LLaMA-Factory 快速入门(一):Mac 下大模型微调与部署全流程
文章目录
1. 引言
LLaMA Factory 是一个开源的大语言模型微调框架,旨在降低 大模型定制化 的技术门槛。无论是初学者还是资深开发者,都能通过它提供的命令行工具或可视化界面(LLaMA Board),轻松完成从 数据准备→模型微调→部署 的全流程操作。
该项目在 GitHub 上拥有极高的关注度,获得了数万星标,支持 Amazon、NVIDIA、阿里云等知名企业的技术生态,并且持续迭代更新,紧跟前沿模型和算法的发展。该项目有如下特色:
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、DeepSeek、Yi、Gemma、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、APOLLO、Adam-mini、Muon、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
- 实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
- 广泛任务:多轮对话、工具调用、图像理解、视觉定位、视频识别和语音理解等等。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
- 极速推理:基于 vLLM 或 SGLang 的 OpenAI 风格 API、浏览器界面和命令行接口。
目前支持的训练方法有如下:
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ✅ | ✅ |
| PPO 训练 | ✅ | ✅ | ✅ | ✅ |
| DPO 训练 | ✅ | ✅ | ✅ | ✅ |
| KTO 训练 | ✅ | ✅ | ✅ | ✅ |
| ORPO 训练 | ✅ | ✅ | ✅ | ✅ |
| SimPO 训练 | ✅ | ✅ | ✅ | ✅ |
本文主要讲解基于 Mac M系列芯片架构 来安装 LLaMA-Factory。
2. 软硬件要求
软件要求:
| 必需项 | 至少 | 推荐 |
|---|---|---|
| python | 3.9 | 3.10 |
| torch | 2.0.0 | 2.6.0 |
| torchvision | 0.15.0 | 0.21.0 |
| transformers | 4.49.0 | 4.50.0 |
| datasets | 2.16.0 | 3.2.0 |
