论文reading学习记录8 - daily - VAD精读
文章目录
前言
忙忙忙。。。
一、题目与摘要
DRAMA: An Efficient End-to-end Motion Planner for Autonomous Driving with Mamba
高效自动驾驶的矢量化场景表示
以前的工作依赖于dense光栅化场景表示(例如,agent占用和语义图)来执行规划,这是计算密集型的,并且错过了实例级结构信息。
所以我们提出了VAD,这是一种端到端的自动驾驶矢量化范式,它将驾驶场景建模为完全矢量化的表示。
所提出的矢量化范式有两个显著的优点:
- VAD利用矢量化的代理运动和映射元素作为显式的实例级规划约束,有效地提高了规划安全性
- VAD通过摆脱计算 dense光栅化表示 和手工设计的后处理步骤,运行速度比以前的端到端规划方法快得多
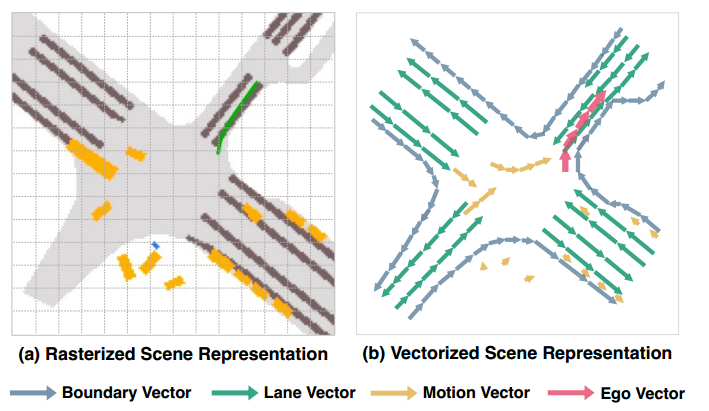
(a)使用光栅化表示进行规划(例如语义图、占用图、流程图和成本图),这是计算稠密型的。
(b)VAD端到端规划的矢量化场景表示,VAD利用实例级结构信息作为规划约束和指导,实现了有前景的性能和效率。
二、引言
传统的自动驾驶方法[23,14,7,48]采用模块化范式,将感知和规划解耦为独立模块。缺点是,规划模块无法访问包含丰富语义信息的原始传感器数据。由于规划完全基于先前的感知结果,感知错误可能会严重影响规划,在规划阶段无法识别和纠正,从而导致安全问题
最近,端到端的自动驾驶方法[19,21,2,11]将传感器数据作为感知的输入,并通过一个整体模型输出规划结果。一些作品[40,9,41]直接基于传感器数据输出规划结果,而不需要学习场景表示,这缺乏可解释性,难以优化。
大多数工作[19,21,2]将传感器数据转换为光栅化用于规划的场景表示(例如,语义图、占用图、流程图和成本图)。虽然很简单,但光栅化表示在计算上很密集,会遗漏关键的实例级结构信息。
在这项工作中,我们提出了VAD(矢量化自动驾驶),这是一种用于自动驾驶的端到端矢量化范式。VAD以完全矢量化的方式(即矢量化的代理运动和建图)对场景进行建模,摆脱了计算密集型的光栅化表示。
我们认为矢量化场景表示优于光栅化场景表示,原因如下:
- 矢量化地图,分为边界矢量和车道矢量,提供道路结构信息(例如交通流量、可行驶边界和车道方向);
- 帮助自动驾驶汽车缩小轨迹搜索空间并规划合理的未来轨迹;
- 交通参与者的运动(表示为agent运动矢量)为避免碰撞提供了实例级限制;
- 矢量化场景表示在计算方面是高效的,这对现实世界的应用很重要。
主要贡献:
- VAD一种端到端的自动驾驶矢量化范式。VAD将驾驶场景建模为完全矢量化的表示,摆脱了计算密集光栅化表示和手工设计的后处理步骤。
- VAD通过查询交互和矢量化规划约束,隐式和显式地利用矢量化场景信息来提高规划安全性。
- 速度和精度我们第一。
补充:VAD利用矢量化信息来隐式和显式地指导规划。
– VAD采用 map queries和agent queries 从传感器数据中隐式学习实例级map特征和agent运动特征,并通过查询交互提取规划指导信息;
– VAD基于显式矢量化场景表示提出了三个实例级规划约束:自我-代理碰撞约束,用于在横向和纵向保持自我车辆与其他动态代理之间的安全距离;超越自我边界的约束,将规划轨迹推离道路边界;以及自我车道方向约束,用于通过矢量化车道方向来规范自动驾驶汽车的未来运动方向。
