EarthSynth Generating Informative Earth Observation with Diffusion Models
由于遥感图像固有的特性(类间相似性高、类内差异性大),模型解释面临挑战。为了从生成式扩散模型中获得信息量更丰富的数据分布,论文提出通过反事实合成来增强场景多样性。目标:构建一个尽可能接近真实世界分布D_real的训练数据分布D_train。方法:将现有的物体类别与多样化的背景上下文进行组合,创造出在现实中不存在但逻辑上合理的新场景。定义 1 (反事实合成)给定一组源元素,每个Ai代表从不同实例中提
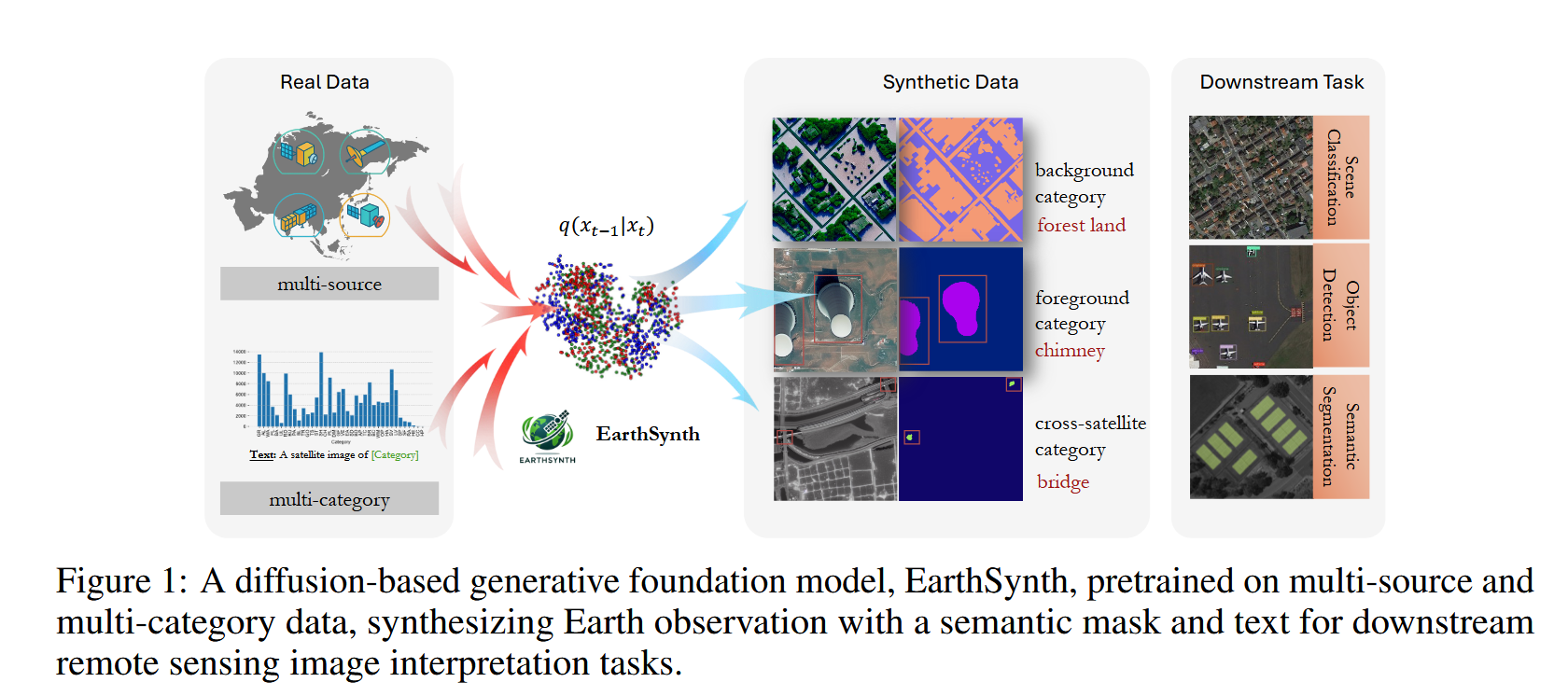
遥感图像解译通常因标注数据稀缺而面临挑战,这限制了遥感图像解译任务的性能。为应对这一挑战,我们提出了 EarthSynth,这是一个基于扩散的生成式基础模型,能够为下游的遥感图像解译任务合成多类别、跨卫星的带标签的地球观测数据。
据我们所知,EarthSynth 是首个探索遥感领域多任务生成的模型,它解决了面向任务的遥感图像合成中泛化能力有限的挑战。EarthSynth 在 EarthSynth-180K 数据集上进行训练,采用了“反事实合成”(Counterfactual Composition)训练策略和一种三维批次样本选择机制,以提高训练数据的多样性并增强对类别的控制能力。
此外,我们还提出了一种名为 R-Filter 的基于规则的方法,用以筛选出对下游任务更具信息量的合成数据。我们在开放世界场景下的场景分类、目标检测和语义分割任务上对 EarthSynth 进行了评估。在开放词汇(open-vocabulary)方面,其性能有显著提升。
Introduction
遥感图像解译[1]从根本上受到诸如严重类别不平衡[2]和高质量标注数据有限等挑战的制约,这严重阻碍了用于下游任务的鲁棒模型的发展。然而,为遥感图像标注通常需要领域专业知识以及大量的人工劳动,使得大规模标注工作既耗时又昂贵。因此,一个重要的研究目标是通过挖掘样本间的潜在关系,来有效利用现有的带标签的地球观测数据集,从而提高数据利用效率。
与此同时,生成式数据增强[3]领域的最新进展,特别是扩散模型[4],为合成高质量的带标签训练数据提供了一条充满前景的途径。使用扩散模型进行数据增强已广泛应用于多个领域[5]。先前的研究[6, 7]探讨了利用文本到图像模型[8]来提升数据稀缺场景下的分类性能,这为遥感领域带来了启发和灵感。此外,一些研究[9, 10]则致力于解决模型崩溃的风险,并通过自生成数据来提升生成质量。通过增广稀有类别和丰富数据多样性[11],这些模型在缓解数据稀缺和增强遥感图像解译的泛化能力方面可以发挥关键作用。与现有研究不同,我们的工作核心在于提升专为遥感应用定制的扩散模型的生成多样性。
在遥感领域,大多数现有的数据增强方法主要在单一来源的地球观测数据上进行训练,这本质上限制了生成类别的多样性,并且在更广泛的遥感应用中缺乏通用性和灵活性。然而,在多源数据上训练生成模型需要平衡生成数据的质量与多样性。Txt2Img-MHN[12]尝试使用生成对抗网络[13]来生成卫星图像。DiffusionSat[14]和CRS-Diff[15]提出了用于生成光学遥感图像的条件扩散模型,它们融入了多种基于纹理的条件,并将合成数据应用于道路提取等下游任务。GeoSynth[16]为卫星语义分割任务构建了图像与标签的联合数据流形。AeroGen[17]和MMO-IG[18]则尝试使用合成的训练数据进行卫星目标检测。然而,这些方法通常针对单一任务或单一来源数据进行训练,需要重复进行训练和生成才能满足多样化需求,这阻碍了它们在实际场景中的应用。
