一文彻底搞定从0到1手把手教你部署Qwen3大模型(Web展示、本地调用)
本文提供了从零开始部署Qwen3大模型的详细教程,包含命令行和Web界面两种调用方式。教程分为四个部分:首先安装gradio环境,然后替换demo文件代码,接着分别运行CLI命令行和Web版demo。Web版可通过SSH工具远程连接,提供了交互式聊天界面。整个过程只需15分钟即可完成本地部署,适合零基础用户。教程附带完整代码和操作截图,帮助用户快速上手使用Qwen3-8B大模型进行对话交互。
·
都是自己的操作截图,手把手教学,零基础也15分钟可以本地调用自己的部署Qwen3大模型!!!
如果对您有帮助请点个赞,谢谢。
系列文章目录
目录
前言
这次主要是通过两个Demo来是我们 本地调用 上期部署的Qwen3大模型,预计 15 分钟。
一、安装gradio环境
pip install gradio二、使用demo代码调用大模型
1.进入指定demo目录
cdcd autodl-tmp/Qwen3/examples/demo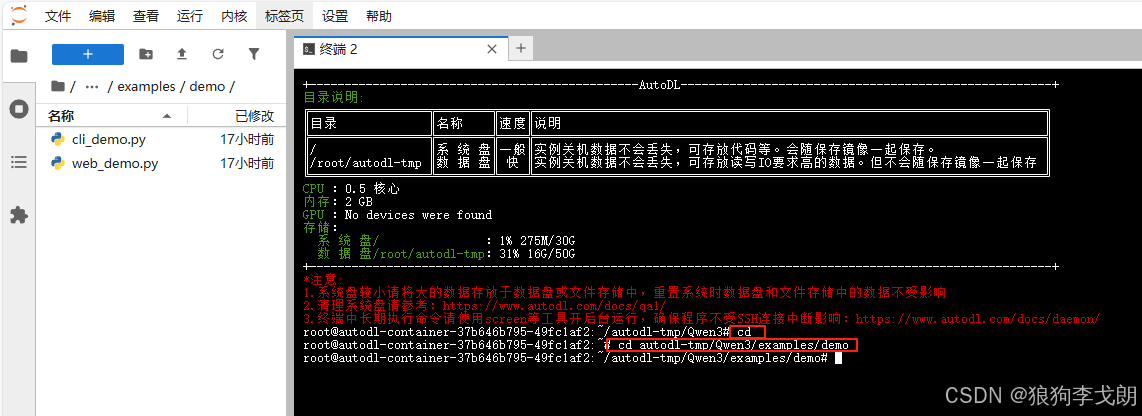
2.替换两个demo文件
双击右边两个python文件,用下面两个代码依次替换掉,Ctrl+S即可保存
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple command-line interactive chat demo."""
import argparse
import os
import platform
import shutil
from copy import deepcopy
from threading import Thread
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from transformers.trainer_utils import set_seed
DEFAULT_CKPT_PATH = "/root/autodl-tmp/Qwen/Qwen3-8B"
_WELCOME_MSG = """\
Welcome to use Qwen3-8B model, type text to start chat, type :h to show command help.
(欢迎使用 Qwen3-8B-Instruct 模型,输入内容即可进行对话,:h 显示命令帮助。)
Note: This demo is governed by the original license of Qwen3-8B.
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc.
(注:本演示受Qwen3-8B的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)
"""
_HELP_MSG = """\
Commands:
:help / :h Show this help message 显示帮助信息
:exit / :quit / :q Exit the demo 退出Demo
:clear / :cl Clear screen 清屏
:clear-history / :clh Clear history 清除对话历史
:history / :his Show history 显示对话历史
:seed Show current random seed 显示当前随机种子
:seed <N> Set random seed to <N> 设置随机种子
:conf Show current generation config 显示生成配置
:conf <key>=<value> Change generation config 修改生成配置
:reset-conf Reset generation config 重置生成配置
"""
_ALL_COMMAND_NAMES = [
"help",
"h",
"exit",
"quit",
"q",
"clear",
"cl",
"clear-history",
"clh",
"history",
"his",
"seed",
"conf",
"reset-conf",
]
def _setup_readline():
try:
import readline
except ImportError:
return
_matches = []
def _completer(text, state):
nonlocal _matches
if state == 0:
_matches = [
cmd_name for cmd_name in _ALL_COMMAND_NAMES if cmd_name.startswith(text)
]
if 0 <= state < len(_matches):
return _matches[state]
return None
readline.set_completer(_completer)
readline.parse_and_bind("tab: complete")
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path,
resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "auto"
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
torch_dtype="auto",
device_map=device_map,
resume_download=True,
).eval()
model.generation_config.max_new_tokens = 2048 # For chat.
