3550 亿参数的 “全能学霸“:GLM-4.5 为什么让 AI 圈集体沸腾?
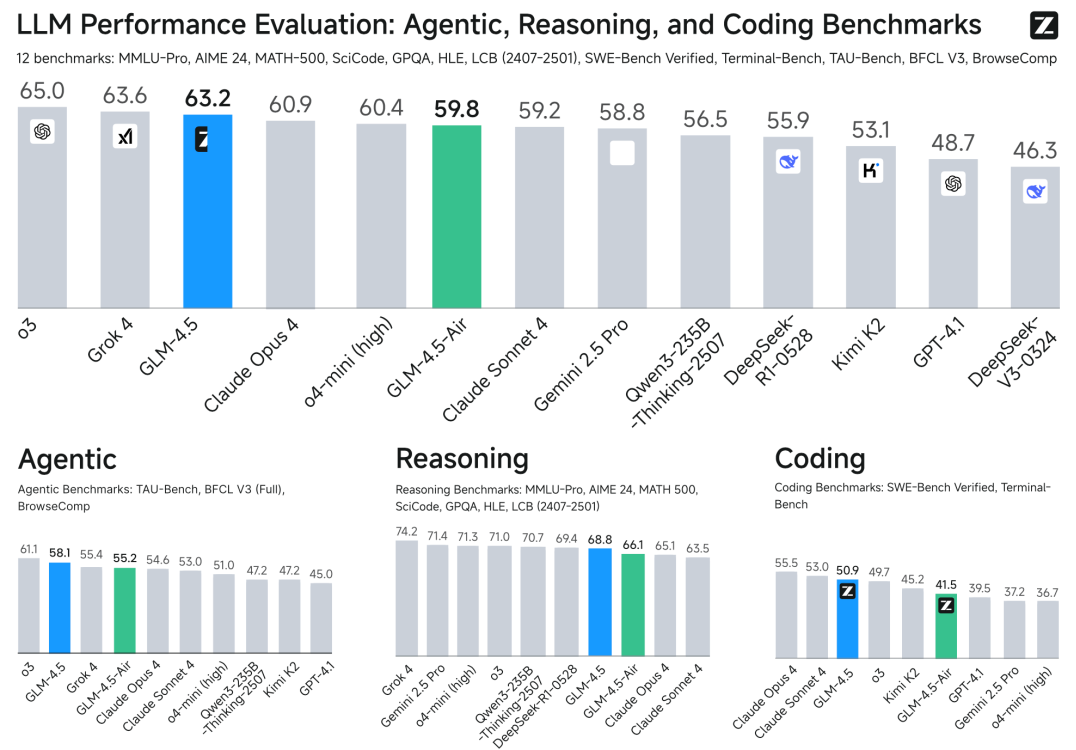
上个月,智谱开源的 GLM-4.5系列大模型在 AI 圈掀起热潮。这个包含 3550 亿总参数的旗舰模型,不仅首次实现推理、编码与智能体能力的原生融合,更在 12 项全球权威测试中拿下综合第三的成绩 。
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
上个月,智谱开源的 GLM-4.5系列大模型在 AI 圈掀起热潮。这个包含 3550 亿总参数的旗舰模型,不仅首次实现推理、编码与智能体能力的原生融合,更在 12 项全球权威测试中拿下综合第三的成绩 。
为何要让模型学会 “全能”?
大模型的进化正从 “知识库” 走向 “问题解决者”,但真正的通用智能,从来不是单一能力的拔尖。
智谱团队提出,衡量一个通才模型,关键看三样东西:能否与外部工具互动的智能体能力、能否解复杂数学科学问题的推理能力、能否处理真实软件工程任务的编码能力 —— 这三者被合称为 ARC 能力。
此前,即便是 OpenAI 的 o1 或 Anthropic 的 Claude Sonnet 4,也只在某一领域突出,而 GLM-4.5 想做的,正是让一个模型同时把这三件事做好。它采用 “混合推理模式”:遇到复杂任务就进入 “思考模式”,需要即时响应就切换到 “直接模式”,像人类一样灵活应对不同场景。
从架构到训练:如何 “炼” 出全能模型?
