Web基础
域名的产生:IP地址不易记忆早期使用Hosts文件解析域名:主机名称重复、主机维护困难DNS(Domain Name System,域名系统):分布式、层次性域名空间结构根域顶级域组织域国家/地区域名二级域FQDN=主机名.DNS后缀域名注册域名注册是Internet中用于解决地址对应问题的一种方法遵循先申请先注册原则域名注册步骤:准备申请资料→寻找域名注册网址→查询域名→正式申请→申请成功。
1 web基础
用户访问网站,使用App时,都是基于Web这种 Browser/Server模式,简称BS架构。它的特点是,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web页面,并把Web页面展示给用户即可。
1.1 Internet的基本概念
-
Internet:全球性的计算机互联网络。
用于信息共享和交互,基于共同协议(如HTTP)进行通信。
-
Web(World Wide Web):全球广域网,也称为万维网。
Internet上最流行的网络应用之一,通过超文本、超媒体和HTTP协议实现信息和服务无缝连接,是一种分布式图形信息系统。
1.2 web技术的主要组成
- HTML(超文本标记语言):用于定义网页结构和内容的标记语言。
- CSS(层叠样式表):用于控制网页样式,实现内容与样式分离。
- JavaScript:为网页添加动态行为和交互性的脚本语言。
1.3 web开发架构和技术
- 客户端技术:HTML、CSS、JavaScript等,负责页面展示和用户交互。
- 服务器端技术:处理客户端请求,生成动态内容,如Java、Python、 PHP等。
- 数据库技术:存储和管理Web应用数据,如MySQL、SQL Server、 Oracle等。
1.4 web的工作原理
- 浏览器:请求服务器获取Web页面,解析并展示给用户。
- 服务器:接收浏览器请求,生成并发送HTML网页等资源。
- HTTP协议:浏览器与服务器之间的通信协议,基于请求-响应模式。
1.5 web应用的工作机制
- 用户通过浏览器输入URL,向服务器发送HTTP请求。
- 服务器接收请求,处理并生成响应(如HTML页面)。
- 浏览器接收响应,解析并展示页面给用户。
1.6 域名概述
-
域名的产生:IP地址不易记忆
-
早期使用Hosts文件解析域名:主机名称重复、主机维护困难
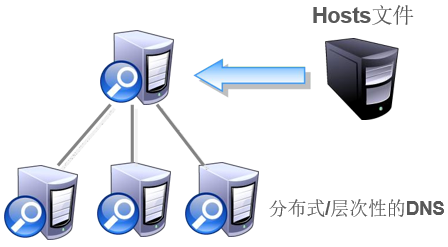
-
DNS(Domain Name System,域名系统):分布式、层次性
-
域名空间结构
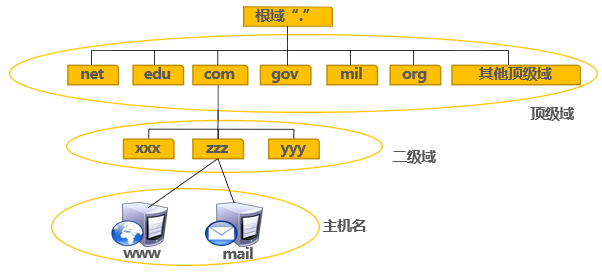
- 根域
- 顶级域
- 组织域
- 国家/地区域名
- 二级域
- FQDN=主机名.DNS后缀
-
域名注册
域名注册是Internet中用于解决地址对应问题的一种方法
遵循先申请先注册原则
域名注册步骤:准备申请资料→寻找域名注册网址→查询域名→正式申请→申请成功
1.7 网页的概念
-
网页
纯文本格式文件
编写语言为HTML
在用户的浏览器中被“翻译”成网页形式显示出来 -
网站
由一个一个页面构成的,是多个网页的结合体
-
主页
打开网站后出现的第一个网页称为网站主页(或首页)
-
域名
浏览网页时输入的网址
-
HTTP
用来传输网页的通信协议
-
URL
一种万维网寻址系统
-
HTML
用来编写网页的超文本标记语言
-
超链接
将网站中不同网页链接起来的功能
-
发布
将制作好的网页上传到服务器供用户访问的过程
1.8 web版本
-
web1.0
以编辑为特征,网站提供给用户的内容是编辑处理后的,然后用户阅读网站提供的内容,这个过程是网站到用户的单向行为。
-
web2.0
更注重用户的交互作用,用户既是网站内容的消费者(浏览者),也是网站内容的制造者。
加强了网站与用户之间的互动,网站内容基于用户提供,网站的诸多功能也由用户参与建设,实现了网站与用户双向的交流与参与。
Web2.0特征:用户分享、以兴趣为聚合点的社群、开放的平台,活跃的用户
1.9 静态网页
-
静态网页是标准的HTML文件
-
扩展名是.htm、.html
文本、图像、声音、Flash动画、客户端脚本和ActiveX控件及Java小程序等
-
是网站建设的基础,早期网站一般都由静态网页制作
-
没有后台数据库、不含程序和不可交互的网页
-
相对更新起来比较麻烦,适用于一般更新较少的展示型网站
-
特点:
每个静态网页都有一个固定的URL,且URL以.htm、.html、.shtml等常见形式为后缀,而不含有 “?”。
网页内容一经发布到网站服务器上,无论是否有用户访问,每个静态网页都是保存在网站服务器上的。
静态网页的内容相对稳定,容易被搜索引擎检索。静态网页没有数据库的支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作方式比较困难。
静态网页的交互性较差,在功能方面有较大的限制。
页面浏览速度迅速,过程无需连接数据库,开启页面速度快于动态页面。
1.10 动态网页
-
网页 URL不固定,能通过后台与用户交互
-
在动态网页网址中有一个标志性的符号——“?”