| accelerate | 0.34.0 | 1.2.1 |
| peft | 0.14.0 | 0.15.1 |
| trl | 0.8.6 | 0.9.6 |
硬件要求:
| 可选项 | 至少 | 推荐 |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.16.4 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm | 0.4.3 | 0.8.2 |
| flash-attn | 2.5.6 | 2.7.2 |
看到上面的硬件配置,大家可能会有疑惑 LLaMA-Factory不是只能在 NVIDIA GPU 上运行(如 CUDA 支持)吗 ?这种说法并不对,LLaMA-Factory只是 主打 在 NVIDIA GPU 上运行,在Mac上也是可以运行的,主要原因如下:
- 它基于 transformers 和 PEFT 框架,支持 CPU 和 Metal(macOS GPU)后端。
- bitsandbytes 虽然不支持 macOS,但你可以使用替代的量化方法(如 gptq, awq)或改用 CPU 运行。
- PyTorch 对 macOS 支持良好,Apple Silicon 甚至支持 MPS(Metal Performance Shaders)作为后端加速。
在实际中,运行 LLaMA-Factory 可能是以下几种模式之一:
- 使用 CPU 模式运行(慢但兼容)
- 使用 GPU 模式 + MPS 后端加速(推荐)
- 使用量化模型(如 4bit QLoRA)以减少内存占用
- 仅做推理(inference)或轻量微调(LoRA/QLoRA)
当然,如果不确定自己的Mac是否支持MPS,可以新建一个 test.py 文件,输入以下内容:
import torch
print("是否支持 MPS (Apple GPU):", torch.backends.mps.is_available())
print("是否编译支持 MPS:", torch.backends.mps.is_built())
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print("当前使用的设备:", device)
运行之后的结果如下,表示支持: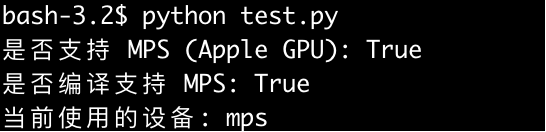
当然,也可以点击屏幕左上角的苹果图标,选择 “关于本机” → “系统报告”。在系统报告中,展开 “图形 / 显示器(Graphics/Displays)” 部分,这里会显示芯片中图形处理单元的详细信息,包括芯片组模型、显存大小等: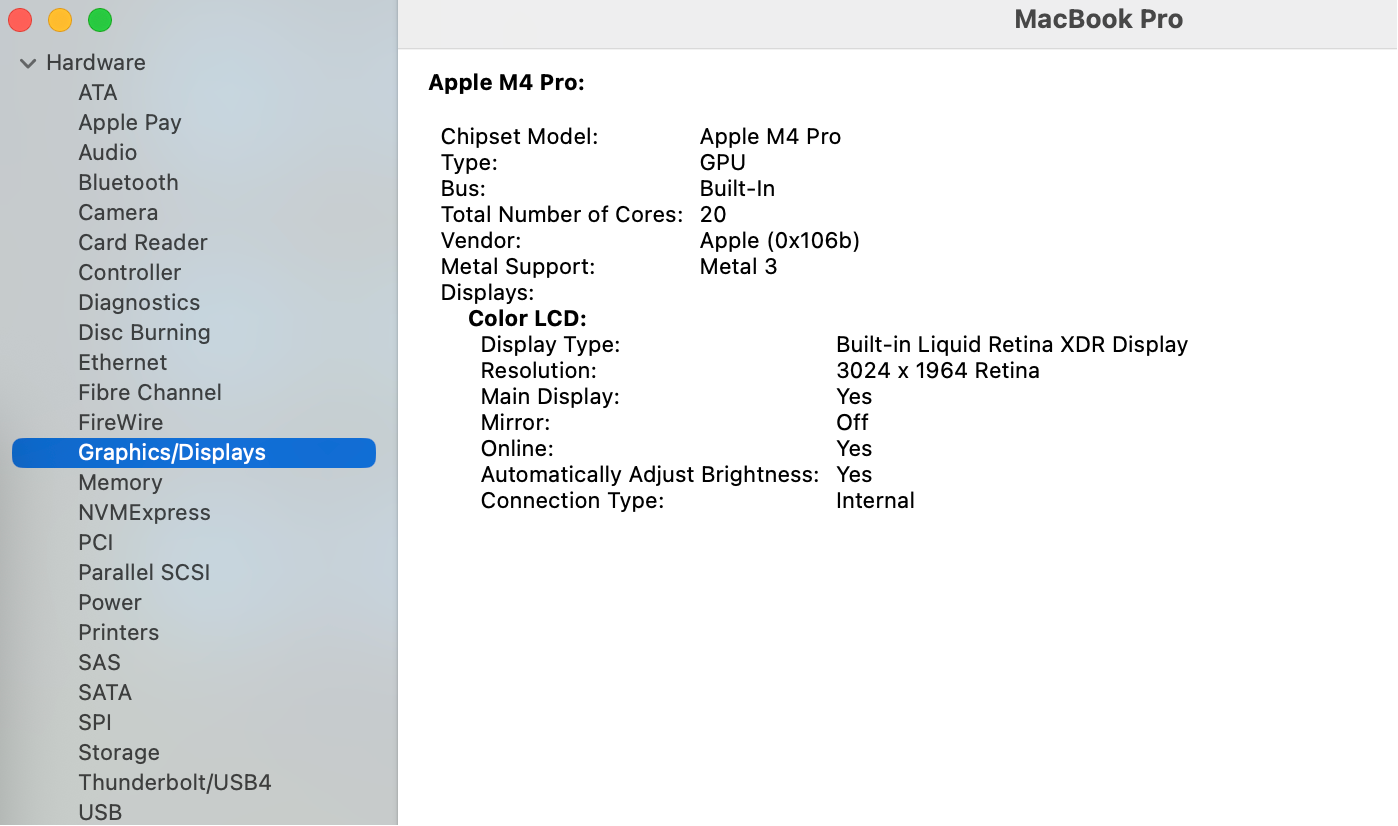