三、relate work
1. 感知
检测:DETR3D[47]使用3D查询对相应的图像特征进行采样,并在没有非最大抑制(NMS)的情况下完成检测。PETR[31]将3D位置编码引入图像特征,并使用检测查询通过注意力机制学习对象特征[46]。
鸟瞰图:BEV表示已经变得流行,并对感知领域做出了巨大贡献[26,51,17,29,8,34,28]。LSS[39]是一项开创性的工作,从BEV的视角将深度预测引入到项目特征中。BEVFormer[26]提出了空间和时间注意力,以更好地编码BEV特征图,并仅通过相机输入实现了显著的检测性能。FIERY[17]和BEVerse[51]使用BEV特征图来预测密集图分割。HDMapNet[25]通过后处理步骤将车道分割转换为矢量化地。VectorMapNet[32]以自回归的方式预测地图元素。MapTR[29]识别地图实例点的置换不变性,可以同时预测所有地图元素。LaneGAP[28]以一种新颖的路径方式对车道图进行建模,很好地保持了车道的连续性,并对交通信息进行了编码以进行规划。
我们利用一组BEV查询、代理查询和地图查询来完成BEVFormer[26]和==MapTR[29]==之后的场景感知,并在运动预测和规划阶段进一步使用这些查询特征和感知结果。详情见第3节。
2. 预测
传统的运动预测以感知地面实况(例如,代理历史轨迹和HD图)作为输入。一些作品[3,38]将驾驶场景渲染为BEV图像,并采用基于CNN的网络来预测未来的运动。其他一些工作[13,33,37]使用矢量化表示,并采用GNN[27]或Transformer[46,33,37].来完成学习和预测。
最近的端到端工作[17,51,15,22]联合执行感知和运动预测。一些作品[17,51,20]将未来的运动视为密集的占用和流动,而不是代理级的未来航路点。ViP3D[15]根据跟踪结果和高清地图预测未来的运动。PIP[22]提出了一种动态代理和静态矢量化映射之间的交互方案,并在不依赖HDmap的情况下实现了SOTA性能。受[22]的启发,VAD通过动态agent和静态地图元素之间的交互来学习矢量化代理运动。
3. 规划
最近,基于学习的规划方法盛行。一些作品[40,9,41]省略了感知和运动预测等中间阶段,直接预测规划轨迹或控制信号。虽然这个想法简单明了,但它们缺乏可解释性,难以优化。
强化学习非常适合规划任务,并已成为一个有前景的研究方向[45,4,4]。显式dense cost map具有很强的可解释性,被广泛使用[2,19,11,44]。成本图由感知或运动预测结果构建或来自基于学习的模块。
通常采用手工制定的规则来选择成本最低的最佳规划轨迹。密集成本图的构建是计算密集型的,使用手工制作的规则会带来鲁棒性和泛化问题。
UniAD[21]有效地整合了各种先前任务提供的信息,以目标为导向的精神协助规划,并在感知、预测和规划方面取得了显著成绩。PlanT[43]将感知地面真实作为输入,并将场景编码为对象级表示以进行规划。
本文探讨了矢量化场景表示在规划中的潜力,并摆脱了密集的地图或手工设计的后处理步骤。
四、方法
