带你轻松学习虚拟线程和StructuredTaskScope
本文详细介绍了JDK21引入的虚拟线程和StructuredTaskScope两大并发编程新特性。虚拟线程作为轻量级用户线程,由JVM管理,具有自动挂起/恢复机制,适用于I/O密集型场景,但需注意载体线程阻塞、ThreadLocal污染等问题。StructuredTaskScope实现结构化并发,通过生命周期绑定和故障策略(ShutdownOnFailure/ShutdownOnSuccess)解
目录
一、虚拟线程
(一)定义
虚拟线程在JDK19引入,在JDK21正式发布。
本质是与平台线程可以建立映射关系的用户线程,一个平台线程可以映射多个虚拟线程,所以在这里我们也称平台线程为载体线程。
虚拟线程由JVM而非操作系统进行管理,用于减少并发开销。
(二)特性
1. 轻量级
虚拟线程由JVM创建并进行管理,默认初始栈内存仅有200b,若不足JVM也会动态扩展其内存,栈溢出发生概率大大减小,但是由于其开辟的是堆内存空间,所以无限递归可能会导致堆溢出。
载体线程由操作系统创建,固定栈内存为1mb,占据内存大。
若开启1w个线程,载体线程占用的内存会高达10g,而虚拟线程最大也很难超过1g。
2. 自动挂起和恢复机制
当虚拟线程检测到阻塞事件时(比如网络IO、睡眠、等待锁),会自动挂起,也就是和挂载的载体线程解绑,放其自由让其去搭载其他准备就绪的虚拟线程。
当阻塞事件完成后,JVM会分配空闲的载体线程来搭载当前虚拟线程继续运行。
3. 兼容性
虚拟线程直接继承lang包下的Thread类,兼容其所有API。
4. 结构化并发
虚拟线程通过StructuredTaskScope管理线程的生命周期,避免传统线程的线程泄露问题。
这一点会在讲述StructuredTaskScope的时候进行详细讲解。
(三)工作机制
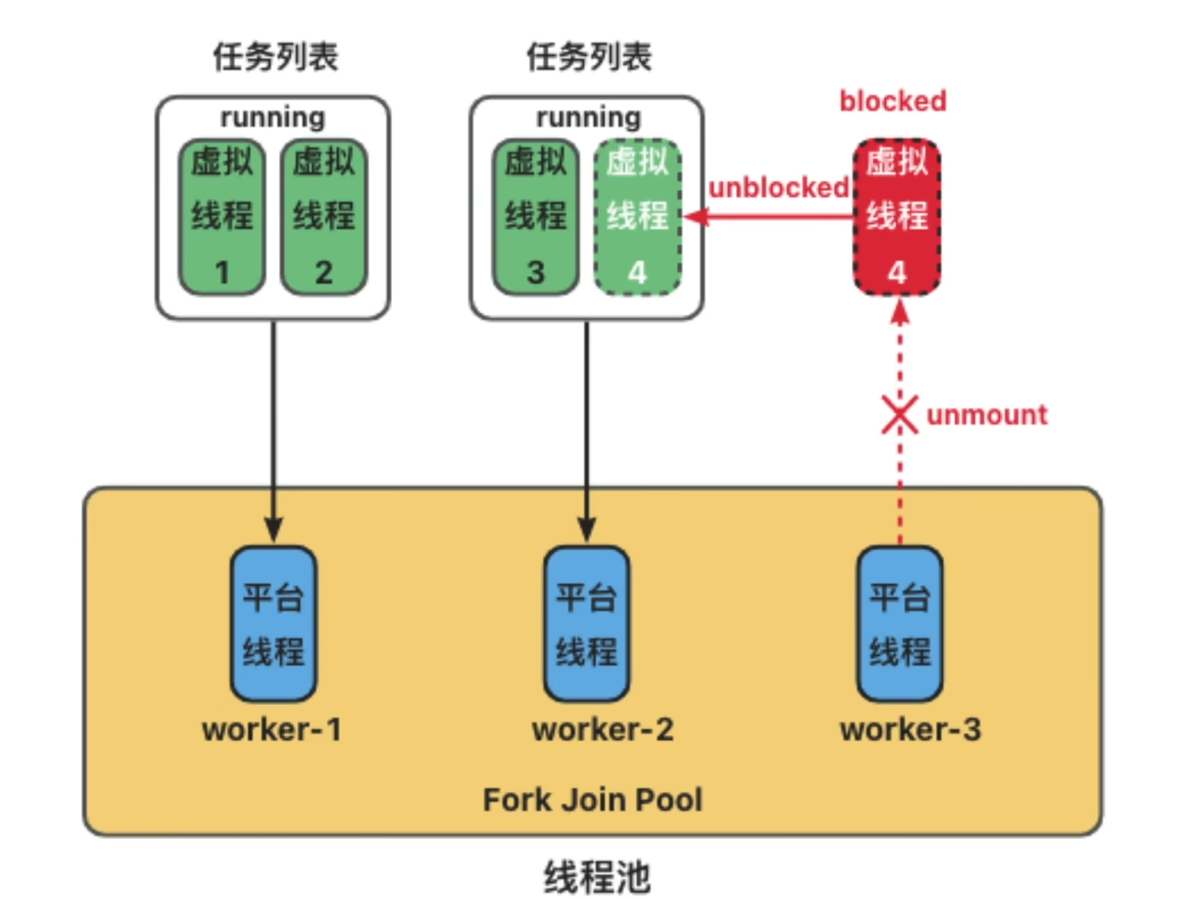
1. 创建
当收到请求时,JVM会从堆空间中开辟一小块内存来创建一个虚拟线程执行该事件,线程创建出来后会将其放入一个载体线程的调度队列中。
其调度器使用的是ForkJoinPool,所以当前虚拟线程可能需要等待搭载的载体线程空闲,也可能会被别的空闲的载体线程所窃取。
底层是双端队列,队头用于搭载的载体线程调度,队尾用于其他载体线程窃取。
2. 挂起
当虚拟线程检测到阻塞事件时(比如网络IO、睡眠、等待锁),会自动挂起,也就是和挂载的载体线程解绑,放其自由让其去搭载其他准备就绪的虚拟线程。
由于其栈空间是在堆内存上开辟的,所以其栈帧也是序列化后存储在堆内存上。
3. 恢复
当阻塞事件完成后,JVM会分配空闲的载体线程来搭载当前虚拟线程继续运行,载体线程会从堆内存中反序列化恢复其栈状态。
4. 终止
当事件运行完成后虚拟线程会直接被销毁,其资源也会立即释放。
(四)适用场景
其自动挂起和恢复机制可以最大限度地运转载体线程,而堆内存存储栈状态也大大加快了载体线程上下文切换的速度,因此可以说其在网络IO频繁、阻塞操作频繁的场景下具有非常大的优势。
(五)存在问题
虚拟线程并非升级版的平台线程,不谨慎使用的话会造成很多问题,甚至酿成事故。
1. 载体线程阻塞问题
由于一个载体线程的调度队列里可能会有成千上万个虚拟线程等待,一旦载体线程陷入BLOCKED状态,其关联的调度队列里的所有任务也会被挂起导致无法被窃取,导致吞吐量断崖式下降。
在以下几种情况中载体线程会陷入阻塞:
(1)synchronized同步块
虚拟线程之所以会自动挂起,是因为其运行到特定阻塞点的时候,会主动通知调度器挂起自己。
但是同步块的锁获取和锁释放的字节码操作是原子性的,虚拟线程根本无法插入调度点,所以无法被挂起,只能将当前载体对象放入EntrySet陷入BLOCKED状态等待获取锁。
解决方案就是将synchronized替换成ReentrantLock,ReentrantLock的底层是基于API:park()和unpark()实现的,因此虚拟线程可以插入调度点来通知调度器挂起自己。
对于这两个锁机制还不太明白的同学可以阅读下面这篇博客,里面详细讲解了其底层原理:
(2)JNI调用
JNI是执行本地方法,由操作系统调用,不归JVM管理,所以自然也无法实现虚拟线程的挂起操作。
JNI的阻塞我们无法解决,只能通过StructuredTaskScope设置超时时间来避免长时间阻塞,或者直接调用平台线程即可。