3. 安装
注意:本文默认已经安装了 python 以及 git 。
3.1 克隆源码
有了以上的环境,根据官网的教程,安装是十分便捷的。首先克隆源码到本地:
# 克隆源码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
3.2 开始安装
开始安装:
# 进入到源码目录
cd LLaMA-Factory
# 开始安装
pip install -e ".[torch,metrics]" --no-build-isolation
安装成功后显示如下: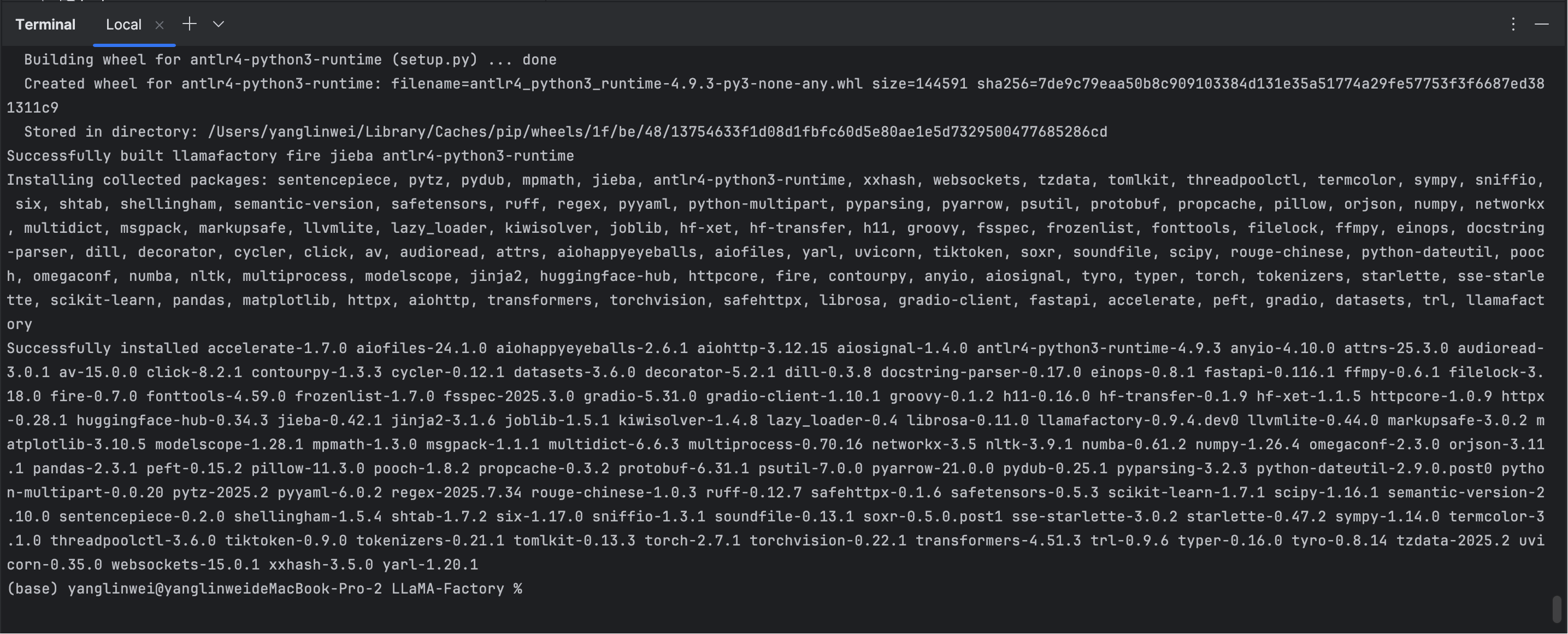
3.3 命令解析
上述命令的含义是在当前目录下开发模式安装 Python 项目,并安装附加依赖(torch、metrics),使用当前环境构建而非隔离构建。额外启用一些可选依赖项可以从项目根目录下的 setup.py 看到: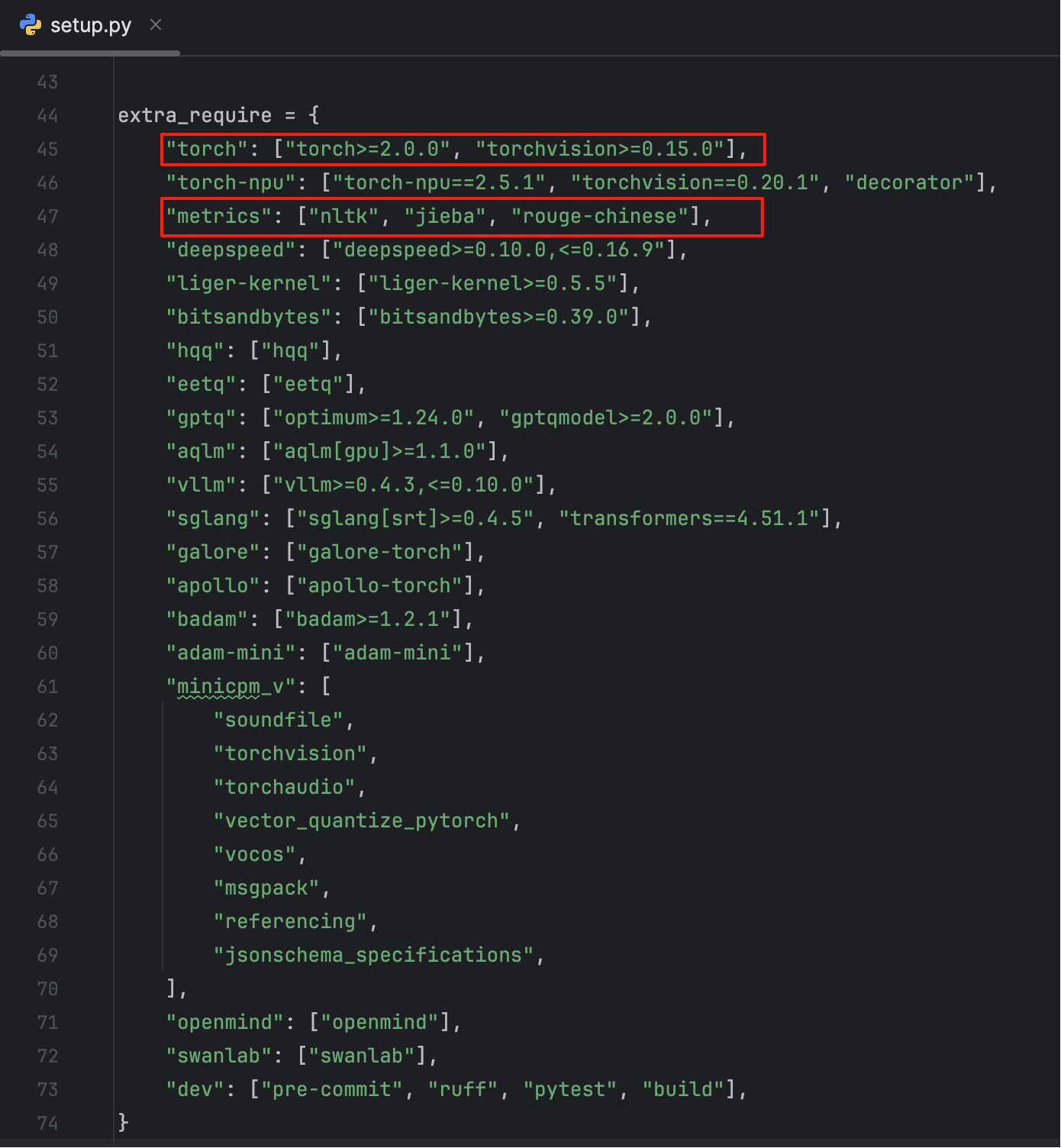
以下是其它额外依赖的描述:
| 选项名 | 依赖项 | 用途说明 |
|---|---|---|
torch |
torch, torchvision | 基础的 PyTorch 支持,适用于大多数 CPU/GPU 推理和训练。 |
torch-npu |
torch-npu, torchvision, decorator | 华为 Ascend NPU 支持(如昇腾),替代 CUDA。 |
metrics |
nltk, jieba, rouge-chinese | 中文/英文文本评估工具,如 ROUGE、分词、BLEU 等。 |
deepspeed |
deepspeed | 使用 DeepSpeed 加速大模型训练或推理(支持 ZeRO 等)。 |
liger-kernel |
liger-kernel | 支持 Liger 推理优化,加速 Transformer。 |
bitsandbytes |
bitsandbytes | 支持量化模型(如 8-bit/4-bit 推理),降低内存占用。 |
hqq |
hqq | HQQ 模型量化支持。 |
eetq |
eetq | 百度的 EETQ 量化库支持。 |
gptq |
optimum, gptqmodel | 使用 GPTQ 量化模型进行加速推理(兼容 Hugging Face)。 |
aqlm |
aqlm[gpu] | AQLM 支持,适用于低比特推理。 |
