AI 基础知识一 神经网络
神经网络是一种模拟人脑神经元连接的计算模型,通过多层神经元的非线性变换和数据驱动的权重调整,实现对复杂模式的学习。它是复杂模型(机器学习,深度学习)的核心基础。一个或多个神经元相互连接组成一个形成复杂的网络叫神经网络。神经元也可以叫节点。神经元有两个重要工作一个加权求和(线性回归另一个激活函数(非线性变换)。
导数概述
导数是微积分中的核心概念之一,函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率(不清楚的话,建议找相应教程), 常用的导数公式和运算法则如下
常数函数
若 f(x) = C(C 为常数),则f'(x) = 0
幂函数

指数函数(暂时用不上)
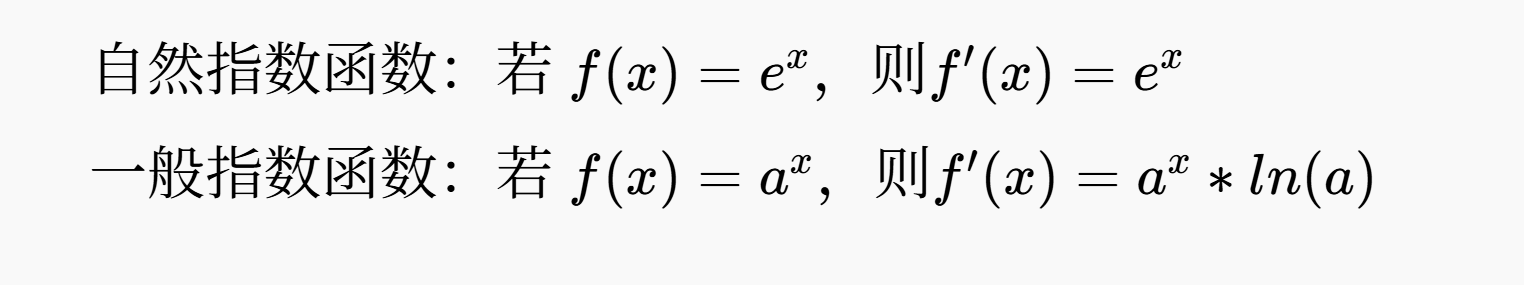
三角函数(暂时用不上)

反三角函数(暂时用不上)
导数的运算法则
设函数f(x)和g(x)均可导
1.和差法则
[f(x)+g(x)]′ = f′(x)+g′(x)
乘积法则
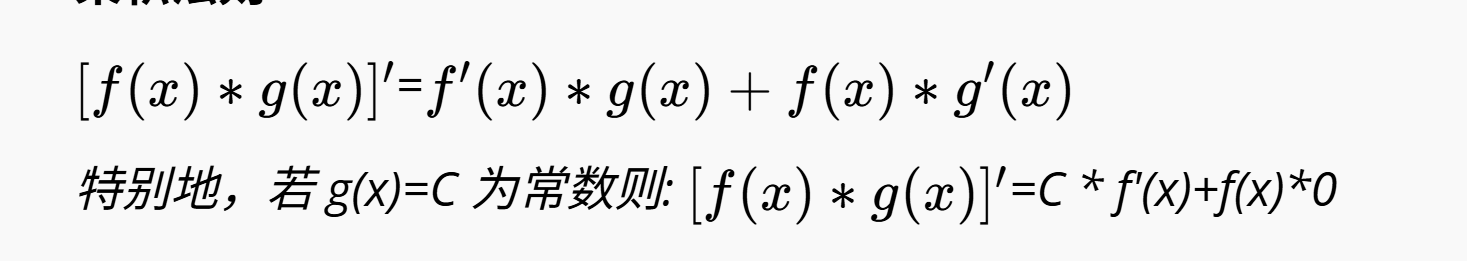
复合函数求导法则(链式法则)
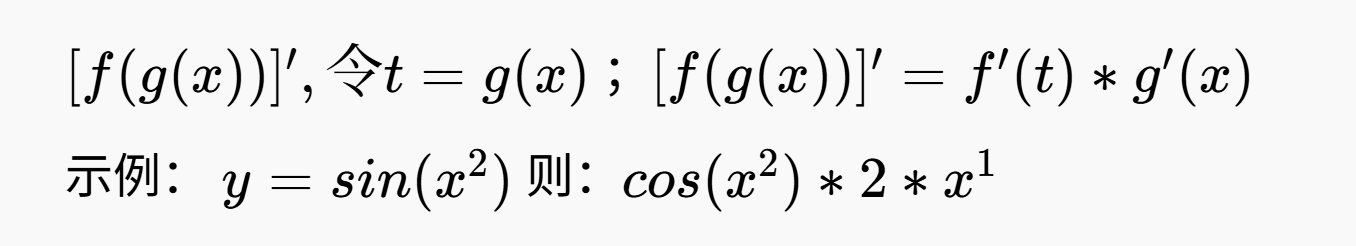
以上是在神经网络计算过程中要使用的数学基础
神经网络概述
神经网络是一种模拟人脑神经元连接的计算模型,通过多层神经元的非线性变换和数据驱动的权重调整,实现对复杂模式的学习。它是复杂模型(机器学习,深度学习)的核心基础。一个或多个神经元相互连接组成一个形成复杂的网络叫神经网络。神经元也可以叫节点。神经元有两个重要工作一个加权求和(线性回归)另一个激活函数(非线性变换)。