(3)CPU密集型任务
这个也很好理解,虚拟线程只会在遇到阻塞操作才会挂起,而这种CPU密集型虽然长时间占用载体线程,但是终究不是阻塞,但是跟阻塞也差不了多少。
所以我们在执行CPU密集型任务时最好调用平台线程。
2. ThreadLocal内存泄漏与载体线程污染问题
(1)问题介绍
A. 内存泄露问题
ThreadLocal需要手动删除,而虚拟线程由于过于轻量,需要频繁地创建销毁,如果忘记调用remove()的话则会造成内存泄露。
除此之外,载体线程的ThreadLocal是会给每个虚拟线程生成独立副本,因此如果使用newVirtualThreadPerTaskExecutor创建线程池的话,在线程池里务必不要涉及到ThreadLocal的操作,如果有也请记得调用remove(),不然极易造成严重内存泄漏导致oom。
B. 载体线程污染问题
虚拟线程对ThreadLocal进行操作实则操作的是载体线程存储的映射,这会导致越权或者逻辑错误问题,比如说ThreadLocal里存储userId,就可能会导致载体线程调度的虚拟线程都使用这个userId,又或者ThreadLocal里存储日期格式化字符串,A虚拟线程可能适用,但是如果A挂起被另一个不适用的线程获取到的话则会报错。
线程污染问题其实可以通过使用阿里的TransmittableThreadLocal来解决
阿里的TTL在创建新线程或者线程池时,其子线程会创建一份父线程的TTL的副本,其在执行使其可以对其进行修改,但只是作用在副本上,并不会影响父线程的TTL,子线程会在执行结束时自动恢复线程原始状态,也就是删除了TTL,大大降低了OOM发生的概率。
如果线程长期存活的话,当并发量骤升的情况下,还是有OOM概率的发生,所以其不适用于轻量级的虚拟线程。
(2)解决方案
JDK21推出了ScopedValue来解决此问题。
ScopedValue是单例存储,子线程共享ScopedValue的对象,不会像ThreadLocal需要创建副本,而且为了防止数据污染,也就是子线程篡改父线程ScopedValue,存入ScopedValue的值都会用final修饰。
然后可以使用ScopedValue开辟一个词法作用域,在这个作用域中声明的对象会在作用域结束后自动销毁。
综上,内存泄漏问题得到了解决。
然后对于这个词法作用域,它会开辟一个作用域栈帧,会将其引用存储在堆空间,绑定到每个虚拟线程上,这使得类似userId这种每个线程不同的变量就可以通过这种方式进行隔离,当作用域结束后会自动解绑,等待GC回收。
综上,载体线程污染问题也得到了解决。
但有些同学可能会问,如果每个线程不同的变量只能在词法作用域里隔离,我们一般的项目都是要经过jwt全局过滤器、controller层、service层和dao层,作用域如何跨类?
其实很简单,我们直接在jwt全局过滤器中解析令牌后,将后续请求处理链都放入作用域即可:
ScopedValue.where(ApiContext.CURRENT_CONTEXT, context) .run(() -> { chain.doFilter(request, response); });这样一来该请求所加载的每个栈帧都是位于这个作用域内,自然会共享当前线程上下文,同时也与其他虚拟线程隔离。
3. 虚拟线程数量过多导致的资源耗尽问题
(1)问题简述
A. 内存耗尽风险
由于虚拟线程的轻量级特性,高并发场景可能创建数百万甚至千万量级的虚拟线程。这些线程的栈空间存储在堆内存中,当大量任务因执行时间较长而无法及时完成时,线程资源将持续占用无法释放。在极端情况下,虚拟线程累积占用的内存可能远超物理内存上限,最终触发OOM。
B. 文件描述符耗尽
每个 I/O 操作(如网络请求或文件读写)均需消耗一个文件描述符(FD)。操作系统的 FD 资源存在严格限制:比如Linux 默认仅提供 1024 个,上限通常为 65535。当海量虚拟线程同时发起 I/O 操作时,FD 资源将瞬间耗尽,抛出异常:IOException: Too many open files 。
C. 下游资源击穿雪崩
中间件资源(如数据库连接池)的并发能力通常有明确上限。若大规模虚拟线程同时访问数据库,会使固定大小的连接池迅速饱和。例如 1000 个连接的 DB 连接池遭遇 10 万虚拟线程的查询请求时,不仅会触发连接拒绝,更可能因过载导致数据库服务雪崩甚至宕机。
