CVPR 2025丨关于图像生成,研究生不必深究底层逻辑,会用就行
如今CVPR的图像生成领域,早已不是单纯比拼生成精度的内卷战场了。从近年顶会文章来看,产出依然旺盛,只是玩法变了——不再是死磕生成网络的层与块,而是转向了跨界融合的深水区。比如和扩散模型、3D 重建、语义理解、多模态大模型这些方向深度绑定… 当然,想在主流会议崭露头角,“融合” 得有真东西,不然连对比实验都撑不起说服力。另外当下火热的可控生成、动态场景生成、低资源图像合成等也是值得深耕的小方向,尤
关注gongzhonghao【CVPR顶会精选】
如今CVPR的图像生成领域,早已不是单纯比拼生成精度的内卷战场了。从近年顶会文章来看,产出依然旺盛,只是玩法变了——不再是死磕生成网络的层与块,而是转向了跨界融合的深水区。
比如和扩散模型、3D 重建、语义理解、多模态大模型这些方向深度绑定… 当然,想在主流会议崭露头角,“融合” 得有真东西,不然连对比实验都撑不起说服力。另外当下火热的可控生成、动态场景生成、低资源图像合成等也是值得深耕的小方向,尤其通用图像生成框架,已有多篇顶会代表作,显然是未来几年的核心赛道。今天小图给大家精选3篇CVPR有关图像生成方向的论文,请注意查收!
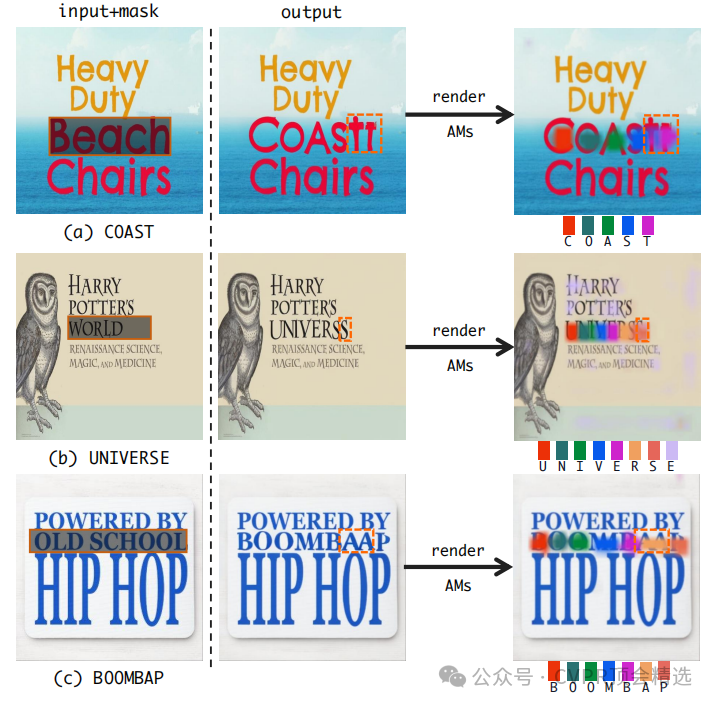
论文一:DREAMTEXT: High Fidelity Scene Text Synthesis
方法:
文章首先利用交叉注意力图生成潜在字符掩码,提取字符的潜在位置信息,并通过精心设计的损失函数迭代优化文本编码器和U-Net。接着,采用启发式交替优化策略,动态交替优化字符嵌入和重新估计字符生成位置。最后,通过平衡监督策略,在训练初期辅助校准字符注意力,之后逐步释放模型的灵活性,使其能够自主学习字符的最佳生成位置。

创新点:
-
提出了DREAMTEXT方法,通过重构扩散训练过程,有效解决了现有方法在多风格场景下字符重复、缺失和扭曲的问题。
-
设计了一种启发式交替优化策略,实现了字符表示学习与字符注意力重新估计之间的协同作用。
-
提出了一种平衡监督策略,在训练初期辅助校准字符注意力,平衡了对模型的约束与灵活性。
论文链接:
https://arxiv.org/abs/2405.14701
图灵学术论文辅导
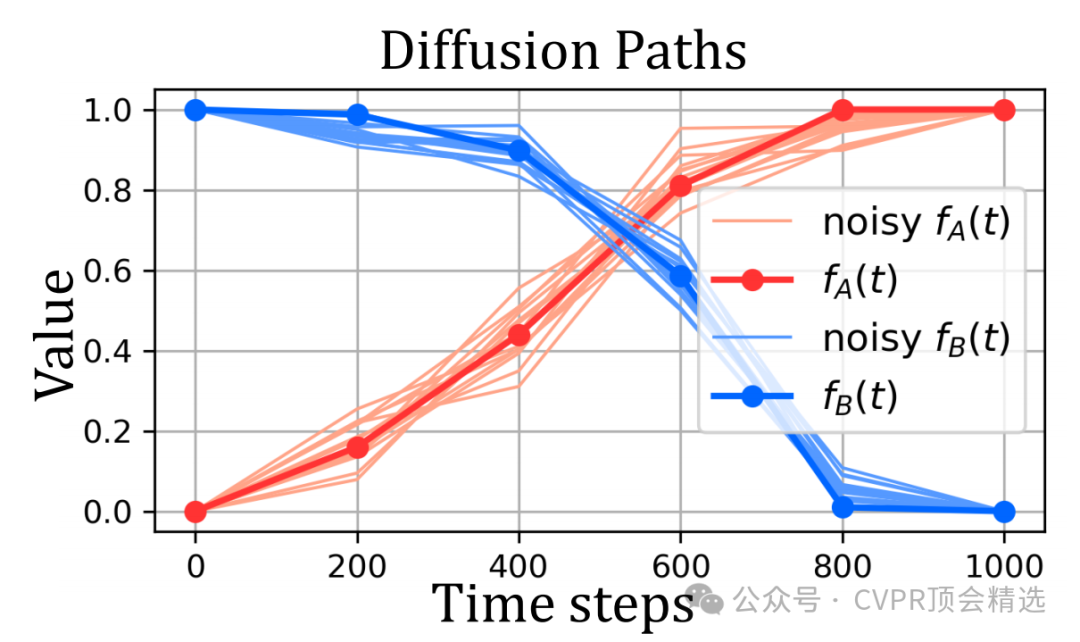
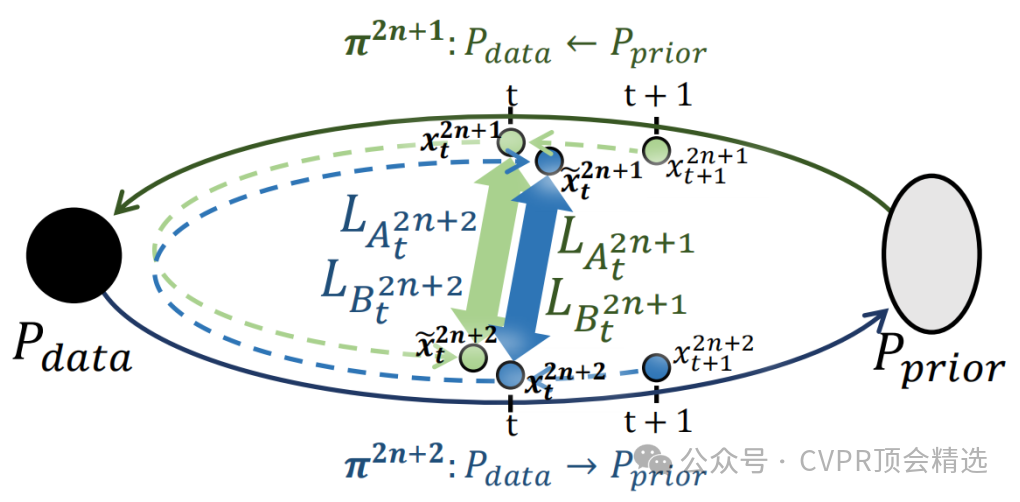
论文二:Finding Local Diffusion Schr¨odinger Bridge using Kolmogorov-Arnold Network
方法:
文章首先对扩散路径进行重新参数化建模,定义了由图像和噪声权重生成的扩散路径子空间。接着,通过迭代优化路径权重,利用IPF策略在该子空间内寻找局部扩散薛定谔桥,从而提升图像生成质量。最后,采用KAN来优化扩散路径,利用其抗遗忘和连续输出的特性,实现了高效且低计算成本的路径优化。
创新点:
-
首次提出在扩散路径子空间中寻找局部扩散薛定谔桥,简化了训练过程,显著提升了图像生成质量。
-
建立了扩散路径子空间的重新参数化模型,实现了时间步之间的更准确连接,并提出了基于迭代比例拟合的优化策略。
-