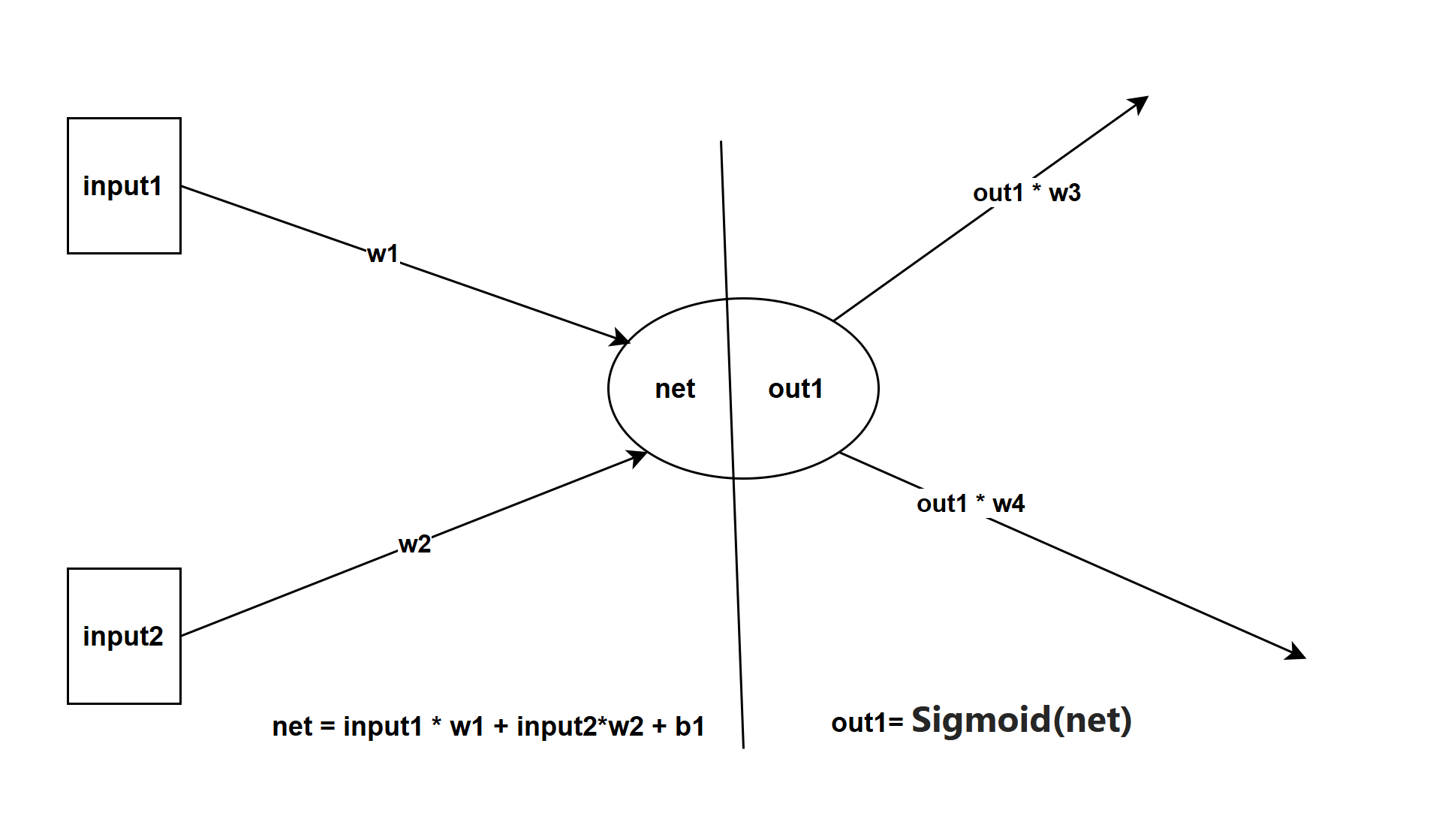
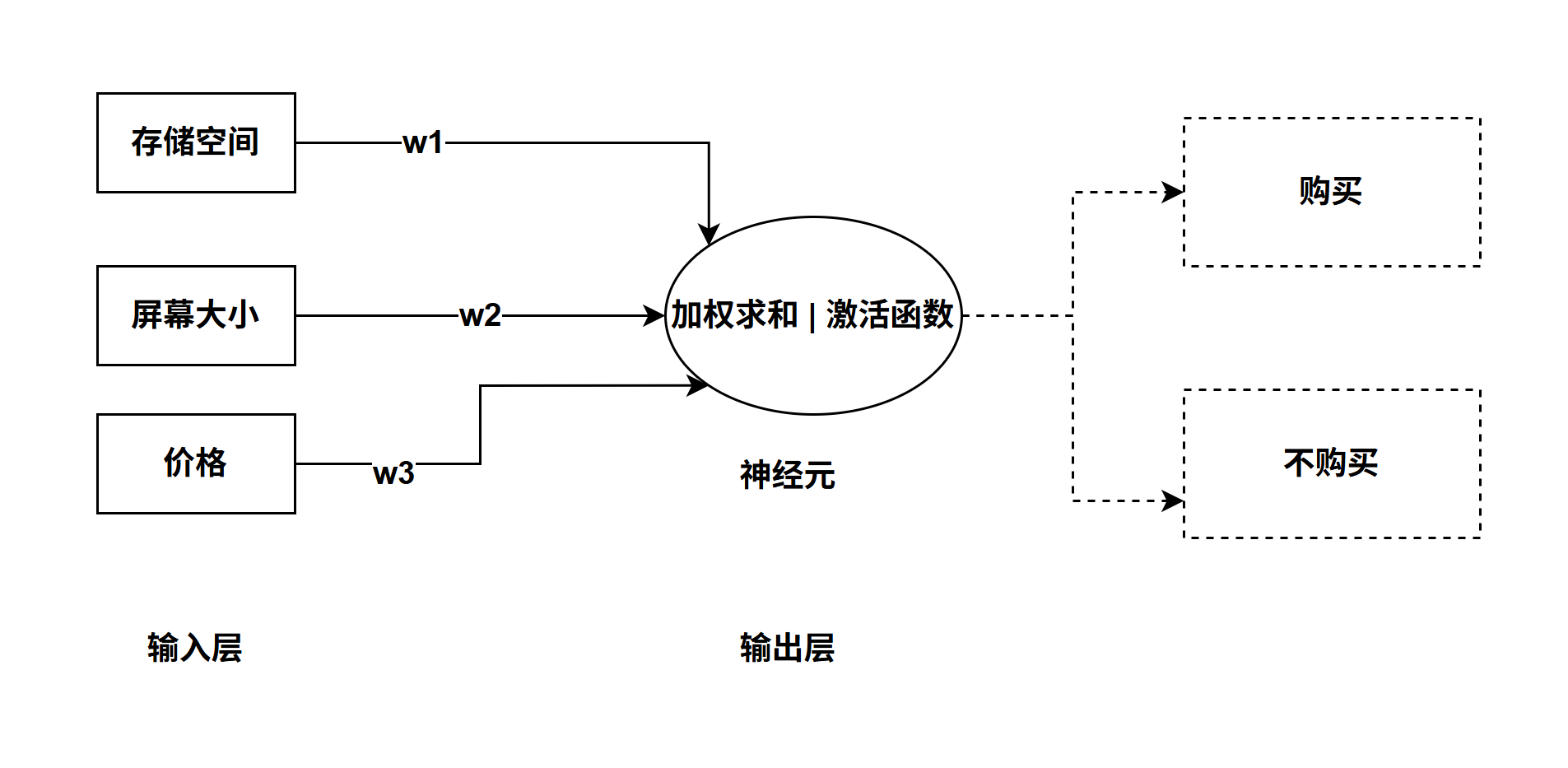
如上图 加权求和公式 net = input1* w1+input2*w2+b1;其中input1、input2是变量,w1(权重)、w2(权重)、b1(偏置量)是已知值随机值或任意值都可以,用数学公式表示为:
y值是由x1,x2计算出来或者说知道x1、x2就能预测y的值
激活函数: 输出的y会被压缩到 [0,1]区间 ,神经元处理加权求和、激活函数 的意义何在呢,这是拟人脑做出决策过程,举个例子我们要购买一部手机,选择存储空间大小、屏幕大小、手机系统(安卓、IOS)、价格等等 经过综合考虑比较之后决策是否购买。如果用数学公式来表达 Y = 存储空间 *w1+屏幕大小*w2+价格*w3+...; Y 就是综合评分也就是加权求和的结果,如果得分大于70 购买否则不购买 也就是经过激活函数后是否购买,那么问题来了w1、w2、w3的权重值是随机的或任意给的,推算的结果确定是错误的。这时需要纠正权重的值,要几组真实的数据来训练也。
还是举买手机的例子,假如只考虑 参数:存储空间、屏幕大小、价格。如果存储空间、屏幕大小都一样,价格分别为(1200,1500),从中选择购买一部手机,用数学公式Y(价格) = 存储空间 *w1+屏幕大小*w2 +价格*w3 ;
购买: Y(1200)= 存储空间 *w1+屏幕大小*w2 + 1200*w3 = 90;