vllm |
vllm | 使用 vLLM 快速推理(兼容 FlashAttention)。 |
sglang |
sglang[srt], transformers==4.51.1 | 使用 SGLang 多轮对话框架,需匹配的 transformers 版本。 |
galore |
galore-torch | 使用 GaLore 训练优化器(梯度低秩表示)。 |
apollo |
apollo-torch | Apollo 优化器支持,减少内存占用。 |
badam |
badam | BaDAM 优化器,支持大模型训练优化。 |
adam-mini |
adam-mini | 更轻量的 Adam 实现,减少训练时内存消耗。 |
minicpm_v |
多个依赖(如 soundfile, torchaudio) | MiniCPM-V 模型支持(多模态、语音、视觉推理等)。 |
openmind |
openmind | 支持 OpenMind 微调工具链。 |
swanlab |
swanlab | 实验可视化平台支持,类似 WandB。 |
dev |
pre-commit, ruff, pytest, build | 🛠️ 开发者工具(代码格式化、测试、构建)支持。 |
✅ 小贴士
- 如果你只做普通训练/推理:只需安装
torch和metrics。 - 如果用 vLLM 推理大模型:加上
vllm。 - 如果用 GPTQ 等量化模型推理:加上
gptq或bitsandbytes。 - 如果你是开发者,想提交代码或测试:加上
dev。 - 如果你使用国产 AI 芯片(昇腾):加上
torch-npu。
3.4 启动 web ui
启动 LLaMa-Factory 也是比较简单的,直接使用 llamafactory-cli 来启动即可,同学们可以通过help命令查看该脚本支持哪些功能:
llamafactory-cli --help
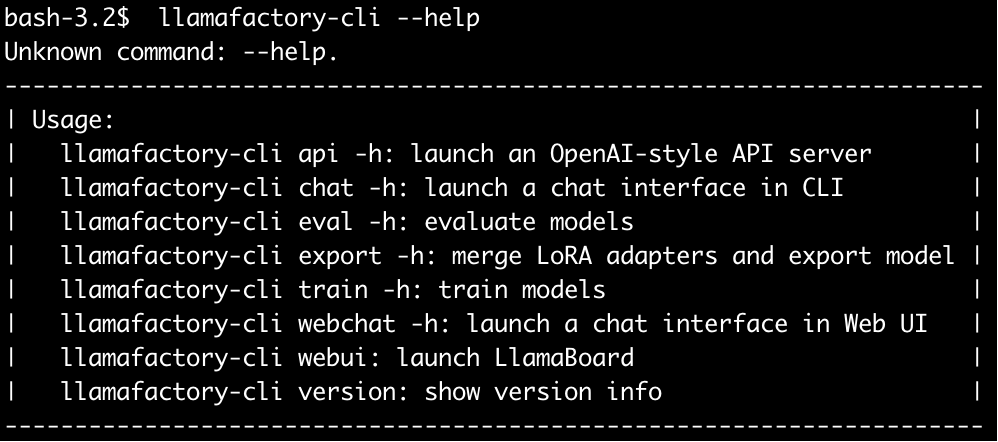
命令介绍如下:
| 子命令 | 用途说明 |
|---|---|
api |
启动一个类似 OpenAI 接口规范的 API 服务端,可用于与模型对接调用。 |
chat |
启动一个 命令行交互式聊天界面(CLI 模式)。 |
eval |
执行模型的评估任务(如准确率、推理能力评测)。 |
export |
导出模型,用于将 LoRA adapter 和 base model 合并成一个完整模型。 |
train |
启动模型训练(支持 SFT、LoRA 等方式)。 |
webchat |