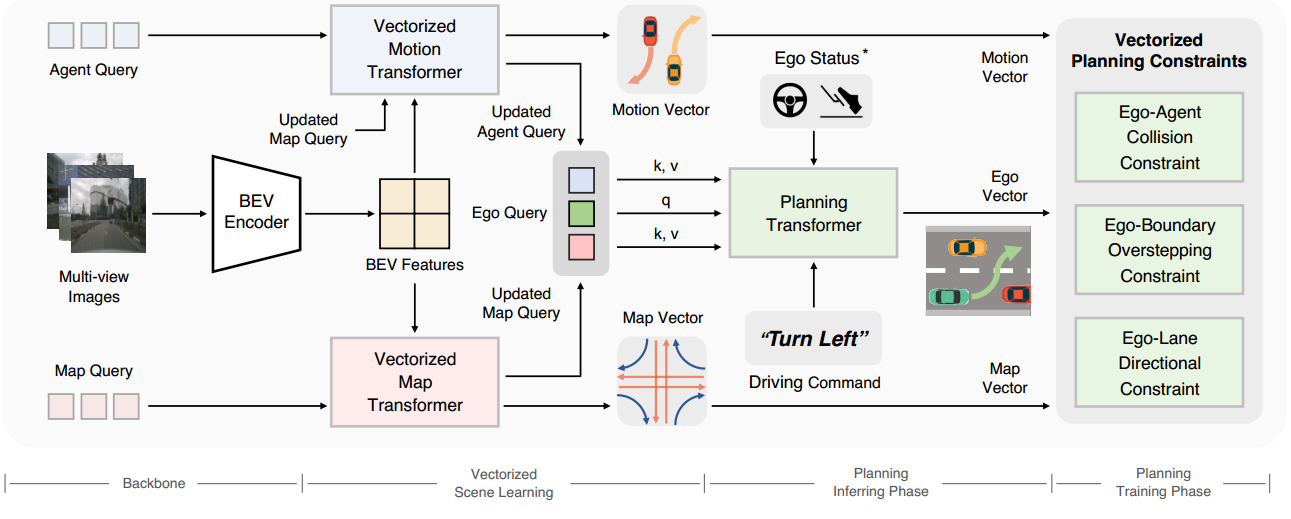 流程图:Backbone包括图像特征提取器和BEV编码器,用于将图像特征投影到BEV特征上。矢量化场景学习旨在将场景信息编码为代理查询和地图查询,并用运动矢量和地图矢量表示场景。在规划的推断阶段,VAD利用自我查询通过查询交互提取地图和代理信息,并输出规划轨迹(表示为自我向量)。所提出的矢量化规划约束使训练阶段的规划轨迹正则化。*代表可选。
流程图:Backbone包括图像特征提取器和BEV编码器,用于将图像特征投影到BEV特征上。矢量化场景学习旨在将场景信息编码为代理查询和地图查询,并用运动矢量和地图矢量表示场景。在规划的推断阶段,VAD利用自我查询通过查询交互提取地图和代理信息,并输出规划轨迹(表示为自我向量)。所提出的矢量化规划约束使训练阶段的规划轨迹正则化。*代表可选。
1. 概述
VAD的总体框架如图2所示。
- 输入:多帧和多视图图像,VAD首先使用骨干网络对图像特征进行编码,并利用一组BEV查询将图像特征投影到BEV特征上[26,39,52]。
- VAD利用一组代理查询和地图查询来学习矢量化场景表示,包括矢量化地图和矢量化代理运动(第3.1节)。
- 根据场景信息进行规划(第3.2节)。具体来说,VAD使用自我查询来学习隐含的场景信息(通过与代理查询和地图查询的交互)。
基于自我查询、自我状态特征和高级驾驶命令,规划头输出规划轨迹。 - VAD引入了三个矢量化规划约束,以在实例级别限制规划轨迹(第3.3节)。
- VAD是完全可微分的,并以端到端的方式进行训练(第3.4节)。
2. 矢量化场景学习:Vectorized Scene Learning
感知交通代理和地图元素在驾驶场景理解中非常重要。VAD将场景信息编码为查询特征,并通过地图矢量和代理运动矢量表示场景。
2.1 矢量地图
以前的工作[19,21(ST-P3)]使用光栅化的语义图来指导规划,这会错过图的关键实例级结构信息。VAD利用一组==地图查询[29]==Qm从BEV特征图中提取地图信息,并预测地图向量ˆVm∈R Nm×Np×2和每个地图向量的类别得分,其中Nm和Np表示预测的地图向量的数量和每个地图矢量中包含的点。
考虑了三种地图元素:车道分隔线、道路边界和人行横道。车道分隔器提供方向信息,道路边界指示可行驶区域。地图查询和地图向量都被用来提高规划性能(第3.2节和第3.3节)。
2.2 矢量化agent运动
VAD首先采用一组代理查询Qa,通过可变形注意力从共享的BEV特征图中学习agent级特征[53]。基于MLP的解码器头从代理查询中解码代理的属性(位置、类分数、方向等)。为了丰富运动预测的代理特征,VAD过**注意力机制(attention mechanism)**执行 agent-agent and agent-map。然后,VAD预测每个智能体的未来轨迹,表示为多模态运动向量Va∈R Na×Nk×Tf×2。Na、Nk和Tf表示预测的代理数量、模态数量和未来时间戳的数量。运动矢量的每种模态都表示一种驾驶意图。VAD输出每种模态的概率得分。
代理运动矢量用于限制自我规划轨迹并避免碰撞(第3.3节)。同时,代理查询作为场景信息发送到规划模块(第3.2节)。
3. 交互式规划:Planning via Interaction(隐式)
3.1 自我代理交互:Ego-Agent Interaction
VAD利用随机初始化的自我查询Qego来学习对规划有价值的隐含场景特征。
为了学习其他动态交通参与者的位置和运动信息,自我查询首先通过TransformerDecoder与代理查询交互[46]
