让大模型 “睡觉”:把版本迭代当作人类睡眠来设计(附可直接改造的训练作息表与代码)
这篇文章给到一套可落地的工程方法论,目标读者是 算法工程师、模型研发生、数据工程团队、AIGC 产品经理、Infra 同学。风格偏实战,无链接、无表格,段落规整,拿去即可改造现有管线。
你有过这种时刻吗:GPU 风扇像台风,训练曲线像过山车,第二天评测却“梦游”一样翻车。与其 24 小时拉满,不如给 AI 模型一张“人类式作息表”——把版本发布之间的这段离线期,当成模型的睡眠周期来设计。结果常见的三大痛点会明显缓解:泛化更稳、成本更省、越狱更难。
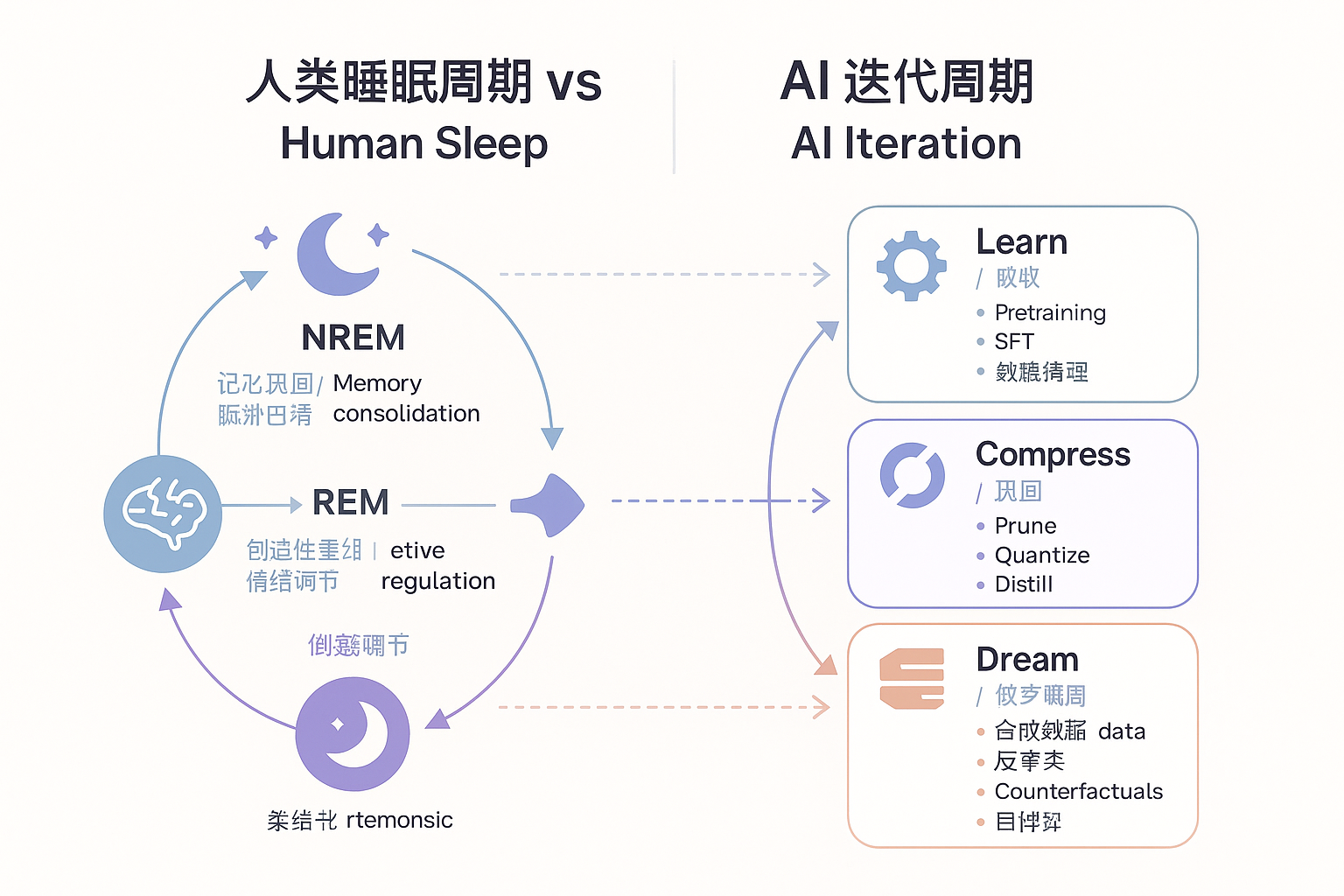
为什么要让 AI 模型 “睡觉”
把大模型的版本迭代期类比为人类睡眠周期,有两个关键映射:
1)NREM 深睡阶段 ⟶ 基础训练与压缩巩固 人类在 NREM 深睡会做两件事:巩固重要记忆、清理代谢垃圾。对应到 AI:大规模训练 + 去噪压缩。工程动作包括数据去重、清洗,SFT 与对齐数据的重采样,正则化、剪枝、量化与 LoRA 合并,减少“权重水肿”。
2)REM 做梦阶段 ⟶ 任务微调与合成数据联想 REM 睡眠中大脑会“做梦”,把白天碎片重新拼接。对应到 AI:构造合成数据、反事实样本、自一致性推理、红队自博弈,把长尾补齐,把知识图谱“串起来”,并在 RLHF 或 RLAIF 中对情绪与风格做“柔性对齐”。
一句话总结:先深睡做巩固,再做梦搞联想,最后醒来做体检(评测与安全闸)。这比单一的“猛拉学习率 + 堆数据”更稳健。
工程落地的 5 个核心组件
组件 A:数据卫生
-
强制去重与源可信分层,拒绝“二次转载体”。
-
任务配比显式化:基础识别、推理、规划、工具使用、结构化输出分桶抽样。
-
合成数据要有“质量闸”,避免 reward hacking。
-
违规与越狱样本库周更,做负采样与覆盖度统计。
组件 B:记忆结构分层
-
权重 = 长期记忆,只存抽象与稳定规律。
-
RAG / 工具 = 短期与情景记忆,高变信息放外部检索。
-
通过训练日志与数据血缘记录,降低跨版本“灾难性遗忘”。
组件 C:稳态控制与压缩
-
剪枝、量化、蒸馏要做 性能–能耗 Pareto 监控,设红线:复杂推理与创造性优先保。
-
LoRA 合并前做 A/B 回归,防“睡过头”导致呆板。
组件 D:对抗覆盖与安全闸
-
红队样本自动生成 + 人工精选双轨,多维评测:越狱触发率、敏感指令服从度、拒答稳健性。
-
上线前强制通过“能力–对齐”双阈值,未达标不发布。
组件 E:迭代节律与门禁
-
以“睡眠周期”组织迭代:学习吸收 → 压缩巩固 → 做梦微调 → 体检发布。
-
每个周期产出最小可比对的模型卡,记录训练谱系与风险清单。
可直接改造的训练 “作息表”