为解决上述问题,我们提出了 EarthSynth,这是一个基于扩散的生成式基础模型,它能够为下游的遥感图像解译任务合成带有语义掩码和文本的地球观测数据,如图1所示。首先,我们构建了包含多源、多类别数据的 EarthSynth-180K 数据集(共18万个样本),用于训练 EarthSynth。具体来说,我们从多个数据集中收集样本,并应用随机裁剪和类别增强策略来标准化图像分辨率,确保图像、语义掩码和文本描述之间的一致性。据我们所知,EarthSynth-180K 是首个用于扩散模型训练的大规模遥感数据集。在训练过程中,我们采用了“反事实合成”(Counterfactual Composition, CF-Comp)策略,将通道、像素和语义空间作为批次样本选择机制,以同时增强布局可控性和类别多样性,从而能够生成信息量更丰富的地球观测数据。与以往的研究不同,我们将 CF-Comp 策略应用于面向下游任务的、基于扩散的生成式基础模型训练中,避免了为每个下游任务重复训练特定任务的生成模型。在训练数据合成方面,我们提出了一种名为 R-Filter 的基于规则的方法,用以筛选出更具信息量的合成数据。我们在多个数据集上,通过场景分类、目标检测和语义分割任务对 EarthSynth 进行了评估。此外,通过全面的消融研究和可视化分析,我们证明了我们方法的有效性。
我们将主要贡献总结如下:
- 我们提出了 EarthSynth,这是一个基于扩散的生成式基础模型,在包含18万个跨卫星、多传感器样本的 EarthSynth-180K 数据集上进行训练,该数据集对齐了图像、语义掩码和文本,为实现多任务生成提供了一个统一的解决方案。
- EarthSynth 采用 CF-Comp 策略来平衡训练过程中的布局可控性和类别多样性,从而实现对遥感图像生成的精细布局控制。并集成了 R-Filter 后处理方法来提取信息量更丰富的合成数据。
- EarthSynth 在开放词汇场景下的场景分类、目标检测和语义分割任务上进行了评估,充分验证了其有效性。
其主体结构图如下: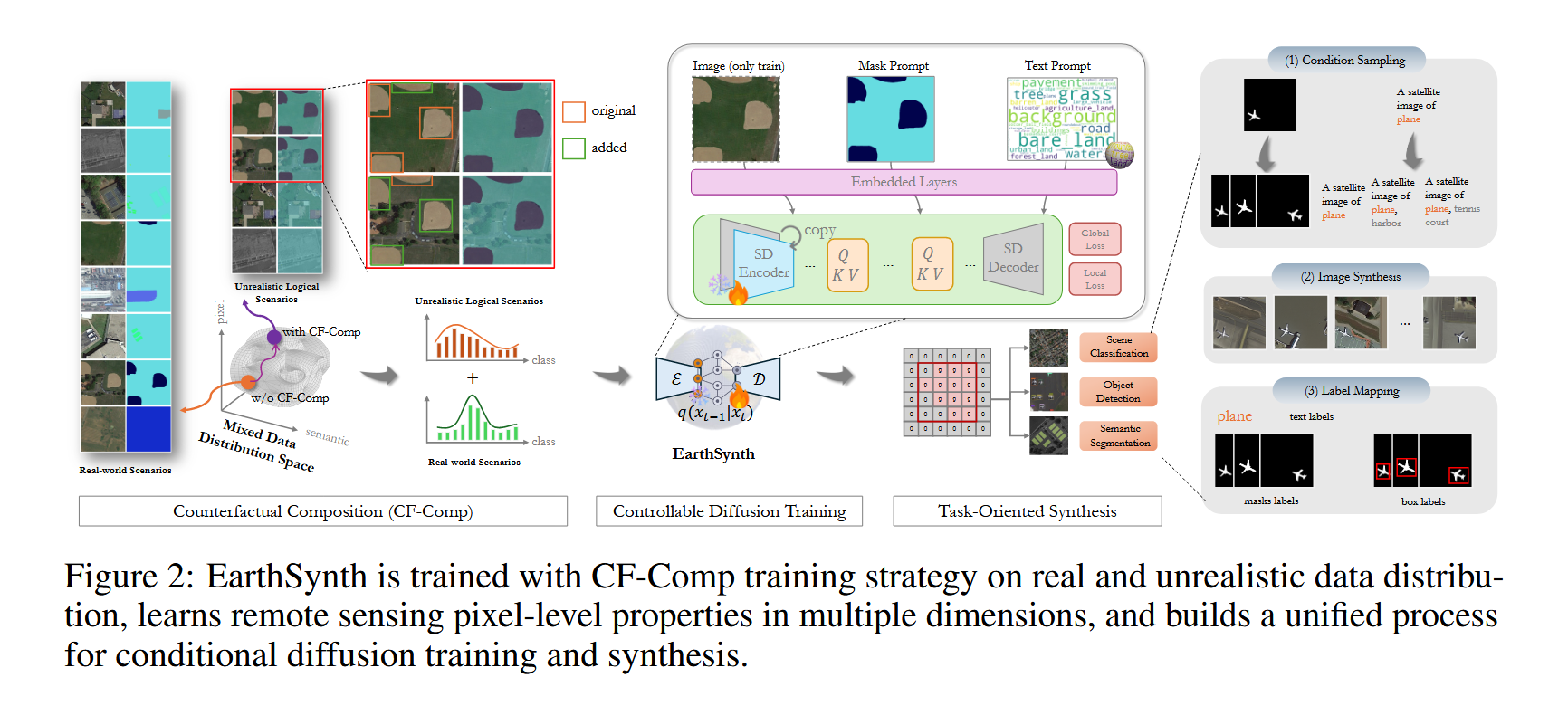
Preliminaries
训练数据合成(Training Data Synthesis)
核心思想:我们不是根据单一的、固定的条件来生成图像,而是根据一个条件集合 C 来生成一个混合的图像分布 XC。这样做的好处是可以生成更多样化、更鲁棒的样本。
公式详解:
XC=1∣C∣∑i=1∣C∣PGθ(x∣ci)(1)X_C = \frac{1}{|C|} \sum_{i=1}^{|C|} P_{G_\theta}(x | c_i) \quad (1)XC=∣C∣1i=1∑∣C∣PGθ(x∣ci)(1)
- XCX_CXC:这是最终我们想要得到的生成图像的分布。它不是一个单一的图像,而是一个概率分布,描述了在给定条件集 C 的情况下,所有可能生成的图像 x 的概率。