TransformerDecoder输入:
----自我查询Qego作为注意力q的查询
----代理查询作为密钥k和值v
----感知模块预测的自我位置pego由单层MLP PE1编码得到qpos
----代理位置pa由单层MLP PE1编码得到kpos
位置嵌入提供了关于代理和自我载体之间相对位置关系的信息。上述过程可表述为: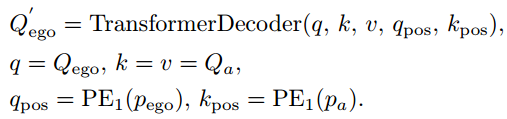
目的:在规划前,系统需要让自车“理解”周围 agent 的位置和运动状态,并建模它们与自车的交互关系。
输出:融合后的自车特征表示。
3.2 自我地图交互:Ego-Map Interaction
在与代理查询交互后,更新的自我查询Q′ego进一步以类似的方式与地图查询Qm交互。唯一的区别是我们使用不同的MLP PE2来编码自我载体和地图元素的位置。输出自我查询Q′'ego包含驾驶场景的动态和静态信息。公式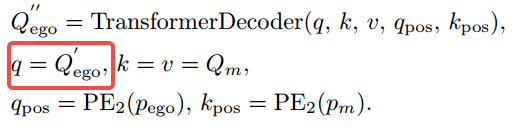
3.3 规划头
由于VAD执行无HDmap规划,因此导航需要高级驾驶命令。按照惯例[19,21],VAD使用三种驾驶命令:左转、右转和直行。因此,规划头将更新的自我查询(Q′ego,Q′′ego)和自我车辆sego的当前状态(可选)作为自我特征fego,以及驾驶命令c作为输入,并输出规划轨迹ˆVego∈R Tf×2。VAD采用简单的基于MLP的规划头。解码过程公式如下: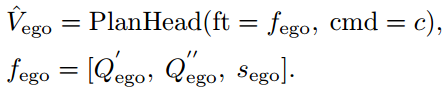
其中[…]表示级联操作,也就是把这些特征拼接成fego。cmd表示导航驱动命令。
Vego是一条覆盖未来 大约 3 秒(或者可能是 2–3 秒)的多点轨迹,每点按固定时间间隔离散输出。
4. 矢量化规划约束:Vectorized Planning Constraint(显式)
隐式和显式的解释:VAD 先用隐式方式让模型自己学会怎么规划(靠 map query / agent query),但在训练中再加上显式的几何约束,让模型在学的过程中被“拉回”到安全、合规的轨迹分布里。推理时这些约束不再计算,但模型已经形成了这样的习惯。
基于学习到的地图向量和运动向量,VAD在训练阶段用实例级矢量化约束对规划轨迹Vego进行正则化,如图3所示。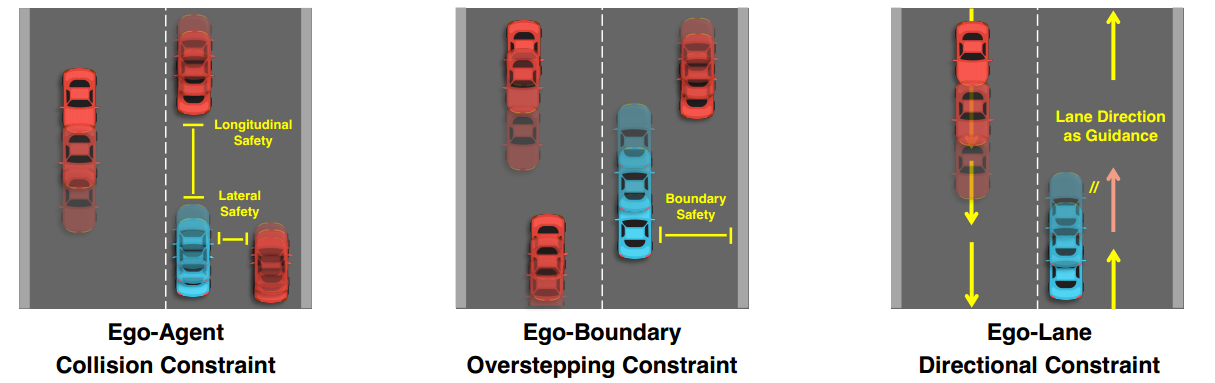
自我-代理碰撞约束:保持自我车辆与其他主体之间的纵向安全和横向安全。
超越自我边界约束:当规划轨迹过于接近车道边界时,会惩罚预测。
自我车道方向约束:利用自我汽车(右侧子图中的粉红色车道)的最接近车道矢量的方向,以规范规划的运动方向。
4.1 自我代理碰撞约束
Ego-agent碰撞约束明确考虑了自我规划轨迹与其他车辆未来轨迹的兼容性,以提高规划安全性并避免碰撞。与之前采用密集占用图的工作[19,21]不同,我们利用了矢量化运动轨迹,这既保持了很好的可解释性,又需要较少的计算。
具体来说,我们首先通过阈值ϵa过滤掉低置信度的代理预测。对于多模态运动预测,我们使用置信度最高的轨迹作为最终预测。我们认为碰撞约束是自我车辆横向和纵向的安全边界。
