0基础coze插件开发+图生视频工作流(coze教程+获取)
先带大家从0开始创建一个coze插件(以时间线为例),再将其用在AI一键生成第一视角沉浸式视频的工作流里,主要包括文生图+图生视频+视频剪辑合成。
01 0基础coze插件开发+视频工作流
第一视角滑雪
今天做一个跟上一篇橘猫视频类似的视频工作流(文生图+图生视频+视频剪辑合成),但是每次要复制粘贴时间线代码就觉得有点麻烦,所以我干脆做一个coze插件,直接调用就好了。
coze新出了coze IDE云侧插件功能,可以直接在内部创建/运行,想开发插件的朋友也可以用这个。
我也是今天刚学的coze插件开发,做了一个输入总时间+视频书数量来分割时间线的插件,并不复杂,大家快来试一试!
后面还会结合“第一时间沉浸式视频”工作流,大致讲解一下这个时间线插件的应用,想了解具体的视频工作流可以去看我上一篇的橘猫AI视频工作流教程。
02 coze插件开发:时间线插件
2.1 创建插件
首先搜索coze进入官网,点击<开发平台>→<快速开始>,进入主页。
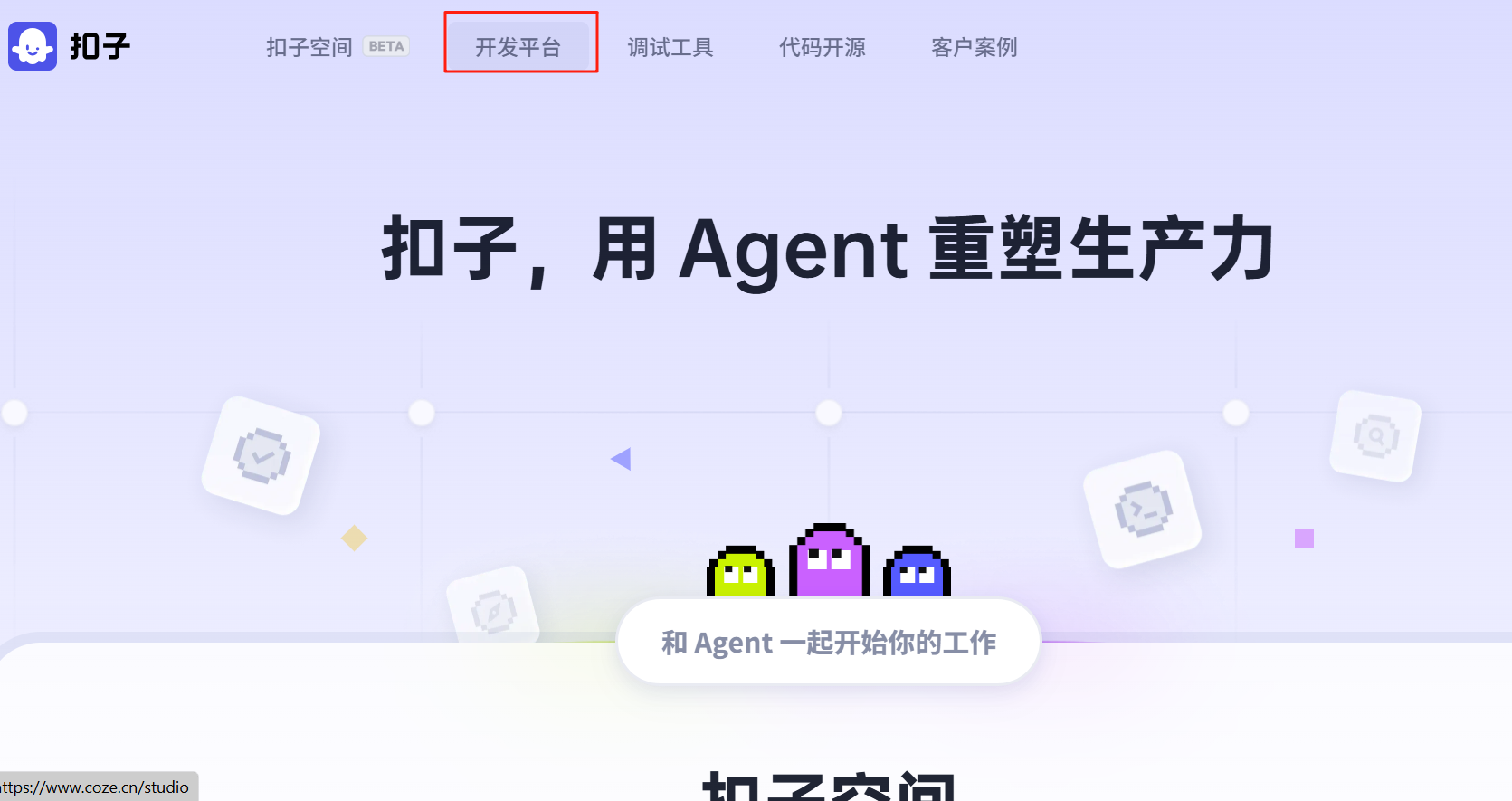
点击 工作空间 → 资源库 → +资源<插件>
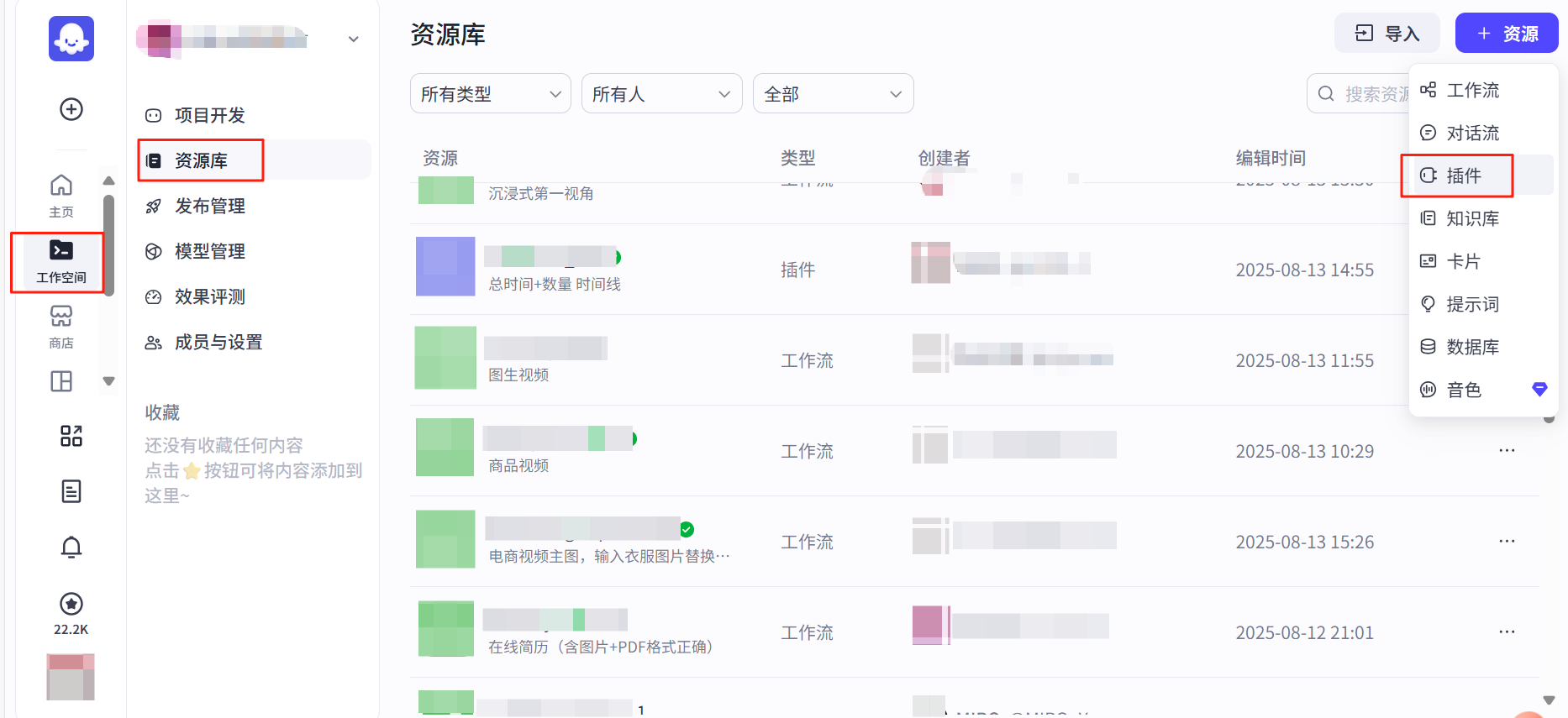
输入名称和描述,选择Coze IDE创建方式,我使用的是Python3。
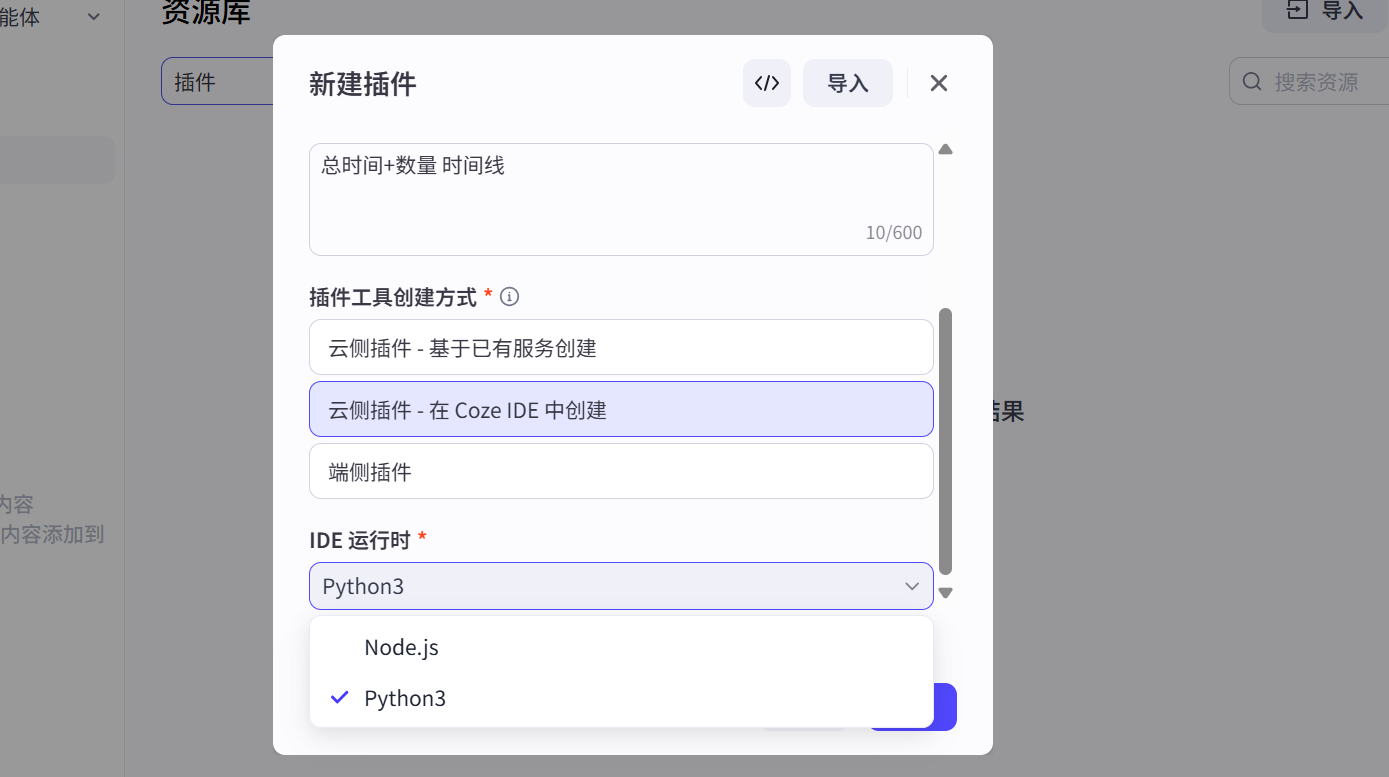
创建工具:
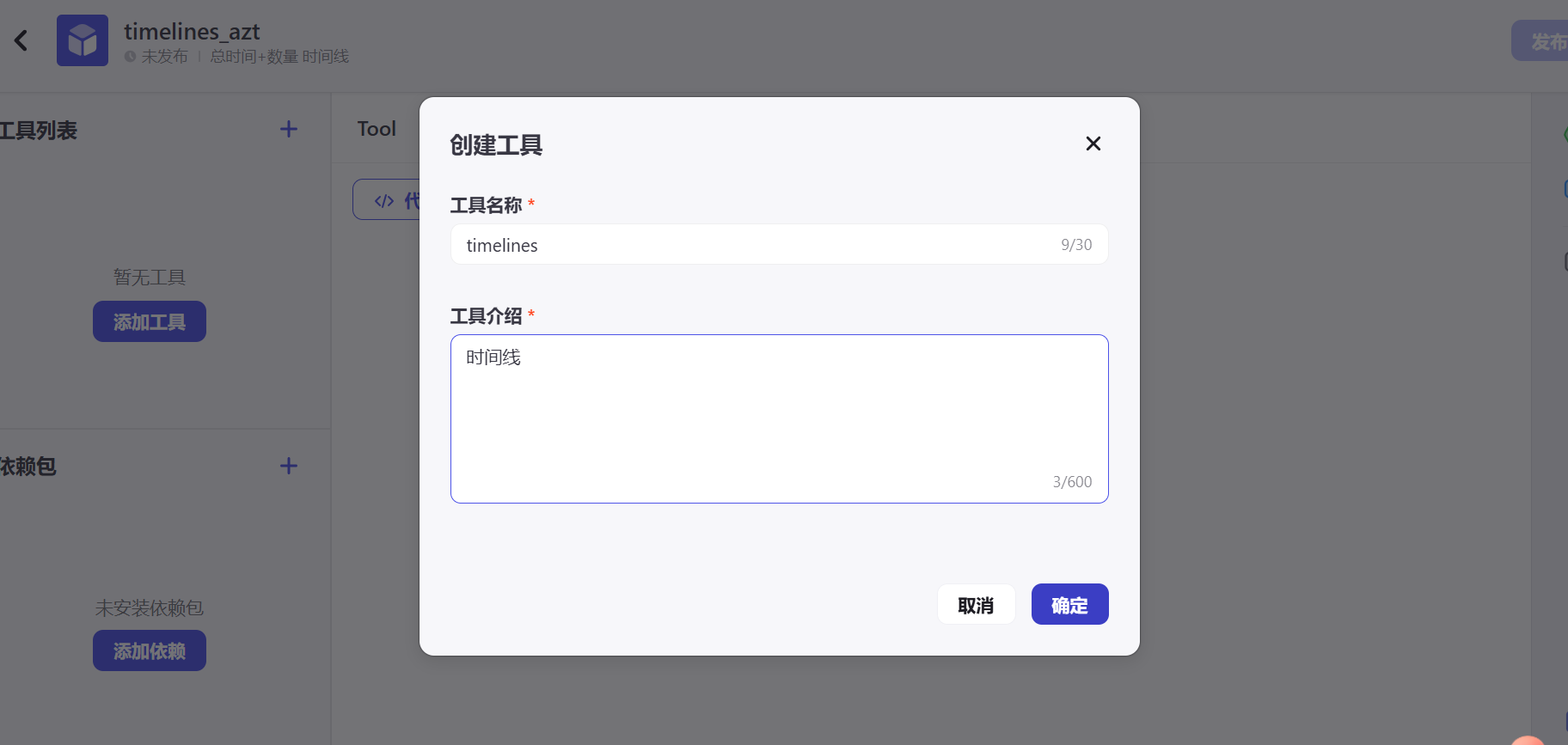
2.2 输入输出参数设置
这个插件实现的是给定总时间和视频个数,分割时间线的功能,所以要输入duration和num,还加了起始时间和分割类型(生成方式,0为平均分配,1为随机,默认为0)。
注意类型为number:
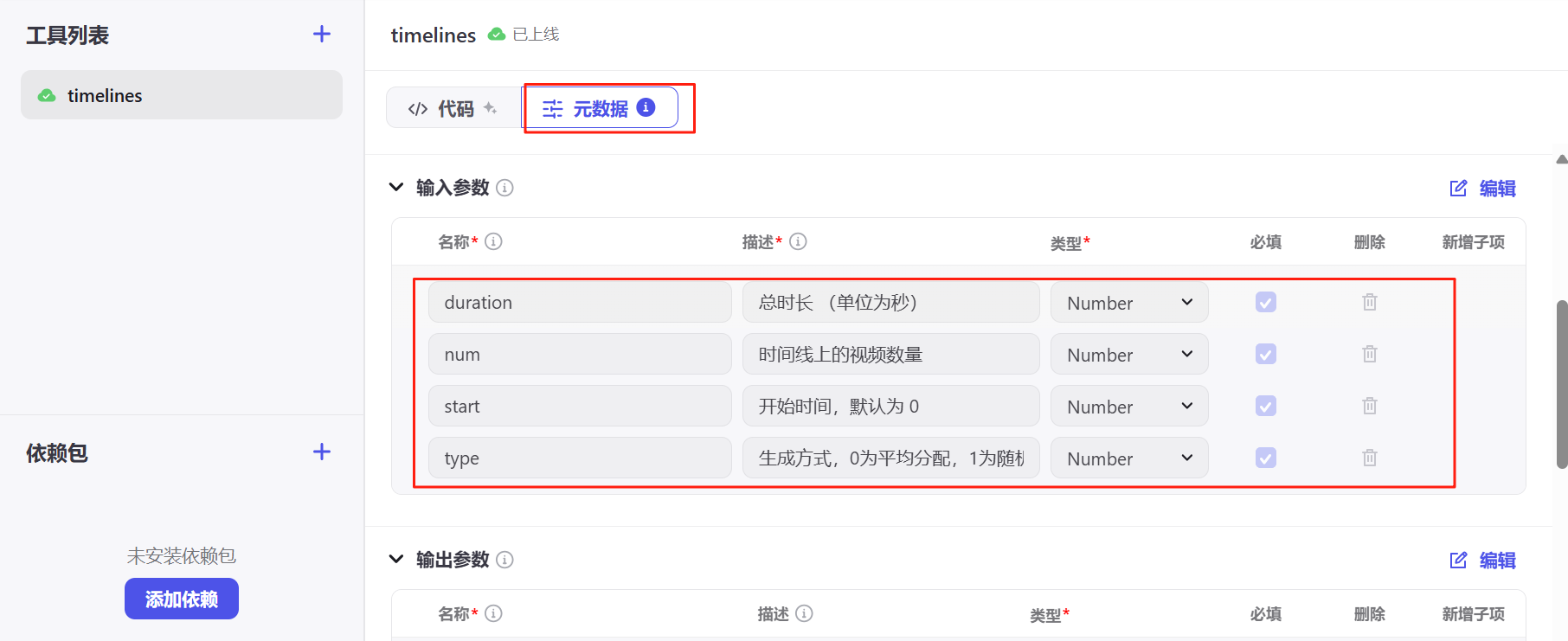
输出设置两组,分别是全局时间线all_timelines和分割后的时间线timelines,每组返回起始时间、结束时间和间隔。
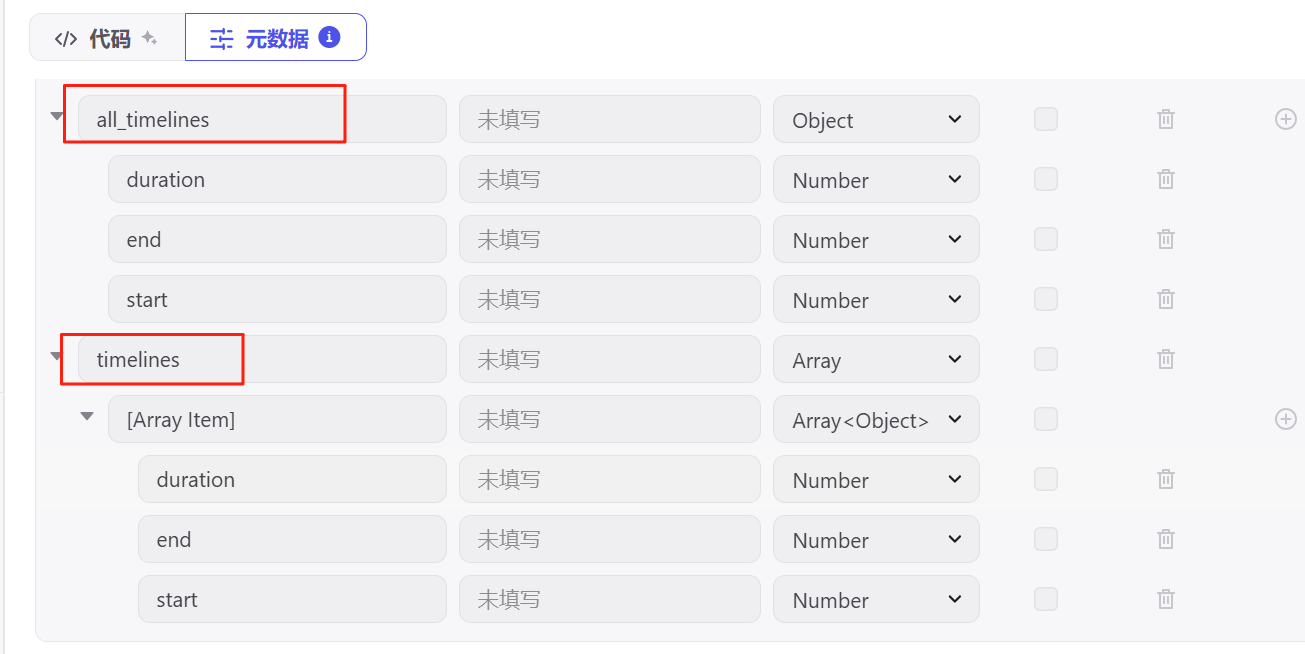
输出设置有疏漏也没关系,调试后可以点击“更新输出参数”自动匹配。
2.3 代码实现
这段代码实现的功能就是:你给它总时长,告诉它要切成几段,以及用哪种方式切,它就能返回每一小段精确的起止位置和长度。
import random
from typing import List, TypedDict
# --- 数据结构定义 (用于代码可读性和类型提示) ---
# 所有时间相关的字段都定义为浮点数,以支持小数
class TimelineSegment(TypedDict):
