自动驾驶大模型---香港科技大学之BEVGPT
BEVGPT提出了一种基于生成式预训练Transformer的自动驾驶统一框架,将预测、决策和运动规划整合到单一模型中。该框架仅以鸟瞰图(BEV)作为输入,采用两阶段训练:先通过大规模数据预训练因果Transformer获得场景预测能力,再通过在线微调优化运动规划。实验表明,该模型在Lyft Level5数据集上100%决策指标和66%运动规划指标优于现有方法,并能实现6秒长期场景预测。创新点包括
1 前言
车企大模型系列(后续增加研究机构论文),在前面的博客中分别介绍了多家车企的方案,有些车企(比如理想汽车/小鹏汽车)公开的相关信息比较多,对很多读者来说,也算是福利。通过了解各家车企的大模型方案,对于从事自动驾驶的朋友能更宏观的看大模型的发展。
预测、决策与运动规划是自动驾驶的核心环节。在当前多数研究中,这些环节要么被视为独立模块,要么被整合到多任务学习框架中 —— 即采用共享的骨干网络,但配备独立的任务头。尽管近年来有部分方法遵循这一思路,但这些方法存在输入表征复杂、框架设计冗余等问题。更重要的是,它们无法对未来驾驶场景进行长期预测。为解决这些问题,重新审视了自动驾驶任务中各模块的必要性,仅将必需模块融入一个极简的自动驾驶框架中。
整体的架构更偏向于早期理解的VLM大模型,输出粗糙轨迹,使用运动学模型和优化算法对轨迹进行平滑,保证输出轨迹的质量。这套方案也是某些车企的当前或者早期量产方案。
当前热门方案:通过新的模型解码,可输出较高质量的轨迹(真正意义上替代了规划模块)。但对于L4或者安全级别的要求,大模型暂时还没有给出答卷。
2 BEVGPT
BEVGPT 框架将预测、决策和运动规划集成到单个生成式预训练 Transformer(GPT)中,仅以鸟瞰图(BEV)作为输入。采用两阶段训练流程:首先,利用大规模自动驾驶数据训练一个因果 Transformer;随后,通过真实模拟器的在线学习对模型进行微调。
决策模块的输出是自车在未来时间范围 秒内的位置信息,这些信息会进一步由运动规划器处理,以生成符合运动学动力学约束且平滑的轨迹。
2.1 模型架构
- 输入:以鸟瞰图(BEV)图像作为唯一的输入源。BEV 图像能够提供清晰的物理可解释性,易于整合不同模态的输入,且可以避免透视失真问题,降低下游任务的复杂性。
- 核心结构:是一个生成式预训练的大型模型(BEVGPT),它可以基于周围交通场景进行驾驶场景预测、决策和运动规划。该模型能够理解输入的 BEV 图像,并根据图像中的信息做出相应的决策和规划。
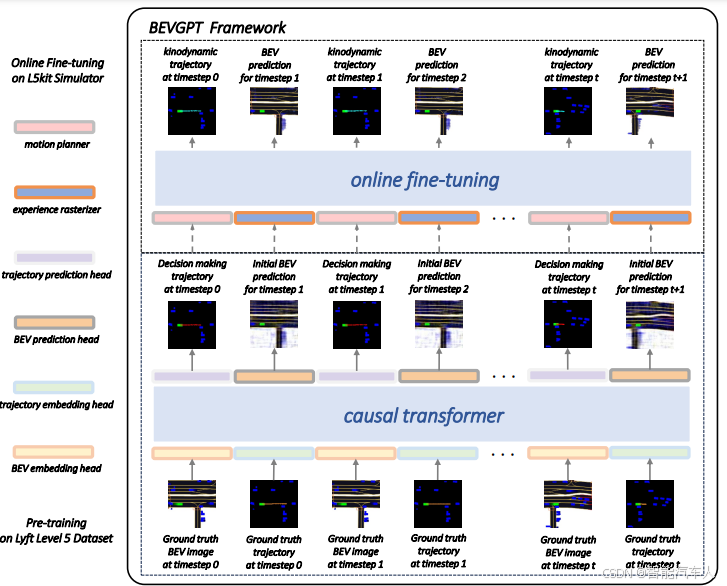
- 决策模块:基于对周围环境的理解,模型会做出驾驶决策,例如选择合适的行驶方向、速度等。
- 规划模块:为了确保驾驶轨迹的可行性和流畅性,增加基于优化的运动规划方法。该方法可以根据决策模块的输出,生成安全、合理的行驶轨迹。
运动规划模块,朋友们就比较熟悉了,最终转化为一个优化问题(论文中的优化目标只有纵向的jerk,相对量产的优化目标,简单了很多)求解即可。
(1)运动学关系
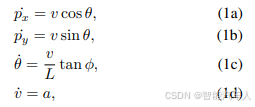
(2)轨迹表示
采用分段多项式轨迹来表示微分平坦输出(即 和
)。为了在后续的运动规划模块中最小化加加速度(jerk),选择五次多项式进行表征。假设该轨迹由共 M 个线段组成,每个线段的时间间隔均为
