表现来修正下一步的训练数据选择ICML。
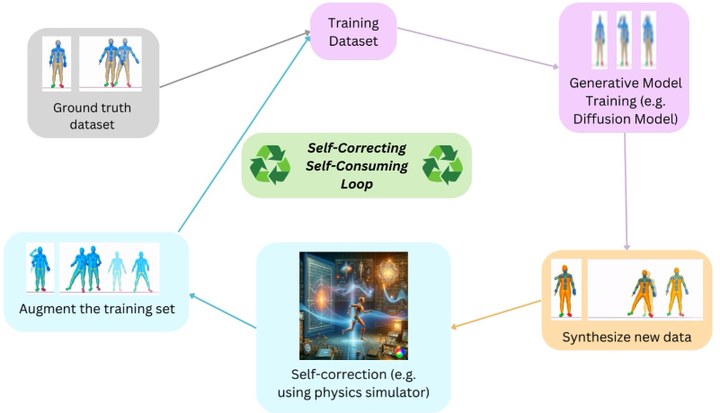
Self-correcting self-consuming loop
总的来说,训练调度方案强调主动干预:不像传统训练被动地用固定数据训练,而是根据模型当前状态自适应地选择真实 vs 合成数据的用量、顺序和方式,从而将合成数据的有益部分用于提升模型,而抑制其有害部分。
结论
最新的研究既从理论上揭示了这一现象的内在机制与不可忽视的风险,也通过大量实验量化了其影响(数据分布退化、知识遗忘、语言多样性降低、偏见加剧等)nature.comar5iv.labs.arxiv.orgdsp.rice.edu。研究者们也在积极探索缓解和预防的技术路线,包括数据策略上的混合与筛选、训练过程中的调控与反馈、以及创新性的模型训练框架。总的来说,要避免“大模型吃掉自己”导致的退化,我们需要在数据获取、训练算法以及模型架构上引入新的思路,以确保未来的模型能够持续从真实、多样的信息源中汲取营养,而不是陷入合成数据的自我循环。在人类和AI共同创造的数字生态中,这将是保障模型性能与可信度所不可回避的挑战,也是学术界2025年前沿研究的重点方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 36
36 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)