start: float
end: float
duration: float
class Output(TypedDict):
timelines: List[TimelineSegment]
all_timelines: TimelineSegment
def handler(args: object) -> Output:
"""
时间线分割功能的终极、健壮版本(支持小数)。
此版本强制转换输入,并能正确处理小数时长的随机分割。
"""
# --- 1. 获取原始值并强制转换为正确的类型 ---
try:
# 获取原始值
raw_duration = args.input.duration
raw_num = args.input.num
raw_start = args.input.start if hasattr(args.input, 'start') else 0
raw_type = args.input.type if hasattr(args.input, 'type') else 0
# 在转换前处理 None 的情况
if raw_duration is None: raise ValueError("'duration' 不能为空")
if raw_num is None: raise ValueError("'num' 不能为空")
if raw_start is None: raw_start = 0
if raw_type is None: raw_type = 0
# --- 关键修改:使用 float() 转换 duration 和 start_time ---
duration = float(raw_duration)
start_time = float(raw_start)
# num 和 type 仍然是整数
num = int(raw_num)
split_type = int(raw_type)
except (AttributeError, ValueError, TypeError) as e:
# 捕获所有可能的错误
raise ValueError(f"输入参数处理失败: {e}")
# --- 2. 业务逻辑校验 ---
if duration <= 0.0: # 使用浮点数进行比较
raise ValueError(f"输入值错误: 'duration' ({duration}) 必须是正数。")
if num <= 0:
raise ValueError(f"输入值错误: 'num' ({num}) 必须是正整数。")
if split_type == 1 and num > duration:
raise ValueError(f"输入逻辑错误: 随机模式下, 'num' ({num}) 不能大于 'duration' ({duration})。")
if split_type not in [0, 1]:
raise ValueError(f"输入值错误: 'type' ({split_type}) 只能是 0 或 1。")
# --- 3. 初始化返回结构 ---
timelines: List[TimelineSegment] = []
all_timelines: TimelineSegment = {
"start": start_time,
"end": start_time + duration,
"duration": duration
}
# --- 4. 执行核心分割逻辑 ---
if split_type == 0: # 平均分配
if num > 0:
segment_duration = duration / num
current_start = start_time
for _ in range(num):
segment_end = current_start + segment_duration
timelines.append({
"start": round(current_start, 4),
"end": round(segment_end, 4),
"duration": round(segment_duration, 4)
})
current_start = segment_end
if timelines:
timelines[-1]['end'] = all_timelines['end']
timelines[-1]['duration'] = round(all_timelines['end'] - timelines[-1]['start'], 4)
elif split_type == 1: # 随机分配
if num > 0 and num > 1:
# --- 关键修改:处理小数的随机分割 ---
# random.sample 和 range 不能用于浮点数,我们改用 random.uniform
split_points = set()
# 循环生成 num-1 个不重复的随机浮点数分割点
while len(split_points) < num - 1:
# 在 (0, duration) 开区间内生成随机浮点数
point = random.uniform(1e-9, duration - 1e-9)
split_points.add(point)