- C={ci}i=1∣C∣C = \{c_i\}_{i=1}^{|C|}C={ci}i=1∣C∣:这是条件集。它包含了
|C|个独立的条件 cic_ici。根据上下文,每个 cic_ici 是一个“掩码-文本”对,例如{"mask": [一个车辆的二进制掩码], "text": "A satellite image of a small vehicle"}。 - PGθ(x∣ci)P_{G_\theta}(x | c_i)PGθ(x∣ci):这是在给定单一条件 cic_ici 的情况下,由扩散模型 GθG_\thetaGθ 定义的条件分布。它表示,如果我们只使用 cic_ici 作为指导,模型会生成什么样的图像 x。
- x=Gθ(ε∣ci),ε∼N(0,I)x = G_\theta(\varepsilon | c_i), \varepsilon \sim N(0, I)x=Gθ(ε∣ci),ε∼N(0,I):这是如何从上述分布 PGθ(x∣ci)P_{G_\theta}(x | c_i)PGθ(x∣ci) 中采样得到一个具体图像 x 的过程。
- ε∼N(0,I)\varepsilon \sim N(0, I)ε∼N(0,I):从一个标准正态分布(均值为0,协方差矩阵为单位矩阵)中随机采样一个噪声向量 ε\varepsilonε。这是扩散模型生成过程的起点。
- Gθ(ε∣ci)G_\theta(\varepsilon | c_i)Gθ(ε∣ci):将噪声 ε\varepsilonε 和条件 cic_ici 一起输入到预训练好的扩散模型 GθG_\thetaGθ 中,模型会根据条件 cic_ici 将噪声逐步去噪,最终生成一个符合条件的图像 x。
- 1∣C∣∑i=1∣C∣\frac{1}{|C|} \sum_{i=1}^{|C|}∣C∣1∑i=1∣C∣:这是求和并取平均的操作。它表示最终的分布 XCX_CXC 是所有单个条件分布 PGθ(x∣ci)P_{G_\theta}(x | c_i)PGθ(x∣ci) 的均匀混合。这意味着,要从 XCX_CXC 中生成一个样本,我们可以先随机从 C 中选一个条件 cic_ici,然后根据 PGθ(x∣ci)P_{G_\theta}(x | c_i)PGθ(x∣ci) 生成图像 x。
标签生成:
y={yl,yc}=F(ci)y = \{y_l, y_c\} = F(c_i)y={yl,yc}=F(ci)
- FFF:这是一个映射函数。它的作用是从条件 cic_ici 中直接提取或生成对应的标签,而无需人工标注。
- yyy:这是生成的图像 x 所对应的完整标签。
- yly_lyl (位置标签):描述了目标在图像中的位置信息,可以是精确的语义掩码(每个像素是否属于目标)或边界框(Bounding Box)。
- ycy_cyc (类别标签):描述了目标的类别,例如 “small vehicle”, “large vehicle”。
图3 左侧解读:
图3左侧展示了 “CF-Comp Strategy” 中使用的 Copy-Paste 操作。 - 输入:两个条件对,分别是 “A satellite image of small vehicle, large vehicle” 和 “A satellite image of large vehicle, small vehicle”。模型根据这两个条件分别生成了图像 x(1)x^{(1)}x(1) 和 x(2)x^{(2)}x(2)。
