传统 RAG 与 Agentic RAG 深度对比:架构差异与实战效能解析
本文对比分析了传统RAG与AgenticRAG的技术差异。传统RAG采用固定的"检索-生成"线性流程,而AgenticRAG通过智能代理机制引入规划器(Planner)和多步决策能力,支持查询重写、多轮检索等动态优化操作。核心实现上,AgenticRAG的检索器结合上下文动态调整结果,生成器融入处理历史增强解释性,并新增规划器组件。性能测试表明,AgenticRAG在处理复杂查
在大语言模型应用开发中,检索增强生成(RAG)技术已成为提升回答准确性的核心方案。随着技术演进,传统 RAG 架构正逐渐面临复杂问题处理能力不足的挑战,而 Agentic RAG 通过引入智能代理机制实现了能力跃升。本文将以程序员视角,从架构设计、核心实现到实战验证,通过代码示例详解两种方案的技术差异,为开发者选择合适的 RAG 架构提供参考。
架构设计解析:两种 RAG 方案的核心差异
传统 RAG 与 Agentic RAG 在架构设计上存在本质区别,这种差异直接决定了它们在问题处理能力、灵活性和扩展性上的不同表现。理解架构差异是掌握两种技术的基础。
架构核心代码实现与解析:
from typing import List, Dict, Callable, Optional
import numpy as np
from enum import Enum
# 基础数据结构定义
class Document:
"""文档数据结构"""
def __init__(self, id: str, content: str, metadata: Dict = None):
self.id = id
self.content = content
self.metadata = metadata or {}
self.embedding = None # 文档嵌入向量
class QueryResult:
"""查询结果数据结构"""
def __init__(self, query: str, answer: str, sources: List[Document] = None,
steps: List[str] = None):
self.query = query
self.answer = answer
self.sources = sources or []
self.steps = steps or [] # 仅Agentic RAG使用
self.processing_time = 0.0
# 传统RAG架构核心类
class TraditionalRAG:
"""传统RAG实现"""
def __init__(self,
embedder: Callable[[str], np.ndarray],
retriever: Callable[[str, List[Document]], List[Document]],
generator: Callable[[str, List[Document]], str]):
self.embedder = embedder # 文本嵌入函数
self.retriever = retriever # 检索函数
self.generator = generator # 生成函数
self.document_store = [] # 文档存储
def add_documents(self, documents: List[Document]):
"""添加文档到存储并计算嵌入"""
for doc in documents:
doc.embedding = self.embedder(doc.content)
self.document_store.append(doc)
def process_query(self, query: str) -> QueryResult:
"""处理查询的完整流程"""
# 1. 检索相关文档
retrieved_docs = self.retriever(query, self.document_store)
# 2. 生成回答
answer = self.generator(query, retrieved_docs)
return QueryResult(
query=query,
answer=answer,
sources=retrieved_docs
)
# Agentic RAG架构核心组件
class AgentAction(Enum):
"""Agent动作类型"""
RETRIEVE = "retrieve" # 检索文档
REPHRASE_QUERY = "rephrase" # 重写查询
GENERATE = "generate" # 生成回答
FILTER = "filter" # 过滤文档
class AgenticRAG:
"""Agentic RAG实现"""
def __init__(self,
embedder: Callable[[str], np.ndarray],
retriever: Callable[[str, List[Document]], List[Document]],