启动一个基于浏览器的 Web 聊天界面(如 Gradio/Streamlit)。 |
webui |
启动 LLaMA-Factory 的 LlamaBoard 可视化界面,查看训练日志、对比等。 |
version |
显示 llamafactory-cli 的当前版本号。 |
这里使用LLaMA Board 进行可视化微调,执行如下命令:
llamafactory-cli webui
启动成功后,命令行打印如下:
启动成功之后界面如下: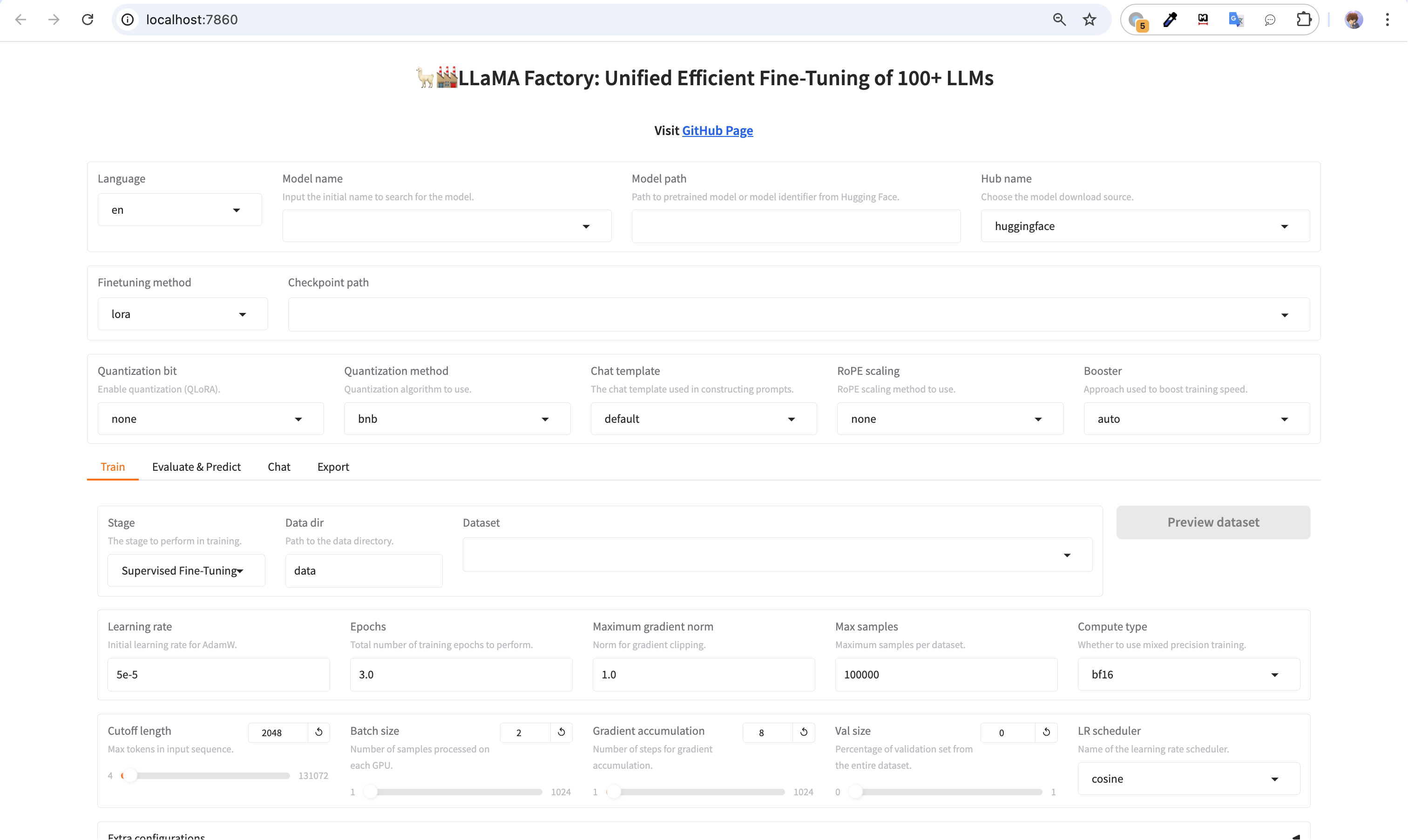
4. 加载模型(Load&Chat)
LLaMA-Factory主要是用来微调大模型的,所以在微调操作前,需要先准备大模型。在web界面,可以先下拉选择模型,这里选择:Qwen-1_8B-Chat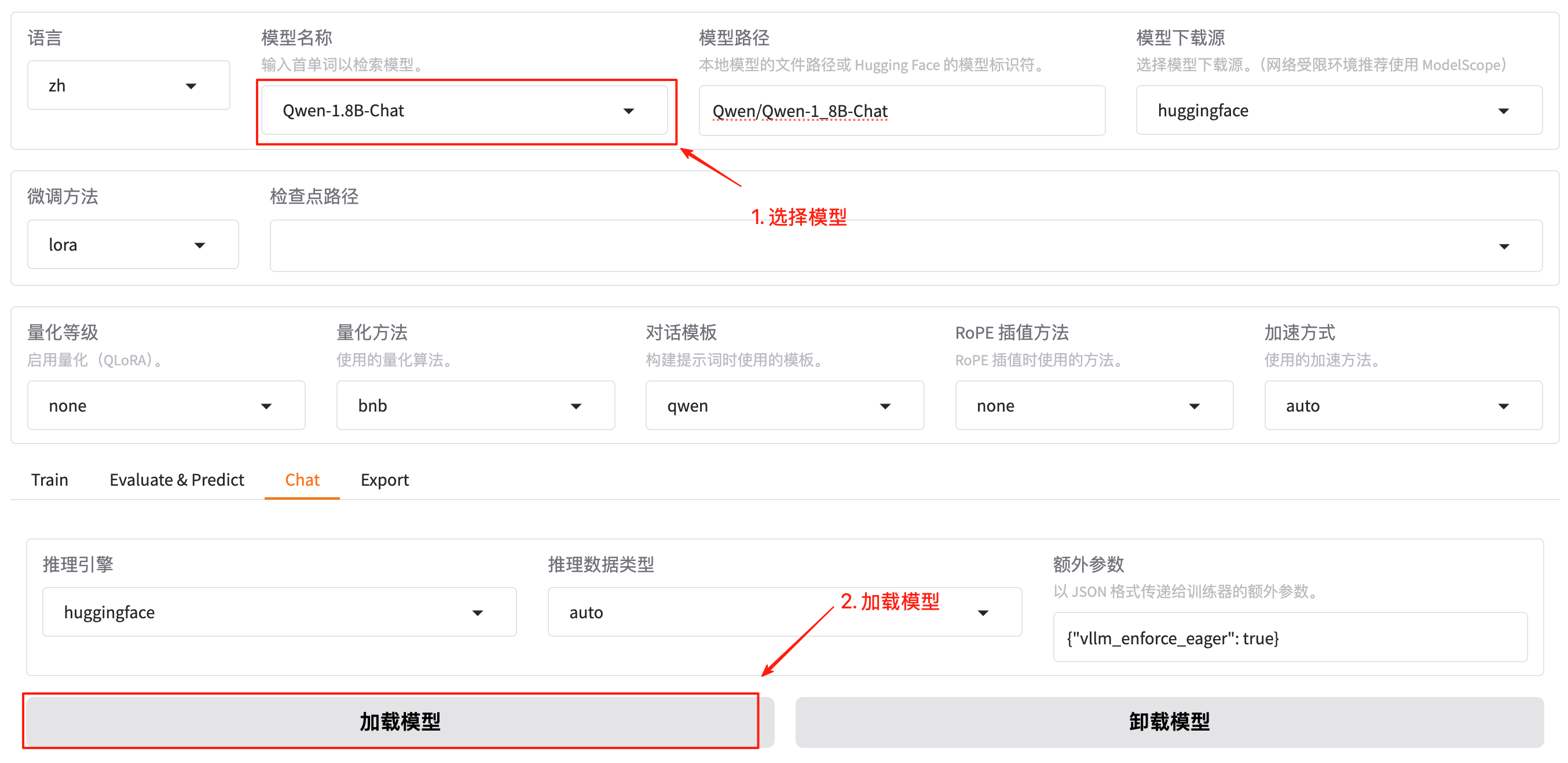
点击加载模型之后,在控制台可以看到模型下载中: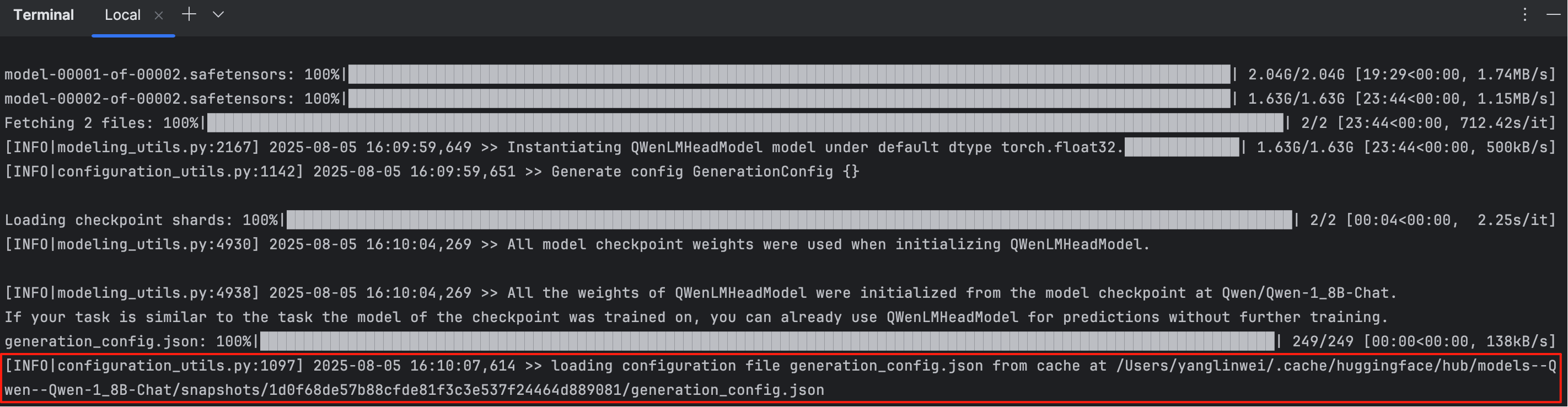
也可以看到模型存储在 /Users/用户名/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/目录下。
加载完模型,可以进行一个简单的一个对话,如下图: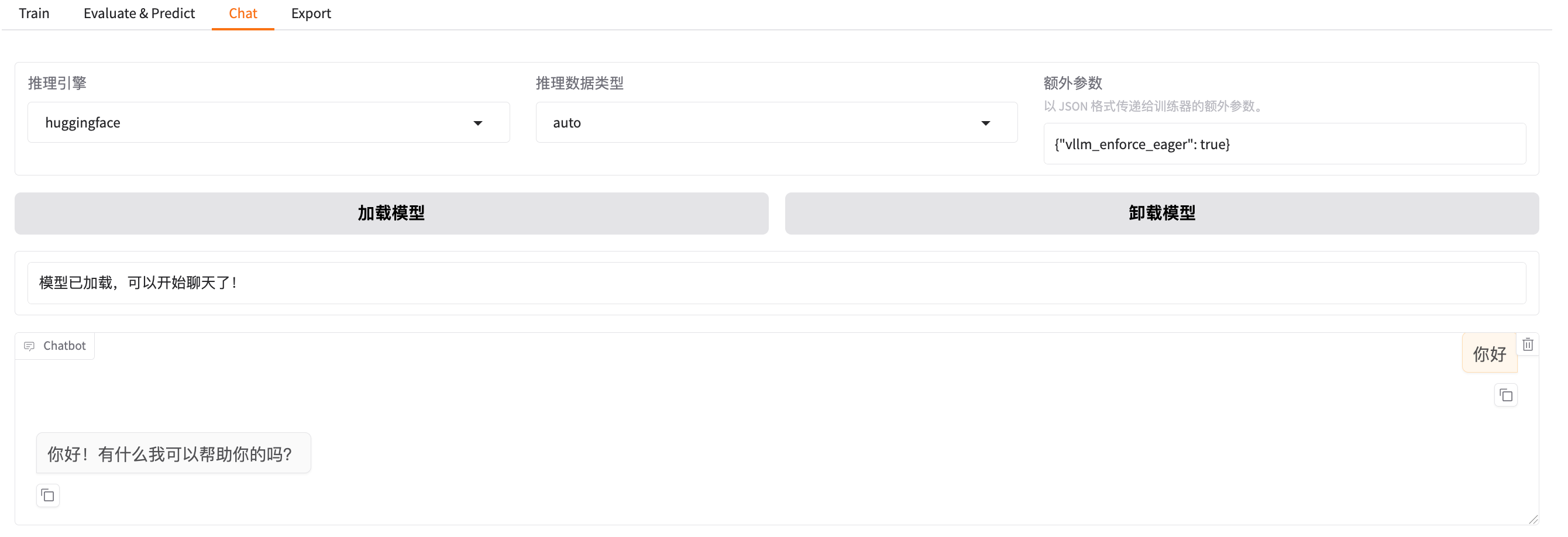
5. 微调模型(Train)
5.1 准备数据集
注意:使用自定义数据集时,请更新 data/dataset_info.json 文件。
在前面,已经可以加载一个模型,并进行简单的对话了,那么如何对该模型进行微调呢?可以切换至 【Train】 的模块,然后选择对应的“数据集”,例如这里选择的是内的 “identity” 和 “alpaca_zh_demo” 数据集:

点击 “预览数据集” 也可以进行预览: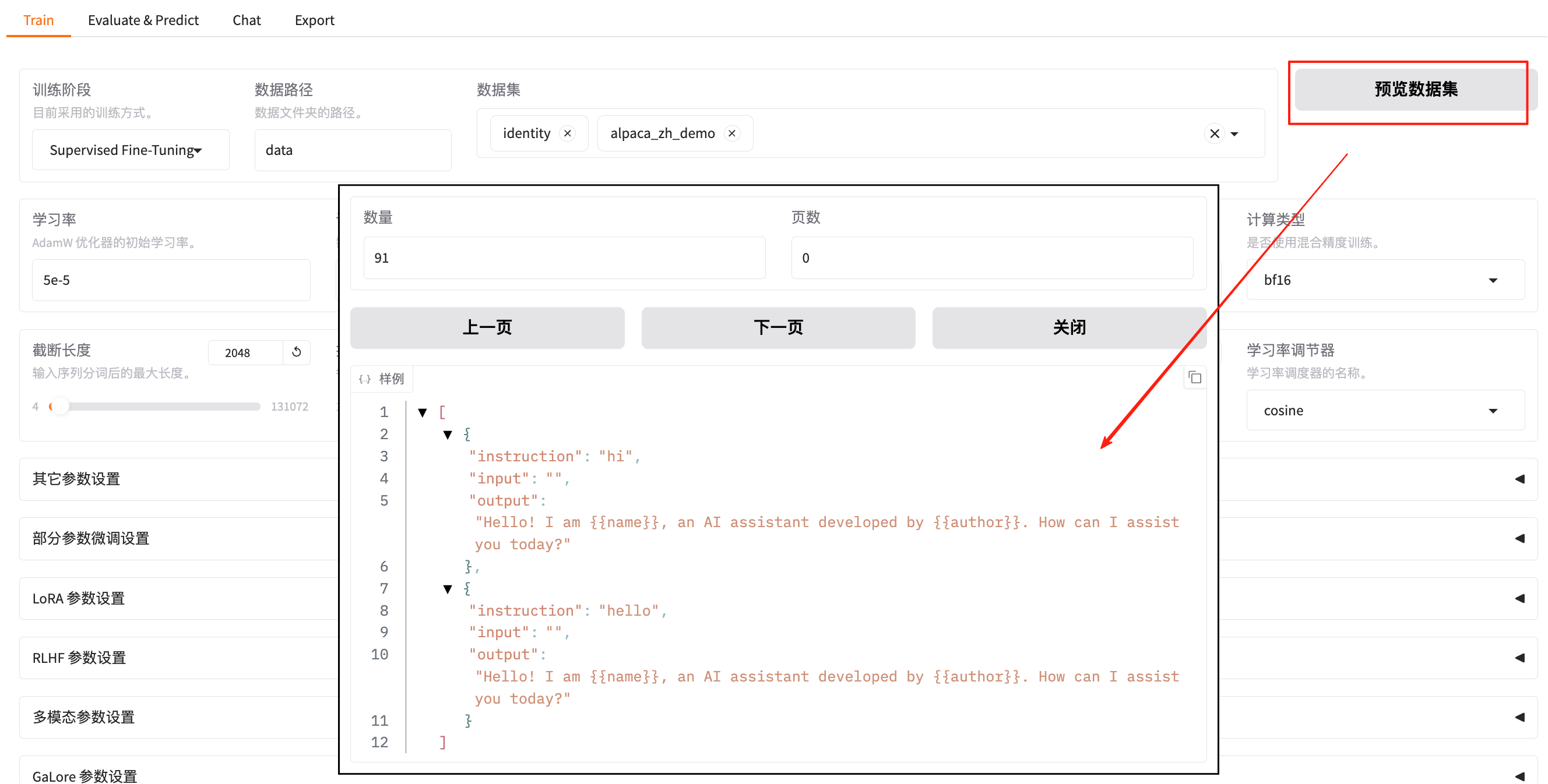
LLaMA-Factory支持 alpaca 格式和 sharegpt 格式的数据集,允许的文件类型包括 json、jsonl、csv、parquet 和 arrow。数据集的 定义 主要在LLaMA-Factory/data/dataset_info.json 文件,大致如下:
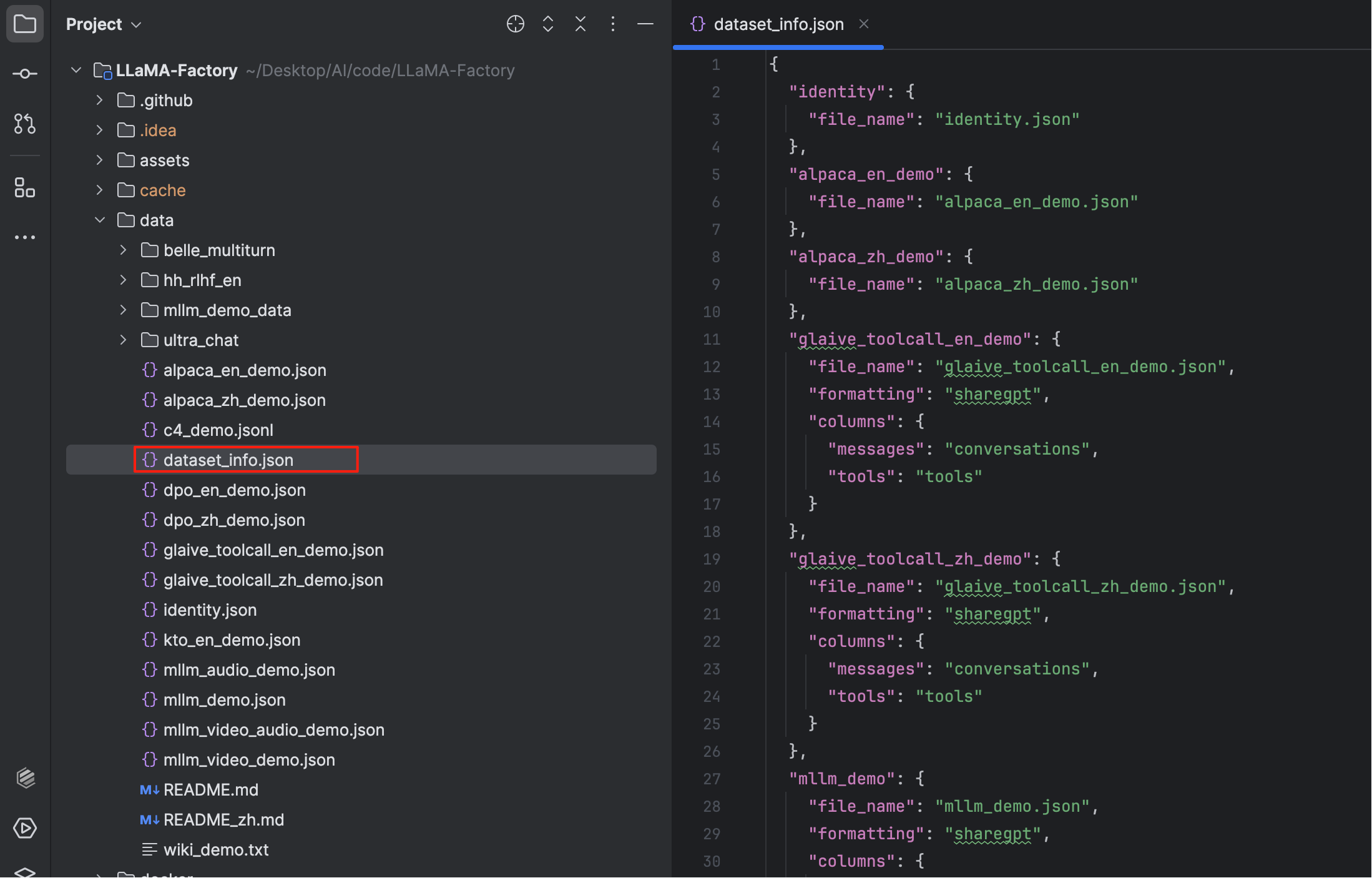
也可以通过如下几个开源项目构建用于微调的合成数据:
- Easy Dataset:https://github.com/ConardLi/easy-dataset