- 操作:
Copy-Paste($x^{(1)}_{obj}, x^{(2)}$):从图像 x(1)x^{(1)}x(1) 中复制物体(xobj(1)x^{(1)}_{obj}xobj(1)),然后粘贴到图像 x(2)x^{(2)}x(2) 的背景上,生成新的合成图像 A。Copy-Paste($x^{(2)}_{obj}, x^{(1)}$):同理,从图像 x(2)x^{(2)}x(2) 中复制物体,粘贴到图像 x(1)x^{(1)}x(1) 的背景上,生成新的合成图像 B。
- 目的:通过这种方式,可以创造出在原始训练数据中不存在的、新的物体与背景组合,从而极大地丰富了数据的多样性。
特征分解(Feature Decomposition)
核心思想:一张卫星图像 x 可以被解构成三个独立的部分:物体、背景和噪声。这种分解是合理的,因为只有物体和背景决定了图像的语义标签,而噪声是无用的、甚至会干扰判断的无关信息。
公式详解:
x={xobj,xbg,xnoise}x = \{x_{obj}, x_{bg}, x_{noise}\}x={xobj,xbg,xnoise}
- xxx:完整的卫星图像。
- xobjx_{obj}xobj:图像中的物体特征。例如,车辆、飞机、建筑物等我们关心的目标。
- xbgx_{bg}xbg:图像中的背景特征。例如,道路、草地、水面等物体所处的环境。
- xnoisex_{noise}xnoise:图像中的噪声特征。这是由传感器、大气、光照等因素引入的干扰信息,不包含任何有用的语义。
xobj,xbg⊥̸ ⊥y,xnoise⊥ ⊥y(2)x_{obj}, x_{bg} \not\perp\!\!\!\perp y, \quad x_{noise} \perp\!\!\!\perp y \quad (2)xobj,xbg⊥⊥y,xnoise⊥⊥y(2)
这个公式用概率论中的独立性概念,精确地定义了各部分与标签 y 的关系。 - ⊥̸ ⊥\not\perp\!\!\!\perp⊥⊥ (不独立):符号 ⊥̸ ⊥\not\perp\!\!\!\perp⊥⊥ 表示“不独立”或“相关”。
- xobj,xbg⊥̸ ⊥yx_{obj}, x_{bg} \not\perp\!\!\!\perp yxobj,xbg⊥⊥y:标签 y 依赖于物体 xobjx_{obj}xobj 和背景 xbgx_{bg}xbg。这非常直观,因为一张图像被标记为“道路上的小汽车”,正是因为图像中包含了“小汽车”这个物体和“道路”这个背景。改变物体或背景,标签就可能改变。
- ⊥ ⊥\perp\!\!\!\perp⊥⊥ (独立):符号 ⊥ ⊥\perp\!\!\!\perp⊥⊥ 表示“独立”。
- xnoise⊥ ⊥yx_{noise} \perp\!\!\!\perp yxnoise⊥⊥y:标签 y 独立于噪声 xnoisex_{noise}xnoise。这意味着,图像中的噪声(如模糊、条纹、颗粒感)与图像的语义内容无关。无论噪声多大或多小,都不会改变图像中物体是“小汽车”这一事实。噪声是判断标签的无关变量。
推论:
PGθ(y∣x)=PGθ(xobj,xbg)P_{G_\theta}(y | x) = P_{G_\theta}(x_{obj}, x_{bg})PGθ(y∣x)=PGθ(xobj,xbg)
- xnoise⊥ ⊥yx_{noise} \perp\!\!\!\perp yxnoise⊥⊥y:标签 y 独立于噪声 xnoisex_{noise}xnoise。这意味着,图像中的噪声(如模糊、条纹、颗粒感)与图像的语义内容无关。无论噪声多大或多小,都不会改变图像中物体是“小汽车”这一事实。噪声是判断标签的无关变量。
- 这个公式是公式(2)的直接结果。它表示:在给定完整图像 x 的条件下,标签 y 的概率,等于在给定物体和背景的条件下,标签 y 的概率。
- 因为噪声 xnoisex_{noise}xnoise 与 y 独立,所以在计算 P(y∣x)P(y|x)P(y∣x) 时,xnoisex_{noise}xnoise 不提供任何信息,可以被忽略。这从理论上证明了,我们只需要关注 xobjx_{obj}xobj 和 xbgx_{bg}xbg 即可确定图像的语义。
实际意义:
这个分解是 Copy-Paste 技术能够奏效的理论基础。既然标签只由物体和背景决定,那么我们就可以:
- 从图像 A 中提取有用的物体 xobjAx_{obj}^AxobjA。
- 从图像 B 中提取有用的背景 xbgBx_{bg}^BxbgB。
- 将它们组合成新图像 xnew={xobjA,xbgB,xnoisenew}x_{new} = \{x_{obj}^A, x_{bg}^B, x_{noise}^{new}\}xnew={xobjA,xbgB,xnoisenew}。
这个新图像的标签 ynewy_{new}ynew 将由 xobjAx_{obj}^AxobjA 和 xbgBx_{bg}^BxbgB 共同决定,从而是合理且有效的。
Copy-Paste 增强
核心思想:利用特征分解的结论,通过“复制-粘贴”操作,低成本、高效率地创造出大量新的、具有真实感的训练样本。
操作详解:
Copy-Paste($x^{a}_{obj}, x^b)$:- xobjax^{a}_{obj}xobja:源图像 xax^axa 中的物体部分。这通常通过掩码来精确提取。
- xbx^bxb:目标图像,它主要提供背景 xbgbx^b_{bg}xbgb。
- 操作过程:将 xobjax^{a}_{obj}xobja “贴”到 xbx^bxb 的背景上,形成一张全新的图像。新图像的标签可以由源物体的标签和目标背景的上下文共同推断。
图3 右侧解读:
图3右侧展示了 CLIP-based rule filtering,即基于 CLIP 模型的规则化过滤,用于筛选高质量的合成图像。
- 输入:通过 Copy-Paste 生成了多个候选图像(例如 A, B, C)。
- 操作:使用 CLIP 模型来评估每个合成图像的质量。CLIP 是一个强大的多模态模型,能够判断图像与文本描述的匹配程度。
- CLIP Score:这里给出的分数(如 58.4, 83.8, 24.8)代表了合成图像与期望的文本描述(例如 “A satellite image of a large vehicle and a small vehicle”)的匹配度。分数越高,说明图像质量越好,语义越准确。
