MySQL讲解/内部结构/索引下推/Explain/慢查询(必备)
MySQL 内部结构与执行计划
1. MySQL 内部结构
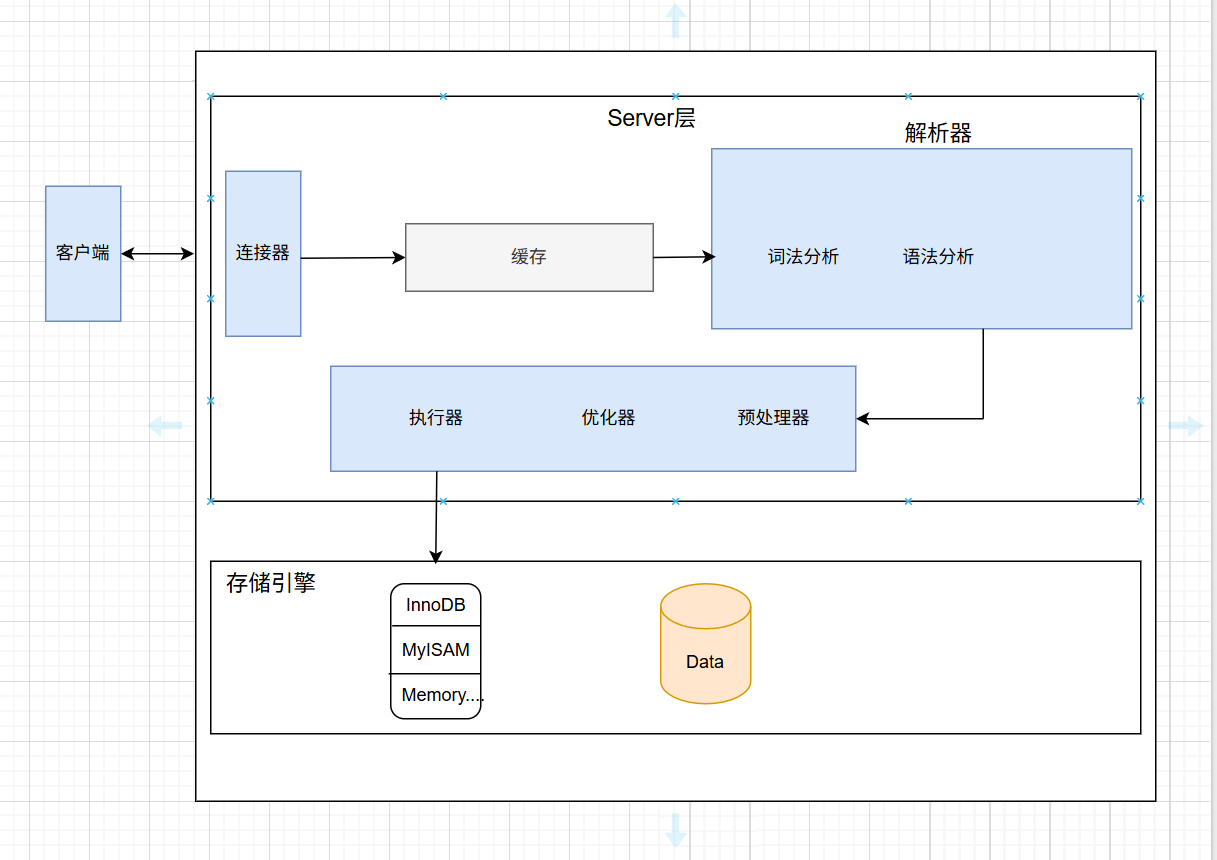
总体来说,MySQL 分为 Server 层 和 存储引擎层。
索引下推:数据的筛选从Server层下推到存储引擎层,主要发生在联合索引上,当前面的的字段发生索引失效,如果没有索引下推,那直接进行回表,最后在Server层进行数据筛选。
如果有索引下推,那么还会继续根据后续字段进行筛选,也就是在存储引擎层筛选。减少回表次数,提升查询速度。
1.1 Server层
总体来说,整个mysql分为Server层和存储引擎层。
Server层:主要包含连接器,查询缓存,解析器,预处理器,优化器,执行器...等,其中查询缓存在mysql8完全剔除。
存储引擎:主要包括多种存储引擎
1.1.1连接器
向mysql发送sql语句时,首先我们得客户端要先与mysql连接器创建连接,完成TCP握手。

终端,在进入这个路径,输入mysql -u root -p 并输入你的密码。
此时我们已经和mysql创建了一个连接,输入show processlist查看MySQL服务被多少个客户端连接。(最大连接数量151)
1.1.1.1权限
当我们在mysql用户密码认证成功后,连接器上权限表会查询该用户所拥有的权限,在此之后,该用户的权限都依赖于初始读到的权限信息。即使中途权限修改。