D. CPU 调度过载
虚拟线程的执行依赖载体线程。当巨量就绪状态的虚拟线程同时等待调度时,JVM 将被迫创建更多载体线程以满足需求。在极端情况下,载体线程的激烈竞争会使 CPU 利用率飙升至 100%,导致 JVM 进程假死,同时影响主机上其他关键服务的正常运行。
(2)解决方案
在使用newVirtualThreadPerTaskExecutor线程池进行IO操作时,应该引入信号量Semaphore进行并发数量的控制,并且根据不同的IO类型也要使用不同的信号量进行隔离。
或者直接使用AIO,不过这样反而失去了使用虚拟线程的意义了。
我们主张使用信号量管理虚拟线程,却不建议将虚拟线程池化
平台线程之所以池化,是因为平台线程如果频繁创建销毁的话会带来巨大开销,而且会占用CPU,所以需要复用来减小开销。
但是虚拟线程创建成本小,而且虚拟线程解决了载体线程阻塞占用资源的问题,池化根本没有任何意义,反而限制了虚拟线程的发挥。
而且虚拟线程天生就是一次性的,不该被池化。
这篇文章也讲解了虚拟线程使用时需要注意的问题,有兴趣的话也推荐阅读一下。
Java Virtual Threads: The Essential Refactor Guide | Medium
综上,我们不应该限制虚拟线程的创建,而是应该限制其并发的粒度。

二、StructuredTaskScope
(一)传统并发模型存在哪些问题?
在传统并发编程中,我们通常使用的是future类来进行子任务的并发处理,但是future类是存在几个缺点的:
1. 父线程阻塞
我们一般使用future进行子任务并行处理时,都是在执行下一步逻辑之前需要获取其结果的,所以通常会调用get()这个api。
Future<TaskResult> future1 = service.submit(() -> {
// 执行任务1并返回TaskResult
});
Future<TaskResult> future2 = service.submit(() -> {
// 执行任务2并返回TaskResult
});
Future<TaskResult> future3 = service.submit(() -> {
// 执行任务3并返回TaskResult
});
// get()将阻塞直到任务1完成
TaskResult result1 = future1.get();
// get()将阻塞直到任务2完成
TaskResult result2 = future2.get();
// get()将阻塞直到任务3完成
TaskResult result3 = future3.get();这个如果子任务的数量大于线程池的最大线程数,那么后续子任务就会在任务队列里等待空闲线程,但是因为这些都是异步进行的,所以主线程在执行到等待任务的get()的时候就会跟着任务一起等待执行,也就是说在此过程中主线程会陷入阻塞状态,而且在这个任务之后的所有任务也都是需要阻塞等待任务完成获取结果的,而在此期间珍贵的平台线程则将会完全被阻塞占用。
所以为了解决这个问题,后续又引入了CompletableFuture,这个类的创新就在于其不需要阻塞等待任务结果,当子任务执行完成后会自动触发回调函数将执行结果放入结果集中。
但是这样又带来个问题,由于触发回调的时机是不确定的,导致可能在执行到使用该结果集的逻辑时,结果集不完整或者为空。所以我们通常会调用join()这个api来等待结果集填充完毕,但这样又回到了上面的线程阻塞问题了。
但解决方案大家也应该已经知晓了,就是引入虚拟线程即可,虚拟线程解决了平台线程阻塞的问题。
2. 任务状态无感知
我们虽然称在future类里创建的任务为子任务,但实际上都是一些完全独立的任务,其生命周期是完全不归父线程管理的,所以极易造成线程泄露问题,也就是父线程已经结束,但是子线程仍在无限阻塞。
除此之外,future只收集任务完成的状态,不管其是否是成功还是失败,这样的话就会造成一个问题,即使其中一个子任务在执行的过程中遇到了错误,也不会立刻抛出异常,而是等待所有任务都执行完毕后,才会在get()提交时抛出。这会造成严重问题,因为一般前一个子任务抛出异常了,后续的任务也基本很难执行成功,使用future则无法使其快速失败导致资源浪费。