- 输出:通过设定一个阈值(例如,只保留分数高于 80 的图像),可以过滤掉质量差、有明显伪影或语义错误的合成图像,只保留高质量的样本用于训练。例如,图像 B 的 CLIP 分数最高(83.8),被认为是最佳样本。
挑战与解决方案: - 挑战:Copy-Paste 是一种简单的像素级操作,直接粘贴会导致合成伪影,例如:
- 物体边缘与背景的过渡不自然、不平滑。
- 光照、阴影、色调不一致。
- 尺度、透视关系不匹配。
这些问题会改变图像的统计特性,可能对模型的训练产生负面影响。
- 解决方案:
- 通过扩散模型训练缓解:文本提到,这些伪影问题通常可以通过扩散模型的训练过程来缓解。这意味着,可以将这些带有轻微伪影的合成图像作为训练数据的一部分,去微调或训练一个新的扩散模型。扩散模型强大的生成能力可以学习到如何“修复”这些不自然的过渡,从而生成更平滑、更真实的图像。
- 基于规则的过滤:如图3右侧所示,使用像 CLIP Score 这样的外部评估指标,在训练前就剔除掉质量最差的样本,保证进入训练环节的数据质量。
总结:
整个流程可以概括为:
- 生成:使用预训练扩散模型和条件集 C 生成基础图像。
- 分解与重组:将生成的图像分解为物体和背景,通过 Copy-Paste 技术进行重组,创造新的合成样本。
- 过滤:使用 CLIP 等模型对合成样本进行质量评估和筛选,剔除低质量数据。
- 精炼:将高质量的合成数据用于训练新的扩散模型,该模型能够学习并修正合成过程中的微小瑕疵,最终产出高质量、多样化的训练数据集。
用于可控扩散训练的反事实合成(Counterfactual Composition for Controllable Diffusion Training)
核心思想:反事实合成
1. 动机与定义
由于遥感图像固有的特性(类间相似性高、类内差异性大),模型解释面临挑战。为了从生成式扩散模型中获得信息量更丰富的数据分布,论文提出通过反事实合成来增强场景多样性。
- 目标:构建一个尽可能接近真实世界分布
D_real的训练数据分布D_train。 - 方法:将现有的物体类别与多样化的背景上下文进行组合,创造出在现实中不存在但逻辑上合理的新场景。
定义 1 (反事实合成):
给定一组源元素A1, A2, ..., An,每个Ai代表从不同实例中提取的特定语义组件(如物体、区域或属性)。一个反事实样本x'通过重组这些组件来构建:x' = CF(A1(i), A2(j), ..., An(k))(其中i ≠ j ≠ k)
这里的CF(·)是一个组合函数,它将来自不同实例的元素逻辑地组合起来,形成一个反事实样本x'。这个x'不在真实分布D_real中,但它是看似合理却未被观察到的。
2. 算法实现
算法 1:用于可控扩散训练的反事实合成
该算法描述了如何在训练过程中动态地生成反事实样本并用于模型训练。
输入: 训练数据集 D_train = {(I, M, T)},其中 I 是真实图像,M 是掩码提示,T 是文本提示。
输出: 训练好的条件扩散模型 M_θ。
训练流程:
- 采样原始批次: 从数据集
D中采样一个原始的小批次三元组B_ori = (I, M, T)。 - 反事实合成:
- 初始化一个空集合
B_copy用于存放合成样本。 - 遍历数据对: 对于数据集中的任意两个样本