不购买:Y(1500)= 存储空间 *w1+屏幕大小*w2 + 1500*w3 = 60;
1200*w3 - 1500*w3=90-60
-300*w3 = 30
w3 = -0.1
解方程可以算出w3的权重值, 只要训练数据管够同理也能推出w1、w2的值。神经网络的反向传播是不是解方程式更新权重?,答案否定的,道理一样的,它用了过更精确方式:偏导数。例子如果用神经网络来表示那么可以为两层:输入层和输出层如图
c++实现 神经网络 实例
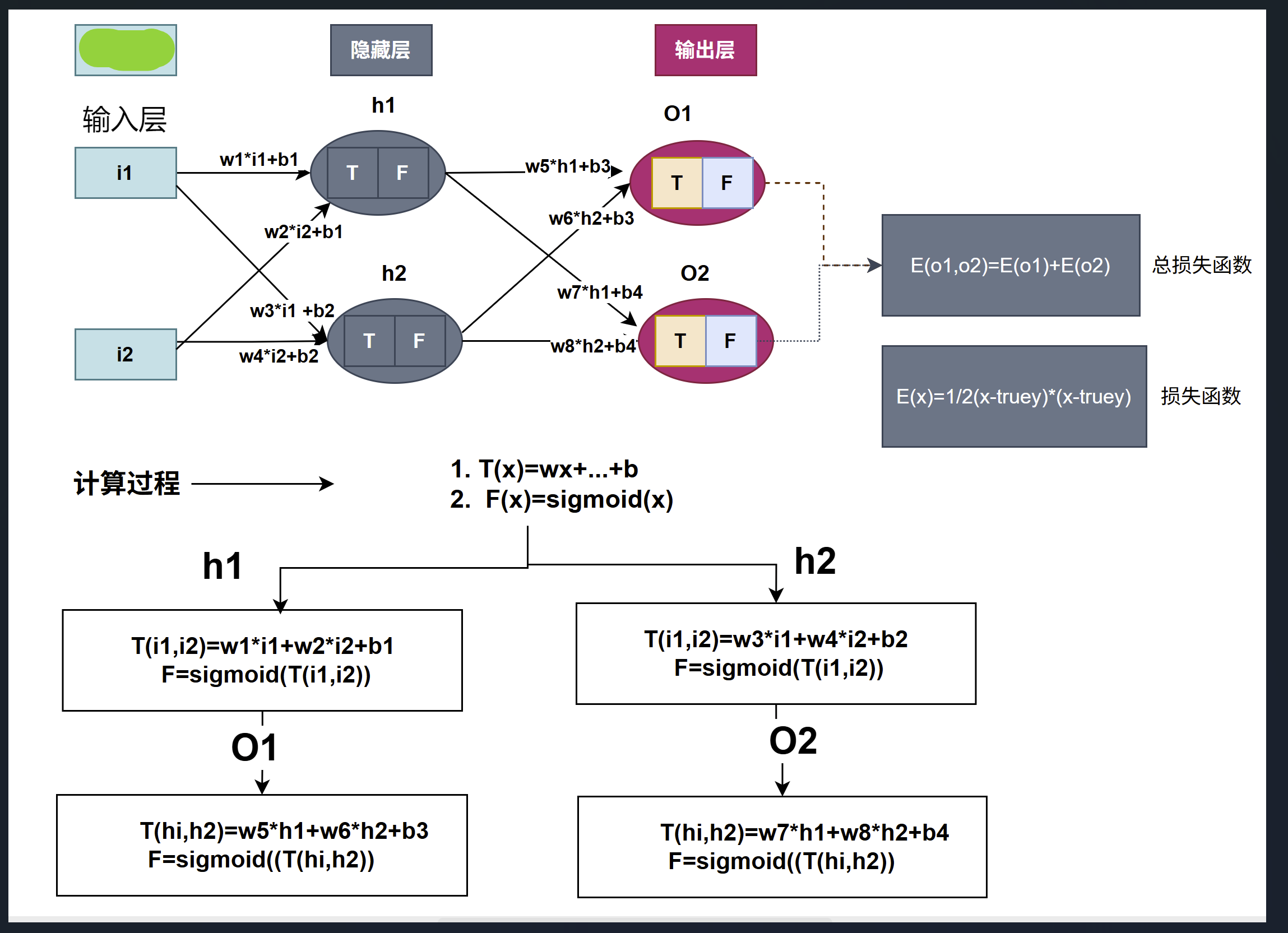
用一个实例来解析神经网络工作原理,从上图可以得知,神经网络有三层,每层两个神经元
输入层 :i1 = 0.05, i2 =0.1
隐藏屋:h1,h2
输出层:O1, O2,真实值(期望值)O1 = 0.01, O2 = 0.99
神经元中T是加权求和函数函 ,F是激活函数
初化数据代码:
double i1 = 0.05;
double i2 = 0.1;
double w1 = 0.15;
double w2 = 0.2;
double w3 = 0.25;
double w4 = 0.3;
double w5 = 0.4;
double w6 = 0.45;
double w7 = 0.5;
double w8 = 0.55;
double b1 = 0.35;
double b2 = 0.35;
double b3 = 0.6;
double b4 = 0.6;
double o1 = 0.01;