3. 资源清理问题
对于future类的资源清理,我们一般使用try-with-resources块进行自动清理,不然如果忘记了手动清理则可能会造成泄露问题。
try (ExecutorService service = Executors.newFixedThreadPool(1)) {
Future<TaskResult> future1 = service.submit(() -> {
// 执行任务1并返回TaskResult
});
Future<TaskResult> future2 = service.submit(() -> {
// 执行任务2并返回TaskResult
});
Future<TaskResult> future3 = service.submit(() -> {
// 执行任务3并返回TaskResult
});
// get()将阻塞直到任务1完成
TaskResult result1 = future1.get();
// get()将阻塞直到任务2完成
TaskResult result2 = future2.get();
// get()将阻塞直到任务3完成
TaskResult result3 = future3.get();
}但虽然说try-with-resources块可以自动清理,但是其自动调用的close()方法,是会等待所有任务完成后才会执行,所以这依旧造成了线程阻塞的问题。
(二)定义
为了解决以上的问题,结构化并发被提出。
StructuredTaskScope 是在JDK19引入,在JDK21正式发布。它代表了结构化并发的核心实现,彻底改变了 Java 的并发编程范式。
其核心思想是:子任务的生命周期必须严格嵌套在父任务作用域内。
(三)特性
1. 生命周期绑定
StructuredTaskScope也依赖于try-with-resources块,但不同的是,在其作用域中创建的子任务是与之绑定的,一旦作用域结束子任务无论是否执行完成都会被取消。
try (var scope = new StructuredTaskScope<Object>()) {
} 2. 故障策略
对于任务状态无感知这个问题,StructuredTaskScope提供了故障策略:
(1)ShutdownOnFailure
只要收到任意一条任务失败的结果就立刻取消后续所有任务。
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Future<?> task1 = scope.fork(() -> taskA());
Future<?> task2 = scope.fork(() -> taskB());
scope.join();
scope.throwIfFailed();
// 所有任务成功后才继续...
}使用了此策略之后,join()方法一旦获取到了失败结果就会立刻结束向下执行,后续任务队列也会全部清空。throwIfFailed()只有在结果集中存在失败记录时才会抛出异常,中断程序运行。
此策略适用于需要保证每个任务都成功执行的场景。
(2)ShutdownOnSuccess
只要收到任意一条任务成功的结果就立刻取消后续所有任务。
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<String>()) {
scope.fork(() -> queryServiceA());
scope.fork(() -> queryServiceB());
scope.join();
String result = scope.result();
}与上面相反,只要获取到了成功结果就会中断join()并清空任务队列。
此策略适用于竞争场景。
(3)自定义策略
如果需要额外扩展的情况,则需要重写handleComplete方法来自定义策略。
比如说我想在收到5个成功结果后结束,但是失败结果不能超过3个:
public class CustomTaskScope<T> extends StructuredTaskScope<T> {
private final ConcurrentLinkedQueue<T> successResults = new ConcurrentLinkedQueue<>();