-
常用的语言有PHP、JSP、Python、Ruby等。
-
特点:
-
交互性
网页会根据用户的要求和选择而动态改变和响应,将浏览器作为客户端界面,这将是今后WEB发展的大势所趋
-
自动更新
无须手动地更新HTML文档,便会自动生成新的页面,可以大大节省工作量
-
因时因人而变
当不同的时间,不同的人访问同一网址时会产生不同的页面
-
2 HTTP协议
HTTP(HyperTextTransferProtocol,超文本传输协议),是一个工作在应用层的协议,它通常运行在 TCP之上,它指定了客户端以什么样的格式发送信息,以及得到什么样的响应信息。
2.1 HTTP 的起源与标准化历程
HTTP 协议,作为互联网基石之一,其发展可以追溯到 1989 年,由 蒂姆·伯纳斯·李 博士在欧洲核子研究组织(CERN)首次提出。这一创举不仅催生了万维网(www)的诞生,还奠定了 HTTP 作为互联网内容传输核心协议的地位。
随后,HTTP 的标准制定工作由两大权威组织 —— 万 维网协会(W3C)与互联网工程任务组(IETF)携手推进。经过多轮讨论和迭代。HTTP 1.1 标准最终于 1999年以 RFC 2616 的形式正式发布,这一版本至今仍广泛应用于全球互联网,支持着数以亿计的网络请求与响应。
2.2 HTTP/2的崛起与标准化
进入 21 世纪后,随着互联网的飞速发展,HTTP 1.1 在性能上的局限性逐渐显现。
为此 IETF 的 httpbis 工作小组于 2014 年启动了 HTTP/2标准的制定工作,旨在通过引入头部压缩、多路复用以及服务器推送等创新机制,显著提升 HTTP 协议的性能和效率。经过紧锣密鼓的研发与测试,HTTP/2 标准于 2015 年 5 月正式获得批准并以 RFC 7540 的形式发布,标志着 HTTP 协议迈进了一个全新的发展阶段。
如今,HTTP/2 已成为众多现代网站和应用的首选协议,为用户带来更加流畅、快速的浏览体验。
2.3 HTTP/3的崛起
HTTP/3是为了处理HTTP/2.0的传输相关问题而生的,可以在各种设备上更快地访问Web。它基于一个新的传输层协议,称为QUIC(Quick UDP Internet Protocol),在UDP之上工作。
当IETF正式标准化HTTP/2时,Google正在独立构建一个新的传输协议,名为gQUIC。它后来成为新互联网草案,并被命名为QUIC。
gQUIC最初的实验证明,在网络条件较差的情况下,gQUIC在增强网页浏览体验方面的效果非常好。因此,gQUIC的发展势头越来越好, IETF的大多数成员赞成建立一个在QUIC上运行的HTTP新规范。这个新的倡议被称为HTTP/3,以区别于当前的HTTP/2标准。
从语法和语义上看,HTTP/3与HTTP/2相似。HTTP/3遵循相同的请 求和响应消息交换顺序,其数据格式包含方法、标题、状态码和body。然而,HTTP/3的显著的偏差在于协议层在UDP之上的堆叠顺序。
2022年6月6日,IETF(互联网工程任务小组)正式发布了HTTP/3的RFC 9114。
主要特性:
基于UDP:HTTP/3使用基于UDP的QUIC协议,而不是传统的TCP。
多路复用:解决了HTTP/2中的队头阻塞问题,允许在单个连接上同时传输多个请求和响应。
内置加密:QUIC协议默认集成了TLS 1.3,提供了与HTTPS相同级别的安全性。
更快的连接建立:通常只需要一个往返时间(RTT)就可以建立加密连接。
目前,Cloudflare、Google Chrome、Firefox Nightly等均已表示支持 HTTP/3。
2.4 HTTP协议工作原理
在Web应用中,浏览器请求一个URL,服务器就把生成的HTML网页发送给浏览器,而浏览器和服务器之间的传输协议是HTTP,所以:
HTML是一种用来定义网页的文本,会HTML,就可以编写网页
HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信
HTTP协议是一个基于TCP协议之上的请求-响应协议,先使用任一浏览器查看网页,然后选择”开发者模式” 就可以看到HTML;切换到Network,重新加载页面,可以看到浏览器发出的每一个请求和响应;
对于Browser来说,请求页面的流程如下:
与服务器建立TCP连接
发送HTTP请求
收取HTTP响应,然后把网页在浏览器中显示出来
-
浏览器发送的HTTP请求如下:

第一行表示使用GET请求获取路径为/的资源,并使用HTTP/1.1协议
从第二行开始,每行都是以Header: Value形式表示的HTTP头,比较常用的 HTTP Header包括:
Host: 表示请求的主机名,因为一个服务器上可能运行着多个网站,因此,Host表示浏览器正在请求的域名;
User-Agent: 标识客户端本身,例如Chrome浏览器的标识类似Mozilla/5.0 …
Chrome/79,IE浏览器的标识类似Mozilla/5.0 (Windows NT …) like Gecko;
Accept:表示浏览器能接收的资源类型,如text/*,image/或者/*表示所有;
Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页;
Accept-Encoding:表示浏览器可以支持的压缩类型,例如gzip, deflate, br。 -
服务器的响应如下:

服务器响应的第一行总是版本号+空格+数字+空格+文本,数字表示响应代码。其中2xx表示成功,3xx表示重定向,4xx表示客户端引发的错误,5xx表示服务器端引发的错误。数字是给程序识别,文本则是给开发者调试使用的。
从第二行开始,服务器每一行均返回一个HTTP头。服务器经常返回的HTTP Header包括:
Content-Type:表示该响应内容的类型,例如text/html, image/jpeg
Content-Length:表示该响应内容的长度(字节数)
Content-Encoding:表示该响应压缩算法,例如gzip
Cache-Control:指示客户端应如何缓存,例如max- age=300表示可以最多缓存300秒 -
常见的响应码:
200 OK:表示成功;
301 MovedPermanently:表示该URL已经永久重定向;
302 Found:表示该URL需要临时重定向;
304 NotModified:表示该资源没有修改,客户端可以使用本地缓存的版本;
400 BadRequest:表示客户端发送了一个错误的请求,例如参数无效;
401 Unauthorized:表示客户端因为身份未验证而不允许访问该URL;
403 Forbidden:表示服务器因为权限问题拒绝了客户端的请求;
404 NotFound:表示客户端请求了一个不存在的资源;
500 InternalServerError:表示服务器处理时内部出错,例如因为无法连接数据库;
503 ServiceUnavailable:表示服务器此刻暂时无法处理请求;
HTTP请求和响应都由HTTP Header和HTTP Body构成,其中HTTP Header每行都以==\r\n==结束。
如果遇到两个连续的\r\n,那么后面就是HTTP Body。浏览器读取HTTP Body,并根据Header信息中指示的 Content-Type、Content-Encoding等解压后显示网页、图像或其他内容。
通常浏览器获取的第一个资源是HTML网页,在网页中,如果嵌入了JavaScript、CSS、图片、视频等其他资源,浏览器会根据资源的URL再次向服务器请求对应的资源。
2.5 HTTP方法
HTTP协议有多种获得Web资源的方法
常用的方法:GET和POST
| HTTP方法 | 描述 |
|---|---|
| GET | 请求获取Request-URI所标识的资源 |
| PUT | 请求服务器存储一个资源,并用Request-URI作为其标识 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| POST | 在Request-URI所标识的资源后附加新的数据 |
| HEAD | 请求获取由Request-URI所标识的资源的响应消息报头 |
2.5.1 GET方法
GET方法:从指定的服务器上获得数据
GET请求能被缓存
GET请求会保存在浏览器的浏览纪录里
GET请求有长度的限制
主要用于获取数据
查询的字符串会显示在URL中,不安全
2.5.2 POST方法
POST方法:提交数据给指定服务器处理
POST请求不能被缓存
POST请求不会保存在浏览器的浏览纪录里
POST请求没有长度限制
查询的字符串不会显示在URL中,比较安全

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)