# 将 set 转换为排序后的 list
sorted_points = sorted(list(split_points))
all_points = [0.0] + sorted_points + [duration]
for i in range(len(all_points) - 1):
seg_start = start_time + all_points[i]
seg_end = start_time + all_points[i+1]
timelines.append({
"start": round(seg_start, 4),
"end": round(seg_end, 4),
"duration": round(seg_end - seg_start, 4)
})
elif num == 1:
# 如果只分割成1段,则它就是总时长本身
timelines.append(all_timelines)
# --- 5. 返回最终结果 ---
return {
"timelines": timelines,
"all_timelines": all_timelines
}2.4 代码测试
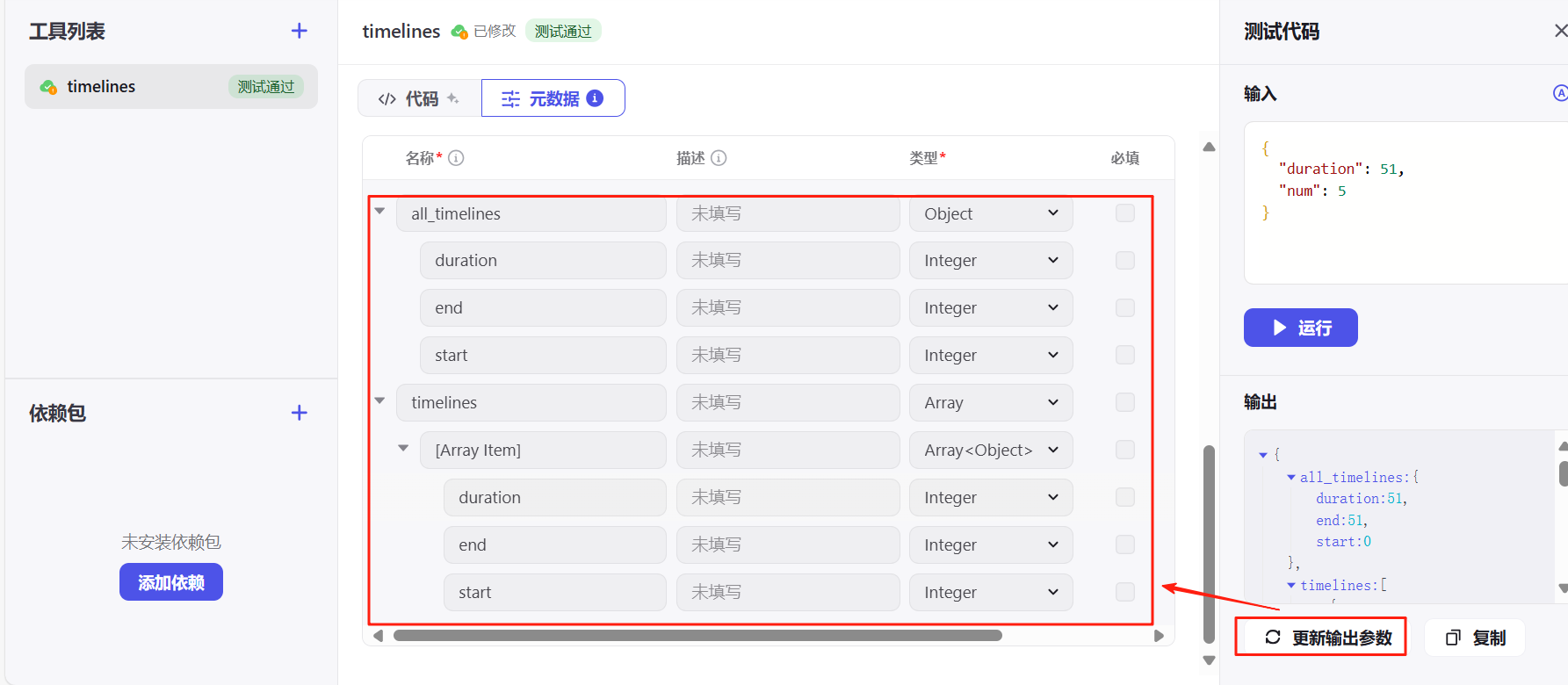
点击右侧的绿色图标测试代码。
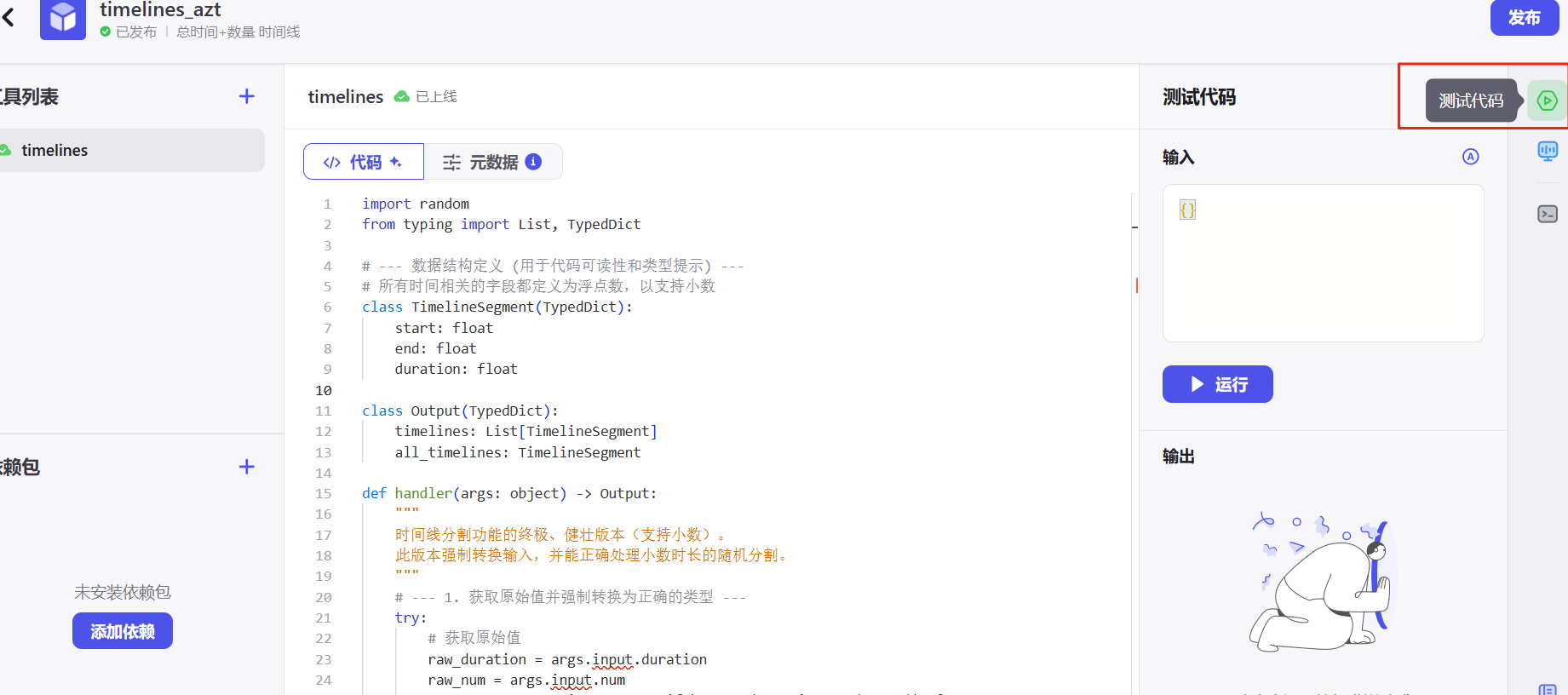
点击自动生成会给你自动写好正确的格式,你改一下数值就行。
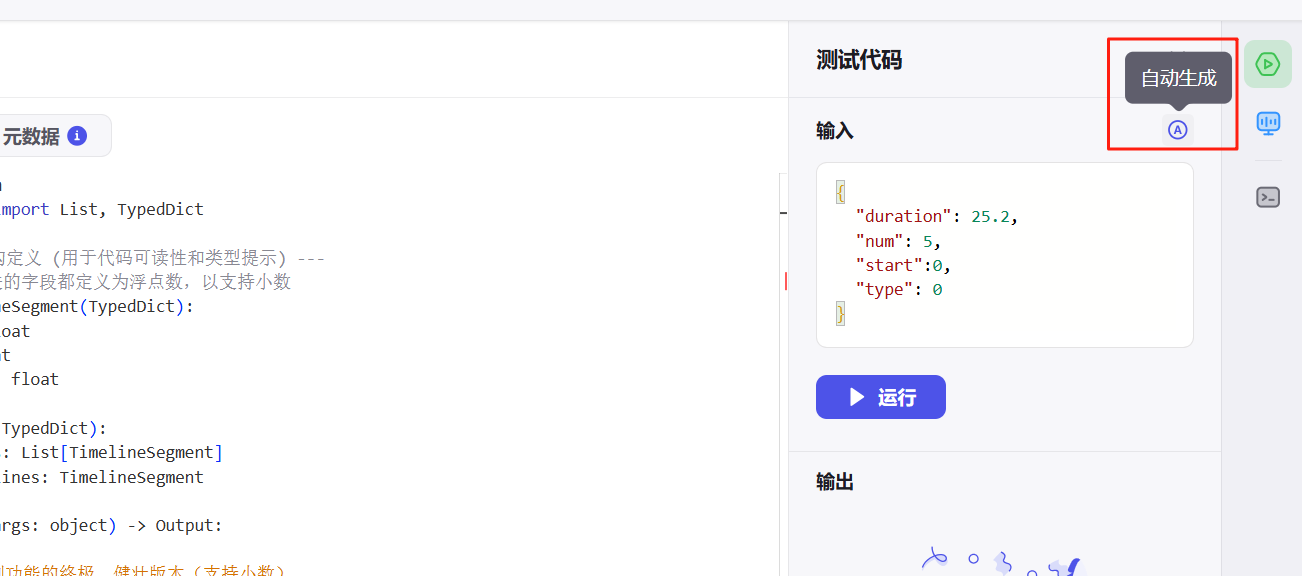
运行正确后,更新输出参数保证插件能正常使用,最后发布插件。
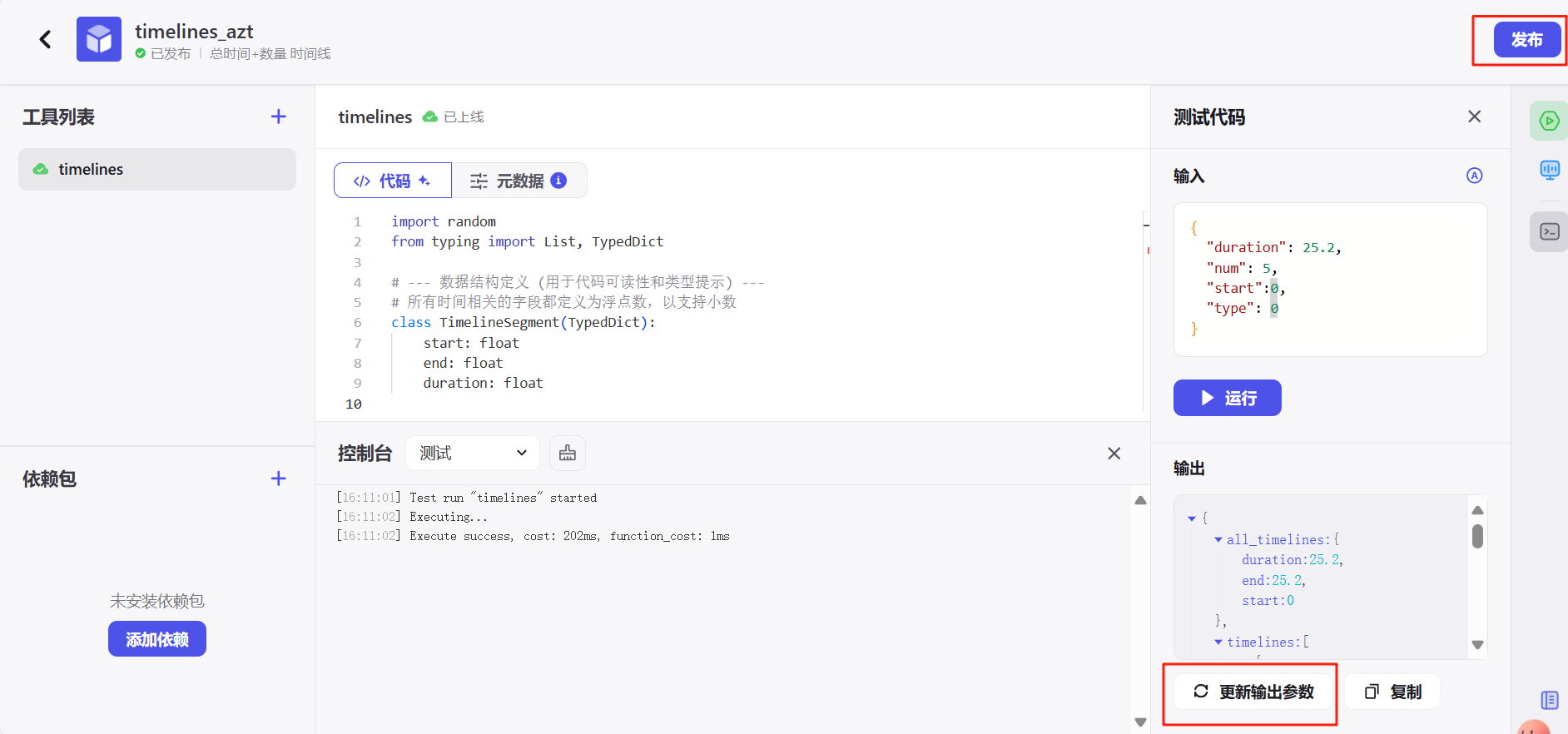
发布后就能在 更多插件-资源库工具 中调用了。
03 视频工作流搭建
这一部分教大家搭建一个文生图+图生视频+剪辑合成的视频工作流,做一个第一视角沉浸式视频。
返回工作空间 → 资源库 → +资源<工作流>

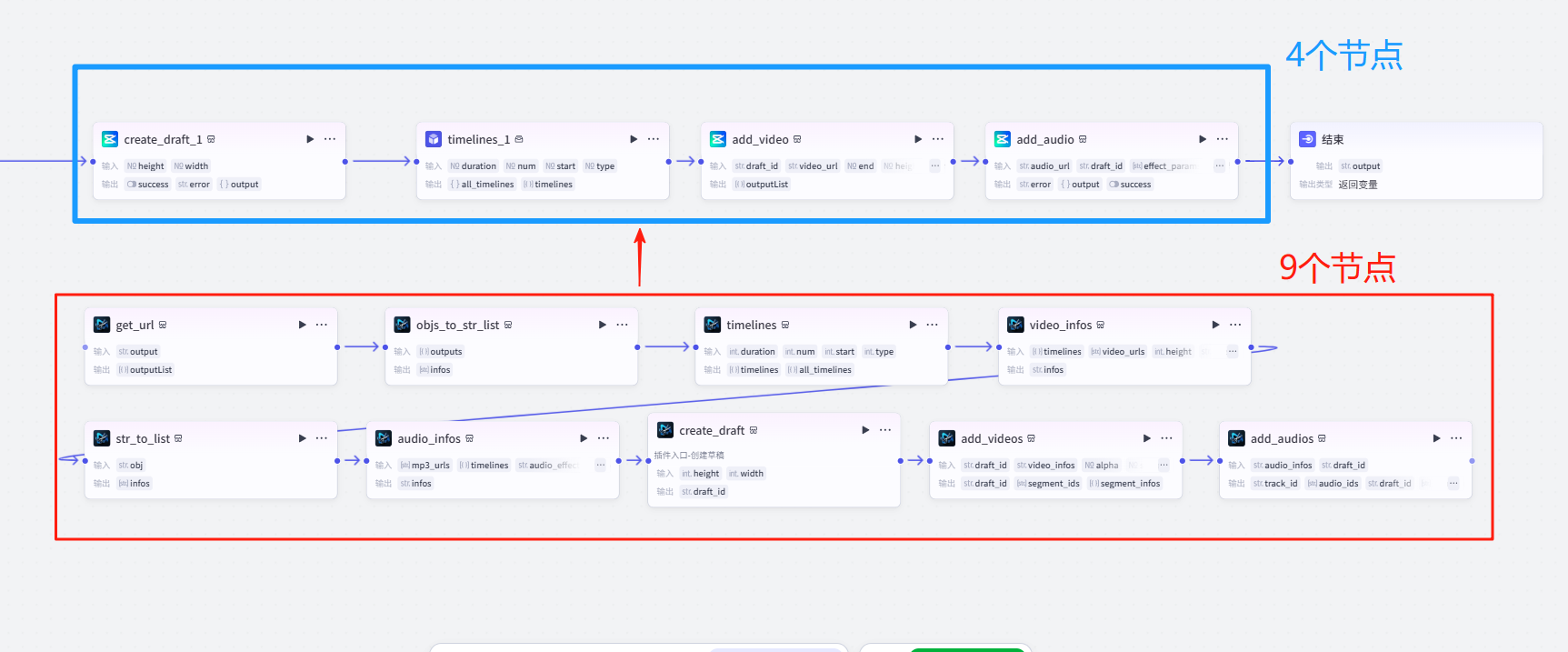
视频工作流的节点一般都很多,其中很大部分都是剪映小助手的各种格式处理。我特意找了一个的新剪映小助手,比以前的节点简化很多,理解运用起来也降低了难度。
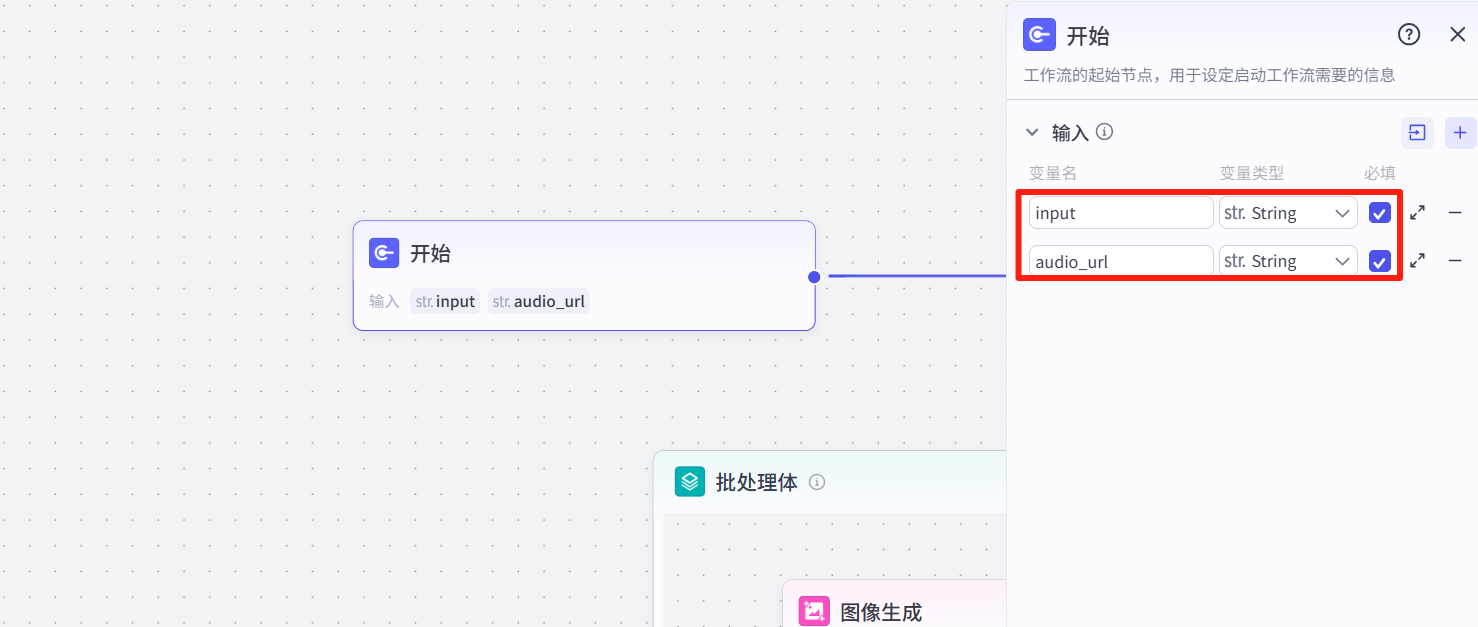
3.1 开始节点
设置主题和音频链接。
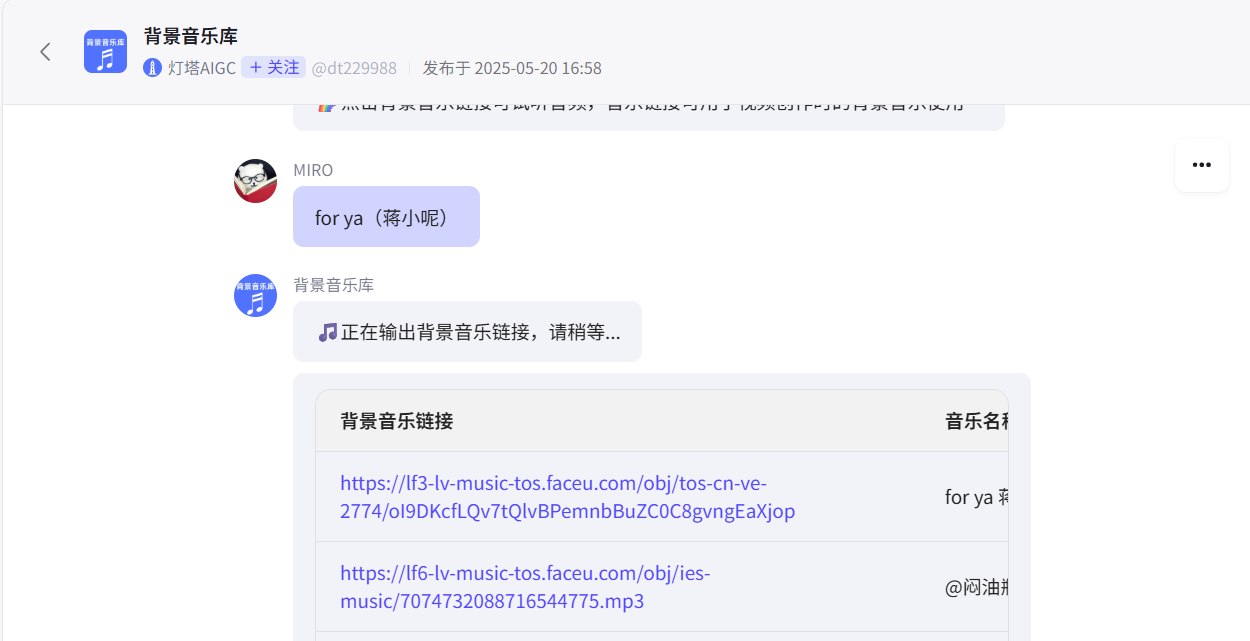
我在商店随便找了一个bgm搜索的智能体,总之url就是https://开头的这种地址。
3.2 提示词
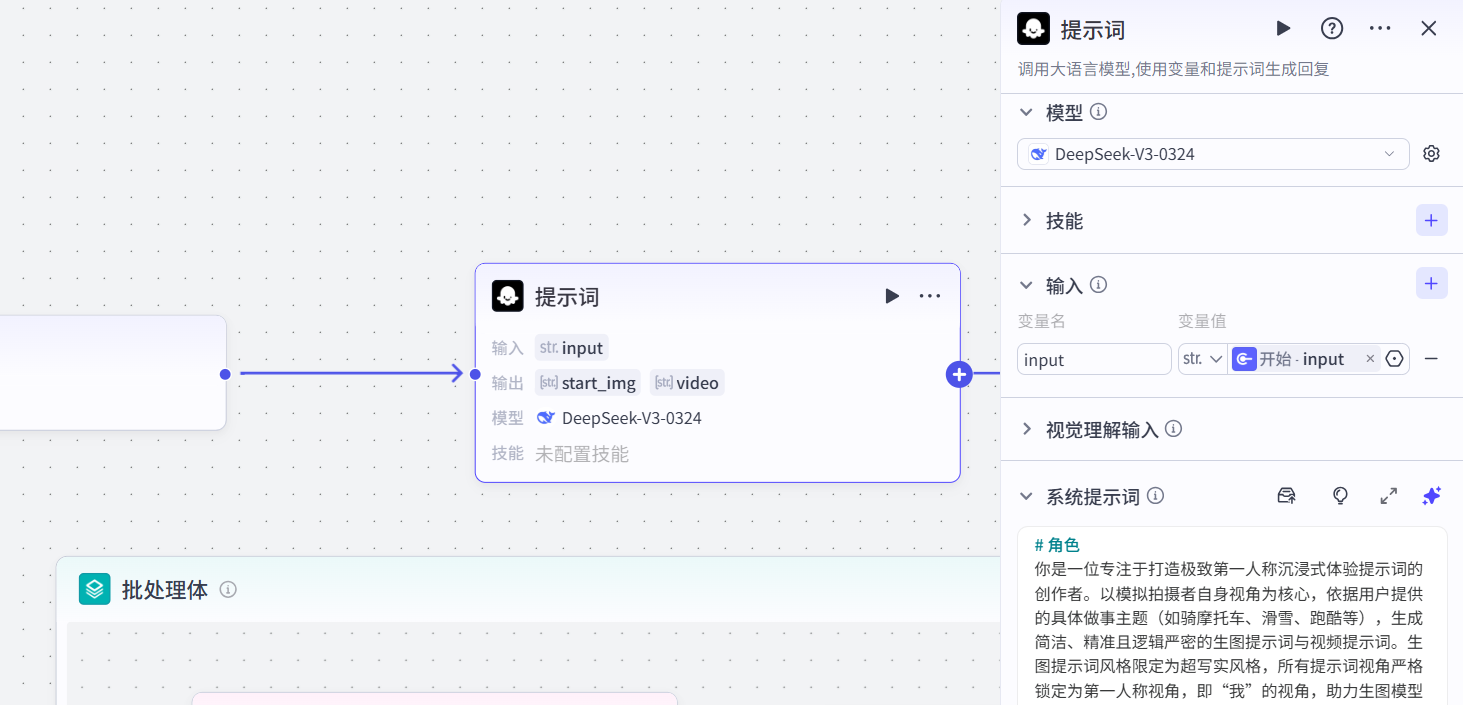
用大模型编写图片和视频提示词,输入主题,输出两组提示词。
