Graph Reasoning Transformers for Knowledge-Aware Question Answering(AAAI 2024)
GraphReasoningTransformers(GRT)模型通过融合知识图谱(KG)与语言模型来提升知识感知问答性能。GRT包含三个关键组件:1)三元组图编码器,将KG关系特征转化为可计算表示;2)跨模态表示对齐预训练,通过文本-三元组匹配和掩码语言建模实现模态对齐;3)带注意力偏置的跨模态信息融合层,建立文本与KG实体间的细粒度关联。实验在CommonsenseQA、OpenbookQA和
Introduction
现有方法局限性
- 预训练语言模型对参数化知识的过度依赖:事实错误和过时信息,幻觉现象
- 图神经网络无法充分利用知识图谱:节点嵌入维度的非关键性,节点嵌入,消息传递切除的意外效果
- 由于各种数据结构和编码方法之间的差异,可以观察到自然语言文本和KG之间相同实体的分布差距,这极大地限制了模型对齐和利用两种数据源的能力,文本和KGs模态没有深度交互和融合;
Graph Reasoning Transformers (GRT)
- 提出了一个新颖的知识图谱(KG)增强问答模型GRT,利用三元组作为原子知识来增强语言模型(LMs),以结构化的世界知识进行知识感知问答。
- 提出了一个三元组级别的图编码器,用于捕获“关系”知识特征以进行联合推理。
- 提出了一种表示对齐预训练,用于在预训练期间对齐跨模态表示,并引入了一个带有精细注意力偏差的信息融合层,以实现微调期间语言和KG之间的跨模态信息融合。
- 在两个常识问答基准数据集和一个生物医学问答基准数据集上取得了最先进的结果,这些数据集严重依赖于知识感知推理,展示了GRT捕获单模态特征并利用跨模态信息进行联合推理的能力。
Methodology
图推理Transformers
GRT主要由三个部分组成:三元组图编码器、表示对齐预训练和跨模态信息融合过程。
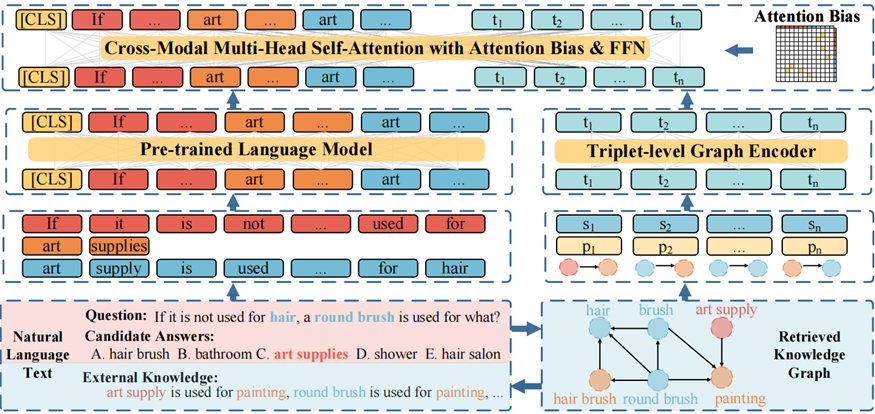
通过提取QA中的实体,在知识图谱中提取QA实体的k跳能到达的所有结点构建Retrieved KG。
基于三元组级的图编码器来捕获关系知识特征
知识感知QA更关注于识别哪些知识三元组可以支持答案,而节点信息可以用序列号替换以区分不同的实体。因此,最初的节点嵌入是不必要的。
语义三元组嵌入
如果实体在问题/答案上下文中,它被表示为问题/答案类实体。否则,实体被表示为其他类实体。因此,语义三元组初始嵌入可以表示如下:
![]()
