传统RAG与Graph RAG的区别
摘要: 检索增强生成(RAG)技术通过整合外部知识库弥补大语言模型的缺陷(知识局限、幻觉问题等),其标准流程包括知识库构建、检索和生成三阶段。然而传统RAG存在检索碎片化、缺乏全局语义等问题。Graph RAG作为升级方案,将知识图谱与大模型结合,利用图结构表达实体间的关联关系,实现多跳推理和动态知识演化,显著提升复杂语境下的信息检索与生成质量。这一技术突破更贴近人类认知模式,为知识密集型任务提供
以输出倒逼自己输入
一,检索增强技术的由来
为什么需要RAG?
尽管大语言模型展现出惊人的通用能力,但其固有缺陷推动了检索增强生成(Retrieval-Augmented Generation, RAG)技术的发展:
- 知识的局限性:受限于训练数据的时效性和封闭性,难以动态融入实时更新的公共数据或企业内部的专有知识;
- 幻觉现象:模型可能生成看似合理实则错误或虚构的内容,导致事实性错误;
- 上下文限制:固定长度的上下文窗口限制了复杂场景下的深度推理能力。
检索增强生成(Retrieval-Augmented Generation)技术是由Facebook AI团队于2020年提出的创新范式,其核心在于构建「检索→融合→生成」的协同机制:先通过信息检索从海量文档库中精准召回相关知识片段,再将这些证据注入语言模型作为生成依据,从而显著提升回答的事实性和逻辑性。这种架构既保留了预训练模型的强大生成能力,又突破了其知识边界的限制。
二,传统RAG技术
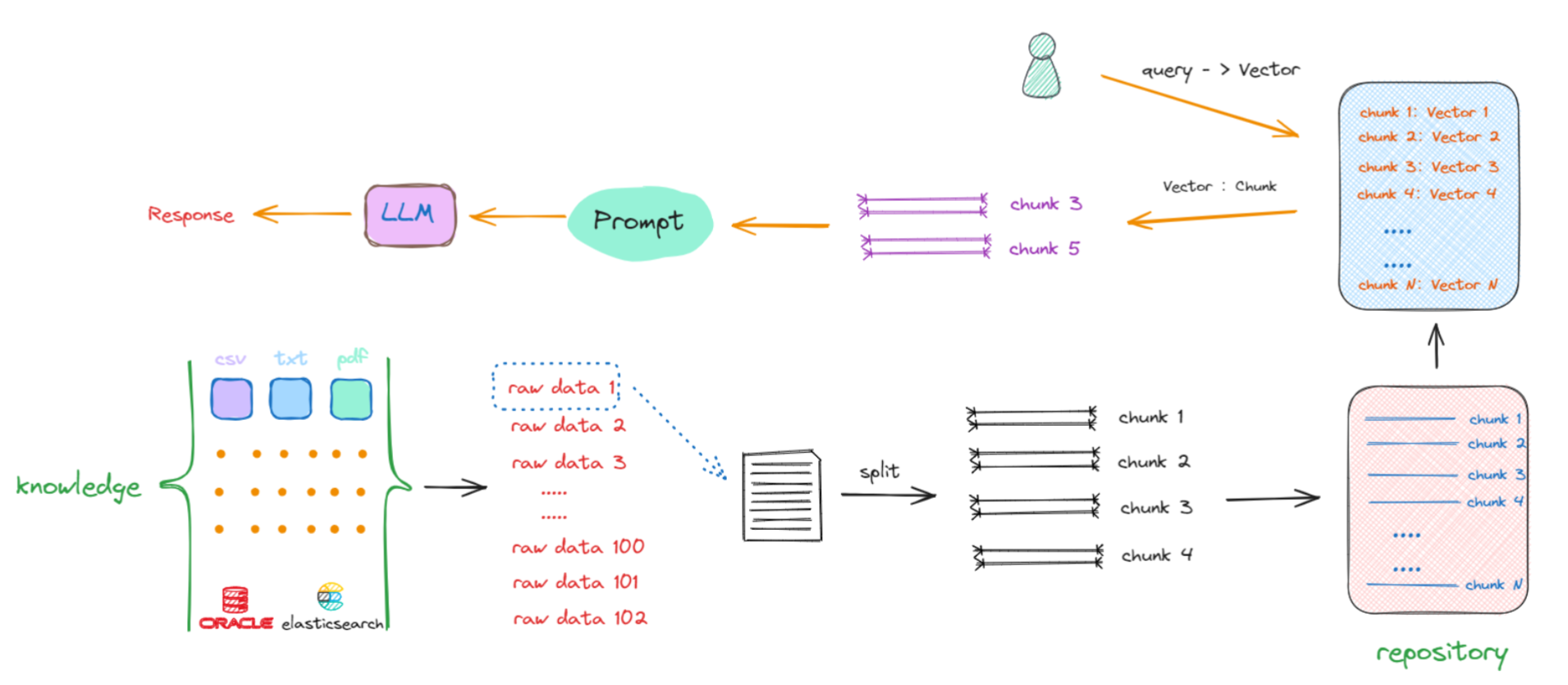
RAG(Retrieval-Augmented Generation)的核心目标是通过整合外部知识库的信息,辅助大语言模型生成兼具准确性与丰富性的文本内容。其标准实施流程包含以下关键环节:
RAG实现的流程:
- 知识库构建
- 数据采集:支持多种格式文档接入(Word/TXT/PDF/CSV等),兼容结构化与非结构化数据;
- 分块处理:按预设规则(如字符数限制、语义单元划分)将文档拆解为可管理的文本块;
- 向量化转换:使用嵌入模型(Embedding Model)将文本块转化为向量表示,存储至向量数据库(如FAISS/Pinecone),实现高效的语义检索。