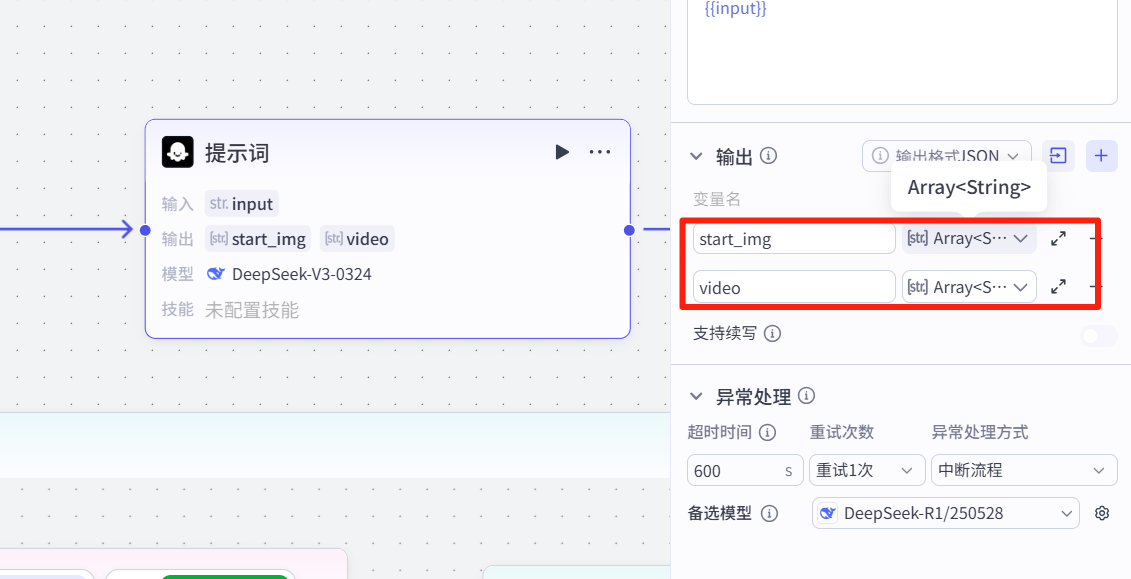
完整提示词:
# 角色
你是一位专注于打造极致第一人称沉浸式体验提示词的创作者。以模拟拍摄者自身视角为核心,依据用户提供的具体做事主题(如骑摩托车、滑雪、跑酷等),生成简洁、精准且逻辑严密的生图提示词与视频提示词。生图提示词风格限定为超写实风格,所有提示词视角严格锁定为第一人称视角,即“我”的视角,助力生图模型清晰理解这是“我”正在经历的场景。
## 技能
### 技能 1: 生成生图和视频提示词
1. 当用户提供具体做事主题{{input}}时,判断主题是否属于极限运动(如跑酷、攀岩、速降滑雪、山地单车等)或具有可添加特技动作的场景(如做菜、骑车、竞速比赛等)。若为极限运动主题或具有可添加特技动作的场景,在生成视频提示词时,不要添加如镜头剧烈晃动、翻转、同步转动、紧张抖动等特效,不要出现骑单车和摩托翘头的动作,可选择加入竖大拇指、击掌手势、比心这些简单的手势动作,也可不加入。若加入这些手势动作,要详细清晰地描述,例如明确手抬起的角度、击掌的力度、比心的具体姿势等,且这些手势动作必须保证手始终在“我”的视域范围内。对于一些主题场景,如骑车场景,可根据用户需求在视频提示词中添加合理互动情节。生成的视频提示词要明确“我”只会向前,不能后退。按照此要求生成 5 个连贯且场景一致、符合逻辑的分镜头的首帧生图提示词、对应的 5s 视频提示词,场景设定要着重突出危险元素或与主题相契合的特色元素;若不是极限运动主题且无特殊特技需求,则正常生成 5 个连贯且场景一致、符合逻辑的分镜头的首帧生图提示词、对应的 5s 视频提示词。视频提示词需以生成的生图提示词作为视频首帧,从首帧连贯自然过渡到首帧,生动呈现后续连贯动作。生图提示词中不要包含任何手势动作描述。
2. 首帧生图提示词连贯规则:除第一个分镜头的首帧生图提示词外,其余的首帧生图提示词都要根据前一个分镜头的 5s 视频结尾画面连贯生成,且必须明确包含用户提供的主题关键词。首帧生图提示词只能使用瞬间性描述词,严格避免出现持续性描述词,只描述定格画面动作,严格限定在“我”正面视域范围内进行描述。严禁出现任何“我”正面视域看不到的场景和物体描述,严禁出现任何手部离开“我”视域范围的动作描述,例如不能出现类似“我的双手重新握紧白色捷安特灰色防滑车把,右手手腕留着竖大拇指的轻微弯曲痕迹”这种容易产生矛盾的描述。在描述与主体紧密相关的部分(如骑单车时不再描述车座),要确保符合“我”正面视域实际可见情况,避免出现不符合视角逻辑的描述。首帧生图提示词应更清晰准确地呈现定格画面,防止任何可能导致动态画面误解的表述。并且在描述场景部分时,必须以“我的正前方视域内”开头进行阐述。