那么这里面发生了什么事情呢?
我们的连接方式有两种,一种是长连接,一种是短连接。
他们的区别在于请求完是否会释放连接。前者客户端与用户端连接后一直不关闭,后者每次请求完都会关闭。当然这会造成巨大的性能开销,所以说在高并发的情况下,短连接并不是最佳之策,还需要使用我们的长连接,但它也并不是完美的,长连接的堆积会造成我们MySQL占用内存太大。
解决策略:
1 定期断开长连接
2 客户端主动重置连接
其实当连接器验证我们账户密码正确时,连接器就会获取当前用户得权限,然后保存起来。后续得任何操作,都会基于我们连接一开始保存的权限信息进行权限分配的判断。也就是说,即使中途我们修改了权限,此时的任何权限判断也是基于连接一开始保存的为准。s
1.1.2 解析器
-
作用:将 SQL 解析为 MySQL 能理解的结构。
-
步骤:
-
词法分析:识别 SQL 中的关键字、表名、字段名等。
-
语法分析:检查 SQL 是否符合 MySQL 语法规则。
-
1.1.3 预处理器
-
检查表、字段是否存在。
-
将
*展开成实际字段列表。
1.1.4 优化器
-
确定 SQL 的执行计划,例如使用哪一个索引、表的连接顺序等。
1.1.5 执行器
-
根据执行计划,从存储引擎中读取数据。
-
如果是全表扫描,会调用存储引擎的接口循环取数据。
1.2 存储引擎
-
MySQL 数据是存储在 聚簇索引 上的(以 InnoDB 为例)。
-
聚簇索引的主键选择规则:
-
如果表有主键(PRIMARY KEY),则使用它作为聚簇索引键。
-
如果没有主键,则选择第一个非空唯一索引作为聚簇索引键。
-
如果没有合适的唯一索引,InnoDB 会生成一个 隐藏主键(6 字节 ROWID)。
-
2. EXPLAIN 执行计划
2.1 id 执行顺序
id代表表查询顺序 id 相同,执行顺序从上往下 id 不同 id递增,大的先执行、
-
相同 id:按从上到下顺序执行。
-
不同 id:id 值大的先执行。
例 1:相同 id(多表 JOIN)
EXPLAIN
SELECT *
FROM user u
JOIN orders o ON u.id = o.user_id;
| id | select_type | table | type |
|---|---|---|---|
| 1 | SIMPLE | u | ALL |
| 1 | SIMPLE | o | ref |
| 解释:两表 JOIN,id 相同,从上到下依次执行。 |
例 2:不同 id(子查询)
EXPLAIN
SELECT *
FROM user
WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);
| id | select_type | table | type |
|---|---|---|---|
| 2 | SIMPLE | orders | range |
| 1 | SIMPLE | user | ALL |
| 解释:子查询的 id=2 先执行,主查询的 id=1 后执行。 |
例 3:混合
EXPLAIN
SELECT u.*, t.total_amount
FROM user u
JOIN (
SELECT user_id, SUM(amount) AS total_amount
FROM orders
GROUP BY user_id
) t ON u.id = t.user_id;
| id | select_type | table | type |
|---|---|---|---|
| 2 | DERIVED | orders | index |
| 1 | SIMPLE | u | ALL |
| 1 | SIMPLE | t | ref |
| 解释:先执行 id=2(派生表),生成临时表,再执行 id=1 的 JOIN。 |
2.2 select_type 查询类型
| 类型 | 说明 | 示例 |
|---|---|---|
| SIMPLE | 查询中不包含子查询或 UNION | EXPLAIN SELECT * FROM user WHERE age > 30; |
| PRIMARY | SQL 中包含子查询时,最外层查询标记为 PRIMARY | EXPLAIN SELECT * FROM user WHERE id IN (SELECT user_id FROM orders); |
| DERIVED | FROM 后的子查询,先执行并存入临时表 | 见例 3 |
| SUBQUERY | 子查询出现在 WHERE 或 SELECT 列表中 | EXPLAIN SELECT * FROM user WHERE id = (SELECT MAX(user_id) FROM orders); |
2.3Table查询的表名
2.4Type访问类型
system 表中只有一行数据
const 主键索引/唯一索引
eq_ref 基于驱动表(主表)的字段,多次通过被驱动表(从表)的主键或唯一索引进行等值匹配
ref 普通索引类型访问
range 索引范围查询
index 全索引扫描,不过数据只需要在节点读取即可,不需要回表。
All 全索引扫描,基于聚簇索引,要到叶子节点拿整行数据
效率:system > const > eq_ref > ref > range > index > All
2.5 possible_keys 可能用到的索引列表
显示可能用的索引名称,[如果查询的字段存在某一个索引上,就把改索引列出来]
select * from person where id is not null ---
2.6 key 实际使用索引
2.7 ref
显示使用了等值匹配哪个列进行过滤
2.8 rows
mysql中优化器估计的要扫描的行数
2.9 extra
一些重要的额外信息
Using filesort 排序字段没有使用索引
Using temporary 分组时没有使用索引 一般没有Using filesort 因为分组需要用到排序
Using index 用到了索引覆盖
Using where 使用了where过滤
慢查询
-- 慢查询日志相关的系统变量
SHOW VARIABLES LIKE '%slow_query_log%';
-- 开启慢查询日志
set GLOBAL slow_query_log = 1
-- 设置时间阈值 超过的sql语句就会被记录在慢查询日志
set GLOBAL long_query_time = 3;
-- 查看时间阈值
show VARIABLES LIKE '%long_query_time%'
慢查询日志文件位置:"C:\ProgramData\MySQL\MySQL Server 8.0\Data\LAPTOP-G7ETDH5B-slow.log"
日志
undo log(回滚日志)
1.在事务未提交之前,会将执行的命令记录在undo log日志中,当需要回滚时,根据日志执行相反的操作。
2. 通过read view快照 + undo log实现mvcc --> 存储旧版本数据

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)