return model, tokenizer
def _gc():
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def _clear_screen():
if platform.system() == "Windows":
os.system("cls")
else:
os.system("clear")
def _print_history(history):
terminal_width = shutil.get_terminal_size()[0]
print(f"History ({len(history)})".center(terminal_width, "="))
for index, (query, response) in enumerate(history):
print(f"User[{index}]: {query}")
print(f"Qwen[{index}]: {response}")
print("=" * terminal_width)
def _get_input() -> str:
while True:
try:
message = input("User> ").strip()
except UnicodeDecodeError:
print("[ERROR] Encoding error in input")
continue
except KeyboardInterrupt:
exit(1)
if message:
return message
print("[ERROR] Query is empty")
def _chat_stream(model, tokenizer, query, history):
conversation = []
for query_h, response_h in history:
conversation.append({"role": "user", "content": query_h})
conversation.append({"role": "assistant", "content": response_h})
conversation.append({"role": "user", "content": query})
input_text = tokenizer.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=False,
)
inputs = tokenizer([input_text], return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(
tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True
)
generation_kwargs = {
**inputs,
"streamer": streamer,
}
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for new_text in streamer:
yield new_text
def main():
parser = argparse.ArgumentParser(
description="QwenQwen3-8B command-line interactive chat demo."
)
parser.add_argument(
"-c",
"--checkpoint-path",
type=str,
default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r",
)
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
parser.add_argument(
"--cpu-only", action="store_true", help="Run demo with CPU only"
)
args = parser.parse_args()
history, response = [], ""
model, tokenizer = _load_model_tokenizer(args)
orig_gen_config = deepcopy(model.generation_config)
_setup_readline()
_clear_screen()
print(_WELCOME_MSG)
seed = args.seed
while True:
query = _get_input()
# Process commands.
if query.startswith(":"):
command_words = query[1:].strip().split()
if not command_words:
command = ""
else:
command = command_words[0]
if command in ["exit", "quit", "q"]:
break
elif command in ["clear", "cl"]:
_clear_screen()
print(_WELCOME_MSG)
_gc()
continue
elif command in ["clear-history", "clh"]:
print(f"[INFO] All {len(history)} history cleared")
history.clear()
_gc()
continue
elif command in ["help", "h"]:
print(_HELP_MSG)
continue
elif command in ["history", "his"]:
_print_history(history)
continue
elif command in ["seed"]:
if len(command_words) == 1:
print(f"[INFO] Current random seed: {seed}")
continue
else:
new_seed_s = command_words[1]
try:
new_seed = int(new_seed_s)
except ValueError:
print(
f"[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number"
)
else:
print(f"[INFO] Random seed changed to {new_seed}")
seed = new_seed
continue
elif command in ["conf"]:
if len(command_words) == 1:
print(model.generation_config)
else:
for key_value_pairs_str in command_words[1:]:
eq_idx = key_value_pairs_str.find("=")
if eq_idx == -1:
print("[WARNING] format: <key>=<value>")
continue
conf_key, conf_value_str = (
key_value_pairs_str[:eq_idx],
key_value_pairs_str[eq_idx + 1 :],
)
try:
conf_value = eval(conf_value_str)
except Exception as e:
print(e)
continue
else:
print(
f"[INFO] Change config: model.generation_config.{conf_key} = {conf_value}"
)
setattr(model.generation_config, conf_key, conf_value)
continue
elif command in ["reset-conf"]:
print("[INFO] Reset generation config")
model.generation_config = deepcopy(orig_gen_config)
print(model.generation_config)
continue
else:
# As normal query.
pass
# Run chat.
set_seed(seed)
_clear_screen()
print(f"\nUser: {query}")
print(f"\nQwen: ", end="")
try:
partial_text = ""
for new_text in _chat_stream(model, tokenizer, query, history):
print(new_text, end="", flush=True)
partial_text += new_text
response = partial_text
print()
except KeyboardInterrupt:
print("[WARNING] Generation interrupted")
continue
history.append((query, response))
if __name__ == "__main__":
main()
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple web interactive chat demo based on gradio."""
