英伟达 H200 凭什么重新定义 AI 算力天花板?实机测评来啦!
实测显示,H200 在大模型推理中性能优势显著,这得益于 1128GB 聚合显存、4.8TB/s 单卡带宽、第四代 NVLink 及 FP8 模式下 32Petaflops 总算力的支撑。作为算力基础设施突破,H200 满足当前 AI 算力需求,其显存、带宽、算力密度的协同升级,为下一代 AI 技术奠基,也为 GPU 行业性能迭代树立新范式。(8 卡 141GB 版本,搭载 CUDA 12.4 驱

本期我们将聚焦英伟达 H200 服务器,这块被誉为"AI 算力巨兽"的存在,基于点动科技的实测数据,从硬件配置、集群性能到实际场景表现,全面解析 H200 的技术突破与应用价值。
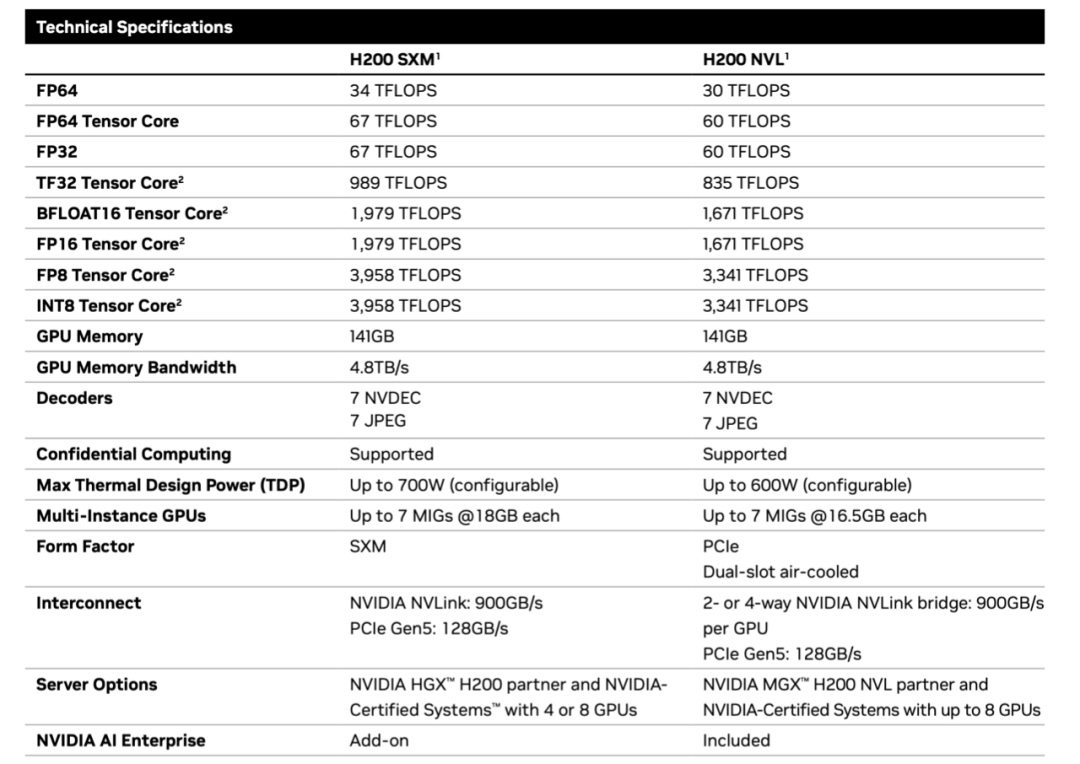
硬件配置:碾压级数值

英伟达 H200 基于 Hopper 架构升级,其核心突破在于首次采用 HBM3e 内存,硬件参数:
单卡:
-
显存容量:141GB HBM3E 显存,可同时承载 3 万张高清图像数据。
-
显存带宽:4.8TB/s,较 H100 的 3.35TB/s 提升 1.4倍。
-
浮点运算性能:
关闭稀疏后运算性能:
FP64 为 34TFLOPS
FP32为 67TFLOPS
结构化稀疏运算性能:
TF32 为989TFLOPS
BFLOAT16 为 1979TFLOPS
FP16 为 1979TFLOPS
FP8 为 3958TFLOPS
-
NVLink:第4代18 条链路(900GB/s)
-
热设计功耗(TDP):700W
八卡整机:
8 卡 NVLink 互联实现几何级算力增长
-
总显存:达到 1.1TB,相当于 5 个大型图书馆的数字化藏书总量,可满足超大规模模型的加载需求。