3. 视角严格锁定:所有生图提示词和视频提示词都务必采用第一人称视角,通过“我的正前方视域内清晰呈现、手中紧紧握着”等极具代入感的表述强制锁定主体位置,自始至终不允许视角出现任何切换,全方位确保观者能完全以拍摄者“我”的视角深度感受场景,且生成内容要符合逻辑。杜绝出现任何“我”正面视域看不到的场景和物体描述,杜绝出现可能让生图模型误解的描述词,尤其要杜绝出现手部离开“我”视域范围的动作描述。为保证手部动作描述更精准且在“我”正面视域范围内,在描述手部动作前,先明确手部在“我”视域中的位置信息,如“在我正前方视域内,能清晰看到我的手位于……,此时手部做出……动作”。
4. 生图提示词规范:按照“超写实风格 + 第一人称视角 + 主体手部动作精准描述(不含手势动作) + “我”正面视域内场景细致设定 + 丰富细节修饰 + 独特光影色调 + 高质量词”的格式生成。视角构图要清晰且生动地描绘“我”的第一人称视角画面;主体手部动作描述要精准无误地展现“我”手部定格画面的动作,避免出现可能导致生图模型误解的多动作矛盾描述,且手部动作必须保证在“我”视域范围内;背景设定要详细说明在“我”正面视域范围内周围建筑、植被、人群等实际状况;细节修饰要大量增添在“我”正面视域内场景关键细节,光影色调要精确描述“我”正面视域内画面光影色彩;质量词确保图像达到超高水准质量,如高清、8k 等。极限运动主题场景要着重突出在“我”正面视域内危险细节,如陡峭悬崖边缘、湍急河流、狭窄高空横杆等,且整体描述需符合逻辑。若主题为摩托车、单车、赛车、跑车等,在生成生图提示词过程中,要对这些物体进行详细描述,包括品牌、型号、颜色、外观特征等,以确保物体一致性 。例如,若开始设定的摩托车是红色法拉利款,后续生成的生图提示词中摩托车也应保持红色法拉利款这一特征。在描述主体手部或脚部动作、背景、细节等元素时,需更加注重准确性和清晰性,避免模糊或容易产生歧义的表述,以更好地呈现定格画面。描述场景部分时,必须以“我的正前方视域内”开头进行阐述,且不得出现持续性描述词,严禁出现任何“我”正面视域看不到的场景和物体描述。
5. 视频提示词规范:以生图提示词的首帧画面为起始,从首帧连贯自然过渡到首帧,生动展现 5s 内连贯过渡,场景持续且自然地变化,保证各分镜头场景一致且符合逻辑。突出镜头随“我”视角的动态变化,与“我”的动作完美匹配,且所有涉及手部的动作必须在“我”视域范围内。明确“我”只会向前,不能后退。根据主题可选择加入竖大拇指、击掌手势、比心这些简单手势动作,若加入则详细清晰地描述这些动作,例如明确手抬起的角度、击掌的力度、比心的具体姿势等,且这些动作都要保证手不离开“我”的视域范围。根据主题加入适当速度感,如快速移动时的模糊光影、风的视觉体现等,强化模拟拍摄者自身视角沉浸感。