double o2 = 0.99;神经网络加权求和函数模型: y=x1*w1+x2*w2+b ,实现函数模型代码
double YFunction(double x1, double w1, double x2, double w2, double b)
{
double y = x1 * w1 + x2 * w2 + b;
return y;
}
激活函数用 : ,y值会被压缩到 [0,1]区间,实现代码
double sigmoid(double x)
{
return 1.0 / (1.0 + std::exp(-x));
}
//它的导数
double sigmoid_derivative(double s)
{
return s * (1.0 - s);
}1.正向传播
这部比较简单套用神经元公式T和F函数,计算过程相关代码
1. 隐藏层的计算代码
neth1 = YFunction(i1,w1,i2,w2,b1);
neth2 = YFunction(i1, w3, i2, w4, b2);
outh1 = sigmoid(neth1);
outh2 = sigmoid(neth2);
2.输出层的计算代码
nety1 = YFunction(outh1, w5, outh2, w6, b3);
nety2 = YFunction(outh1, w7, outh2, w8, b4);
outy1 = sigmoid(nety1);
outy2 = sigmoid(nety2);
outy1: 0.75136506955231575 预测值
outy2: 0.77292846532146253 预测值
o1: 0.01 真实值
o2: 0.99 真实值
o1Loss = Loss(outy1, o1); o1的损失函数
o2Loss = Loss(outy2, o2); o2的损失函数
totalLoss = o1Loss + o2Loss; 总损失函数2.反向传播
反向传播是神经网络的核心算法也是最难的部份,通过算损失函数对网络中所有参数(权重和偏置)的偏导数(梯度)。
1.损失函数 预测值减真实值 为了方便求导 定义为 它的导数
代码
double Loss(double y, double targetY)
{
return 0.5 * (y - targetY) * (y - targetY);
}
//导数
double Loss_derivative(double computey, double truey)
{
return computey - truey;
}计算损失函数代码
o1Loss = Loss(outy1, o1); o1的损失函数
o2Loss = Loss(outy2, o2); o2的损失函数
totalLoss = o1Loss + o2Loss; 总损失函数用一个数学公式表示
2.对输出层 权重求导
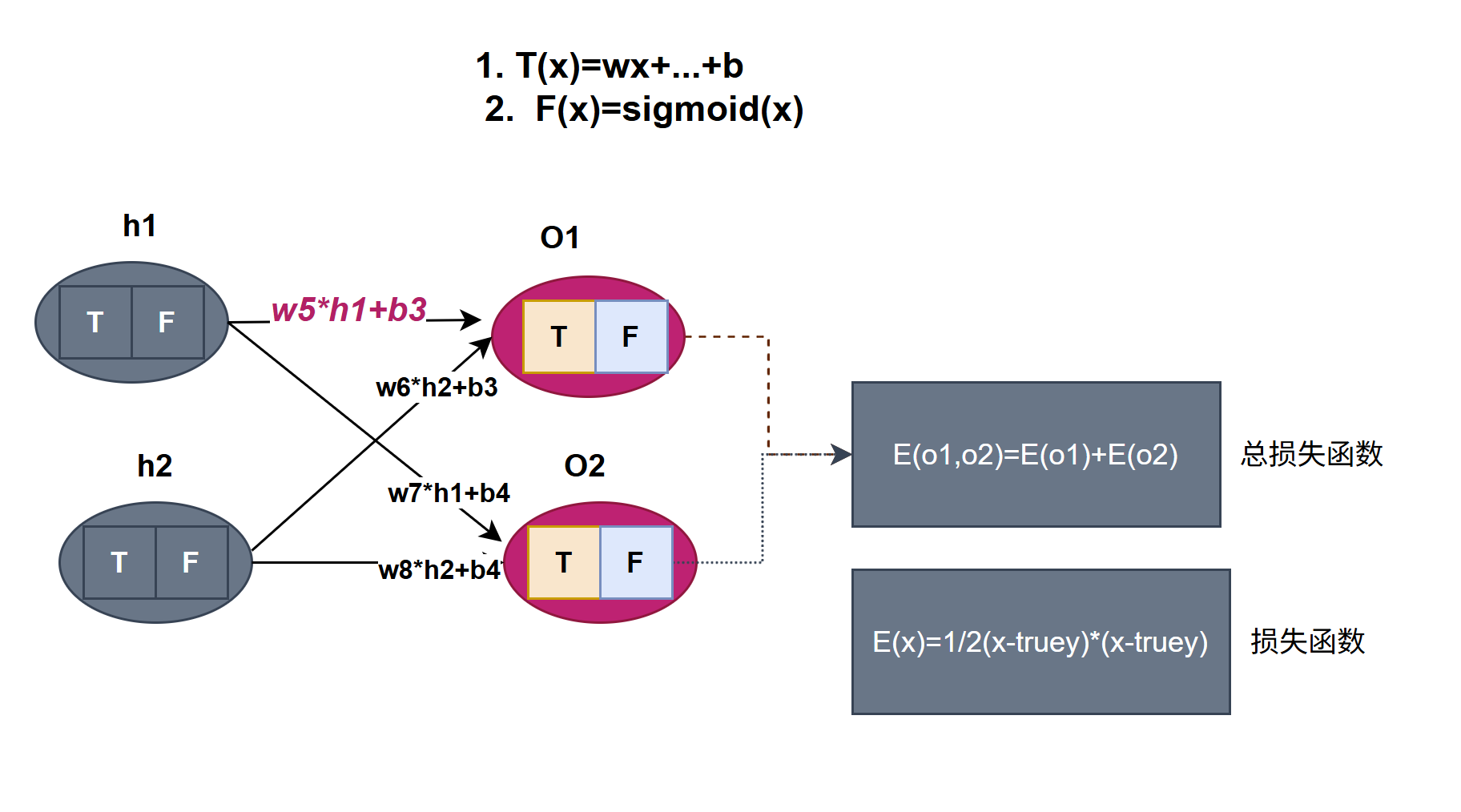
如上图,E对w5求偏导数,因为是求偏导所以可以把与w5相关计算的当成变量也就嵌套式函数,其他的都是常量,常量的导数为0,以下是推导过程

从流向上看 w5 经过加权求和函数T,然后经过激活函数F,最后是损失函数E,是层层嵌套进去的,利用复合函数求导法则分别对函数T、函数F、函数E求导相乘
