让AI读懂财报PDF(多模态RAG)-Datawhale夏令营 baseline学习笔记以及后续思考
baseline实现了什么?baseline的RAG系统工作流程:首先,使用 mineru_pipeline_all.py(MinerU,baseline一键式跑通没有使用这个,需要GPU,安装相关依赖有些麻烦)或 fitz_pipeline_all.py(PyMuPDF,处理速度相当快,baseline使用的是这个,该章节下也只说明使用此库的后续)解析PDF文档其次,将解析结果存储在 data_
以下内容是我与DeepSeek老师和ChatGPT老师共同完成
baseline实现了什么?
baseline的RAG系统工作流程:
1. 数据准备阶段
首先,使用 mineru_pipeline_all.py(MinerU,baseline一键式跑通没有使用这个,需要GPU,安装相关依赖有些麻烦)或 fitz_pipeline_all.py(PyMuPDF,处理速度相当快,baseline使用的是这个,该章节下也只说明使用此库的后续)解析PDF文档
其次,将解析结果存储在 data_base_json_page_content/ 目录
最后,合并所有分页内容为 all_pdf_page_chunks.json
用一张表格总结:
| 步骤 | 主要脚本 / 工具 | 输入 | 产出 |
|---|---|---|---|
| 1.1 解压原始研究报告 | !unzip 或手动解压 |
datas/财报数据库.zip |
datas/财报数据库/ PDF 文件夹 |
| 1.2 PDF 解析(图文) | PDF 文件 | data_base_json_content/(按文档结构化 JSON) |
|
| 1.3 PDF 解析(纯文本快速) | PDF 文件 | 同上(可替代 1.2,速度快) | |
| 1.4 分页内容生成 | 内嵌于 1.2/1.3 | 解析结果 | data_base_json_page_content/ 每页 JSON |
| 1.5 汇总分页 | 见 1.2/1.3 尾部逻辑 | 多个分页 JSON |
说明:步骤 1.2 与 1.3 二选一;均支持自动遍历
datas/下所有 PDF。
2. 向量化阶段
首先,通过 get_text_embedding.py 生成文本嵌入向量
其次,使用 rag_from_page_chunks.py 批量处理文本嵌入
| 步骤 | 主要脚本 / 类 | 输入 | 产出 |
|---|---|---|---|
| 2.1 批量生成文本嵌入 | 或 | all_pdf_page_chunks.json 文本列表 |
向量矩阵 (内存或本地缓存) |
| 2.2 构建向量索引 | 文本嵌入 + 元数据 | 内存向量库(可改为FAISS等) |
3. 问答处理阶段
主入口为 rag_from_page_chunks.py
加载测试数据(datas/test.json)
使用 rag_from_page_chunks.py进行检索和生成
并发处理多个问题
结果存储在 output/ 目录
| 步骤 | 主要脚本 / 类 | 输入 | 产出 |
|---|---|---|---|
| 3.1 初始化 RAG | -> | 向量索引 | RAG 对象(含检索 & 生成模型) |
| 3.2 读取问题 | datas/test.json 或交互输入 |
问题列表 | — |
| 3.3 检索相关 chunk | SimpleRAG.retrieve() |
问题文本 | top-k chunk + 分数 |
| 3.4 构造 Prompt | rag_from_page_chunks.py 内部 |
问题 + chunk | 模型输入 messages |
| 3.5 生成答案 | 本地 Qwen 模型 (API/本地) | Prompt | 答案字符串 |
| 3.6 批量并发 | ThreadPoolExecutor |
多个问题 | 结果列表 |