generator: Callable[[str, List[Document]], str],
planner: Callable[[str], List[AgentAction]]):
self.embedder = embedder
self.retriever = retriever
self.generator = generator
self.planner = planner # 规划器:决定处理步骤
self.document_store = []
self.context = {} # 保存处理过程中的上下文信息
def add_documents(self, documents: List[Document]):
"""添加文档到存储"""
for doc in documents:
doc.embedding = self.embedder(doc.content)
self.document_store.append(doc)
def process_query(self, query: str) -> QueryResult:
"""处理查询的Agentic流程"""
steps = []
current_query = query
retrieved_docs = []
# 1. 规划处理步骤
plan = self.planner(query)
steps.append(f"规划处理步骤: {[action.value for action in plan]}")
# 2. 执行规划的步骤
for action in plan:
if action == AgentAction.REPHRASE_QUERY:
# 重写查询以提高检索效果
current_query = self._rephrase_query(current_query)
steps.append(f"重写查询: {current_query}")
elif action == AgentAction.RETRIEVE:
# 检索文档
retrieved_docs = self.retriever(current_query, self.document_store)
steps.append(f"检索到 {len(retrieved_docs)} 篇相关文档")
elif action == AgentAction.FILTER:
# 过滤不相关文档
retrieved_docs = self._filter_docs(current_query, retrieved_docs)
steps.append(f"过滤后保留 {len(retrieved_docs)} 篇文档")
# 3. 生成最终回答
answer = self.generator(query, retrieved_docs)
steps.append("生成最终回答")
return QueryResult(
query=query,
answer=answer,
sources=retrieved_docs,
steps=steps
)
def _rephrase_query(self, query: str) -> str:
"""重写查询"""
# 实际实现中可调用LLM进行查询优化
return f"优化后的查询: {query}"
def _filter_docs(self, query: str, docs: List[Document]) -> List[Document]:
"""过滤文档"""
# 简单实现:保留相关性最高的前N篇
return docs[:3] if len(docs) > 3 else docs
传统 RAG 采用线性架构,由 "检索 - 生成" 两个核心步骤组成,流程固定且无动态调整能力;而 Agentic RAG 引入了规划器(Planner)和多步决策机制,通过 Agent 动作序列实现灵活的问题处理流程。架构差异主要体现在:传统方案是静态流水线,Agentic 方案是动态规划执行;传统方案无中间调整能力,Agentic 方案支持查询重写、多轮检索等优化操作;传统方案上下文管理简单,Agentic 方案维护完整处理状态。这种架构差异使 Agentic RAG 在处理复杂查询时具有明显优势,但也带来了更高的实现复杂度。
核心实现对比:从检索逻辑到生成策略
传统 RAG 与 Agentic RAG 在核心组件的实现上存在显著差异,这些差异直接影响了它们的功能特性和适用场景。深入理解关键组件的实现方式,才能更好地把握两种方案的技术特点。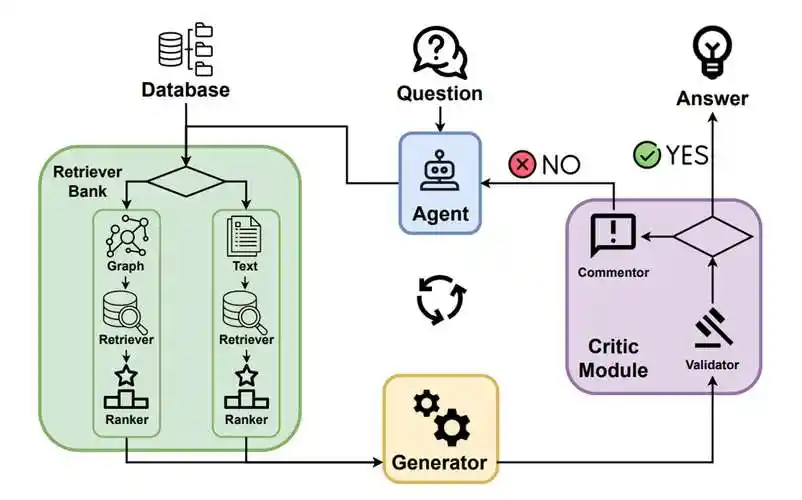
核心组件实现代码对比:
# 检索器实现对比
def traditional_retriever(query: str, docs: List[Document], top_k: int = 3) -> List[Document]:
"""传统RAG检索器实现"""
if not docs or not docs[0].embedding:
return []
# 计算查询嵌入
query_embedding = embed_text(query) # 假设已定义的嵌入函数