from argparse import ArgumentParser
from threading import Thread
import gradio as gr
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
DEFAULT_CKPT_PATH = "/root/autodl-tmp/Qwen/Qwen3-8B"
def _get_args():
parser = ArgumentParser(description="Qwen3-8B web chat demo.")
parser.add_argument(
"-c",
"--checkpoint-path",
type=str,
default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r",
)
parser.add_argument(
"--cpu-only", action="store_true", help="Run demo with CPU only"
)
parser.add_argument(
"--share",
action="store_true",
default=False,
help="Create a publicly shareable link for the interface.",
)
parser.add_argument(
"--inbrowser",
action="store_true",
default=False,
help="Automatically launch the interface in a new tab on the default browser.",
)
parser.add_argument(
"--server-port", type=int, default=6006, help="Demo server port."
)
parser.add_argument(
"--server-name", type=str, default="127.0.0.1", help="Demo server name."
)
args = parser.parse_args()
return args
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path,
resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "auto"
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
torch_dtype="auto",
device_map=device_map,
resume_download=True,
).eval()
model.generation_config.max_new_tokens = 2048 # For chat.
return model, tokenizer
def _chat_stream(model, tokenizer, query, history):
conversation = []
for query_h, response_h in history:
conversation.append({"role": "user", "content": query_h})
conversation.append({"role": "assistant", "content": response_h})
conversation.append({"role": "user", "content": query})
input_text = tokenizer.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=False,
)
inputs = tokenizer([input_text], return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(
tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True
)
generation_kwargs = {
**inputs,
"streamer": streamer,
}
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for new_text in streamer:
yield new_text
def _gc():
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def _launch_demo(args, model, tokenizer):
def predict(_query, _chatbot, _task_history):
print(f"User: {_query}")
_chatbot.append((_query, ""))
full_response = ""
response = ""
for new_text in _chat_stream(model, tokenizer, _query, history=_task_history):
response += new_text
_chatbot[-1] = (_query, response)
yield _chatbot
full_response = response
print(f"History: {_task_history}")
_task_history.append((_query, full_response))
print(f"Qwen: {full_response}")
def regenerate(_chatbot, _task_history):
if not _task_history:
yield _chatbot
return
item = _task_history.pop(-1)
_chatbot.pop(-1)
yield from predict(item[0], _chatbot, _task_history)
def reset_user_input():
return gr.update(value="")