同理可以推出w6、w7、w8的导数,相关代码
double qOut1 = Loss_derivative(outy1,o1); //E的导数
double qOut2 = Loss_derivative(outy2, o2);
///totalLoss 对 w5的导数
double lossw5 = qOut1 * sigmoid_derivative(outy1) * outh1;
double oldw5 = w5;
w5 = w5 - rate * lossw5;
/// totalLoss 对 w6的导数
double lossw6 = qOut1 * sigmoid_derivative(outy1) * outh2;
double oldw6 = w6;
w6 = w6 - rate * lossw6;
/// totalLoss 对 w7的导数
double lossw7 = qOut2 * sigmoid_derivative(outy2)* outh1;
double oldw7 = w7;
w7 = w7 - rate * lossw7;
double lossw8 = qOut2 * sigmoid_derivative(outy2) * outh2;
double oldw8 = w8;
w8 = w8 - rate * lossw8;学习率(Learning Rate,通常用符号 表示)是学习中最重要的超参数之一,它决定了模型在训练时参数更新的步长。学习率本质上平衡了模型的收敛速度和收敛精度:
学习率过大:参数更新幅度过大,可能越过损失函数的最小值(震荡甚至发散),导致模型无法收敛。
学习率过小:参数更新缓慢,训练时间延长,可能陷入局部最小值或鞍点,无法找到全局最优解。
w5 = w5 - rate * lossw5; rate=0.5是学习率;这是更新权重的代码。
再来就是E对w1求偏导数,与w5推导差不多,对w1流向分析然后导数相乘,看图注意红色部队分
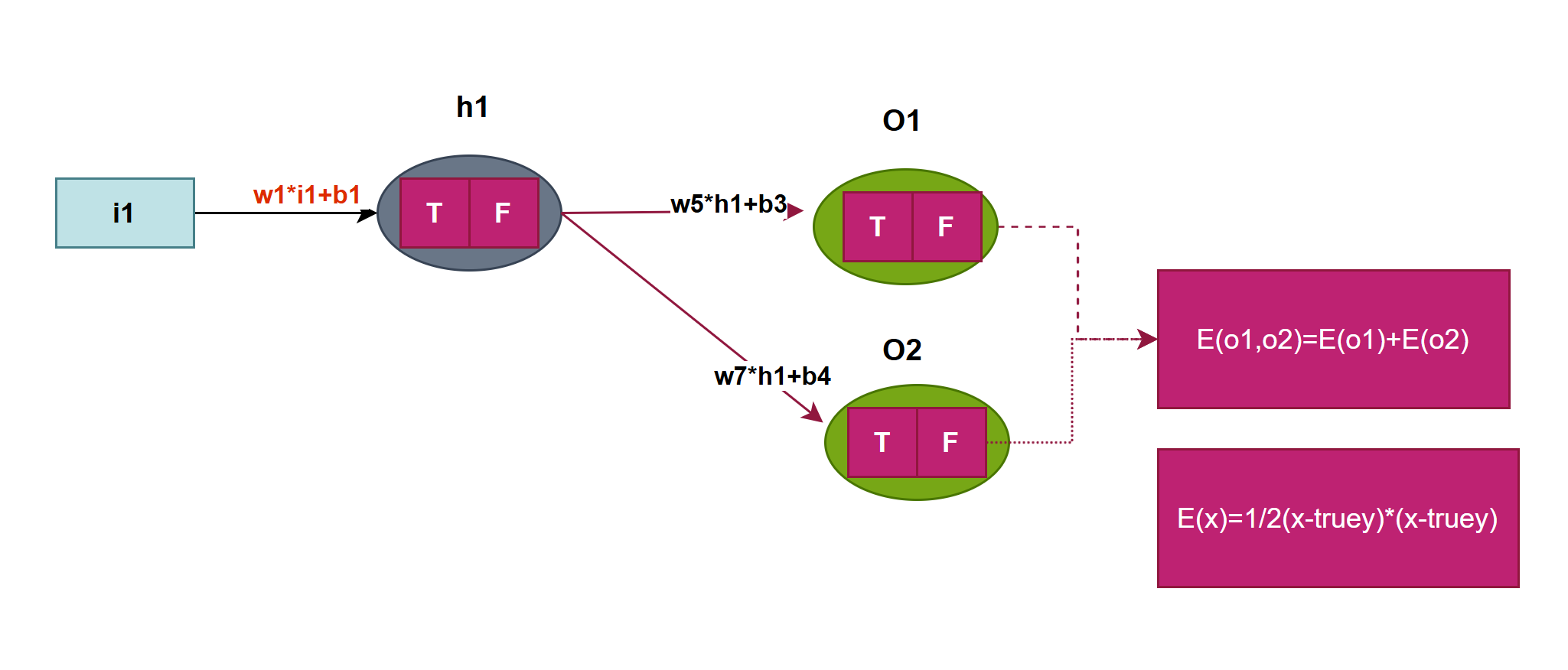
隐藏层h1有 两条线路:h1->o1->E和h1->o2->E,对w1在两线上分别求导然后相加
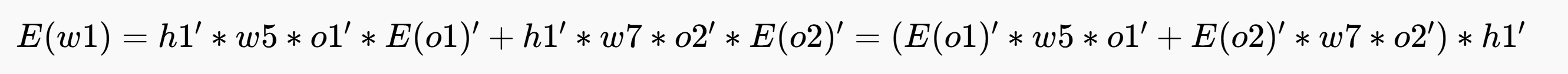
代码如下
///totalLoss 对 w1的导数
double lossw1 = (qOut1 * sigmoid_derivative(outy1) * oldw5 + qOut2 * sigmoid_derivative(outy2) * oldw7) * sigmoid_derivative(outh1) * i1;
// (outy1 - o1) * sigmoid_derivative_from_sigmoid(outy1) * oldw5 *sigmoid_derivative_from_sigmoid(outh1) * i1 + (outy2 - o2) * sigmoid_derivative_from_sigmoid(outy2) * oldw7 * sigmoid_derivative_from_sigmoid(outh1) * i1;