| 3.7 保存结果 | 同脚本 | 结果列表 | rag_top1_pred.json / output/ |
4. 结果输出
生成结构化结果文件如 rag_top1_pred.json
支持交互式问答模式
文件使用情况分析
使用的核心文件:
- rag_from_page_chunks.py:RAG系统主逻辑,负责问答生成
- get_text_embedding.py:文本向量化处理
- fitz_pipeline_all.py:纯文本PDF快速解析
- extract_json_array.py:从模型输出提取JSON结构
使用的数据文件:
- datas/财报数据库/:存放PDF研究报告
- datas/test.json:测试集数据
- all_pdf_page_chunks.json:合并后的PDF分页内容
未使用/辅助性文件:
- Qwen3_14B_finetune.ipynb:模型微调脚本(未集成到主流程)
- baseline.ipynb:基础实验文件
- env.txt:环境配置参考
- dataset_infos.json:数据集元信息
改进思考
1. PDF的解析方法
对于PDF的解析,我看到比较常用的两种工具是:MinerU 与 unstructed库
我让DeepSeek帮我进行了对比
| 特性 | MinerU | Unstructured |
|---|---|---|
| 开发团队 | 上海人工智能实验室OpenDataLab团队 | Unstructured.io团队 |
| 核心功能 | PDF→Markdown/JSON转换,保留文档结构 | 文档分区(partitioning)和清理(cleaning),支持多种格式 |
| 布局支持 | 单栏/多栏/复杂布局 | 深度理解文档格式分区 |
| 元素提取能力 | 文本/表格/公式/图像/标题 | 文本/表格(复杂表格存在列偏移问题) |
| 结构保留 | 标题/段落/列表结构保留 | 分区为语义单元(document elements) |
| 局限 | 不支持垂直文本/多级标题有限 | 生产环境性能下降/无GPU支持 |
| 性能(x86 CPU) | 3.3秒/页 | 4.2秒/页 |
| 适用场景 | 科学文献/财报等结构化数据提取 | 快速原型开发/NLP数据预处理 |
关键差异总结:
- 架构设计:MinerU专注PDF深度解析和结构保留,Unstructured侧重通用文档分区
- 表格处理:MinerU支持表格标题和注脚提取,Unstructured在复杂表格上易出错
- 生产支持:Unstructured开源版非生产级,推荐其企业平台;MinerU提供Docker生产部署方案
- 多语言:MinerU对中文文档优化更好(中国团队开发)
总结说来,MinerU更适合财务报告的解析。
但是其显存要求较高,布局模型加载后就吃掉不少显存,我笔记本只有8G显存,实际运行时 8G 显存容易爆(尤其是大页 PDF)。并且,Windows 下安装依赖稍麻烦,部分模型要手动下载。
所以我需要找到一种既能利用MinerU强大的版面识别能力,同时可以在笔记本上进行解析的方法
2. MinerU 要如何使用(硬件设施有限的情况下)
这里我去问了ChatGPT
MinerU 本身不是一个完整的 OCR 端到端方案,它主要聚焦在文档版面结构分析(Layout Analysis)。
这就很符合我的想法
-
OCR模型
MinerU 内置的 OCR 模型一般是基于开源或自研的轻量文字检测与识别模型,但核心不是专门的 OCR 引擎。它的重点在“结构化元素检测”,即定位文字块、表格块、图片块的边界框,而不是精准识别文字内容。
换句话说,MinerU通常会调用已有的 OCR 模型或第三方 OCR 服务来完成文本识别。它提供的是版面分割和元素定位的功能。 -
表格处理
MinerU的表格处理通常是通过版面分析模型检测表格区域的边界,和部分单元格线条检测,帮助定位整张表格及单元格的位置。