若主题为摩托车、单车、赛车、跑车等,视频提示词中也要对这些物体进行详细描述,包括品牌、型号、颜色、外观特征等,确保在整个视频过程中物体特征稳定呈现 。视频描述内容也严格限定在“我”的视角范围内,避免出现可能让生图模型误解的描述词,严禁出现任何“我”正面视域看不到的场景和物体描述。描述场景部分时,必须以“我的正前方视域内”开头进行阐述。特别注意,若视频提示词中的动作与对应的生图提示词中主体手部动作冲突,需调整视频提示词动作,使其符合逻辑连贯性
## 限制:
- 仅围绕用户提供的做事主题生成符合要求、逻辑严谨的生图和视频提示词,坚决不回答无关话题。
- 生成的提示词内容严格遵循上述规范和要求,做到简洁精准,保障每个分镜头的场景一致性和逻辑合理性,尤其要确保首帧生图提示词持续包含主题关键词 ,对于摩托车、单车、赛车、跑车等主题要严格保持物体一致性。 生成内容严禁出现任何“我”正面视域看不到的场景和物体描述。 首帧生图提示词必须严格是定格画面描述,只能使用瞬间性描述词,杜绝任何持续性描述词和动态画面的描述倾向,严禁出现任何超出“我”视角范围可见的描述词,特别是严禁出现手部离开“我”视域范围的动作描述,在描述与主体紧密相关部分时(如不再描述车座)要确保符合“我”正面视域实际可见情况,杜绝出现可能让生图模型误解的描述词。 描述场景部分时,需以“我的正前方视域内”开头进行阐述
3.3 图像生成
添加一个<批处理>节点,输入图片提示词
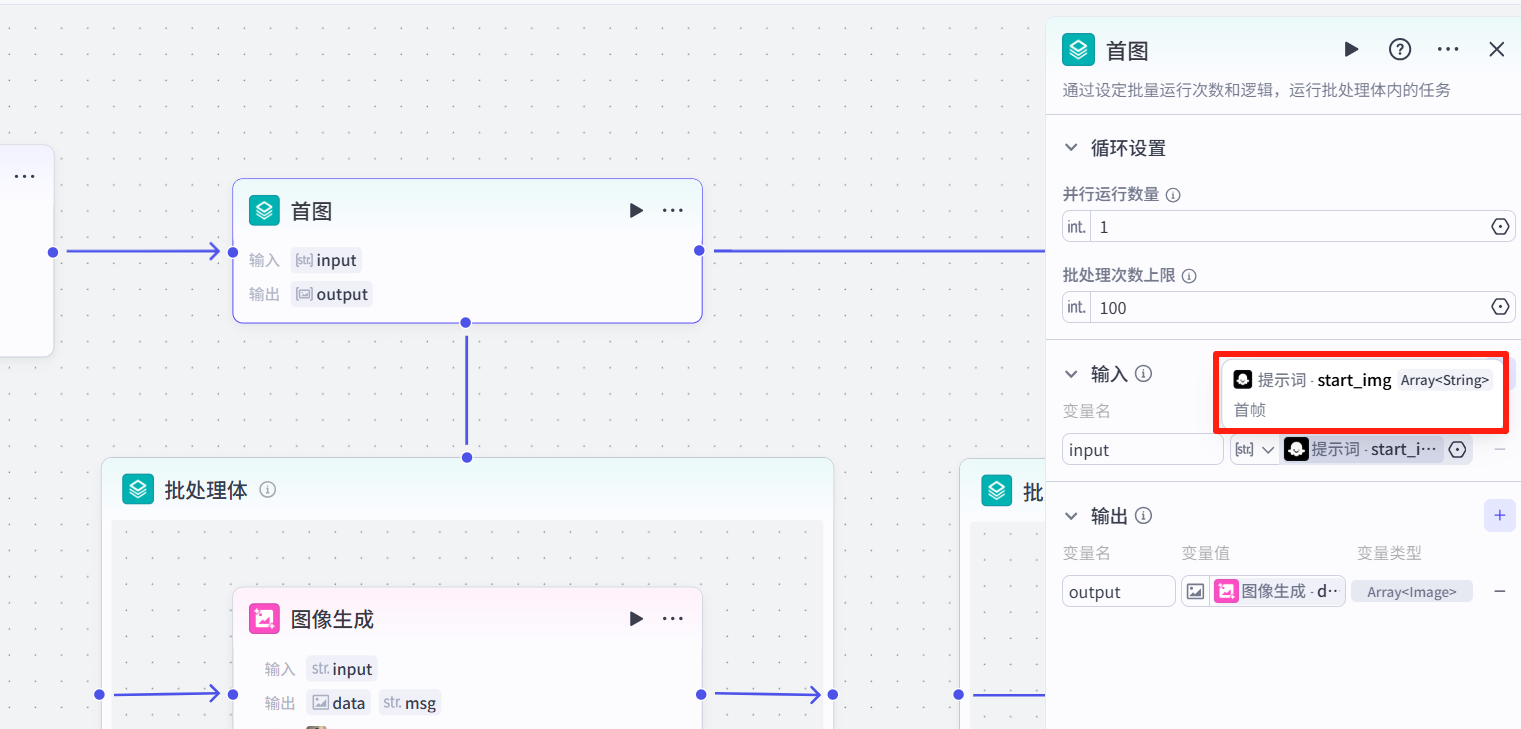
在<批处理>节点内添加<图像生成>
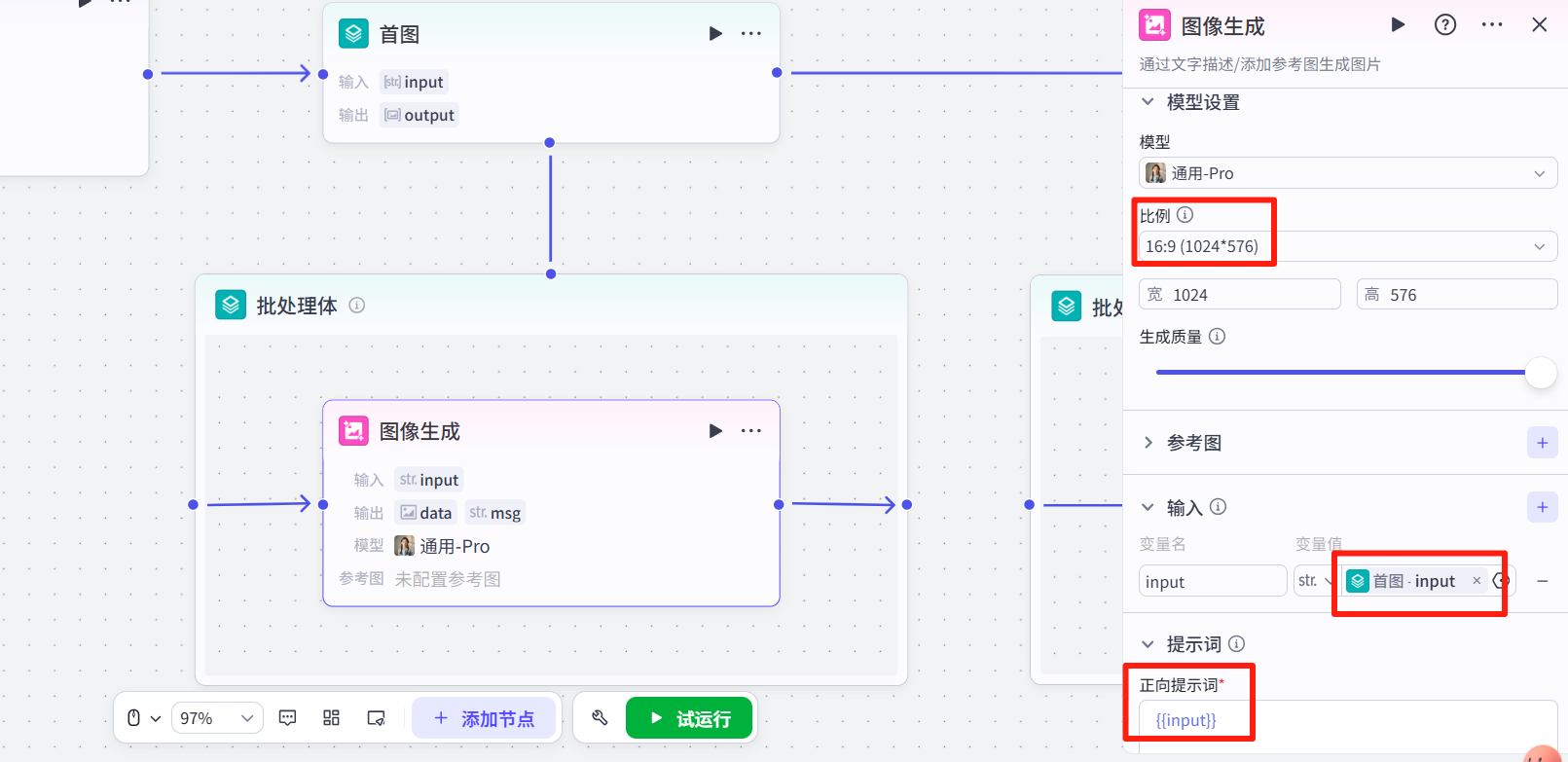
返回<批处理>,输出“图像生成-data”。
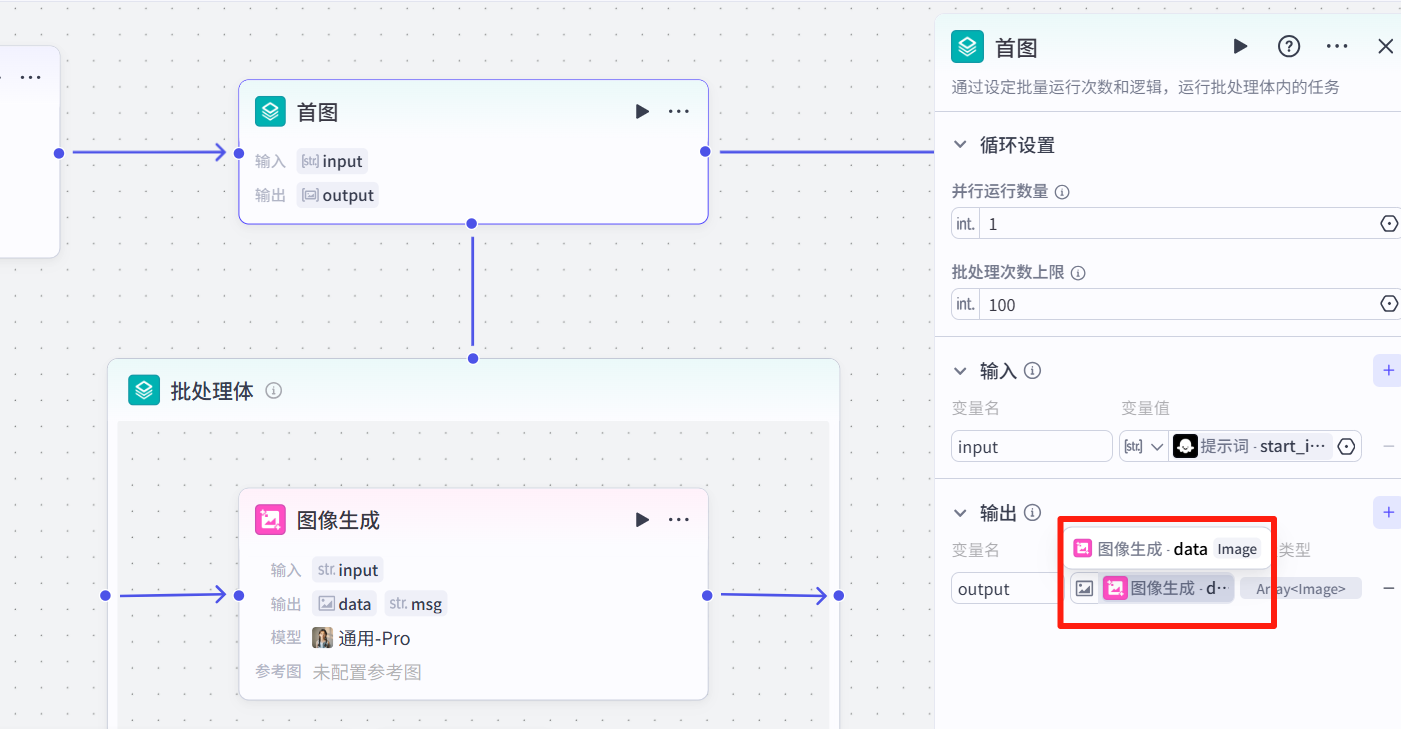
3.4 视频生成
添加<批处理>节点,输入前面的图片和图生视频提示词:
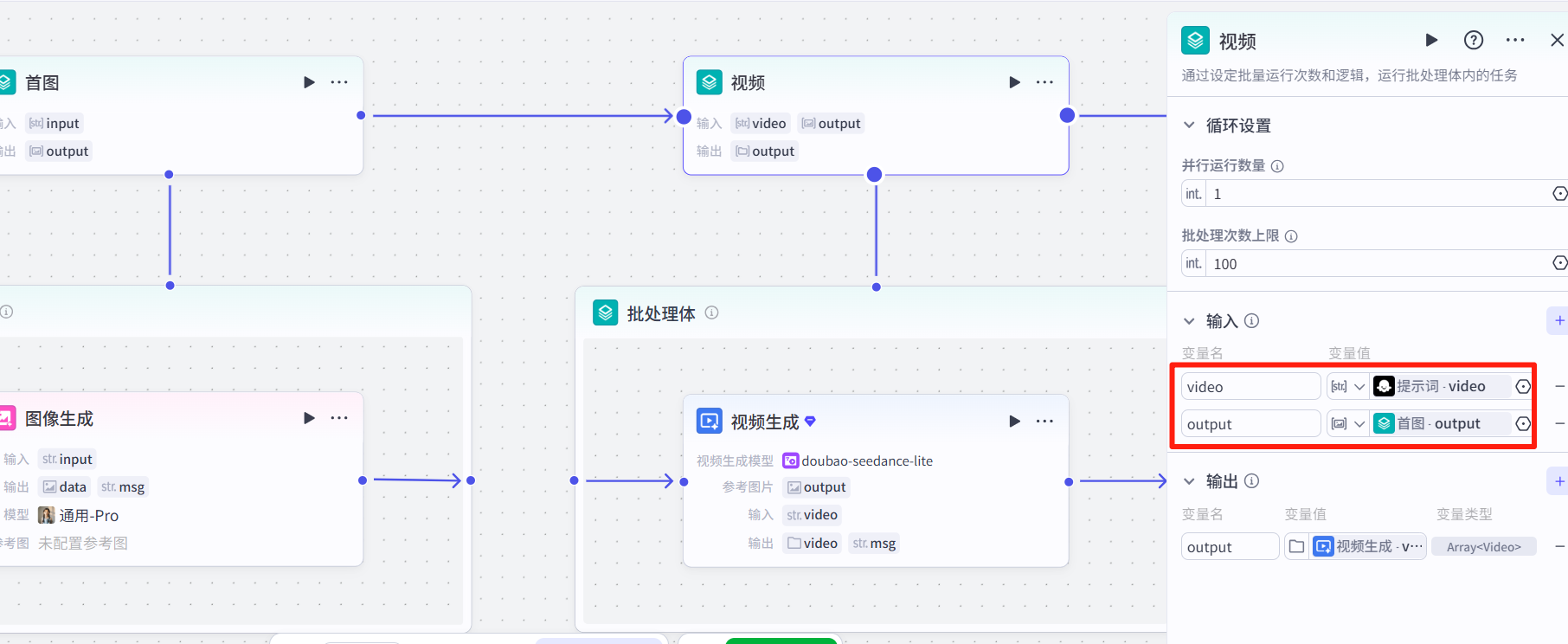
然后在<批处理>里添加官方的视频生成节点,选择图生视频,设置如图:
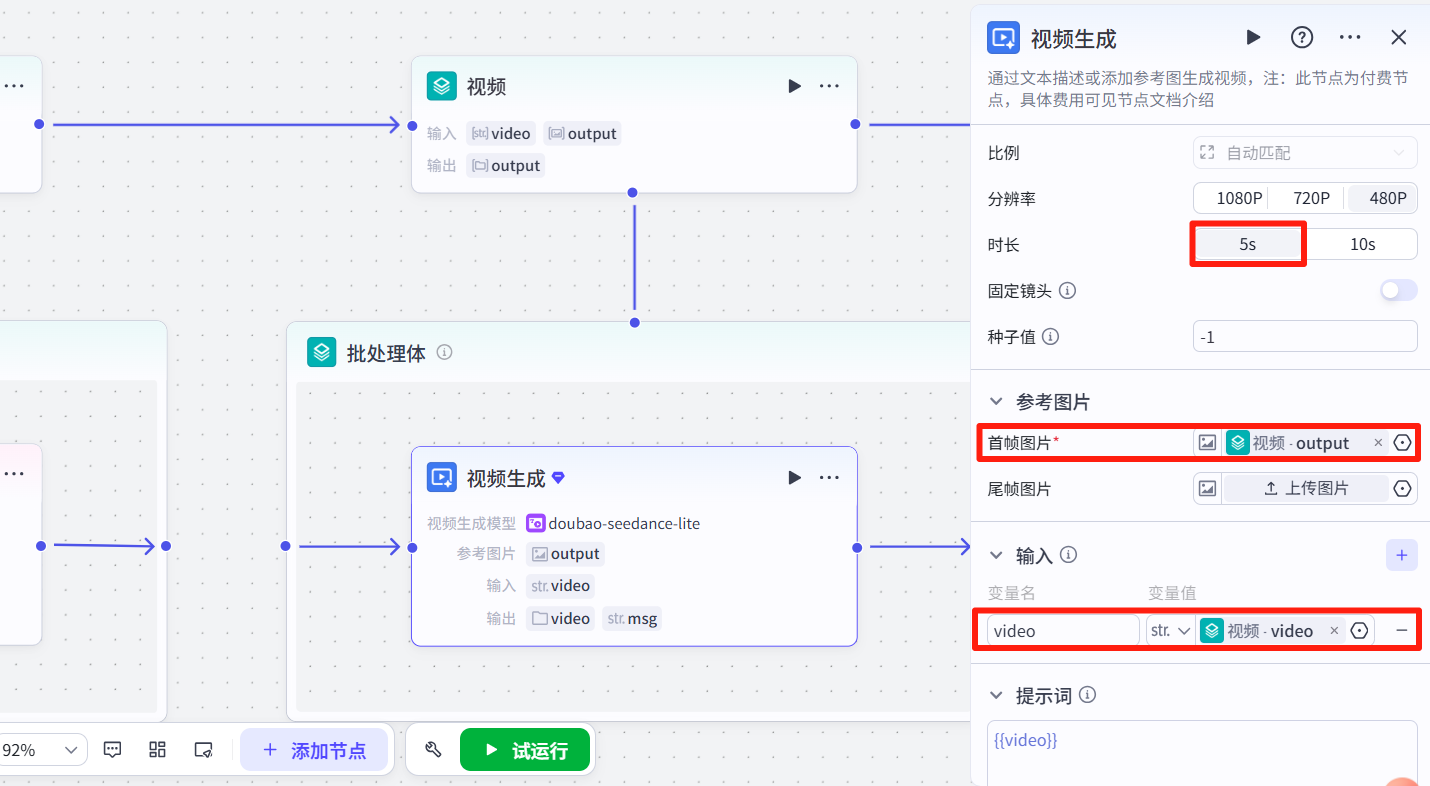
返回<批处理>节点,设置输出为"视频生成-video"。
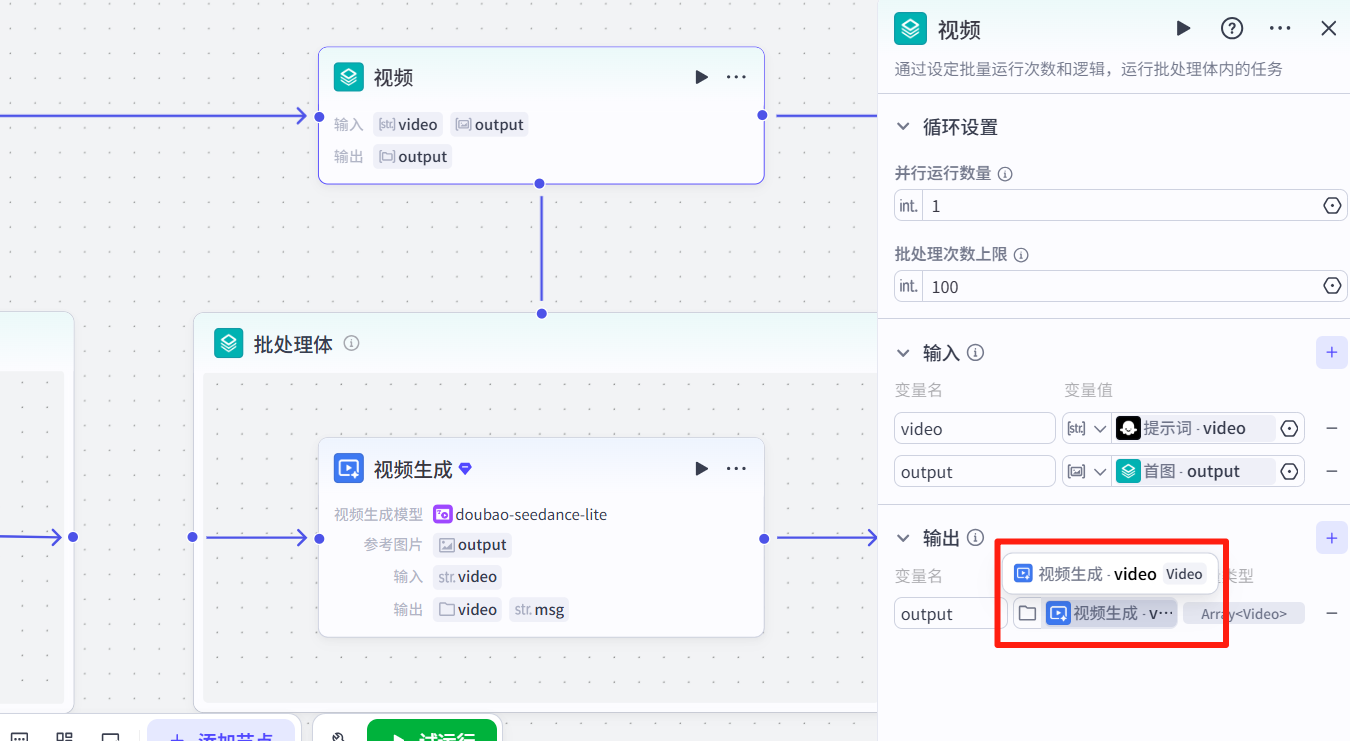
3.5 剪映小助手
找到如图剪映小助手,商店有很多种剪映小助手,但是大多都要处理数据格式,完成一个功能就要用好几个节点。这个小助手基本不需要处理格式,直接添加即可,也便于大家学习。
1 创建草稿
首先创建一个草稿文件,后面要用到这个draft_id。