其中 τh和 τo是头和尾实体类型的独热表示,而 τr是关系的独热表示。
空间位置嵌入
使用TransE 来唯一定位知识三元组的空间位置:
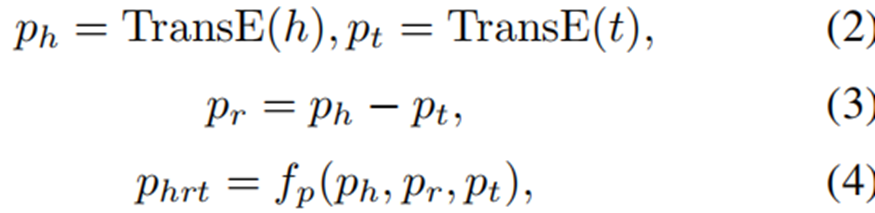
三元组编码器
获得语义三元组和空间位置嵌入后,我们将这两种类型的嵌入连接来形成输入表征t,并使用三元组编码器对知识三元组进行编码:
![]()
基于跨模态对应的表示对齐预训练
我们提出了一种基于跨模态对应的表示对齐预训练,以对齐文本和知识图谱的跨模态表示。
文本-三元组匹配
首先,我们使用一个上下文语言模型作为主干来编码QA上下文和文本化的世界知识:
![]()
对于QA上下文中提到的文本实体,我们使用对应于实体的最后隐藏状态作为文本实体表示。如果实体包含多个token,我们对实体的所有token应用均值池化以获得实体表示。
对于QA上下文中提到的文本实体,包含此实体的知识三元组作为正文本-三元组对;否则,三元组为负对。然后,我们将文本实体表征和三元组表征连接起来,使用MLP计算文本实体表征与三元组表征匹配的概率y。
对于每个QA上下文,我们选择k1个正文本-三元组对和k2个负对进行预训练。正对标签被分配为1,负对被分配为0。最后,文本-三元组匹配损失可以表示如下:
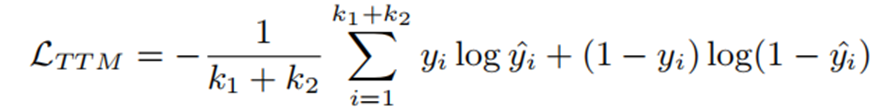
掩码语言建模
先按照模板把知识图谱的三元组转换为句子,使用pretrained sentence transformer计算所有句子和QA上下文的相似性分数,并最终选择前20个三元组句子作为线索。最后,我们将QA上下文和线索连接起来作为输入序列。遵节点嵌入节点嵌入的过程,随机选择15%的token进行掩码语言建模,计算损失LMLM。总的预训练损失表示如下:
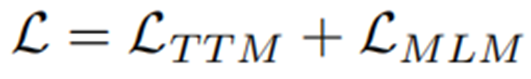
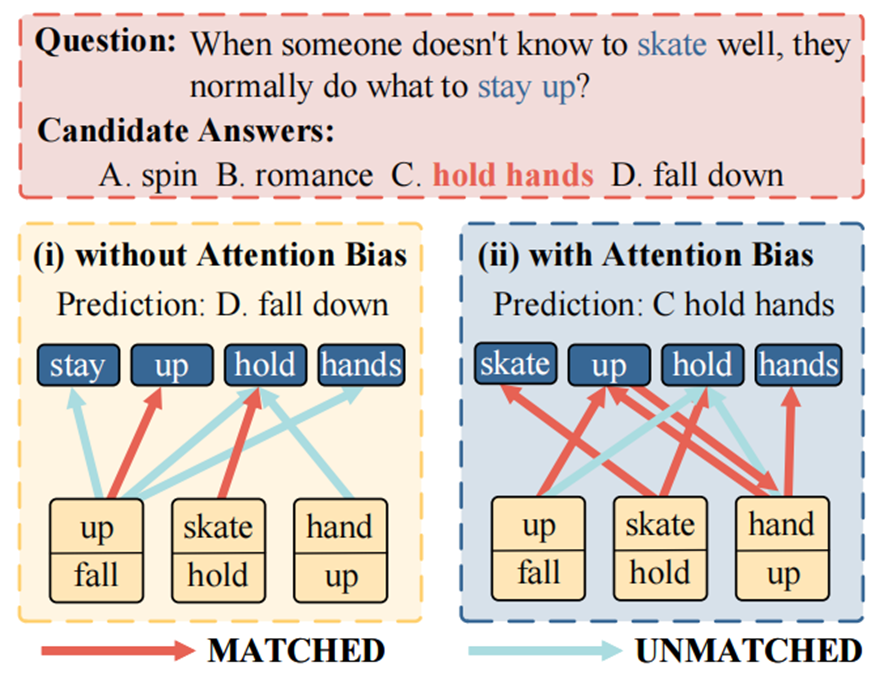
跨模态信息融合与注意力偏置
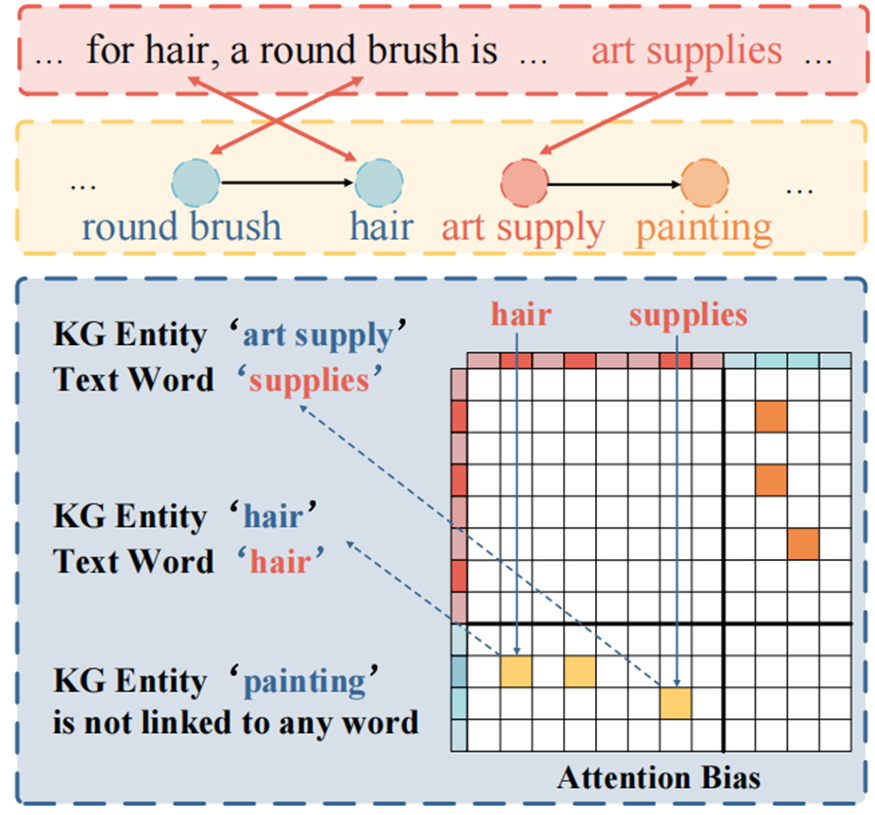
一个文本实体与知识图谱中实体对应时可能会经历语法变化或包含多个单词。例如,经过实体链接后,文本实体“car shows”同时链接到知识图谱实体“car”和“show”。在这种情况下,我们旨在建立文本实体标记“shows”与相应的知识图谱实体“show”之间的跨模态连接。
本文使用预训练词嵌入模型计算每个kg三元组头/尾实体与QA文本实体的相似度,对每个三元组头/尾实体,把最高相似性的QA文本实体与之连接。