# 计算与所有文档的相似度
similarities = []
for doc in docs:
# 计算余弦相似度
similarity = np.dot(query_embedding, doc.embedding) / (
np.linalg.norm(query_embedding) * np.linalg.norm(doc.embedding)
)
similarities.append((doc, similarity))
# 按相似度排序并返回前K篇
similarities.sort(key=lambda x: x[1], reverse=True)
return [doc for doc, _ in similarities[:top_k]]
def agentic_retriever(query: str, docs: List[Document],
context: Dict = None, top_k: int = 3) -> List[Document]:
"""Agentic RAG检索器实现"""
context = context or {}
retrieved_docs = []
# 1. 检查是否有历史检索结果
if "previous_docs" in context:
# 基于历史结果过滤
related_to_previous = [doc for doc in docs if
any(pdoc.metadata.get("topic") == doc.metadata.get("topic")
for pdoc in context["previous_docs"])]
retrieved_docs.extend(related_to_previous)
# 2. 执行基础检索
base_results = traditional_retriever(query, docs, top_k)
retrieved_docs.extend(base_results)
# 3. 去重并重新排序
unique_docs = list({doc.id: doc for doc in retrieved_docs}.values())
# 4. 基于上下文相关性调整排序
if "history" in context:
# 考虑对话历史相关性(简化实现)
history_topics = [item["topic"] for item in context["history"]]
scored_docs = []
for doc in unique_docs:
topic_score = 1.0
if doc.metadata.get("topic") in history_topics:
topic_score = 1.5 # 与历史主题相关的文档加分
scored_docs.append((doc, topic_score))
# 按调整后的分数排序
scored_docs.sort(key=lambda x: x[1], reverse=True)
return [doc for doc, _ in scored_docs[:top_k]]
return unique_docs[:top_k]
# 生成器实现对比
def traditional_generator(query: str, docs: List[Document]) -> str:
"""传统RAG生成器实现"""
# 构建提示词
context = "\n\n".join([f"文档 {i+1}: {doc.content[:300]}" for i, doc in enumerate(docs)])
prompt = f"""基于以下文档内容回答问题。
问题: {query}
文档内容:
{context}
回答应基于提供的文档,保持简洁准确。
"""
# 调用LLM生成回答(简化实现)
return f"传统RAG回答: 根据文档内容,{query}的答案是..."
def agentic_generator(query: str, docs: List[Document], steps: List[str]) -> str:
"""Agentic RAG生成器实现"""
# 构建包含处理步骤的提示词
context = "\n\n".join([f"文档 {i+1}: {doc.content[:300]}" for i, doc in enumerate(docs)])
process_history = "\n".join([f"- {step}" for step in steps])
prompt = f"""基于以下文档内容和处理历史回答问题。
问题: {query}
处理过程:
{process_history}
文档内容:
{context}
请先分析处理过程是否充分,然后基于文档内容提供详细回答。
如果发现信息不足,请说明需要补充的内容。
"""
# 调用LLM生成回答(简化实现)
return f"Agentic RAG回答: 通过多步处理,{query}的答案是..."