private final ConcurrentLinkedQueue<Throwable> exceptions = new ConcurrentLinkedQueue<>();
private final AtomicInteger successCount = new AtomicInteger(0);
private final AtomicInteger failureCount = new AtomicInteger(0);
// 自定义关闭条件
private volatile boolean shouldShutdown = false;
@Override
protected void handleComplete(Future<T> future) {
switch (future.state()) {
case SUCCESS -> {
T result = future.resultNow();
successResults.add(result);
successCount.incrementAndGet();
// 自定义条件:当收集到5个成功结果时关闭
if (successCount.get() >= 5) {
this.shutdown(); // 请求关闭作用域
}
}
case FAILED -> {
Throwable ex = future.exceptionNow();
exceptions.add(ex);
failureCount.incrementAndGet();
// 自定义条件:当失败次数超过阈值
if (failureCount.get() > 3) {
this.shutdown();
}
}
case CANCELLED -> {
// 任务被取消时的处理
System.out.println("Task cancelled: " + future);
}
}
}
// 获取成功结果
public List<T> getSuccessResults() {
return new ArrayList<>(successResults);
}
// 获取异常
public List<Throwable> getExceptions() {
return new ArrayList<>(exceptions);
}
// 自定义方法:检查是否满足条件
public boolean hasReachedTarget() {
return successCount.get() >= 5 || failureCount.get() > 3;
}
}3. 资源安全
在作用域结束后,会先清空任务队列,然后中断所有子线程,最后再释放资源。
这三步严格保障了资源安全,泄露的风险变为0。
对于线程阻塞问题也不需要显示声明虚拟线程来解决,因为StructuredTaskScope默认使用虚拟线程,当然如果想切换为平台线程也可以使用线程工厂的构造方法。
三、最佳实践
我们引入一个下载器来了解一下如何使用好虚拟线程和StructuredTaskScope:
@Slf4j
public class VirtualThreadDownloader {
// 全局信号量控制并发量 (最大50个并发下载)
private static final Semaphore downloadSemaphore = new Semaphore(50);
// 原子类保证线程安全
// 正在执行的任务
private static final AtomicInteger activeTasks = new AtomicInteger(0);
// 执行成功的任务
private static final AtomicInteger completedTasks = new AtomicInteger(0);
// 执行失败的任务
private static final AtomicInteger failedTasks = new AtomicInteger(0);
public static void main(String[] args) {
// 要下载的URL列表
List<String> urls = List.of(
"https://example.com/file1",
"https://example.com/file2",
// ...