(xa, ma, ta)和(xb, mb, tb):- 计算相似度:
α = ICS(xa, xb): 图像颜色敏感性。β = MOR(ma, mb): 掩码重叠率。η = TSS(ta, tb): 文本语义相似度。
- 判断与合成: 如果
α, β, η都大于预设的阈值α0, β0, η0,则认为这两个样本适合合成。- 执行 Copy-Paste 操作:
(x', m', t') = Copy-Paste(xa_obj, xb),即将xa中的物体粘贴到xb的背景上。 - 将合成的新三元组
(x', m', t')加入B_copy。
- 执行 Copy-Paste 操作:
- 计算相似度:
- 初始化一个空集合
- 构建新批次: 将原始批次
B_ori和合成批次B_copy合并,形成新的训练批次B。 - 标准扩散模型训练:
- 使用冻结的文本编码器编码文本提示
T,得到E_T。 - 采样噪声
ε和时间步t,生成带噪图像x_t。 - 使用条件模型
M_θ从掩码M中提取掩码特征F_M。 - 将掩码特征注入到冻结的 UNet 中,预测噪声
ε̂。 - 计算损失: 结合全局损失和局部损失进行优化。
L = ‖ε̂ − ε‖² + γ‖F_M · ε̂ − F_M · ε‖² - 通过梯度下降更新模型参数
θ。
备注 1: 反事实合成通过融合多样化的元素来生成新颖且逻辑一致的场景。其目标是在保持语义和结构连贯性的同时,扩大输入的多样性并提高模型的泛化能力。
- 使用冻结的文本编码器编码文本提示
3. 关键组件详解
a. 非真实逻辑场景
这是反事实合成的具体目标:构建一个在现实世界中不存在,但在逻辑上成立的卫星图像场景。为了防止任意组合导致的逻辑混乱,需要从三个维度来判断两个图像是否可以组合:
- 通道空间: 图像颜色敏感性
ICS(xa, xb) = 1{|S(xa)−S(xb)|<s0}, if Ca = Cb; 0, if Ca ≠ CbS = Var(R−G) + Var(R−B) + Var(G−B)是颜色敏感度计算公式。Ca和Cb是图像的通道数。- 意义: 确保两个图像在颜色风格上基本一致,且通道数相同,避免出现明显的色彩冲突。
- 像素空间: 掩码重叠率
MOR(ma, mb) = |ma ∩ mb| / |ma ∪ mb|, if |ma ∪ mb| > 0; 0, otherwise- 意义: 衡量两个掩码的重叠程度。低的重叠率意味着将
xa的物体粘贴到xb上时,空间冲突较小,合成结果更合理。
- 意义: 衡量两个掩码的重叠程度。低的重叠率意味着将
- 语义空间: 文本语义相似度
TSS(ta, tb) = (ta · tb⊤) / (‖ta‖ · ‖tb‖)- 意义: 使用余弦相似度衡量两个文本描述的语义相关性。确保组合的场景在语义上是通顺的(例如,不会把“飞机”贴到“海底”上)。
b. 混合数据分布
反事实合成会引入分布外的数据。论文通过数学分析来描述这种分布偏移。
- 假设: 物体
x_obj和背景x_bg分别服从高斯分布:x_obj ∼ N(μ_obj, σ²_obj I)x_bg ∼ N(μ_bg, σ²_bg I) - 合成图像的分布: 通过 Copy-Paste 操作(
α是前景像素占比),合成图像x'的均值和方差为:μ_mix = αμ_obj + (1−α)μ_bgσ²_mix = ασ²_obj + (1−α)σ²_bg + α(1−α)(μ_obj − μ_bg)² - 关键发现: 方差公式中的最后一项