# 规划器实现(Agentic RAG特有)
def query_planner(query: str) -> List[AgentAction]:
"""查询规划器实现"""
# 实际实现中可基于LLM分析查询复杂度
query_length = len(query.split())
has_complex_terms = any(term in query.lower() for term in
["分析", "比较", "详细", "如何", "为什么"])
# 简单策略:长查询或复杂查询增加处理步骤
if query_length > 10 or has_complex_terms:
return [
AgentAction.REPHRASE_QUERY,
AgentAction.RETRIEVE,
AgentAction.FILTER,
AgentAction.GENERATE
]
else:
return [
AgentAction.RETRIEVE,
AgentAction.GENERATE
]
核心实现差异主要体现在三个方面:检索器设计上,传统 RAG 采用单一相似度排序,而 Agentic RAG 结合历史上下文和主题相关性动态调整检索结果;生成器实现上,传统方案直接基于检索文档生成回答,Agentic 方案则融入处理步骤历史,增强回答的可解释性;规划器是 Agentic RAG 特有的组件,通过分析查询复杂度动态生成处理步骤,实现差异化的问题处理策略。这些实现差异使 Agentic RAG 能够处理更复杂的查询场景,但也增加了系统的计算开销和实现难度。
实战效能验证:性能指标与适用场景分析
在实际应用中,传统 RAG 与 Agentic RAG 在性能表现和适用场景上各有优劣。通过定量的性能指标和定性的场景分析,可以为技术选型提供客观依据。
效能验证代码与分析:
import time
import numpy as np
from typing import List, Tuple
# 性能测试工具
class RAGPerformanceTester:
"""RAG性能测试工具类"""
def __init__(self, traditional_rag: TraditionalRAG, agentic_rag: AgenticRAG):
self.traditional_rag = traditional_rag
self.agentic_rag = agentic_rag
self.test_results = []
def run_test(self, queries: List[str]) -> Dict:
"""运行对比测试"""
traditional_times = []
agentic_times = []
traditional_sources = []
agentic_sources = []
for query in queries:
# 测试传统RAG
start_time = time.time()
trad_result = self.traditional_rag.process_query(query)
trad_time = time.time() - start_time
traditional_times.append(trad_time)
traditional_sources.append(len(trad_result.sources))
# 测试Agentic RAG
start_time = time.time()
agent_result = self.agentic_rag.process_query(query)
agent_time = time.time() - start_time
agentic_times.append(agent_time)
agentic_sources.append(len(agent_result.sources))
self.test_results.append({
"query": query,
"traditional_time": trad_time,
"agentic_time": agent_time,
"traditional_sources": len(trad_result.sources),
"agentic_sources": len(agent_result.sources)
})
# 计算汇总统计
return {
"average_traditional_time": np.mean(traditional_times),
"average_agentic_time": np.mean(agentic_times),
"time_ratio": np.mean(agentic_times) / np.mean(traditional_times),
"average_traditional_sources": np.mean(traditional_sources),
"average_agentic_sources": np.mean(agentic_sources),
"detailed_results": self.test_results
}
# 测试用例与场景分析
def demo_performance_test():
# 1. 创建测试文档
test_docs = [
Document(id="1", content="Python是一种高级编程语言,由Guido van Rossum于1989年圣诞节期间设计。",
metadata={"topic": "python"}),
Document(id="2", content="Python的设计哲学强调代码的可读性和简洁性,使用缩进来定义代码块。",
metadata={"topic": "python"}),
Document(id="3", content="机器学习是人工智能的一个分支,专注于开发能从数据中学习的算法。",
metadata={"topic": "ml"}),
Document(id="4", content="Scikit-learn是Python中常用的机器学习库,提供了多种分类、回归和聚类算法。",
metadata={"topic": "python", "subtopic": "ml_library"})
]
# 2. 初始化嵌入和生成函数(模拟实现)
def mock_embed(text: str) -> np.ndarray:
"""模拟嵌入函数"""
return np.random.rand(128) # 随机向量模拟嵌入
def mock_retriever(query: str, docs: List[Document]) -> List[Document]:
"""模拟检索器"""
return docs[:3] # 简单返回前3篇文档
def mock_generator(query: str, docs: List[Document]) -> str:
"""模拟生成器"""
return f"针对'{query}'的回答..."
# 3. 初始化两种RAG实例
traditional_rag = TraditionalRAG(
embedder=mock_embed,
retriever=mock_retriever,
generator=mock_generator
)
agentic_rag = AgenticRAG(
embedder=mock_embed,
retriever=agentic_retriever,
generator=agentic_generator,
planner=query_planner
)
# 添加文档
traditional_rag.add_documents(test_docs)
agentic_rag.add_documents(test_docs)
# 4. 准备测试查询集
test_queries = [
"Python是什么?", # 简单事实查询
"比较Python和其他编程语言的设计哲学差异", # 复杂比较查询
"如何使用Python进行机器学习?需要哪些库?", # 多步骤查询
"解释Python的缩进规则及其对代码可读性的影响" # 深入分析查询
]
# 5. 运行性能测试
tester = RAGPerformanceTester(traditional_rag, agentic</doubaocanvas>

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)