def reset_state(_chatbot, _task_history):
_task_history.clear()
_chatbot.clear()
_gc()
return _chatbot
with gr.Blocks() as demo:
gr.Markdown("""\
<p align="center"><img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/assets/logo/qwen2.5_logo.png" style="height: 120px"/><p>""")
gr.Markdown(
"""\
<center><font size=3>This WebUI is based on Qwen2.5-Instruct, developed by Alibaba Cloud. \
(本WebUI基于Qwen2.5-Instruct打造,实现聊天机器人功能。)</center>"""
)
gr.Markdown("""\
<center><font size=4>
Qwen2.5-7B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2.5-7B-Instruct/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen2.5-7B-Instruct">🤗</a>  |
Qwen2.5-32B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2.5-32B-Instruct/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen2.5-32B-Instruct">🤗</a>  |
Qwen2.5-72B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2.5-72B-Instruct/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen2.5-72B-Instruct">🤗</a>  |
 <a href="https://github.com/QwenLM/Qwen2.5">Github</a></center>""")
chatbot = gr.Chatbot(label="Qwen", elem_classes="control-height")
query = gr.Textbox(lines=2, label="Input")
task_history = gr.State([])
with gr.Row():
empty_btn = gr.Button("🧹 Clear History (清除历史)")
submit_btn = gr.Button("🚀 Submit (发送)")
regen_btn = gr.Button("🤔️ Regenerate (重试)")
submit_btn.click(
predict, [query, chatbot, task_history], [chatbot], show_progress=True