α(1−α)(μ_obj − μ_bg)²反映了由于物体和背景统计特性不匹配而导致的分布偏移。 - 遥感图像特性: 在遥感图像中,由于背景干扰和类内变异性,通常
μ_obj ≈ μ_bg且σ²_obj ≈ σ²_bg,因此分布偏移较小。而在自然场景图像中,这种偏移可能非常显著。
c. 全局与局部损失
为了实现对语义掩码的精细控制,论文结合了全局和局部损失。
- 全局损失
L_global: 标准的扩散模型损失,关注整个图像的生成质量。L_global = ‖ε̂ − ε‖² - 局部损失
L_local: 在掩码区域内计算的损失,确保生成物体在像素级别的精确性。L_local = ‖F_M · ε̂ − F_M · ε‖² - 总损失
L: 将两者加权结合,γ是局部约束的权重因子。L = L_global + γL_local - 意义: 这种设计使得模型既能保证整体图像的真实性,又能严格遵守掩码所指定的区域和形状进行生成。
4. 训练数据合成
算法 2:训练数据合成
该算法描述了如何使用预训练模型批量生成合成数据集。
输入: 预训练的条件扩散模型 M_θ,采样步数 T,条件集 C。
输出: 合成数据集 S。
流程:
- 遍历条件集
C中的每个条件c_i。 - 执行标准的扩散模型去噪采样过程,从噪声
x_T开始,逐步生成图像x_0。 - 基于规则的过滤: 生成完成后,使用 CLIP 模型对生成的完整图像
x和其中的物体x_obj进行评分。 - 筛选入库: 如果 CLIP 分数都高于阈值
S0,则认为该样本质量高,将其加入最终的数据集S。 - 返回最终从条件分布
X_C中采样的数据集S。
5. 实验结果
论文通过在场景分类和目标检测任务上的实验来验证其方法 EarthSynth 的有效性。
表 1: 基于 CLIP 的场景分类准确率
- 任务: 在 RSICD 和 DIOR 数据集上进行场景分类。
- 结果:
EarthSynth (Ours)在两个数据集上都取得了具有竞争力的 Top-1 和 Top-5 准确率。- 在 RSICD 上,Top-5 准确率(91.8%)显著优于其他方法,表明其生成的场景在语义上非常准确,能被 CLIP 模型很好地识别。
- 这证明了
EarthSynth生成的数据在语义保真度上很高。
表 2: 目标检测性能
- 任务: 在 DOTAv2 和 DIOR 数据集上进行开放词汇目标检测。
- 设置:
Base GroundingDINO: 仅在真实数据上训练。+ StableDiffusion / + ControlNet / + EarthSynth (Ours): 在真实数据 + 各方法生成的合成数据上训练。
- 结果:
- 所有使用合成数据的方法都比基线有所提升,证明了合成数据的有效性。
EarthSynth (Ours)带来的提升最大,在 DOTAv2 上 mAP 提升了 +2.1,在 DIOR 上提升了 +0.3。- 这证明了
EarthSynth生成的数据能够最有效地提升下游任务(如目标检测)的性能,尤其是在处理复杂和多样化的遥感场景时。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)