w1 = w1 - rate * lossw1;
double lossw2 = (qOut1 * sigmoid_derivative(outy1) * oldw5 + qOut2 * sigmoid_derivative(outy2) * oldw7) * sigmoid_derivative(outh1) * i2;
w2 = w2 - rate * lossw2;
double lossw3 = (qOut1 * sigmoid_derivative(outy1) * oldw6 + qOut2 * sigmoid_derivative(outy2) * oldw8) * sigmoid_derivative(outh2) * i1;
w3 = w3 - rate * lossw3;
double lossw4 = (qOut1 * sigmoid_derivative(outy1) * oldw6 + qOut2 * sigmoid_derivative(outy2) * oldw8) * sigmoid_derivative(outh2) * i2;
w4 = w4 - rate * lossw4;b1、b2、b3、b4要不要更新呢,程序运行效果:
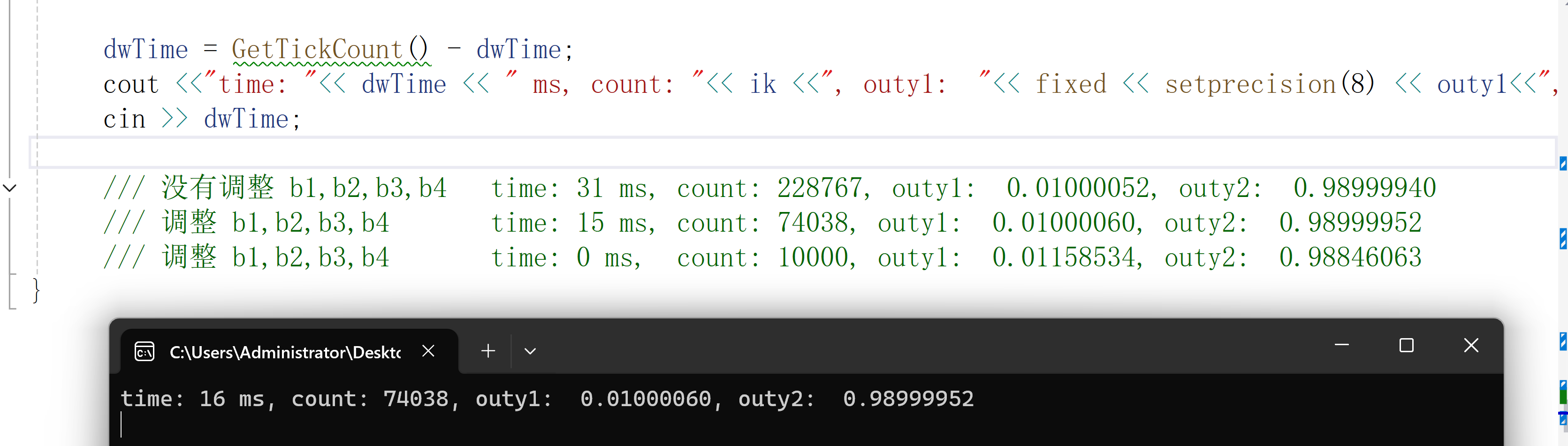
总结 神经网络经过74038次训练调整权重值之后与真实值很接近了(精确到6位小数点)。
感谢大家的支持,如要问题欢迎提问指正。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)