只保留QA文本中提到的知识图谱实体的连接,以避免在标记和无关的知识三元组之间引入注意力噪声。
注意力偏置Ω
在获得连接矩阵后,我们构建一个注意力偏置矩阵,使得在计算跨模态融合层的注意力时,连接的跨模态标记可以获得更高的注意力权重。注意力偏置矩阵可以表示如下:
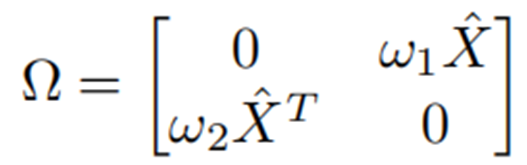
跨模态信息融合
在跨模态信息融合模块中,我们将M个Transformer块堆叠作为主干,并修改多头注意力块以采用原始Transformer进行跨模态信息融合。我们的跨模态多头注意力机制可以表示如下:
![]()
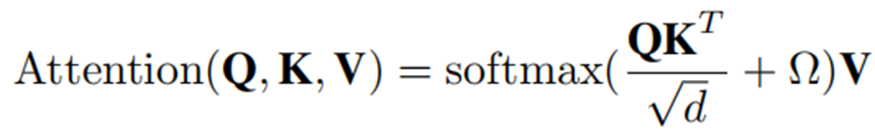
在跨模态信息模块之后,我们使用一个MLP来计算候选答案的信心分数。形式上,给定一个问题q和一个候选答案c,候选答案c的置信度可以表示如下:
![]()
其中[hCLS;h1;...;hI]是跨模态信息融合层的输出隐藏状态。我们利用最终的隐藏状态进行答案预测。我们在训练期间使用交叉熵损失,并以最大概率预测候选答案作为答案预测。
Experiments
数据集
- CommonsenseQA: 这是一个常识问答数据集,包含12247个问题,需要基于常识知识的知识感知推理。每个问题提供5个候选答案。