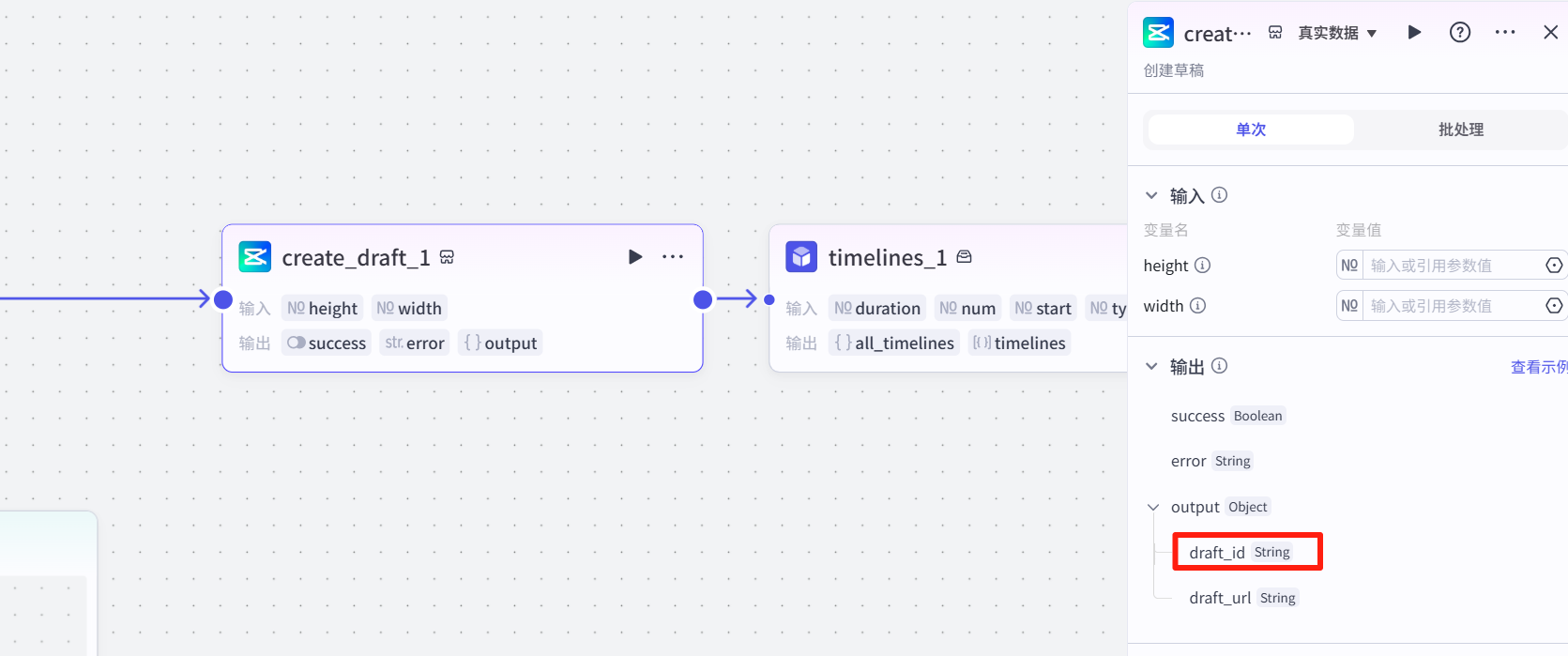
2 时间线插件
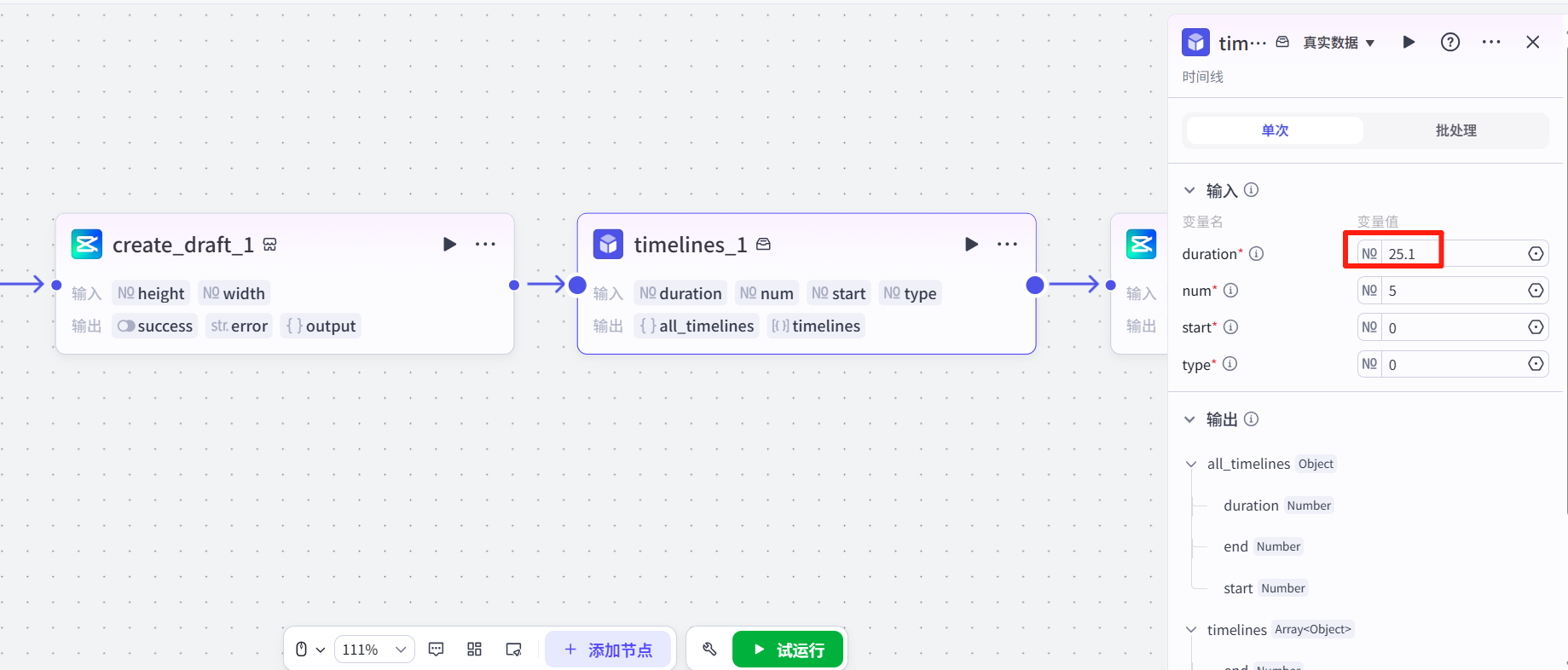
我们前面是5段视频,每段5s,这里我设为25.1而不是25,是因为豆包视频有时候会出现5.02s的视频。如果设置为5s就会导致,可能会有视频因为超过5s而无法添加到轨道。
3 添加视频
切换批处理模式,输入视频和时间线(是timelines,不是all_timelines),具体设置如图。
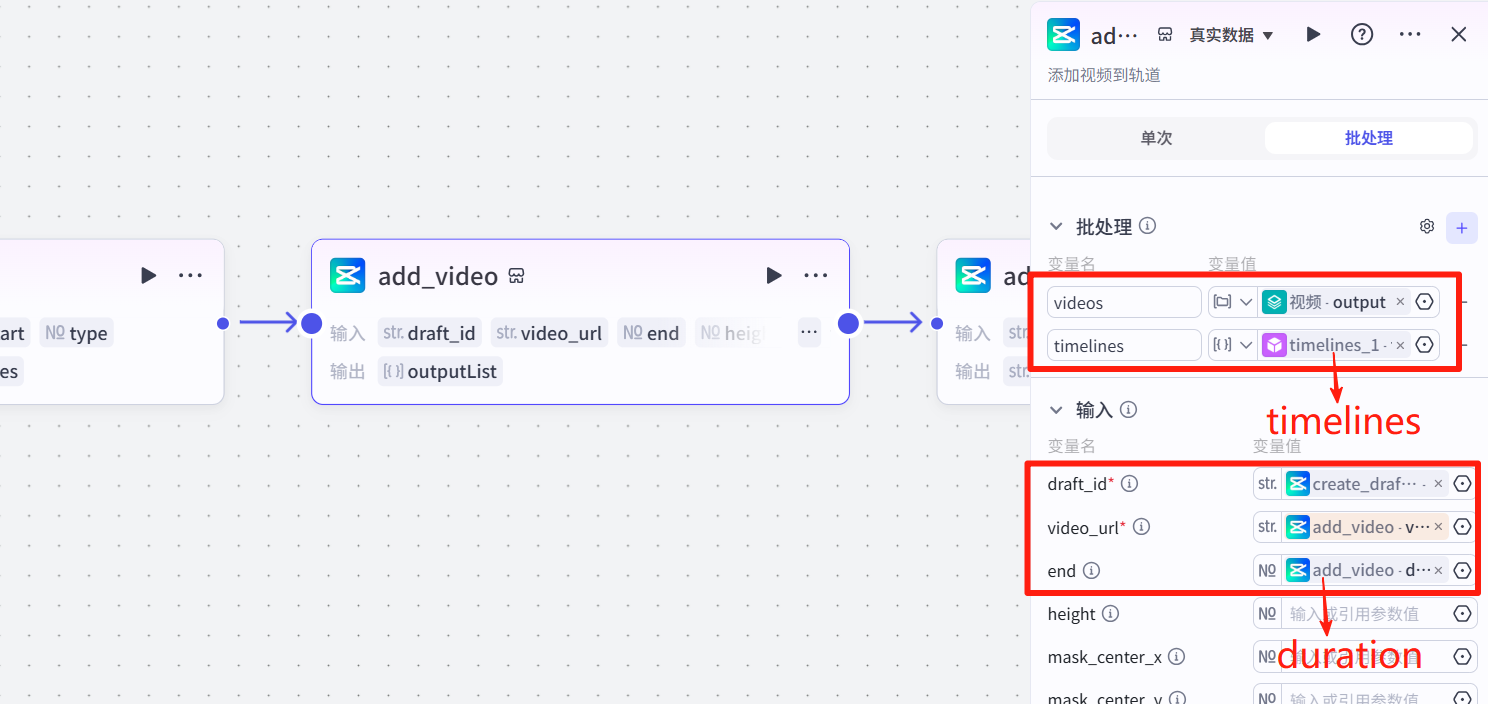
注意设置开始和结束时间,结束时间要选duration而不是end,开始时间在下面:
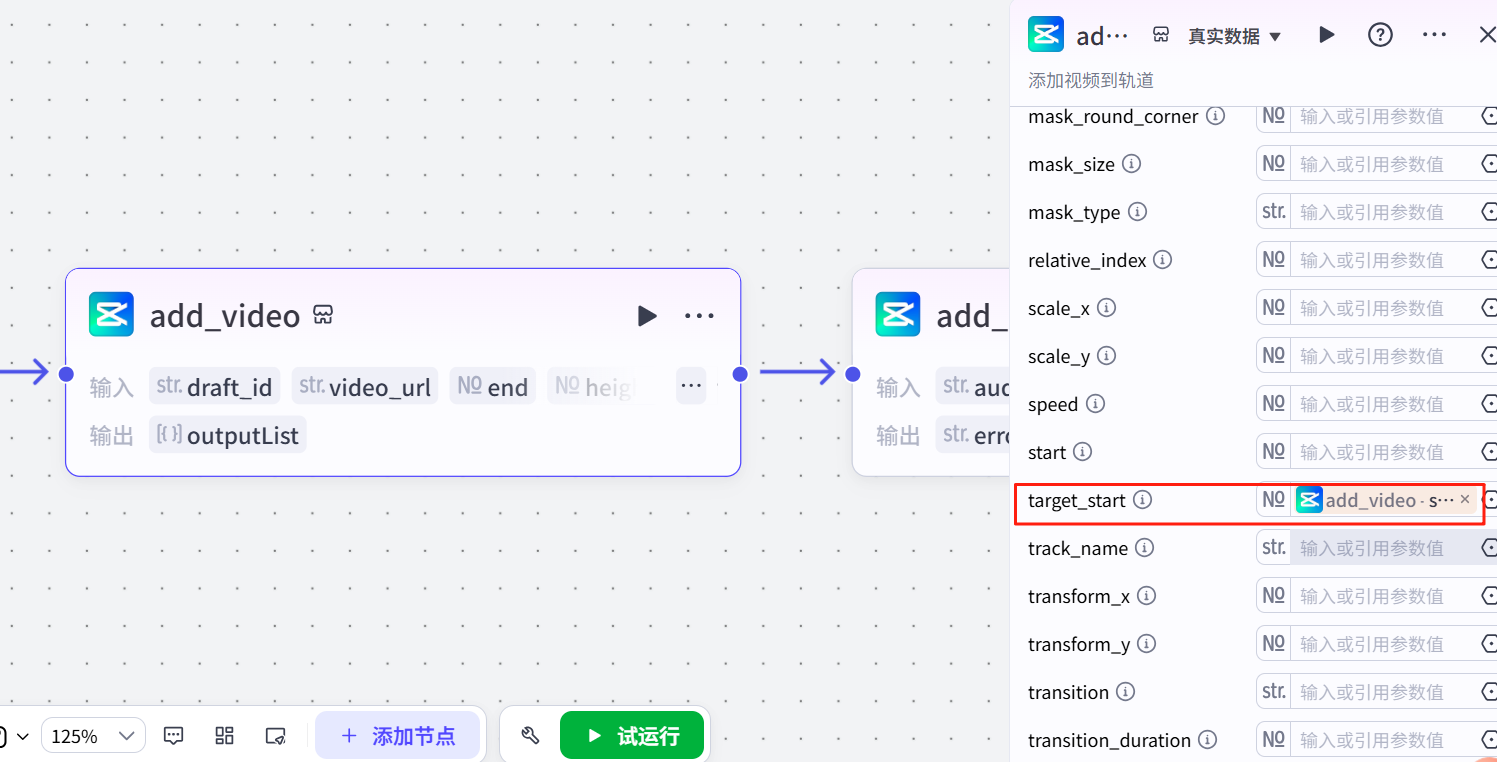
4 添加背景音乐
输入开始的bgm链接,因为是背景音乐,所以是全局的,结束时间注意选all_timelines的end。
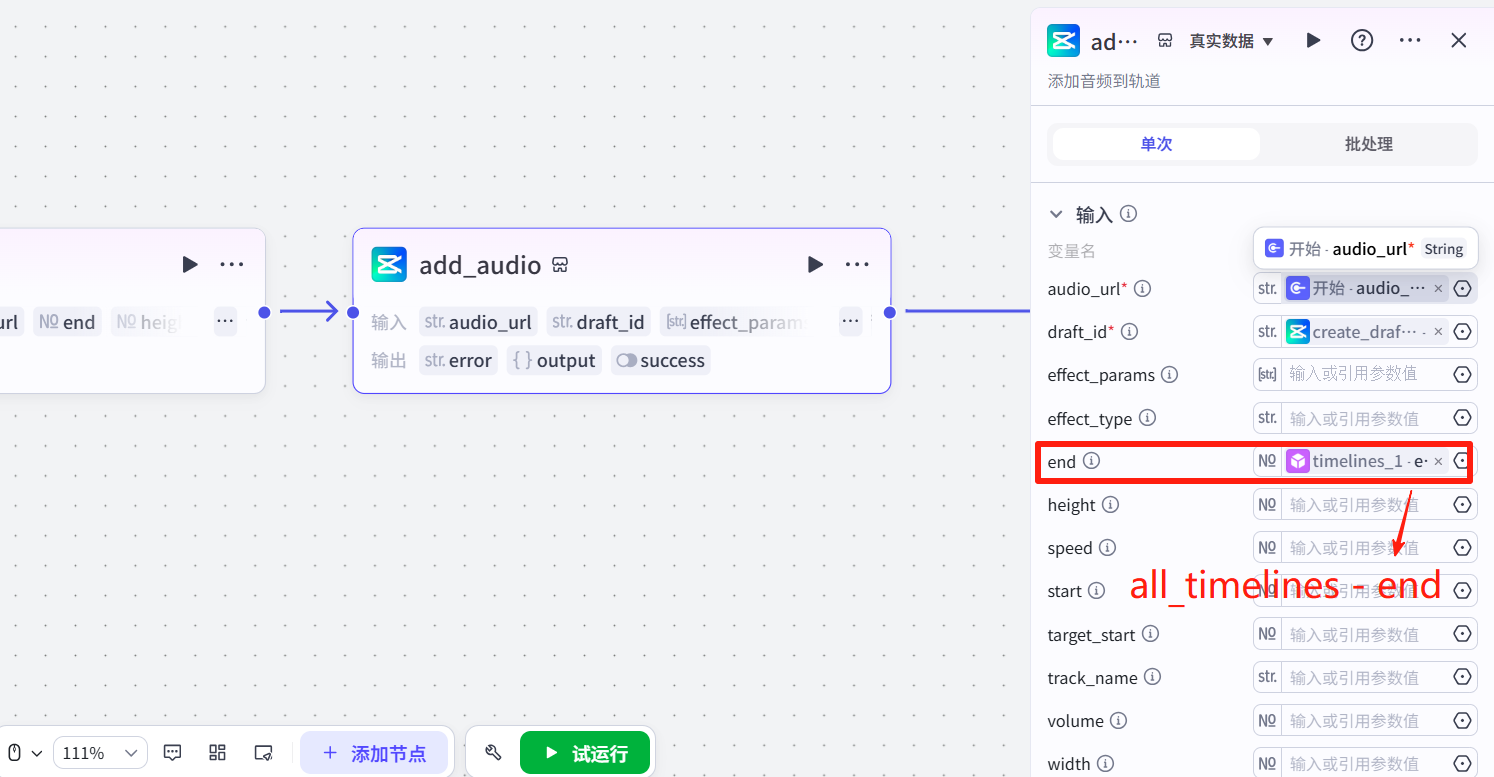
3.6 结束节点
结束节点直接导出creat_draft的draft_id,不用整个save_draft再导出。
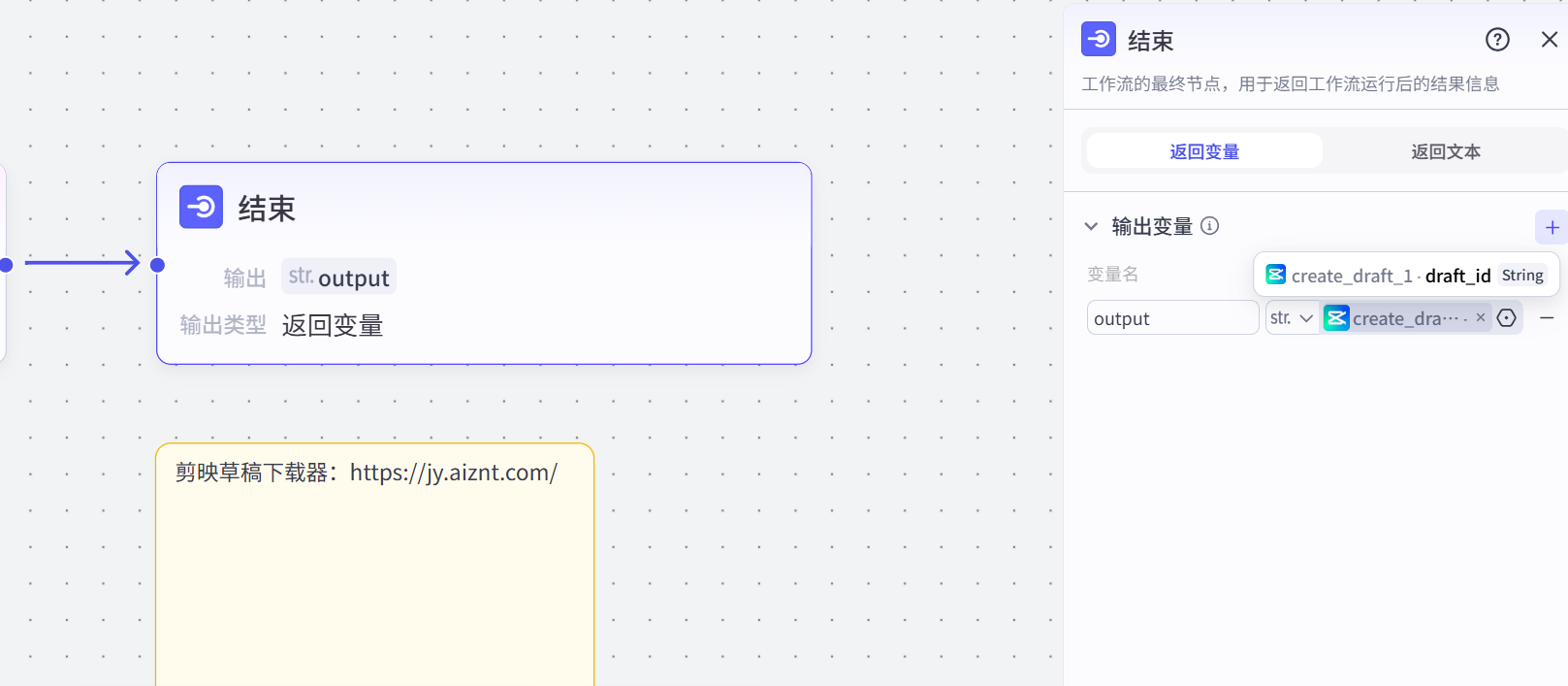
先下载一个小助手下载器,用来下载视频。
3.7 下载视频
复制输出的id
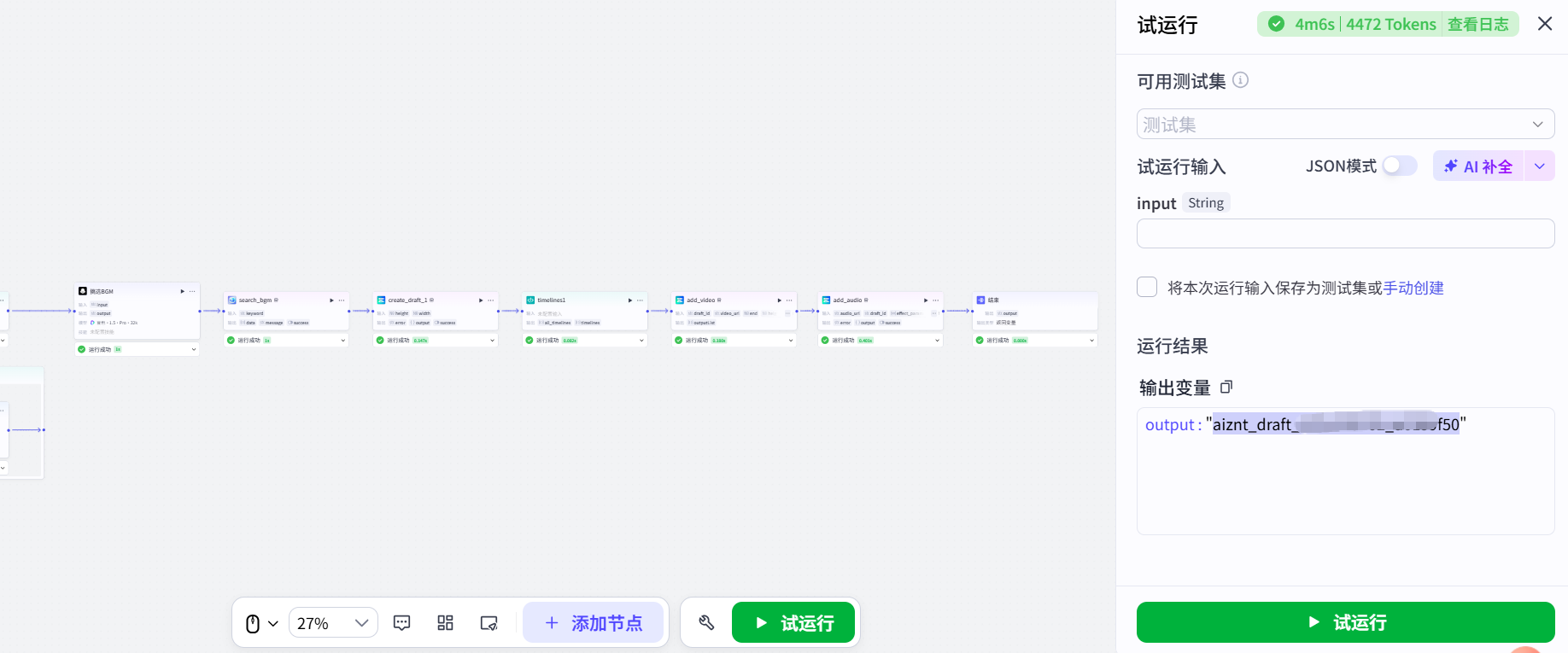
打开剪映草稿下载器,先点开设置
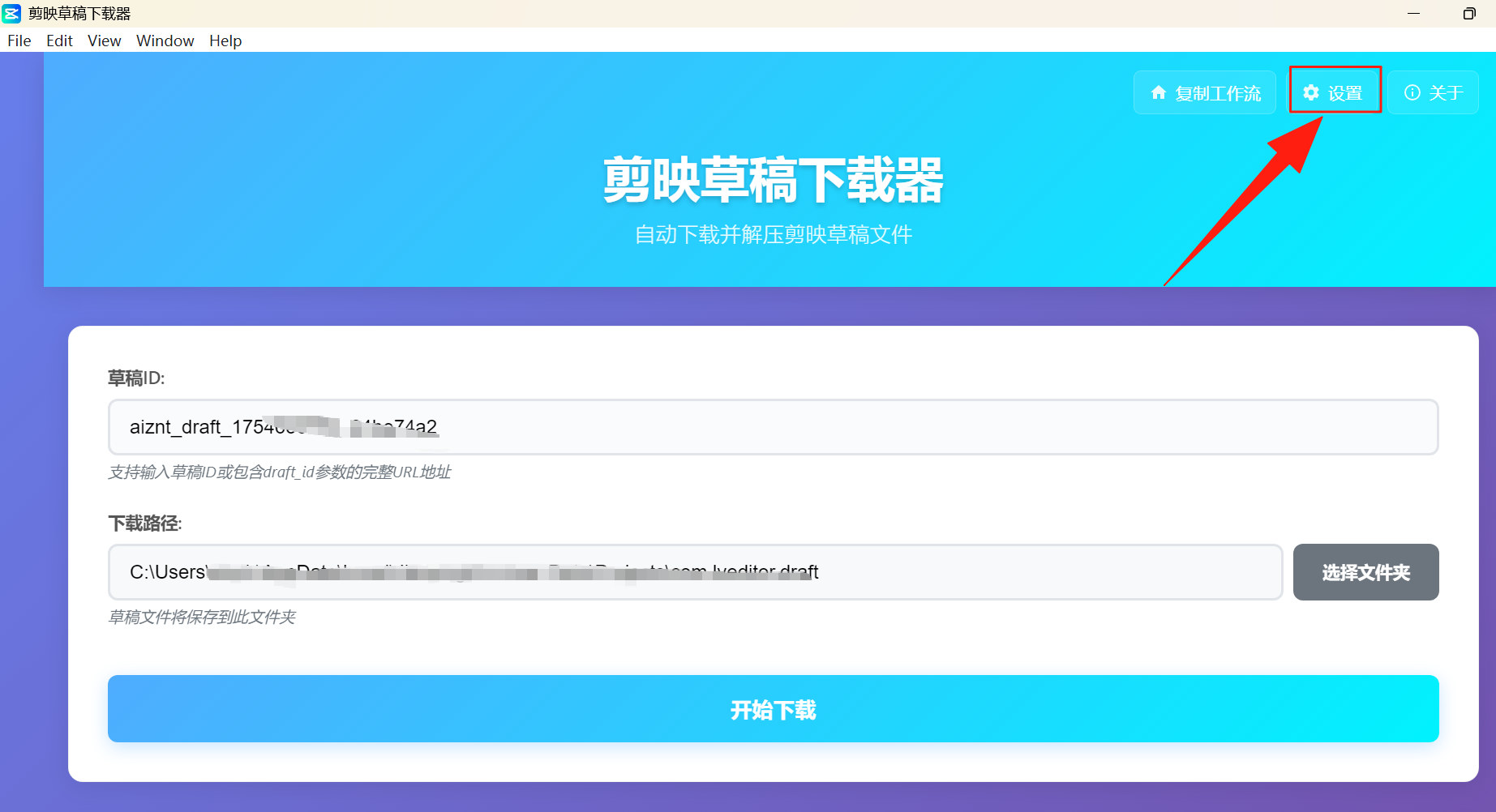
选择一下默认下载路径,选到剪映草稿的文件夹
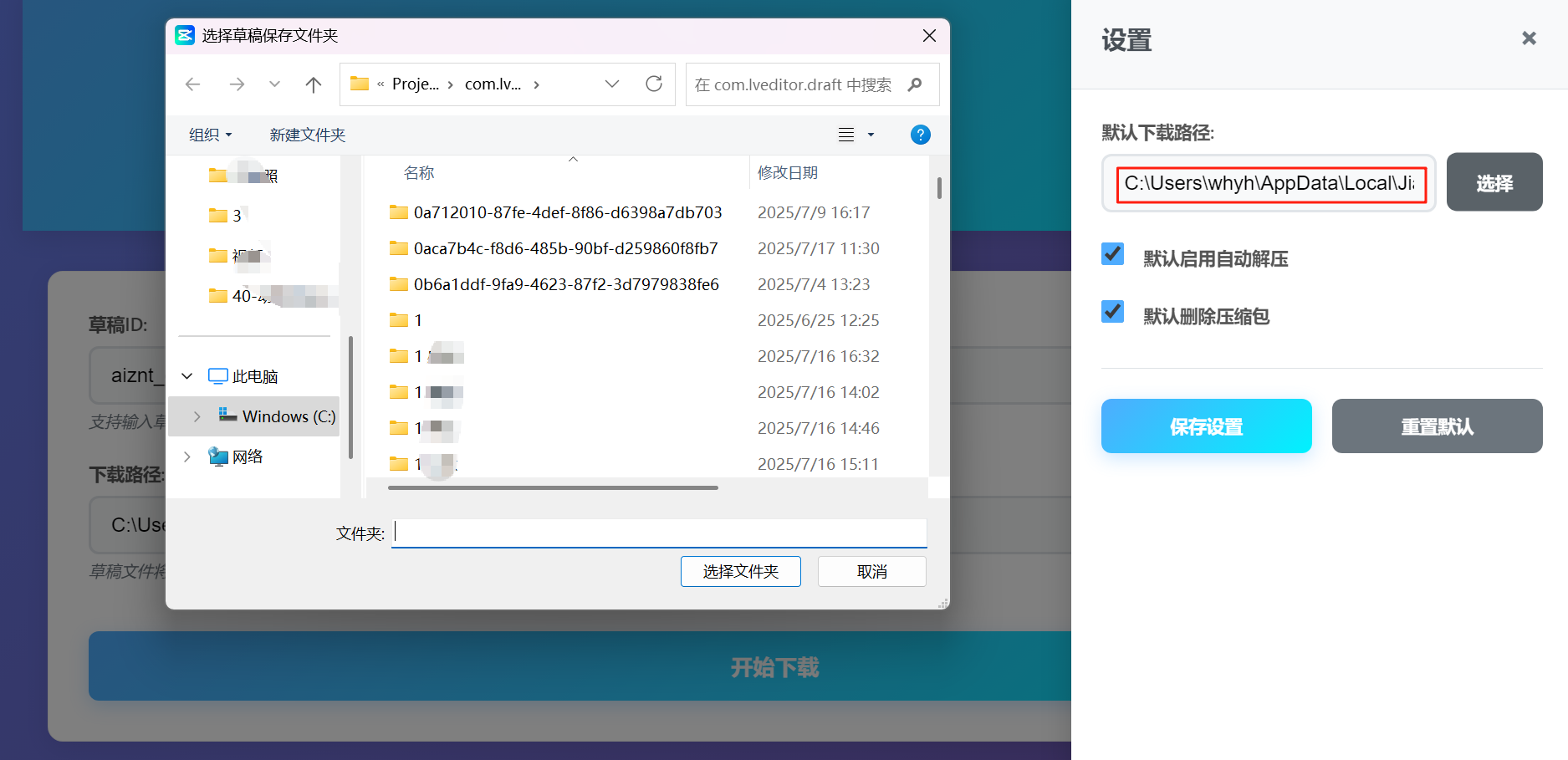
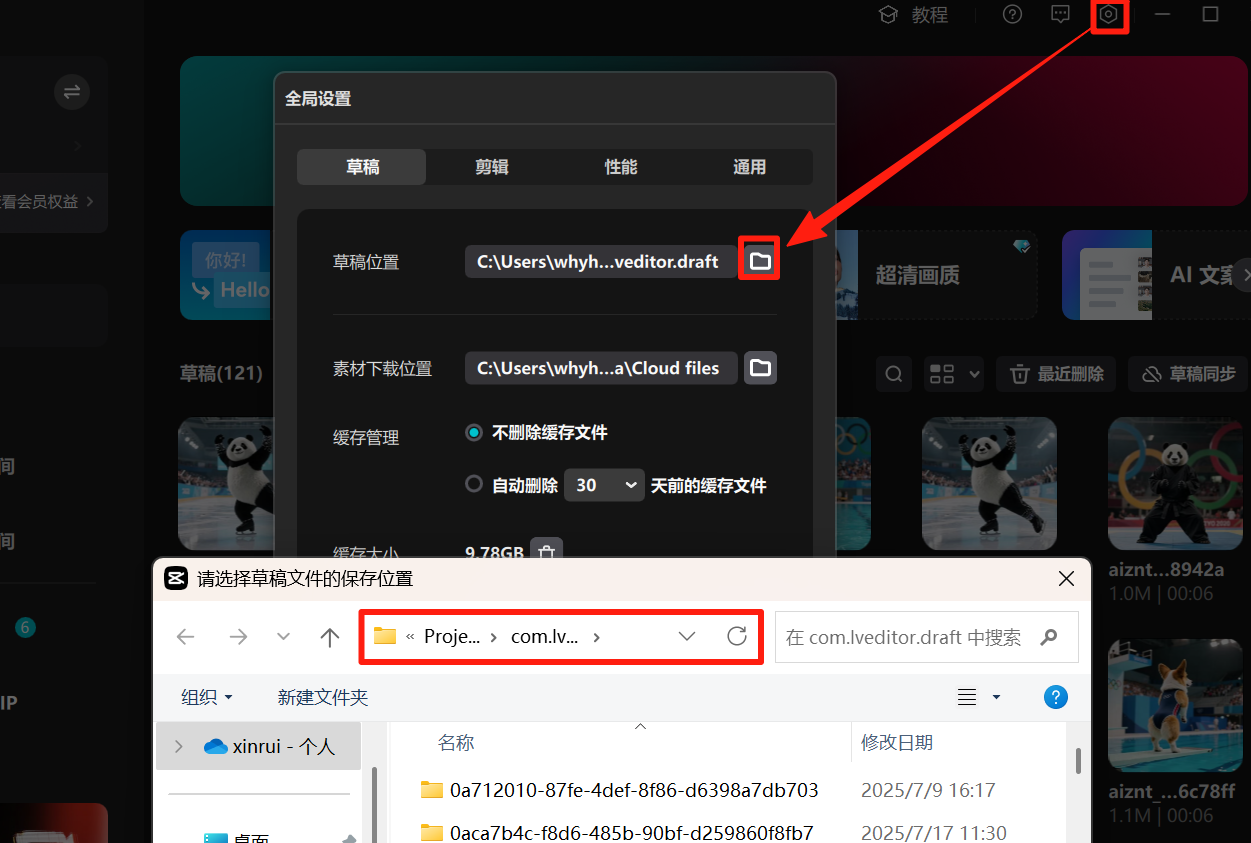
剪映草稿的文件夹地址:剪映设置-全局设置-草稿设置
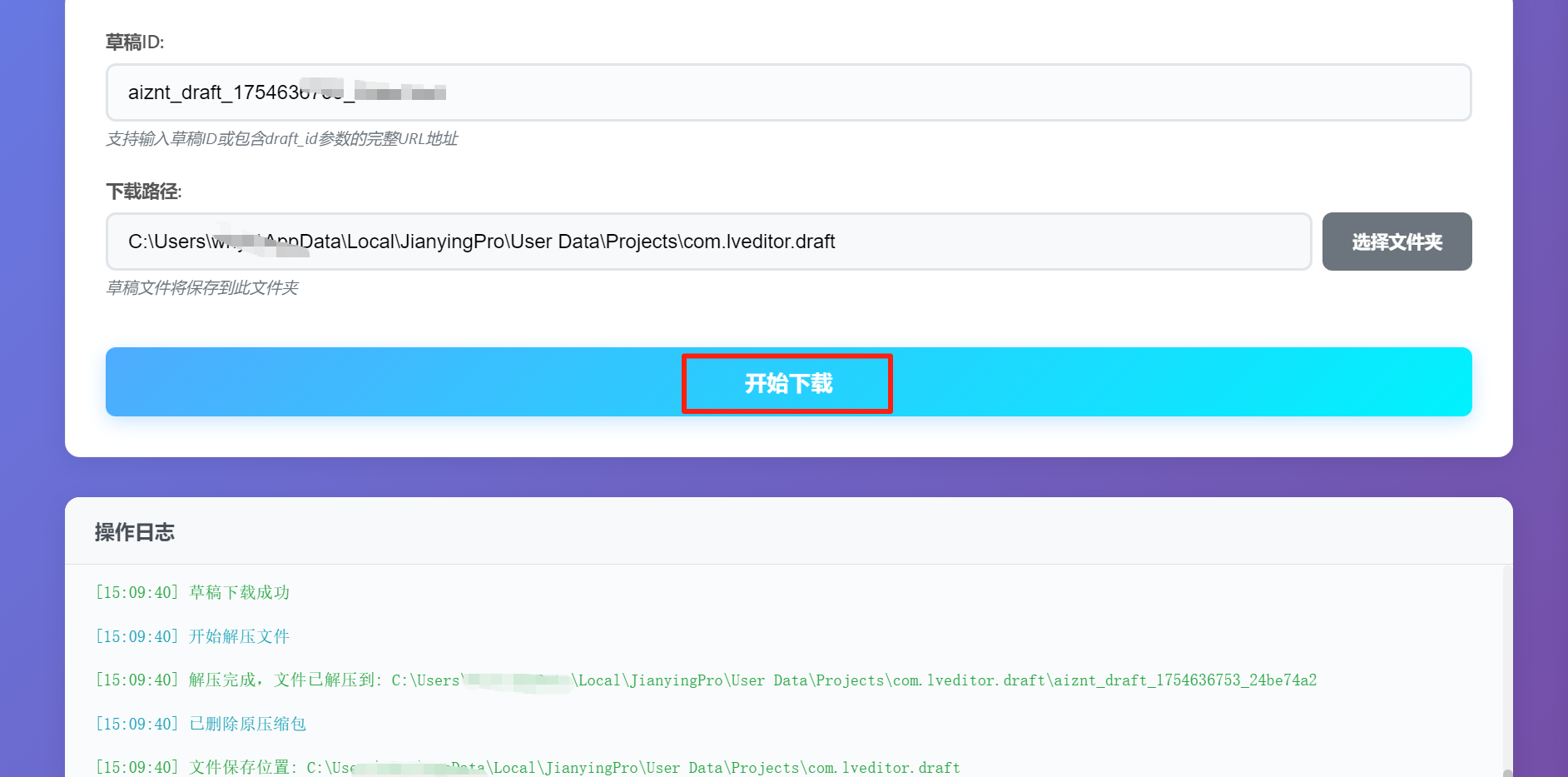
把草稿id复制进去,点击下载就可以了,打开剪映会有一个黑屏+大小为2.7k的草稿,点进去就是视频。
04 结语
这篇带大家开发coze插件+AI一键生成第一视角沉浸式的工作流,有收获的朋友一键三连支持一下~
想直接获取视频工作流源码的后台私信“第一视角”,有问题也可以留言,看到了都会回复,快来试一试吧!
往期工作流/智能体教程回顾:
1 视频系列:
2 小红书图文创作系列:
3 图片系列:
我们空间还有几百个工作流:
我们能提供:
✅ AI学习资料分享
✅ 官方最新工作流分享
✅ 大佬技术交流学习
✅ 专业解答各种问题

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)