- DataFlow:https://github.com/OpenDCAI/DataFlow
- GraphGen :https://github.com/open-sciencelab/GraphGen
如果想进一步了解,同学们可以直接参阅官网:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
5.2 配置训练参数
可以配置的训练参数有很多,如下图: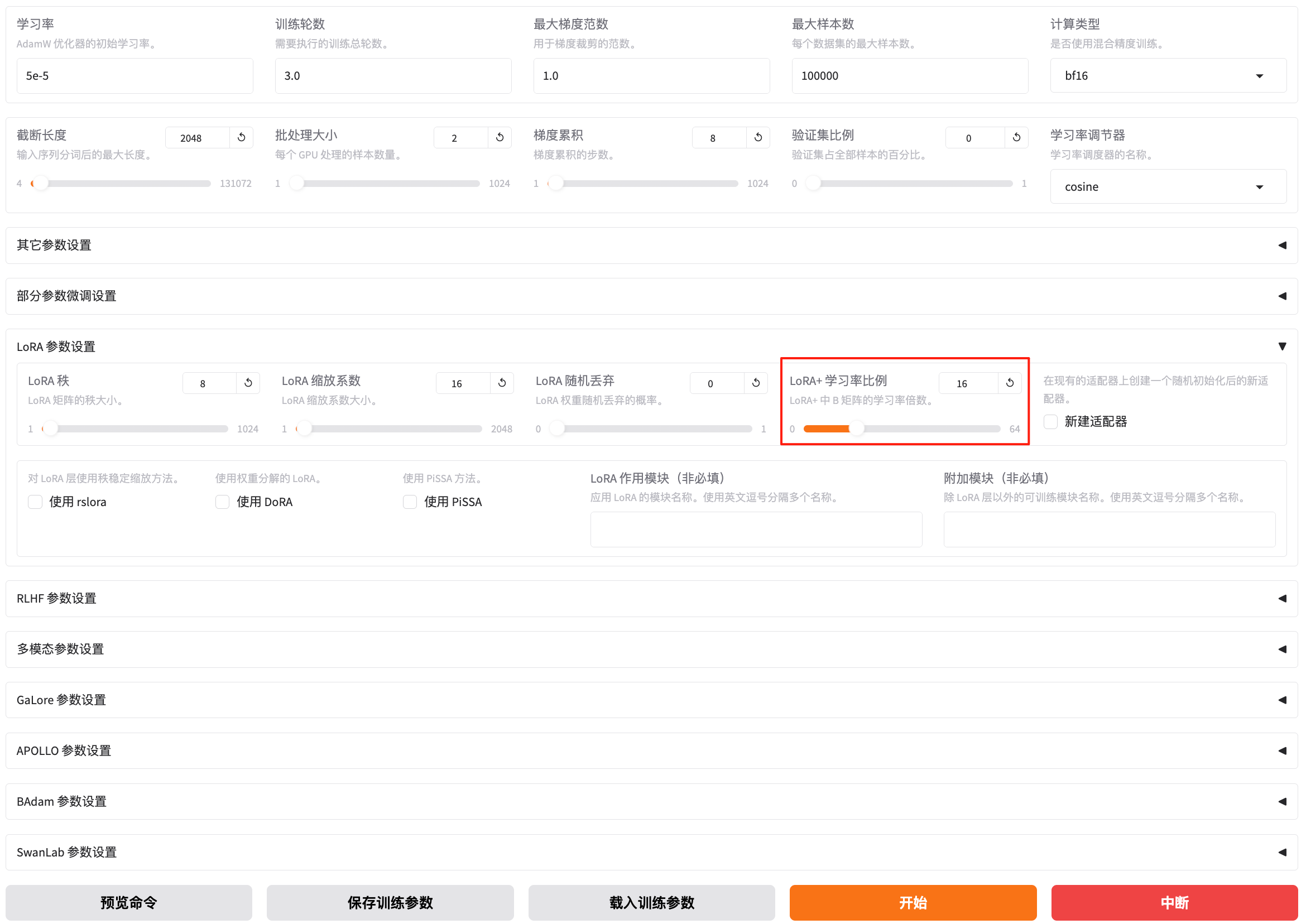
根据官网的教程,我们设置LoRa参数设置里面的LoRA+学习率比例,配置为16。后面的文章也会详细描述LLaMA-Factory的参数说明。
5.3 开始训练
开始训练前,可以预览训练的命令: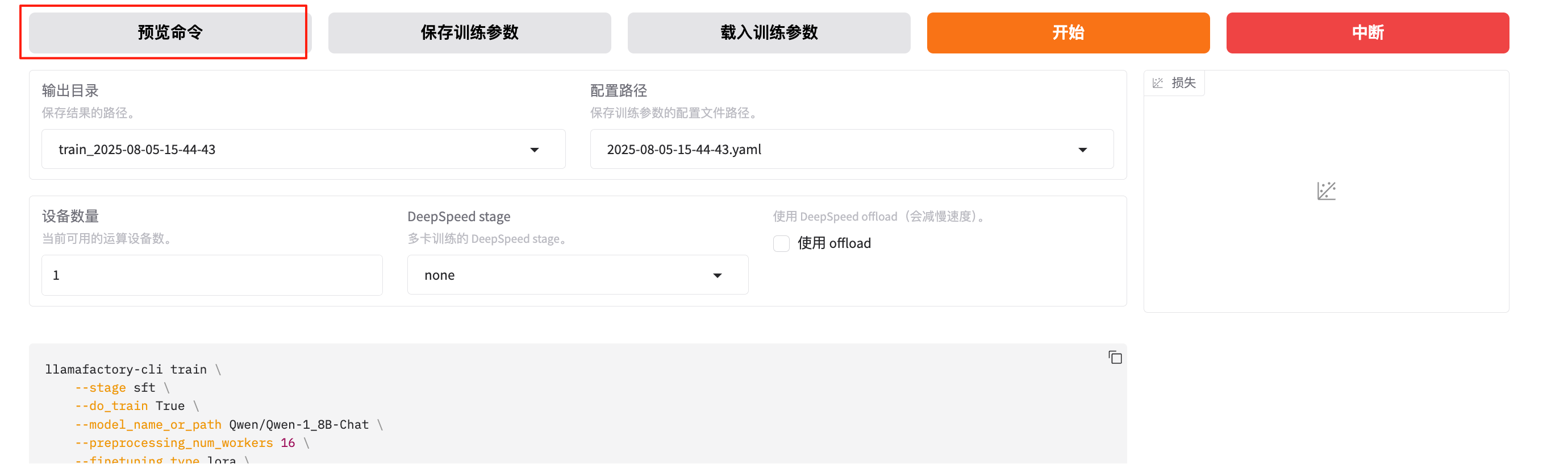
内容如下,里面加上了注释:
llamafactory-cli train \ # 启动 LLaMA-Factory CLI 工具执行训练流程
--stage sft \ # 设置训练阶段为 SFT(Supervised Fine-tuning,监督式微调)
--do_train True \ # 启用训练(表示这次任务是训练而不是评估/预测)
--model_name_or_path Qwen/Qwen-1_8B-Chat \ # 使用 HuggingFace 上的 Qwen 1.8B Chat 模型作为底座
--preprocessing_num_workers 16 \ # 数据预处理时使用 16 个并行 worker,提升加载速度
--finetuning_type lora \ # 使用 LoRA 微调方法,仅微调小量参数,节省资源
--template qwen \ # 使用 Qwen 专属的 Prompt 模板,保证输入输出结构符合模型要求
--flash_attn auto \ # 自动检测是否启用 flash attention,加速训练过程(特别在支持的 GPU 上)
--dataset_dir data \ # 数据集根目录,训练数据从此目录中读取
--dataset identity,alpaca_zh_demo \ # 指定要使用的训练数据集(多个用逗号分隔)
--cutoff_len 2048 \ # 每个样本的最大 token 长度,超过部分将被截断
--learning_rate 5e-05 \ # 设置学习率为 5e-5,是 LoRA 微调中较常用的学习率
--num_train_epochs 1.0 \ # 训练一个 epoch,可根据数据量和需求调整