下面给出一个可嵌入现有管线的伪代码示例(PyTorch 风格伪代码),核心是 Learn / Compress / Dream / Gate 四相循环。你可以把它接到现有调度器与评测框架里。
# pseudo-code for a sleep-inspired training loop
for cycle in range(num_cycles):
# 1) Learn:吸收期(高学习率 + 多样数据)
set_lr(high_lr)
train(
data=mix_corpus(
base_corpus,
curated_sft,
reasoning_tasks,
tool_use_logs,
dedup=True,
source_tiering=True
),
epochs=learn_epochs,
regularize=True
)
# 2) Compress:巩固期(降噪 + 稀疏化 + 蒸馏)
set_lr(low_lr)
prune(target_sparsity)
quantize(bits=8)
lora_merge(threshold=merge_thr)
distill(teacher=chkpt_best, student=current_model)
# 3) Dream:做梦期(合成与对抗)
synth = generate_synthetic(
strategies=[
"self_consistency_cot",
"counterfactual_qa",
"self_play_redteaming"
],
quality_gate="auto+rater"
)
finetune(
data=blend(sft, dpo_pairs, synth),
epochs=dream_epochs
)
# 4) Gate:门禁期(能力 + 安全双闸)
metrics = evaluate(
suites=[
"reasoning_suite",
"structured_output_suite",
"tool_use_suite",
"long_context_suite"
]
)
safety = redteam_eval(
suites=["jailbreak", "toxicity", "privacy", "copyright"]
)
if pass_threshold(metrics, safety):
save_as_release()
else:
rollback_or_adjust()
实践建议:让调度器支持按“周期”记录指标,避免只看单次迭代的波动。
如何让模型 “做更好的梦”
1)自一致性推理 对同一复杂问题采样多条 Chain of Thought,做一致性投票,保留高一致性样本,作为 SFT 与 DPO 的高质量增量。
2)反事实数据 对事实样本做最小扰动生成“假设场景”,训练模型识别与纠正“看似对却不对”的陷阱,提升 OOD 泛化。