具体识别表格内容(单元格内文字)通常需要结合 OCR 模型或者专门的表格识别模块(比如 PaddleOCR 的表格识别组件)。MinerU有集成部分这类功能,但很多场景下仍需要结合OCR结果和表格结构化算法去做后处理。
所以我萌生了一种想法:用MinerU负责布局定位,然后调用更强的视觉OCR服务做文本和表格内容识别,这样结合能兼顾显存消耗和识别精度。
3. MinerU + 视觉模型的整体思路
选择 MinerU 作为版面分析工具,输出图片和表格的位置信息,文本和图片的识别则通过调用 Qwen-VL 来完成。
我的整体处理流程是:
- 用 MinerU 分析 PDF 版面,得到文本块、图片块、表格块的位置信息(bbox)。
- 对图片块调用 Qwen VL 模型提取文字或生成摘要。
- 将文本与对应的位置信息关联,后续用于 RAG 检索与评估。
- 表格识别暂时禁用,主要专注于文本和图片处理。
4. 遇到的问题
在实现过程中,我遇到了两个主要问题:
(1) 小尺寸图片导致 OCR 报错
Qwen VL 模型对输入图片有尺寸要求(宽度和高度至少 10 像素)。
然而在 PDF 中,一些页码、装饰性图标、分隔线等图片往往非常小(例如 7×25 像素),直接传给 OCR 会报错或者浪费调用资源。
(2) API 频率限制(429 错误)
批量处理 PDF 时,OCR 请求的发送速度过快,触发了阿里百炼的速率限制,出现 429 Too Many Requests 错误。
5. 解决问题的方法
为了保证系统稳定性和效率,我在 OCR 调用部分做了三项关键优化:
1. 图片尺寸过滤
- 在调用 OCR 之前,先检测图片宽度和高度。
- 如果宽度或高度小于
OCR_MIN_IMAGE_SIZE = 10,跳过该图片并记录日志。 - 这样可以避免无效调用,并减少 API 请求次数。
2. 限速机制
- 假设 API 限制为每秒 2 次请求(可通过
OCR_RATE_LIMIT_PER_SECOND配置)。 - 使用
OCRRateLimiter控制请求节奏,确保调用间隔约为 0.5 秒。 - 有效避免触发 429 错误。
3. 自动重试机制
- 针对 429 错误,优先解析 API 返回的
Retry-After时间,否则使用默认延迟(3 秒)。 - 最多重试 3 次,如果仍失败则跳过该图片并记录错误。
- 避免因为网络波动或短暂超限而中断批处理任务。
PDF解析最终方案
1. 总体策略概览
(1)版面分析优先级与回退策略
- 当然首选 MinerU 做版面分析,但若当 MinerU 环境依赖不足(如缺少 magic_pdf,在win环境下,依赖安装太麻烦了,总是出现版本问题)时,会自动回退到 PyMuPDF 做版面分析。
经过反复尝试,总算解决版本依赖问题,然而批处理PDF后,查看解析日志,发现居然全是PyMuPDF,好嘛,这次我就放弃了,之后抽时间好好学习一下这类开源工具的安装使用。
- 回退行为与元素总数会被详细记录在系统日志中,可从日志看到多次回退并统计出每个 PDF 的元素数量。
(2)元素分治与异步处理(这里是尊敬的D老师写的)
- 版面分析结果被统一抽象为 LayoutElement(类型含 text/table/image,带有 page_num 与 bbox)。
- OCR 阶段按照元素类型分组并发处理(受并发信号量控制),表格识别可通过配置开关启停。
- 小尺寸图片会被跳过(有最小尺寸阈值),跳过会写日志并在 OCRResult 中标记 error。
- 结果标准化、分块与向量化
- OCR 结果统一封装为 OCRResult(包含文本、置信度、page_num、bbox、element_type、error 等)。
- Chunker 将 OCR 结果按语义与空间线索生成可检索的文本块,并追加来源位置信息等元数据。
- 文本块异步送入向量化模块,随后写入公司级别的 FAISS 索引。
(3)批处理增强能力
批处理对多 PDF 进行遍历与并发控制,自动衍生公司 ID(这里我是按公司名字划分的faiss数据库,库,方便查询)。