GLM-4.5 的 “全能”,始于独特的架构设计。它采用混合专家(MoE)架构,但走了条 “瘦高” 路线 —— 相比同类模型追求 “宽”(更多专家、更大隐藏维度),它选择减少宽度、增加深度。
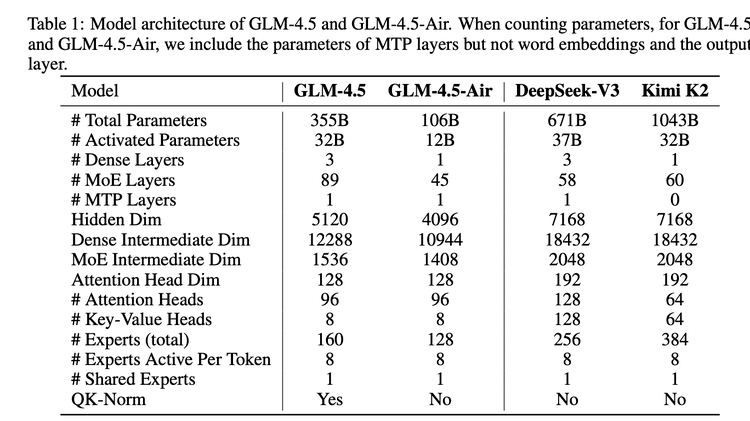
团队发现,更深的模型在推理能力上更有优势。同时,它把注意力头数量增加到常规模型的 2.5 倍,虽然没降低训练损耗,却让推理基准测试的表现稳步提升。这种设计,让它在 3550 亿总参数下,仅需激活 320 亿参数就能高效运行,兼顾性能与成本。
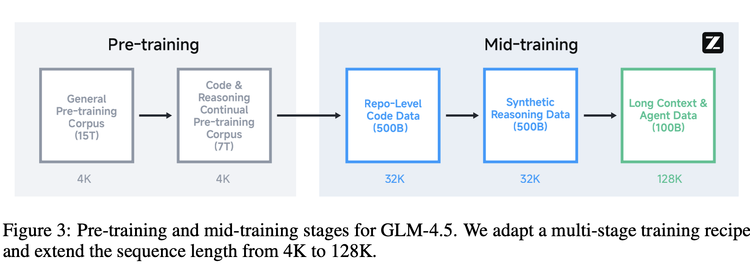
训练过程则像一场 “阶梯式修炼”。先是 15 万亿 token 的通用预训练,让模型打下知识基础;接着用 7 万亿 token 的代码与推理语料强化专项能力;最关键的 “中期训练” 阶段,模型开始 “定向突破”:拼接代码仓库文件学习跨文件依赖,用合成数据强化推理步骤,把序列长度从 4K 扩展到 128K 以适应长文本与智能体任务。就像学生先学基础知识,再针对性攻克难点,每一步都在为 ARC 能力添砖加瓦。
而让能力 “落地” 的关键,是强化学习。智谱专门开发了开源框架 slime,它像个高效的 “训练管家”:把训练与数据生成解耦,让智能体任务能并行处理;用 FP8 精度加速数据生成,BF16 精度保证训练稳定。这种设计,让模型在处理网页搜索、代码修复等复杂任务时,能持续从交互中学习,不断优化策略。
实战见真章:它真的能打吗?
12 项基准测试成了最好的 “成绩单”。智能体能力上,它在 TAU-Bench 超越 Gemini 2.5 Pro,BFCL V3 拿下榜首;推理能力更惊艳,AIME 24 数学测试得分 91.0%,超过 OpenAI o3;编码方面,SWE-bench Verified 的 64.2% 成绩,让它成为 Claude Sonnet 4 最有力的对手。
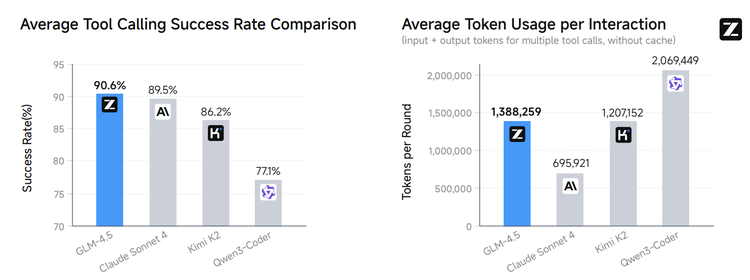
社区实测中,有开发者发现,它在真实编程任务中的工具调用成功率高达 90.6%,单轮交互的 token 消耗却比同类模型低不少 —— 性能与效率的平衡,让它在落地场景中更具优势。
当模型权重、技术报告与 slime 框架同时开源,GLM-4.5 的意义早已不止于一个好用的工具。它像一本公开的 “教科书”,展示了如何让大模型突破单一能力局限,走向真正的通用智能。对于 AI 社区而言,这或许正是打开下一代大模型研发之门的钥匙。
关注gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)