"https://example.com/file100"
);
// 启动监控线程
startMonitoringThread();
try {
// 执行下载逻辑
downloadAll(urls);
log.info("所有下载任务完成: 成功={}, 失败={}", completedTasks.get(), failedTasks.get());
} catch (Exception e) {
log.error("下载失败!", e);
}
}
// 启动监控线程定期报告状态
private static void startMonitoringThread() {
// 使用虚拟线程,不占用资源
Thread monitorThread = Thread.ofVirtual().name("monitor-thread").start(() -> {
while (true) {
try {
// 每5秒报告一次
Thread.sleep(5000);
int active = activeTasks.get();
int completed = completedTasks.get();
int failed = failedTasks.get();
// 报告
log.info("监控报告: 活跃任务={}, 已完成={}, 失败={}, 信号量可用={}",
active, completed, failed, downloadSemaphore.availablePermits());
// 当所有任务完成时退出监控
if (active == 0 && (completed + failed) > 0) {
break;
}
} catch (InterruptedException e) {
log.error("监控线程被中断", e);
// 重置中断标记
Thread.currentThread().interrupt();
break;
}
}
});
}
// 使用StructuredTaskScope
private static void downloadAll(List<String> urls) throws Exception {
// 创建作用域,使用ShutdownOnFailure策略保障任务必须全部成功,不然可能下载数据不完整导致损坏
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// 提交所有下载任务
for (String url : urls) {
scope.fork(() -> downloadUrl(url));
}
log.info("已提交所有下载任务,总数: {}", urls.size());
// 等待所有任务完成
scope.join();
// 若存在失败结果则抛出异常,中断下载
scope.throwIfFailed();
}
}
// 单一职责的下载任务
private static Void downloadUrl(String url) throws Exception {
// cas给执行中任务集合++
activeTasks.incrementAndGet();
log.debug("开始下载: {}", url);
try {
// 获取信号量许可
downloadSemaphore.acquire();
// 执行下载
fetchUrlContent(url);
// 下载完成
completedTasks.incrementAndGet();
log.debug("下载完成: {}", url);
return null;
} catch (InterruptedException e) {
log.error("下载被中断: {}", url, e);
failedTasks.incrementAndGet();
Thread.currentThread().interrupt();
throw e;
} catch (Exception e) {
log.error("下载失败: {} - {}", url, e.getMessage());
failedTasks.incrementAndGet();
throw e;
} finally {
activeTasks.decrementAndGet();
// 释放信号量
downloadSemaphore.release();
}
}
// 模拟下载
private static voidfetchUrlContent(String url) throws Exception {
// 下载中……
}
}最后还是要强调一点:
虚拟线程仅适用于I/O密集型任务,严禁在CPU密集型场景中使用! 同时必须彻底禁用ThreadLocal 和synchronized,强制通过信号量控制并发粒度,防止虚拟线程爆发式创建导致的资源过载。
虚拟线程与 StructuredTaskScope 势必将引领 Java 并发编程的变革,带来更安全、更直观、更高效的开发模式,其重要性不容忽视。
~码文不易,留个赞再走吧~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)