(4)入库
将得到的向量与其元数据按 company_id 写入对应的 FAISS 索引
2. 批量处理完成摘要
跑了很久,从晚上11点到第二天的下午5点
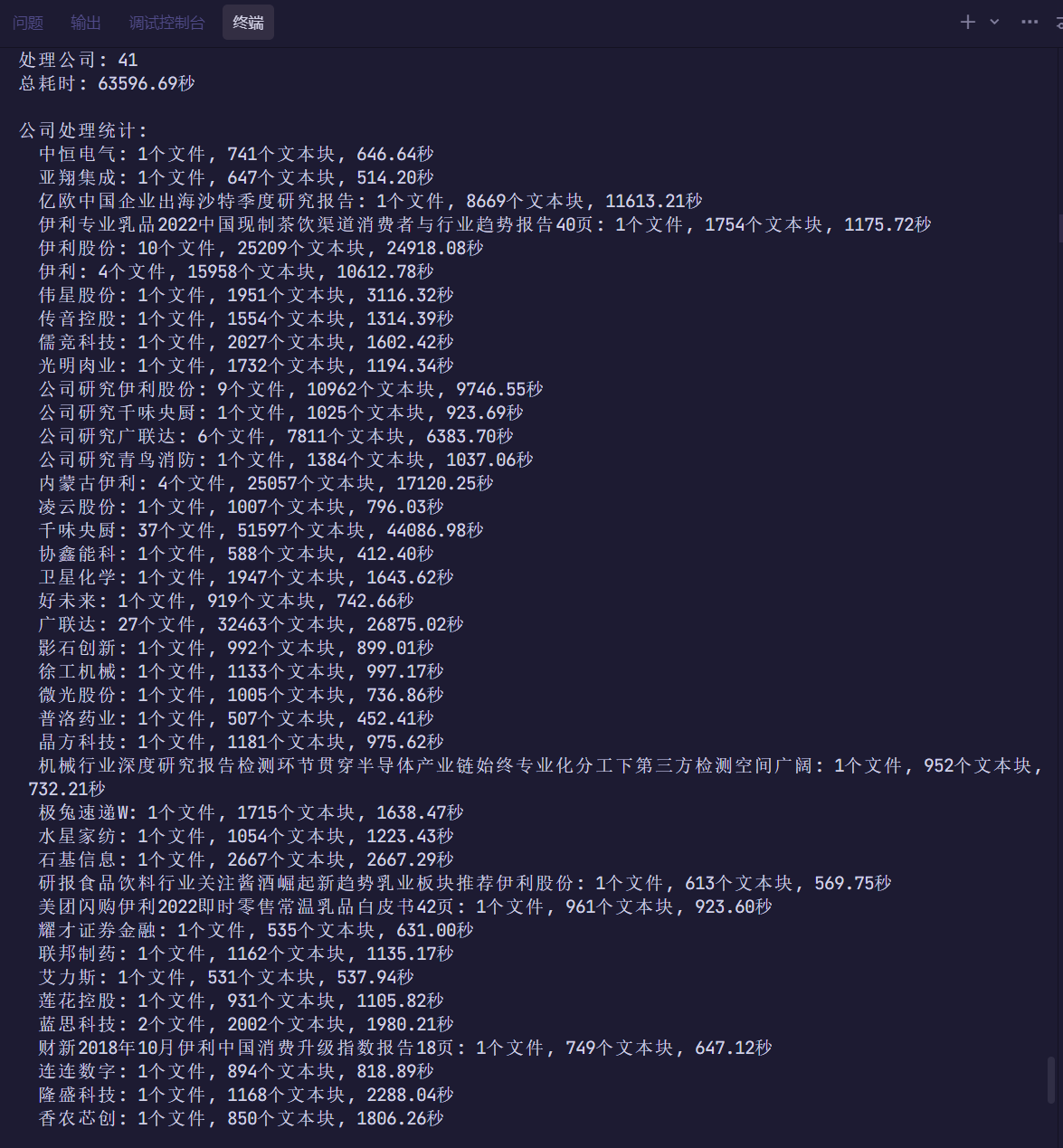
总文件数: 132
成功处理: 132
处理失败: 0
跳过文件: 0
总文本块: 216604
处理公司: 41
总耗时: 63596.69秒
公司处理统计:
中恒电气: 1个文件, 741个文本块, 646.64秒
亚翔集成: 1个文件, 647个文本块, 514.20秒
亿欧中国企业出海沙特季度研究报告: 1个文件, 8669个文本块, 11613.21秒
伊利专业乳品2022中国现制茶饮渠道消费者与行业趋势报告40页: 1个文件, 1754个文本块, 1175.72秒
伊利股份: 10个文件, 25209个文本块, 24918.08秒
伊利: 4个文件, 15958个文本块, 10612.78秒
伟星股份: 1个文件, 1951个文本块, 3116.32秒
传音控股: 1个文件, 1554个文本块, 1314.39秒
儒竞科技: 1个文件, 2027个文本块, 1602.42秒
光明肉业: 1个文件, 1732个文本块, 1194.34秒
公司研究伊利股份: 9个文件, 10962个文本块, 9746.55秒
公司研究千味央厨: 1个文件, 1025个文本块, 923.69秒
公司研究广联达: 6个文件, 7811个文本块, 6383.70秒
公司研究青鸟消防: 1个文件, 1384个文本块, 1037.06秒
内蒙古伊利: 4个文件, 25057个文本块, 17120.25秒
凌云股份: 1个文件, 1007个文本块, 796.03秒
千味央厨: 37个文件, 51597个文本块, 44086.98秒
协鑫能科: 1个文件, 588个文本块, 412.40秒
卫星化学: 1个文件, 1947个文本块, 1643.62秒
好未来: 1个文件, 919个文本块, 742.66秒
广联达: 27个文件, 32463个文本块, 26875.02秒
影石创新: 1个文件, 992个文本块, 899.01秒
徐工机械: 1个文件, 1133个文本块, 997.17秒
微光股份: 1个文件, 1005个文本块, 736.86秒
普洛药业: 1个文件, 507个文本块, 452.41秒
晶方科技: 1个文件, 1181个文本块, 975.62秒
机械行业深度研究报告检测环节贯穿半导体产业链始终专业化分工下第三方检测空间广阔: 1个文件, 952个文本块, 732.21秒
极兔速递W: 1个文件, 1715个文本块, 1638.47秒
水星家纺: 1个文件, 1054个文本块, 1223.43秒
石基信息: 1个文件, 2667个文本块, 2667.29秒
研报食品饮料行业关注酱酒崛起新趋势乳业板块推荐伊利股份: 1个文件, 613个文本块, 569.75秒
美团闪购伊利2022即时零售常温乳品白皮书42页: 1个文件, 961个文本块, 923.60秒
耀才证券金融: 1个文件, 535个文本块, 631.00秒
联邦制药: 1个文件, 1162个文本块, 1135.17秒
艾力斯: 1个文件, 531个文本块, 537.94秒
莲花控股: 1个文件, 931个文本块, 1105.82秒
蓝思科技: 2个文件, 2002个文本块, 1980.21秒
财新2018年10月伊利中国消费升级指数报告18页: 1个文件, 749个文本块, 647.12秒
连连数字: 1个文件, 894个文本块, 818.89秒
隆盛科技: 1个文件, 1168个文本块, 2288.04秒
香农芯创: 1个文件, 850个文本块, 1806.26秒
检索方案
对于RAG,我第一时间想到的有两套方案:
- 混合检索(向量检索 + BM25)
- 粗排 + 精排

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)