采用Kolmogorov-Arnold网络优化扩散路径,能够有效提升优化效果且模型大小小于0.1MB。
论文链接:
https://arxiv.org/html/2502.19754v2
图灵学术论文辅导
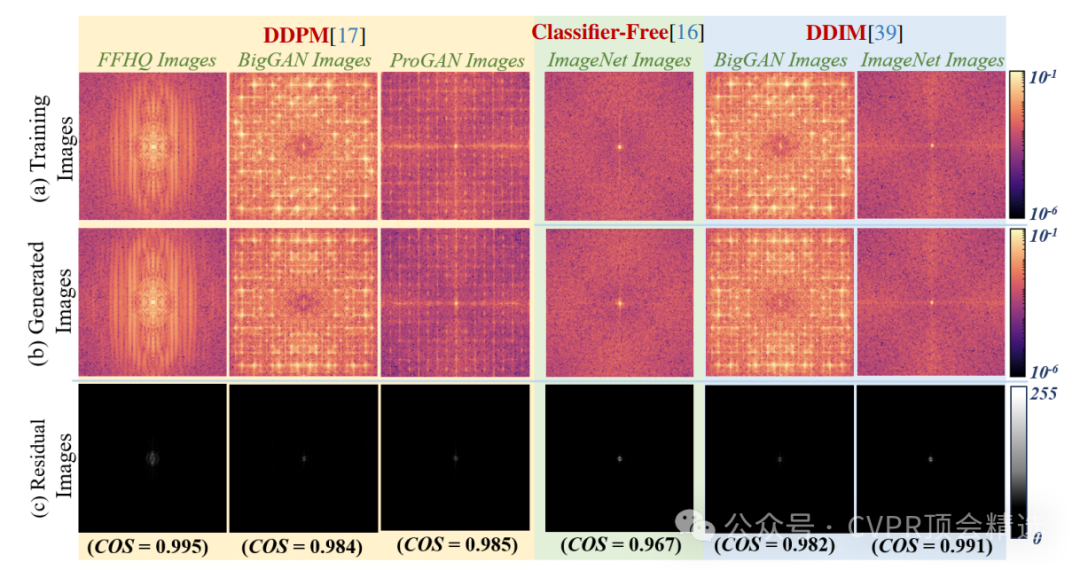
论文三:Harnessing Frequency Spectrum Insights for Image Copyright Protection Against Diffusion Models
方法:
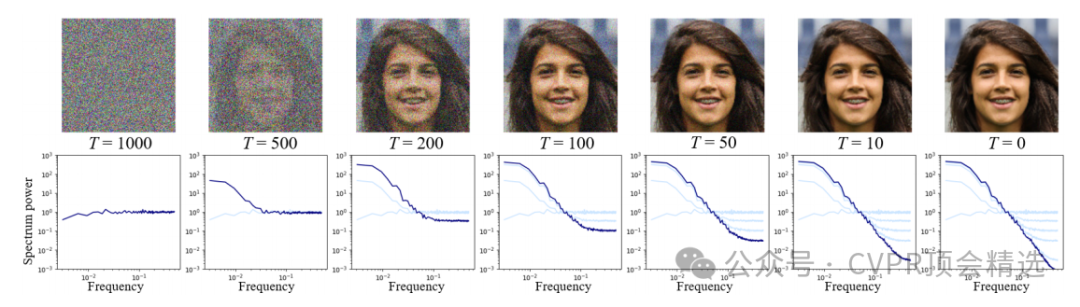
文章首先通过实验分析发现扩散模型生成的图像在频谱上与训练数据高度相似,基于这一发现,设计了CoprGuard框架。该框架利用HiNet在图像的离散小波变换域嵌入水印,并提出信息增强模块以对抗自编码器对水印的削弱。在检测阶段,通过比较从可疑模型生成的图像中提取的水印与原始水印的相似度,判断模型是否使用了未经授权的图像。
创新点:
-
首次发现扩散模型生成的图像保留了训练数据的统计特性,尤其是频谱特征,为版权保护提供了新的视角。
-
提出了CoprGuard框架,能够在训练数据中只有少量水印图像时,依然准确检测出未经授权的图像使用。
-
该框架对多种扩散模型均有效,且对图像质量和模型训练过程影响极小。
论文链接:
https://arxiv.org/abs/2503.11071
本文选自gongzhonghao【CVPR顶会精选】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)