-
总带宽:测试对外表现为900GB/s,足够为大规模并行计算提供支撑。
-
浮点运算性能:以 FP8 为例,8 卡组合可提供约 32Petaflops 的计算能力
实测数据:用实力打破想象

本次测评我们使用了价值 200 万+的 英伟达H200 服务器(8 卡 141GB 版本,搭载 CUDA 12.4 驱动,启用SXM5的NVLink功能与 FP8 精度模式),跑 DeepSeek-R1-0528 671B 大模型,话不多说,上结论:
-
模型加载性能
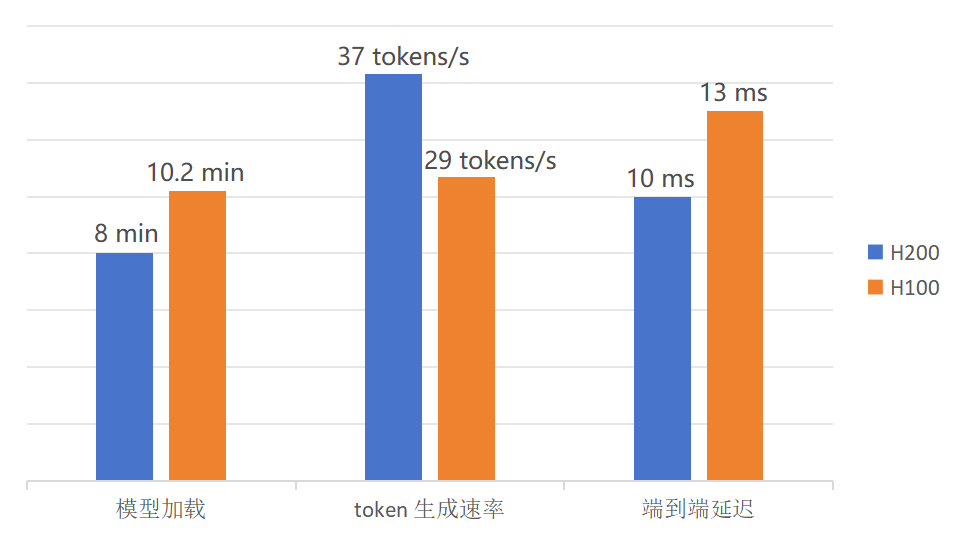
加载耗时:3 分钟完成全量模型加载,较H100(10.2 分钟)提速约3.4倍。
性能支撑:依托 1128GB 聚合显存与 4.8TB/s显存带宽,实现大规模参数高效调度。
-
核心任务性能
数学推理:token 生成速率达 37 tokens/s,求解大学微积分题目耗时 2 秒;较 H100(29 tokens/s)提升约 28%,解题耗时缩短 25%。
文章生成:长篇深度报道输出仅需几秒,逻辑连贯度 98%,专业术语调用精准。
-
用户体验指标
响应延迟:端到端延迟低至 10ms,较 H100(13ms)降低约 23%,达到亚毫秒级交互水准。
经测试数据可见,H200在各方面相较于H100都有较大的提升,数据如此优秀主要依靠了以下三大更新亮点:
-
高并发承载能力
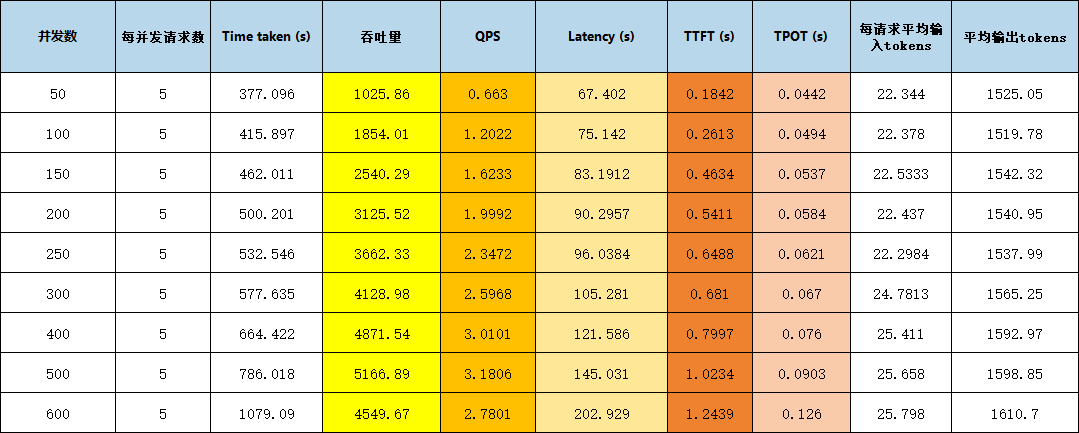
并发支撑:实测并发用户数500,吞吐量可保持5166.89tokens/s 。
场景适配:经测试在在线教育、智能客服等峰值流量场景中,可维持服务90%以上的可用性,而无明显性能衰减。