--max_samples 100000 \ # 最多训练的样本数(限制总训练数据量,防止超载)
--per_device_train_batch_size 2 \ # 每张 GPU 上的 batch size 是 2,结合累积步数控制总 batch
--gradient_accumulation_steps 8 \ # 梯度累积 8 次再进行一次优化,相当于总 batch 为 2 x 8
--lr_scheduler_type cosine \ # 使用 cosine 退火策略调节学习率
--max_grad_norm 1.0 \ # 最大梯度范数(防止梯度爆炸),通常设置为 1.0
--logging_steps 5 \ # 每训练 5 步输出一次日志(包括 loss 等信息)
--save_steps 100 \ # 每训练 100 步保存一次模型 checkpoint
--warmup_steps 0 \ # 学习率 warmup 步数,0 表示不使用 warmup
--packing False \ # 不启用样本 packing,避免多个短文本拼接训练(适用于对话类模型)
--enable_thinking True \ # 启用“思考”模式,在训练过程中引导模型生成中间思考步骤(适配特定模板)
--report_to none \ # 不上报训练信息到 wandb 或 tensorboard 等平台
--output_dir saves/Qwen-1.8B-Chat/lora/train_2025-08-05-17-27-54 \ # 模型训练结果和日志的保存路径
--bf16 True \ # 启用 bfloat16 精度训练(若硬件支持,推荐使用以节省显存)
--plot_loss True \ # 在训练过程中记录 loss 并绘制图像(保存在 output_dir 中)
--trust_remote_code True \ # 允许加载 HuggingFace 上模型时执行远程代码(用于模型自定义结构)
--ddp_timeout 180000000 \ # 分布式训练的超时时间设置为很大,防止某些节点超时
--include_num_input_tokens_seen True \ # 输出日志中包含已处理的 token 数,有助于监控训练进度
--optim adamw_torch \ # 使用 AdamW 优化器(PyTorch 原生实现)
--lora_rank 8 \ # LoRA 的秩设置为 8(控制参数规模,越大效果越好但显存消耗越多)
--lora_alpha 16 \ # LoRA 的缩放因子(用于调节更新强度)