- 检索模块
- 查询编码:将用户输入的自然语言问题通过相同嵌入模型转换为查询向量;
- 相似度匹配:在向量空间中快速定位与查询语义最接近的文本块,并返回相关性最高的前N个结果;
- 上下文过滤:可选地应用元数据筛选(如时间范围、文档类别)提升检索精度。
- 生成模块
- 上下文整合:将
原始问题与检索得到的关联文本共同注入提示模板; - 答案生成:大语言模型基于增强后的上下文信息进行推理,输出兼顾事实准确性与语言流畅性的最终答案。
- 上下文整合:将
三,Graph RAG技术
传统RAG技术存在的问题
- 检索结果缺乏全局语义协调:基于向量相似度的检索本质是局部最优解,可能遗漏全局视角下更重要的关联信息。
- 结构化知识表达能力弱:真实世界的知识天然具有层级和关联(如组织结构图、产品分类树、科研范式演进)。纯文本检索难以捕捉实体间的拓扑关系(父子/包含/并列/时序等)。
- 上下文碎片化:传统 RAG 仅检索局部相关的文本片段(Chunks),导致模型只能看到孤立的「证据岛」。当问题涉及跨段落的逻辑推理(如因果链、时间线、多步骤推导)时,分散的片段难以支撑完整语境。
Graph RAG技术
Graph RAG 技术是对传统 RAG 架构的重要升级,其核心在于将知识图谱与大语言模型深度融合。相较于传统 RAG 仅向模型输入非结构化文本块的方式,Graph RAG 额外提供结构化实体信息——包括实体本身的文本描述、属性特征及其与其他实体的关系网络。这种融合使每个输入记录具备更丰富的上下文表征,显著提升了模型对专业术语、复杂概念及跨实体关联关系的理解能力。
其核心优势在于:
- 从平面到立体:将一维文本序列升级为多维知识网络
- 从被动匹配到主动推理:利用图结构引导模型进行可控的多跳推理
- 从静态快照到动态系统:支持知识的持续演化和实时推理
这种演进符合认知科学原理——人类专家解决问题时,依赖的不是孤立的事实碎片,而是大脑中组织良好的知识网络。
图结构的优势就在于:可以在图谱中建立实体之间的关系,从而可以更全面的检索到全局的信息。
如此一来在进行检索时,就可以从图谱中检索到与问题相关的所有信息,从而可以更全面的检索到全局
的信息。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)