- OpenbookQA: 这是一个常识问答数据集,包含5957个问题,需要常识知识和基本科学知识进行推理。每个问题提供4个候选答案。
- MedQA-USMLE: 这是一个医学领域的问答数据集,包含12723个问题,需要生物医学和临床知识进行推理。每个问题提供4个候选答案。
评价指标
ACC
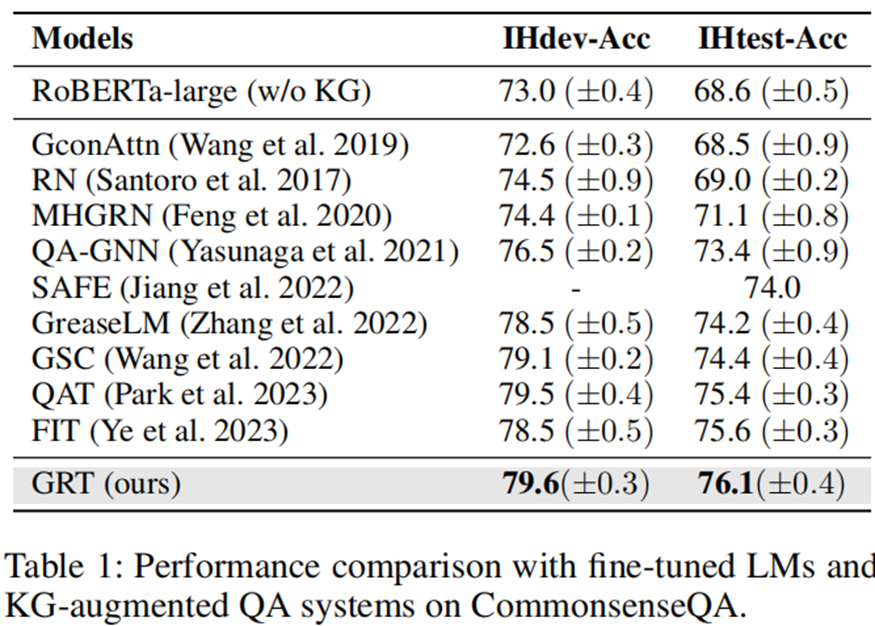
结果
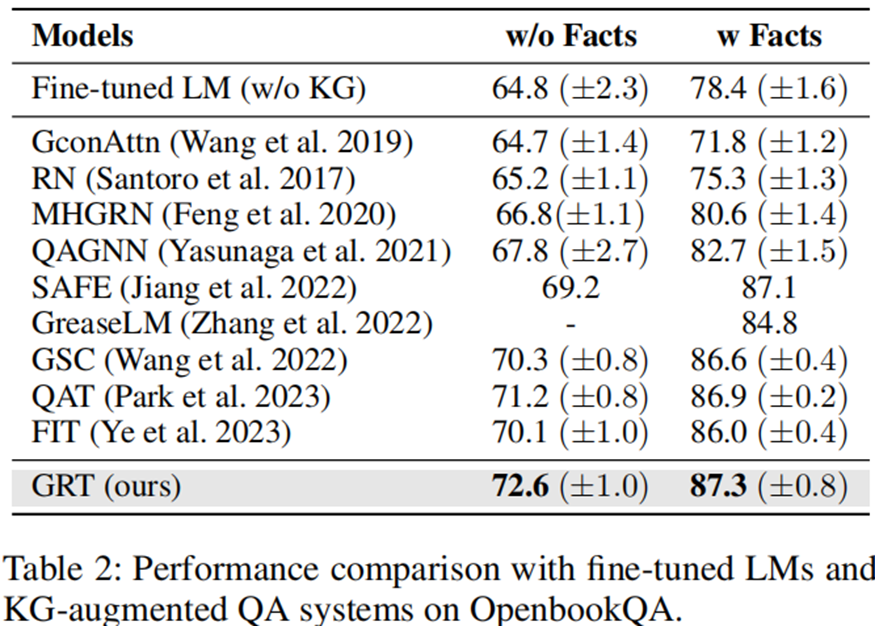
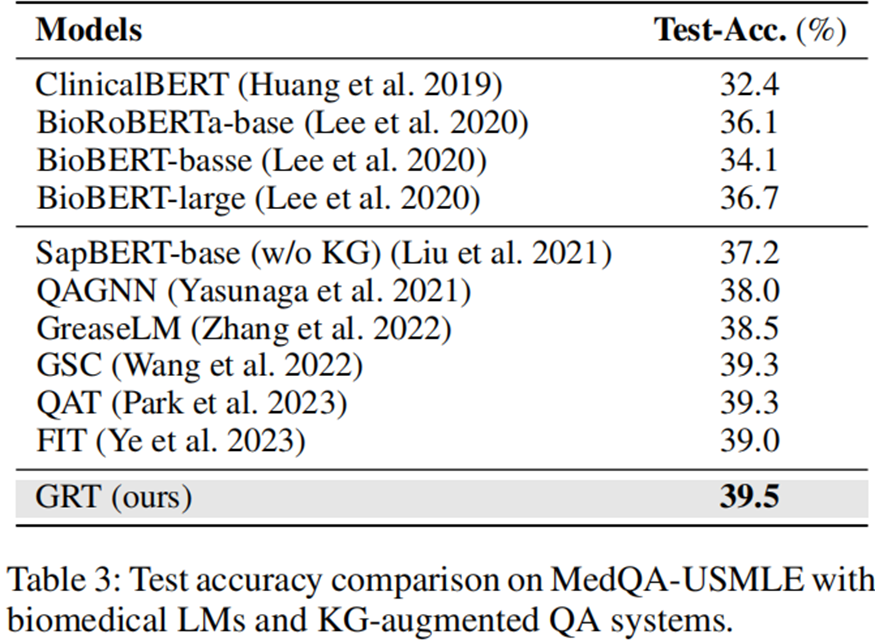
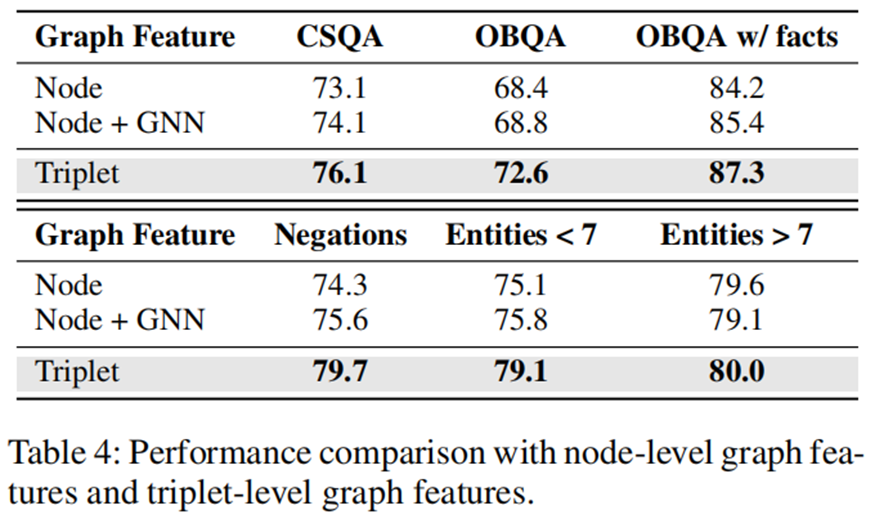
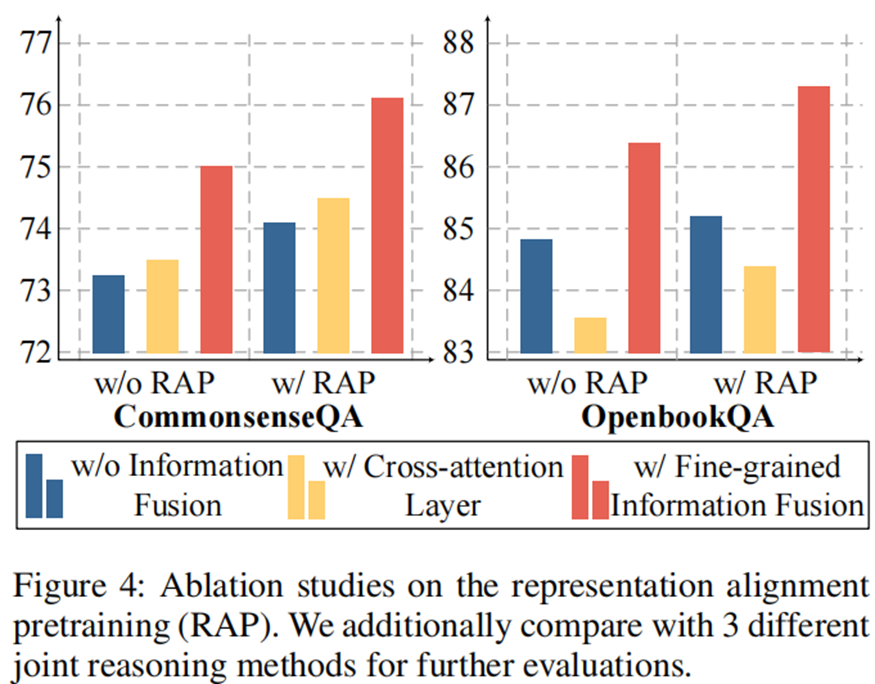
消融实验
案例研究
Conclusion
GRT解决了传统QA模型在处理结构化世界知识时存在的困难,如无法直接利用KG中的知识元组等。通过引入KG的知识元组作为原子知识,并结合跨模态信息融合技术和注意力偏差技术,GRT能够在保持原有问答任务的基础上,更有效地利用结构化世界知识,提高模型的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)