)
submit_btn.click(reset_user_input, [], [query])
empty_btn.click(
reset_state, [chatbot, task_history], outputs=[chatbot], show_progress=True
)
regen_btn.click(
regenerate, [chatbot, task_history], [chatbot], show_progress=True
)
gr.Markdown("""\
<font size=2>Note: This demo is governed by the original license of Qwen2.5. \
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, \
including hate speech, violence, pornography, deception, etc. \
(注:本演示受Qwen2.5的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,\
包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)""")
demo.queue().launch(
share=args.share,
inbrowser=args.inbrowser,
server_port=args.server_port,
server_name=args.server_name,
)
def main():
args = _get_args()
model, tokenizer = _load_model_tokenizer(args)
_launch_demo(args, model, tokenizer)
if __name__ == "__main__":
main()
三、运行CLI命令行demo
python cli_demo.py
输入问题开始对话,输入 :q 即可退出
四、运行 Web demo
1.开启服务demo
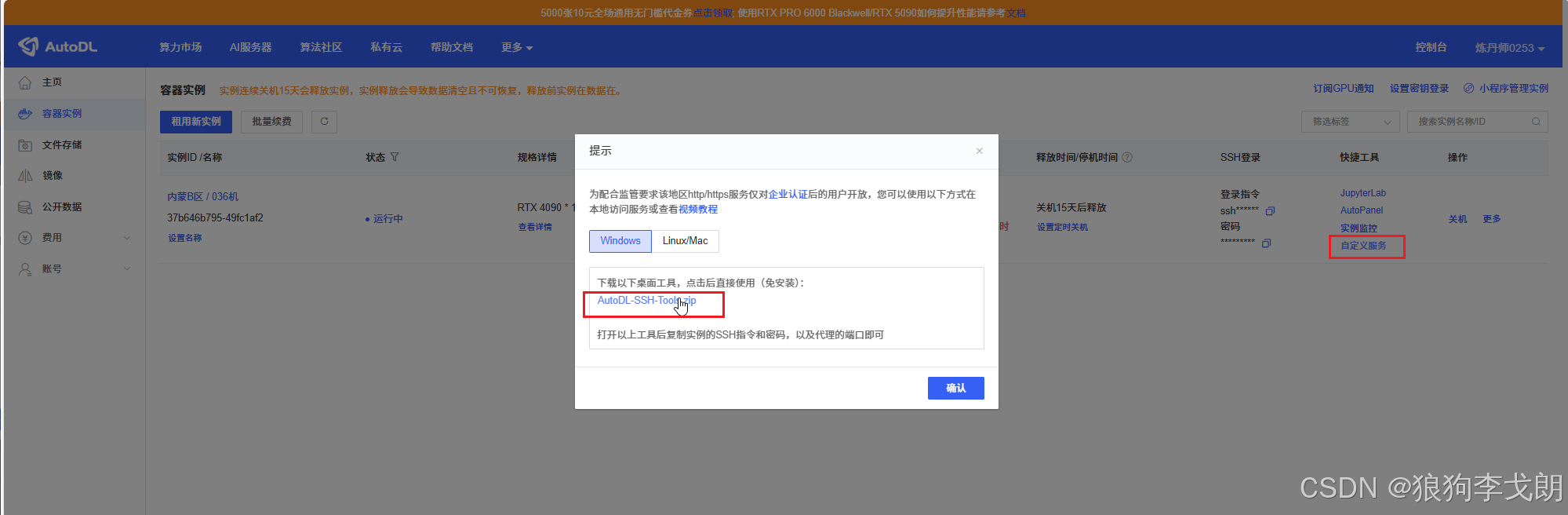
python web_demo.py2.下载Autodl平台SSH工具
1.返回Autodl主界面,选择自定义服务
2.下载SSH Tool到本机电脑,并解压
3.通过SSH连接远程服务端口
打开解压的文件,点击AutoDL.exe并运行,弹出以下窗口
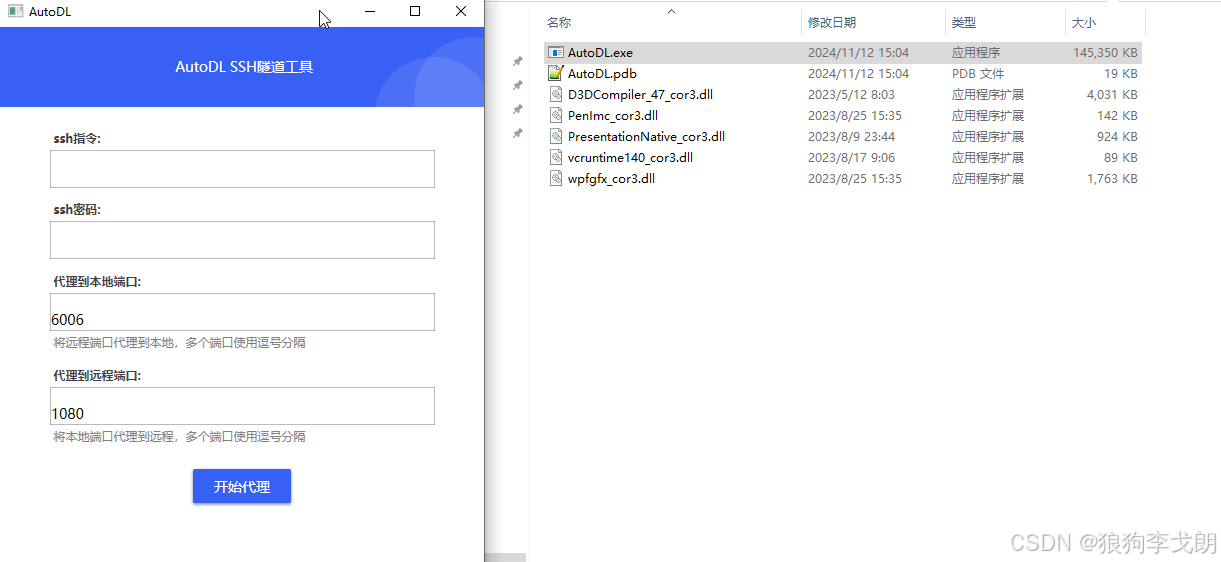
其中服务器的远程指令和密码可以直接复制
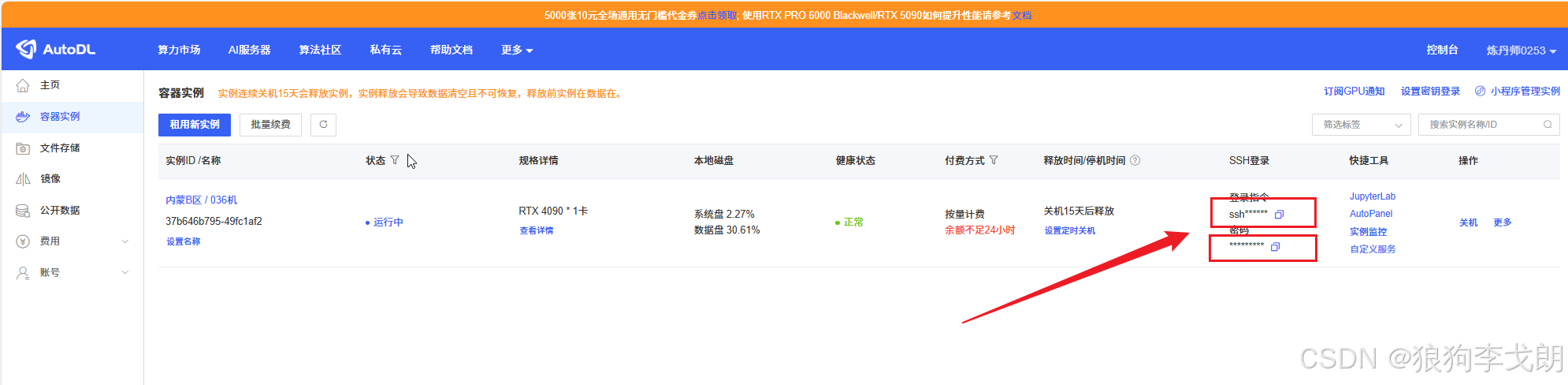
点击“开始代理”后卡住是正常的,耐心等待半分钟即可,成功后点击访问即可开启对话
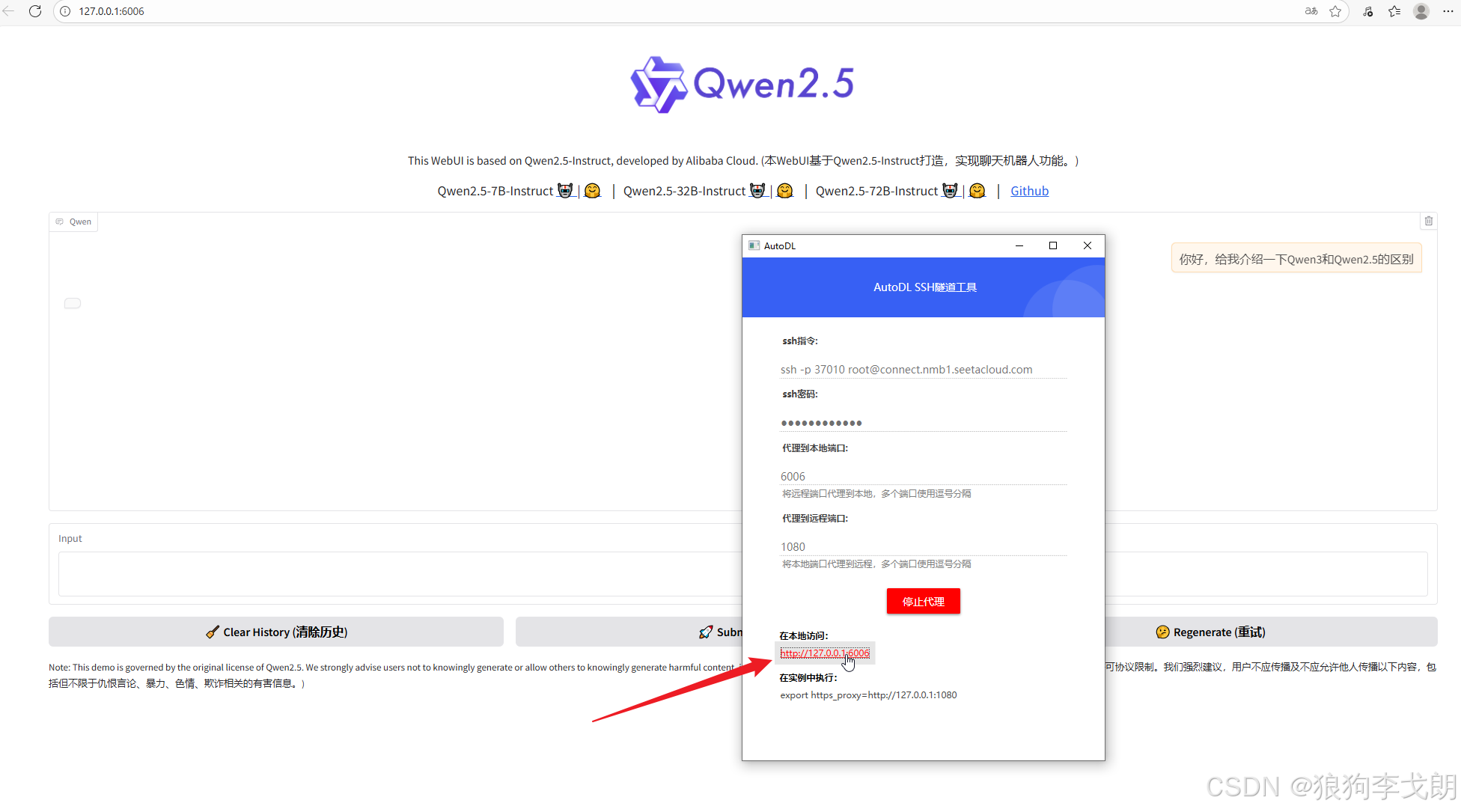
恭喜你成功调用了自己部署的大模型!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)