多辆汽车可能在横向方向上彼此靠近(例如并排行驶),但在纵向方向上需要更长的安全距离。因此,我们针对不同的方向采用不同的代理距离阈值δX和δY。对于每个未来的时间戳,我们在两个方向上都能在一定范围δa内找到最接近的代理。那么对于每个方向i∈{X,Y},如果与最接近代理的距离di a小于阈值δi,则该约束的损失项L i col=δi−d i a,否则为0。自我-代理碰撞约束的损失可以公式化为: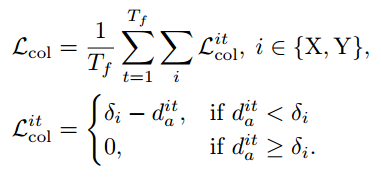
4.2 超越自我边界约束
该约束旨在将规划轨迹推离道路边界,以便轨迹可以保持在可驾驶区域内。我们首先根据阈值ϵm过滤掉低置信度图预测。然后,对于每个未来的时间戳,我们计算计划航路点与其最近的地图边界线之间的距离d t bd。δbd是映射边界阈值然后,该约束的损失公式为: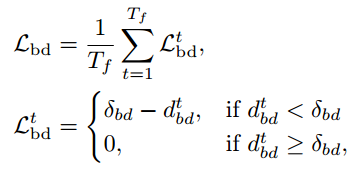
4.3 自我车道方向约束
Ego-lane方向约束来自一个前提,即车辆的运动方向应与车辆所在的车道方向一致。方向约束利用矢量化的车道方向来规范我们规划轨迹的运动方向。具体来说,首先,我们根据ϵm过滤掉低置信度图预测。
5. 端到端训练
5.1 矢量化场景学习损失
矢量化场景学习分为:
1. 矢量化地图学习
任务:学会预测地图元素(车道线、边界、交通标志等)的实例级矢量表示。
回归损失 (Manhattan/L1)
目的:让模型预测的地图点精确对齐真实地图点
解决问题:避免规划轨迹偏离道路结构(例如偏离车道线、压线)
方法:采用曼哈顿距离来计算预测地图点与地面真实地图点之间的回归损失。
分类损失 (Focal Loss)
目的:判断每个点属于哪种地图元素(车道、停止线、边界等)
2. 矢量化运动预测
任务:学会预测动态 agent(车辆、行人等)的运动轨迹和属性。
回归损失 (L1, minFDE)
目的:预测 agent 的位置、朝向、尺寸,以及未来轨迹
minFDE(最小最终位移误差, minimum final displacement error):在预测多条轨迹时选最接近真实轨迹的agent作为作为代表性预测。
分类损失 (Focal Loss)
目的:预测 agent 的类别(车辆/行人/自行车等),或轨迹模式
5.2 矢量化约束损失
矢量化约束损失由前面提出的三个约束组成,即自我代理碰撞约束Lcol、自我边界越界约束Lbd和自我车道方向约束Ldir,它们通过矢量化场景表示对规划轨迹Vego进行正则化。
5.3 模仿学习损失
模仿学习损失Limi是计划轨迹Vego和地面真实自我轨迹Vego之间的l1损失,旨在用专家驾驶指导规划轨迹。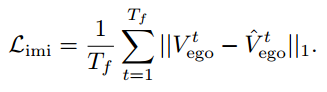
基于所提出的矢量化规划约束,VAD是端到端可训练的。端到端学习的总体损失是矢量化场景学习损失、矢量化规划约束损失和模仿学习损失的加权和。
五、总结
VAD利用矢量化信息来隐式和显式地指导规划。
– VAD采用 map queries和agent queries 从传感器数据中隐式学习实例级map特征和agent运动特征,并通过查询交互提取规划指导信息;
– VAD基于显式矢量化场景表示提出了三个实例级规划约束:自我-代理碰撞约束,用于在横向和纵向保持自我车辆与其他动态代理之间的安全距离;超越自我边界的约束,将规划轨迹推离道路边界;以及自我车道方向约束,用于通过矢量化车道方向来规范自动驾驶汽车的未来运动方向。(训练时约束)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)