3)自博弈红队 让模型以“攻守”角色互测,产出越狱样本与修复提示,再由安全策略与拒答策略吸收。
4)难例回放 把上一周期挂掉的难例与长尾集中回放,防止灾难性遗忘。回放要设置上限,避免过拟合难例。
评测与监控:别只看单点分数
核心能力面板
-
推理与规划:多步推理成功率、工具使用成功率。
-
结构化与执行:JSON 输出可解析率、函数调用参数正确率。
-
长上下文:检索召回率、引用命中率、跨段一致性。
-
生成稳健性:重复率、幻觉率、引用自信度。
-
安全与对齐:越狱触发率、敏感任务拒答正确率、礼貌稳健度。
趋势指标
-
性能–能耗 Pareto:每单位算力的有效增益。
-
创造性与多样性:在压缩后是否显著下降。
-
回归报警:对关键基准的跌落阈值与自动回滚。
常见反模式(踩坑预警)
-
永动机式训练:长时间不做“巩固与压缩”,权重膨胀、学习率失控,成本暴涨。
-
一次性大合并:LoRA 或适配器一股脑合并,导致能力互相抵消。分批、回归、留退路。
-
把 RAG 当垃圾桶:短期记忆塞满低质片段,检索命中高但答案更糟。RAG 必须有质量控制。
-
只追求安全分:过度收紧会先伤创造性与复杂推理,平衡对齐与能力是门学问。
-
放弃数据血缘:不记录数据来路与配比,问题回溯无从下手,复现困难。
版本发布节律:三种可复用的“作息表”
方案 1:应用侧小模型(周节律)
-
周一至周三:Learn + Compress。
-
周四:Dream(合成 + 红队)。
-
周五:Gate(评测 + 安全闸),傍晚小版本灰度。
-
周末:仅做索引与 RAG 更新,不改权重。
方案 2:平台基座模型(月节律)
-
第 1 周:大规模 Learn。
-
第 2 周:Compress(蒸馏、剪枝、量化)。
-
第 3 周:Dream(生成 + DPO + 领域微调)。
-
第 4 周:Gate(全量回归 + 安全)并发布候选版。
方案 3:在线系统的日更策略(天节律)
-
凌晨 2 点:索引与知识库刷新(外部记忆)。
-
凌晨 3 点:难例回放与小步 Dream(仅 LoRA)。
-
清晨 5 点:快速评测,通过则生效,否则回滚到前一日。
给团队的落地清单
-
数据:去重、分层、抽样、难例回放比例可配置化。
-
训练:Learn 与 Compress 分离调度,学习率与正则策略分档。
-
做梦:合成策略库与质量闸,上线前强制通过人工抽检。
-
安全:红队数据周更,越狱触发率作为发布硬门槛。
-
评测:标准化模型卡,记录每个周期的改动与结果。
-
成本:所有压缩动作必须伴随能力–能耗曲线更新。
-
回滚:一键回滚与“前一周期最佳”热切换,避免长时间故障。
与其让模型“硬撑”,不如让它按人类的智慧规律去“睡”。
深睡做巩固,做梦补长尾,醒来过门禁,这套范式会把你的迭代从“赌命调参”变成“有节律的工程”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)