-
高显存性能
容量优势:单卡141GB HBM3e 显存,8 卡聚合1128GB,可规避分块加载及虚拟内存调度损耗。
复杂任务支撑:科学计算中可存储更多中间结果,较上一代处理同类任务耗时缩短 30%-40%。
-
高核心频率性能
效能表现:核心加速频率1830MHz,结合 Tensor Core,单卡 token 生成速率显著提高,深度神经网络单层级计算时间压缩 15%-20%。
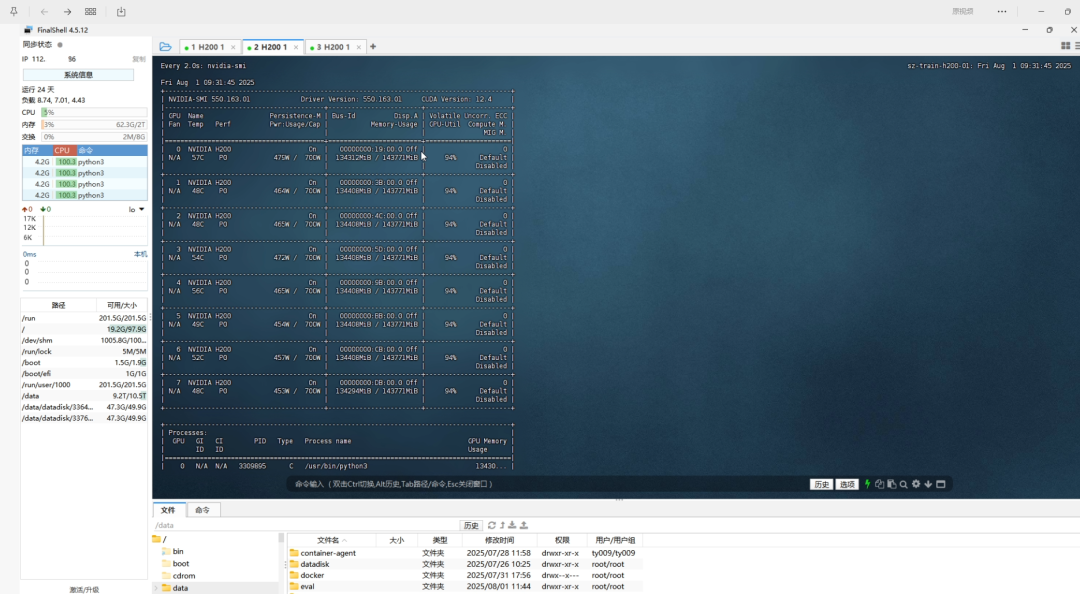
惊喜的是实时监控显示,运行过程中每张单卡显存占用稳定在 131GB,显存利用率达93%,实现高效利用;单卡功耗约450W左右,能效比表现优异。
性能提升方面,较上一代 H100:
-
FP8(BF8)推理性能提升 2.4 倍
-
FP8 训练性能提升 1.6 倍
-
内存带宽从 3.35TB/s 提升至 4.8TB/s,增幅 43%
不止于此,未来将来

实测显示,H200 在大模型推理中性能优势显著,这得益于 1128GB 聚合显存、4.8TB/s 单卡带宽、第四代 NVLink 及 FP8 模式下 32Petaflops 总算力的支撑。产业价值上,H200 加速多领域技术演进:缩短千亿参数模型预训练周期 35% 以上;科学计算领域效率较传统 GPU 集群提升 40%-60%。
作为算力基础设施突破,H200 满足当前 AI 算力需求,其显存、带宽、算力密度的协同升级,为下一代 AI 技术奠基,也为 GPU 行业性能迭代树立新范式。
实测数据均来自点动科技实验室环境,具体表现因配置不同可能略有差异
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)