。对于每个维度,第 n 段多项式轨迹可表示为:
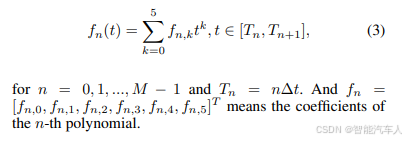
(3)优化问题
规划轨迹 的基本要求包括动力学可行性和轨迹平滑性。同时,最好能最小化控制代价。选择加加速度(jerk)来表示控制代价(这里的处理比较简单)。初始状态
和最终状态
是已知的,决策模块输出的
必须包含在轨迹中。综上,运动规划的需求可转化为如下最小加加速度问题:
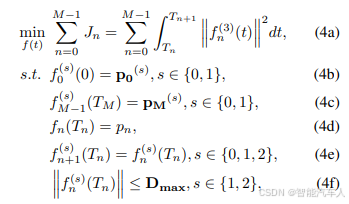
2.2 训练
BEVGPT 框架采用两阶段训练流程。在预训练阶段,利用大规模自动驾驶数据训练一个因果 Transformer,目标是让模型学习驾驶场景预测与决策能力。该模型具备强大的容量,能够规划未来 4 秒的行驶轨迹,并可对未来长达 6 秒的驾驶场景进行预测。在在线微调阶段,针对运动学动力学运动规划和精确的 BEV(鸟瞰图)生成任务,对已训练的因果 Transformer 进行适配优化。
具体而言,预训练阶段的目标是让模型学习驾驶场景预测与决策能力,即在自动驾驶任务中实现鸟瞰图生成与自车轨迹预测。该模型具备强大的容量,能够规划未来 4 秒的行驶轨迹,并可对未来长达 6 秒的驾驶场景进行预测。
紧接着是在线微调阶段,在此阶段我们针对运动学动力学运动规划和精确的鸟瞰图预测任务,对已训练的因果 Transformer 进行适配优化。微调阶段中,我们设计了一个运动规划器,用于为自动驾驶车辆生成平滑且可行的轨迹;此外,还开发了一个经验栅格化器,帮助模型处理驾驶场景中的静态信息(如车道和路口)。
2.3 试验结果与创新
- 实验结果:
- 性能优势:在 Lyft Level 5 数据集上进行了实验,并使用 Woven Planet L5Kit 进行了逼真的驾驶模拟。结果表明,该模型在 100% 的决策指标和 66% 的运动规划指标上优于之前的方法,验证了所提出框架的有效性和鲁棒性。
- 场景预测能力:通过驾驶场景预测任务,证明了该框架能够准确地生成长期的 BEV 图像,展示了其在长期预测方面的能力。
- 创新点与贡献:
- 整合框架:将自动驾驶中的预测、决策和运动规划三个关键环节整合到一个统一的框架中,提高了系统的整体性能和效率。
- 输入简洁:仅使用 BEV 图像作为输入,避免了复杂的输入表示,降低了模型的复杂度。
- 长期预测能力:能够对未来的驾驶场景进行长期预测,为自动驾驶系统提供了更全面的信息支持。
- 性能优越:在多个指标上取得了优于现有方法的性能,为自动驾驶技术的发展提供了新的思路和方法。
- 优化运动规划:通过基于优化的运动规划方法,确保了驾驶轨迹的可行性和平滑性。
- 生成式预训练:BEVGPT作为一种生成式预训练大模型,具有强大的泛化能力和理解能力,能够处理复杂的自动驾驶任务和各种场景。
3 结论
BEVGPT提出了一种基于生成式预训练Transformer的自动驾驶统一框架,将预测、决策和运动规划整合到单一模型中。该框架仅以鸟瞰图(BEV)作为输入,采用两阶段训练:先通过大规模数据预训练因果Transformer获得场景预测能力,再通过在线微调优化运动规划。
参考文献:
《BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)