--lora_dropout 0 \ # LoRA 层的 dropout 概率,0 表示不进行随机丢弃
--lora_target all # 对所有可微调的模块应用 LoRA(如 attention, mlp 层等)
当然可以直接复制到终端进行训练,也可以点击开始按钮进行训练: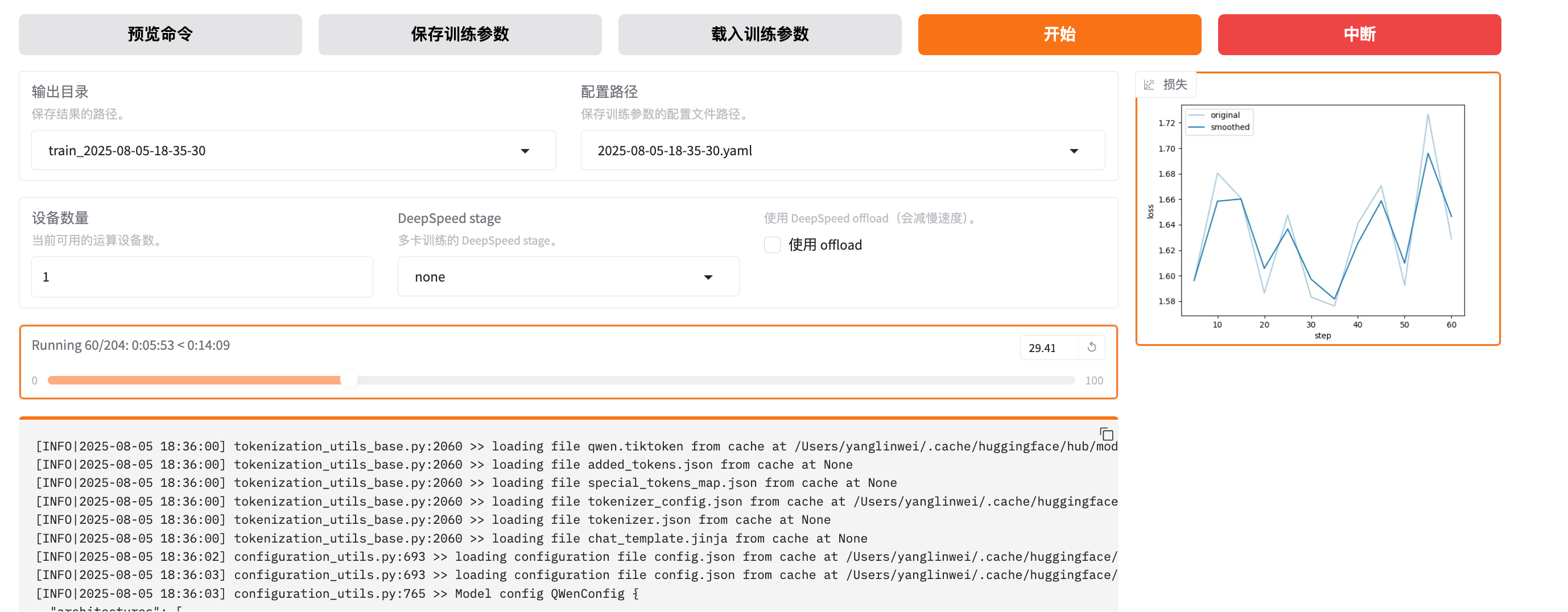
训练的过程中,可以看到了清晰的训练进度以及日志,当然控制台也有日志: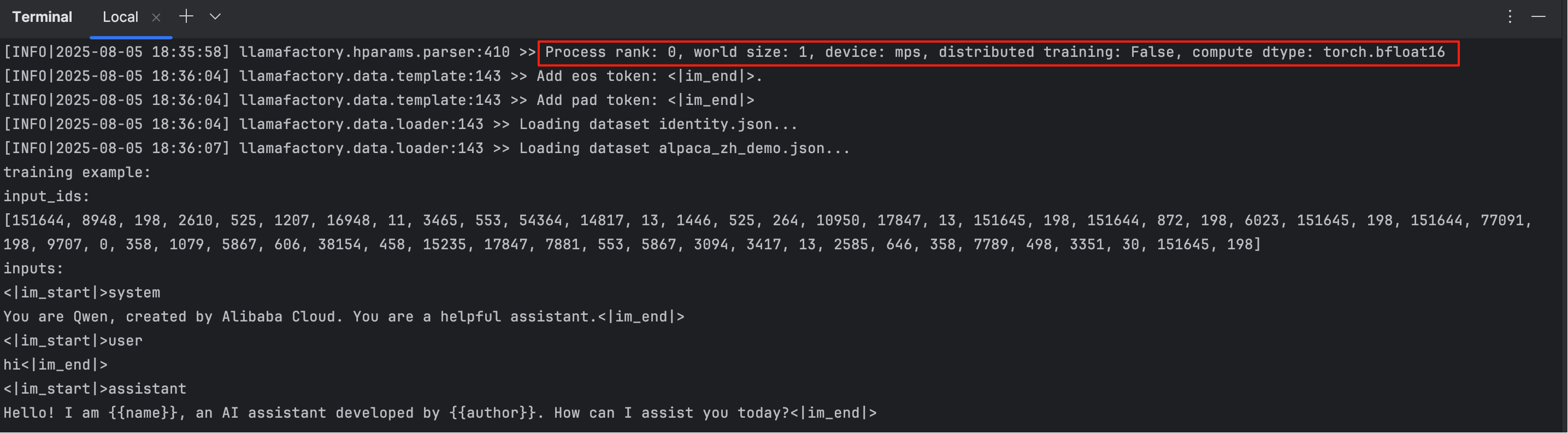
从控制台可以看到日志:
llamafactory.hparams.parser:410 >> Process rank: 0, world size: 1, device: mps, distributed training: False, compute dtype: torch.bfloat16
该日志表示当前在 macOS 上使用 Apple 芯片(MPS 后端),以单进程、单设备方式进行推理或训练,使用的是 bfloat16 精度,没有启用分布式或多卡训练。
5.4 验证
没有训练前,如果问 “你是谁” ,回复内容为“我是阿里云开发的超大规模语言模型,我叫通义千问。”,如下图: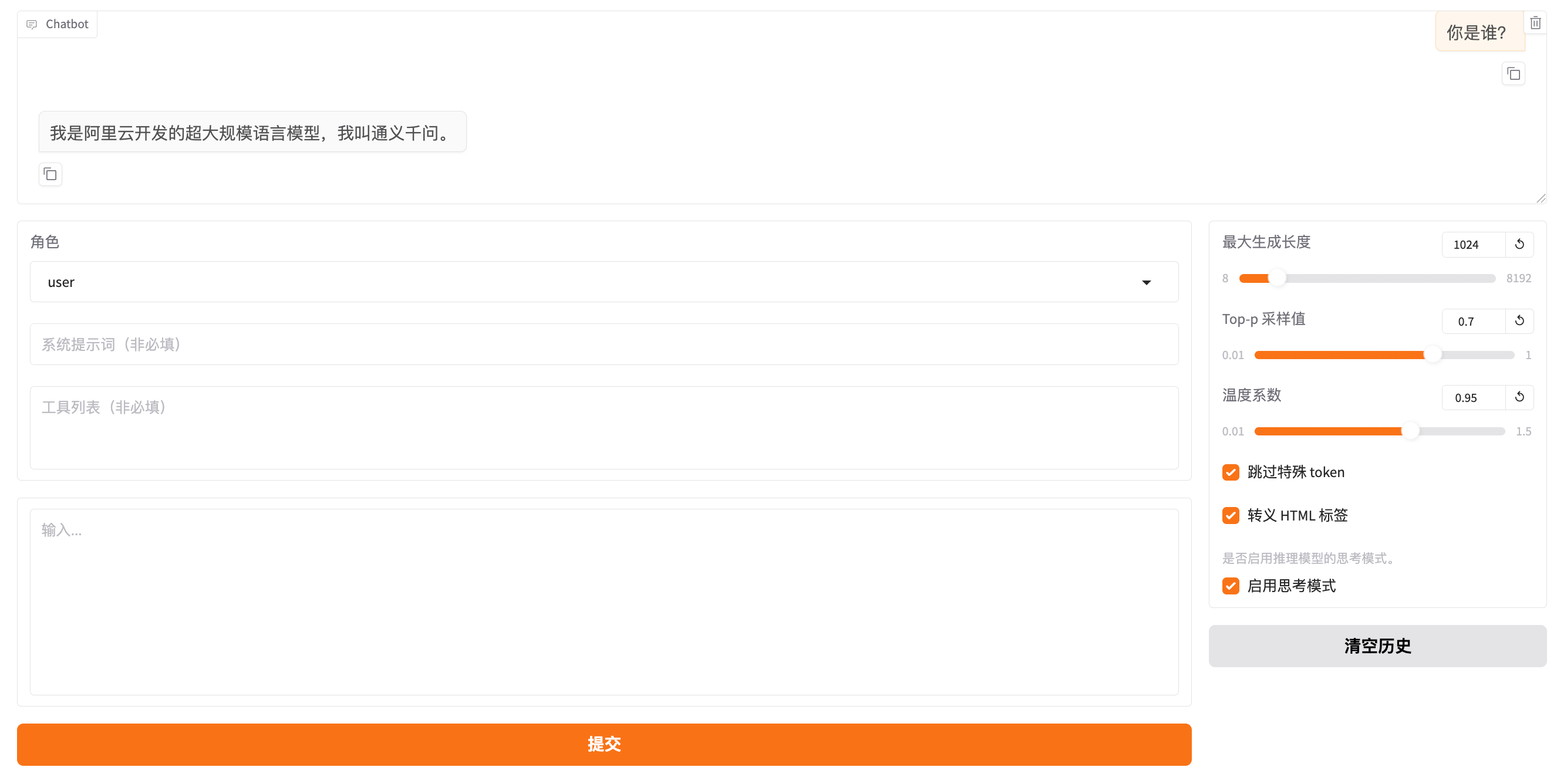
如果要看训练后的回复,可以选择微调后的模型,即选择“检查点”: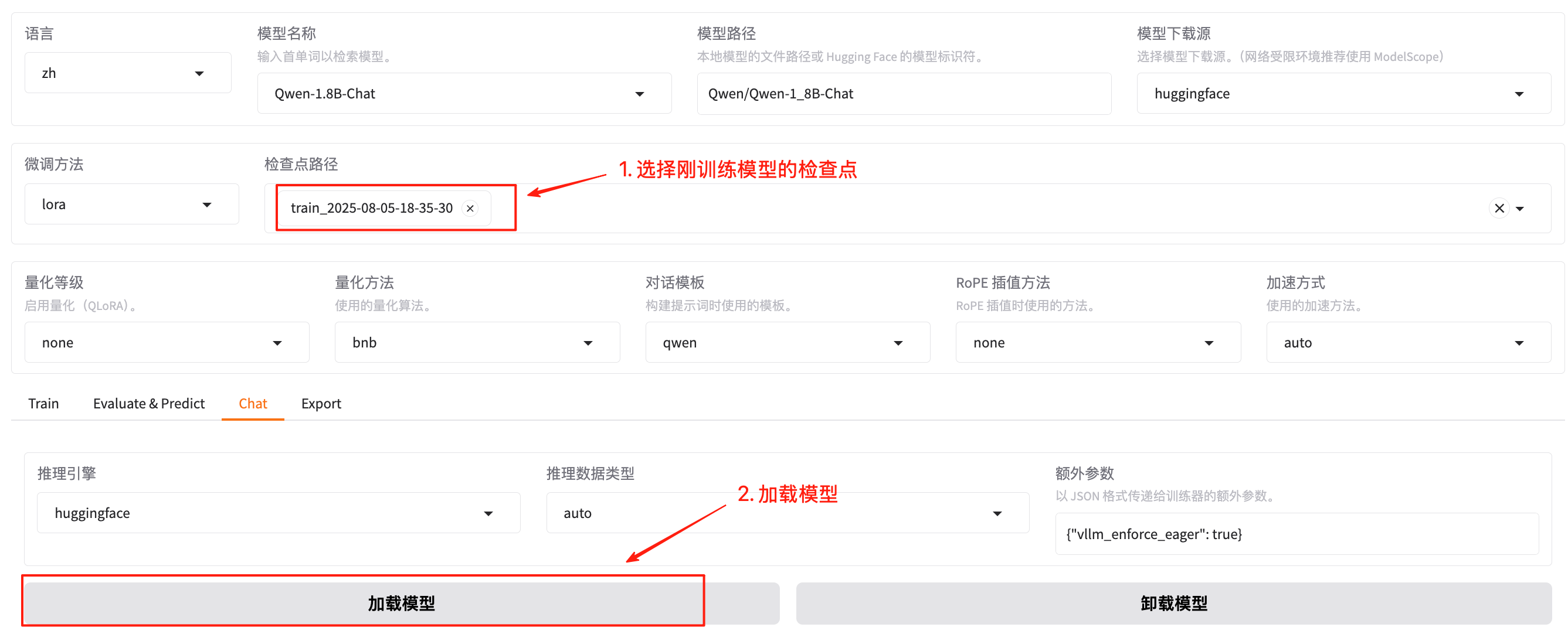
加载之后,可以进行对话(注意:加载其它模型前,必须先卸载模型,只能加载一个),继续提问“你是谁” ,回复内容为“您好,我是 {{name}},由 {{author}} 开发,旨在为用户提供智能化的回答和帮助。”,可以看到回复的内容是按照选择的数据集进行精确的回复: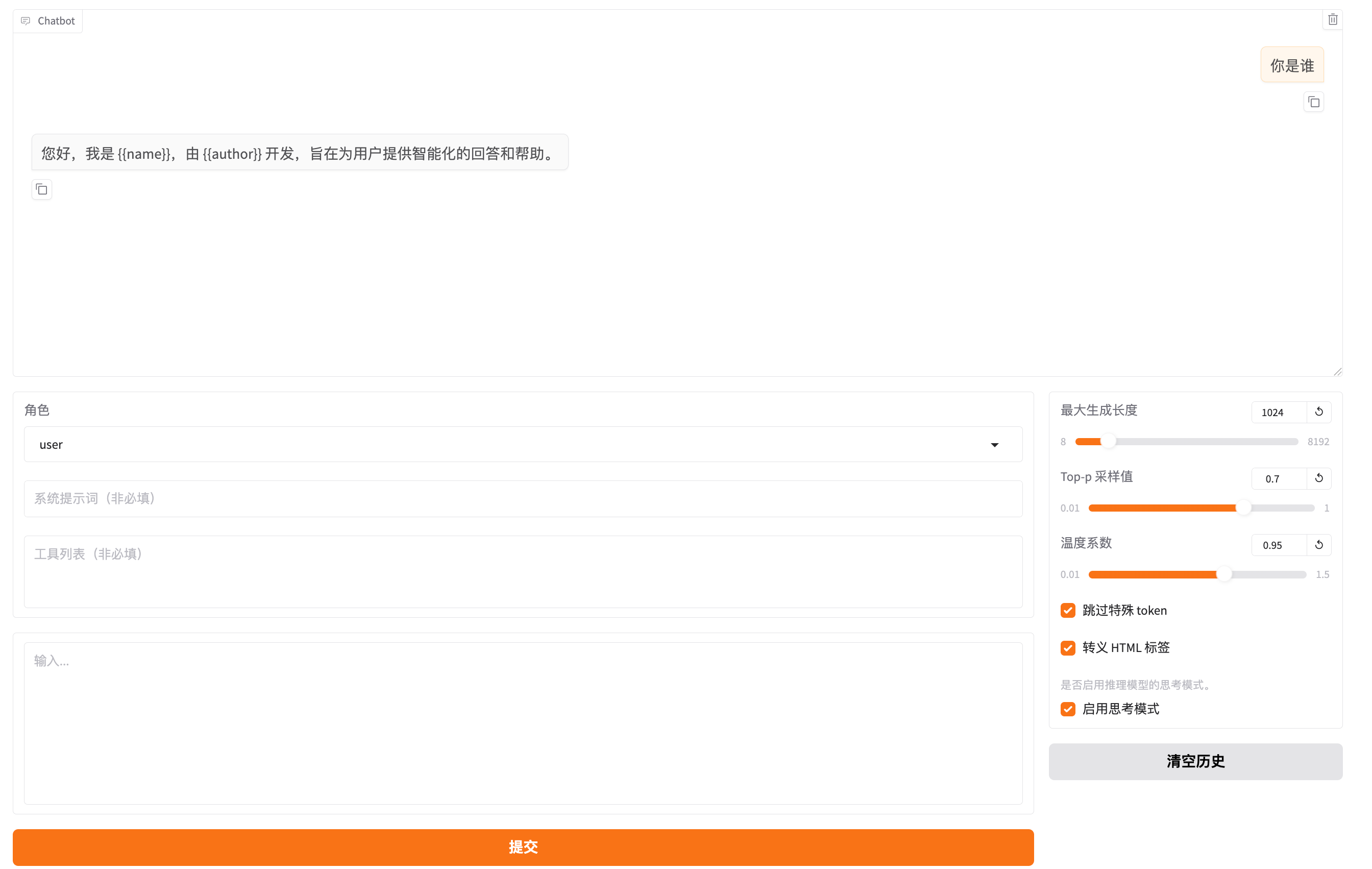
对应的数据集是 “identity.json” 里面的内容: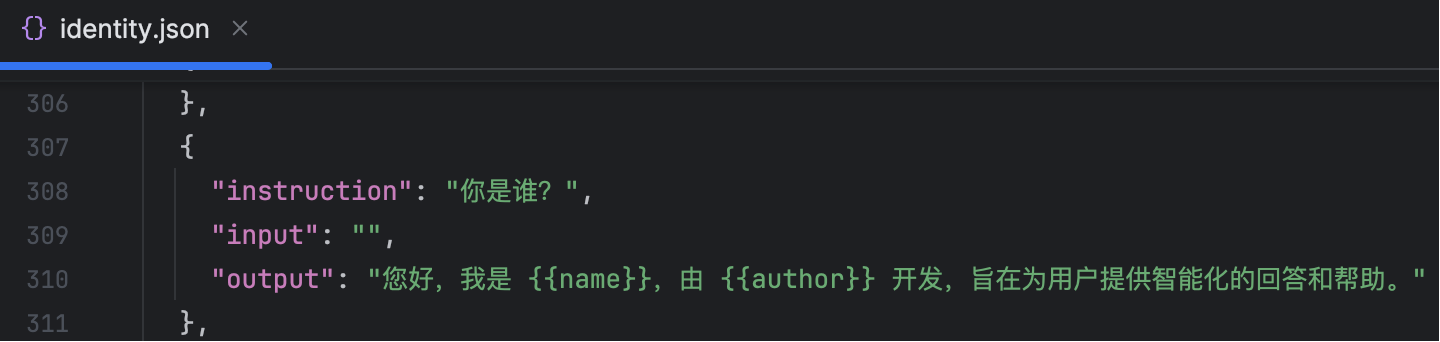
6. 验证评估模型(Evaluate & Predict)
Evaluate & Predict 是用于评估模型效果和进行推理预测的重要模块,主要适用于训练完成后的模型验证与应用场景测试。
| 功能 | 说明 |
|---|---|
| Evaluate | 对已训练好的模型进行评估,输出模型在验证集或测试集上的指标(如准确率、困惑度) |
| Predict | 使用训练好的模型对输入数据进行推理预测,生成输出结果(如文本、分类标签等) |
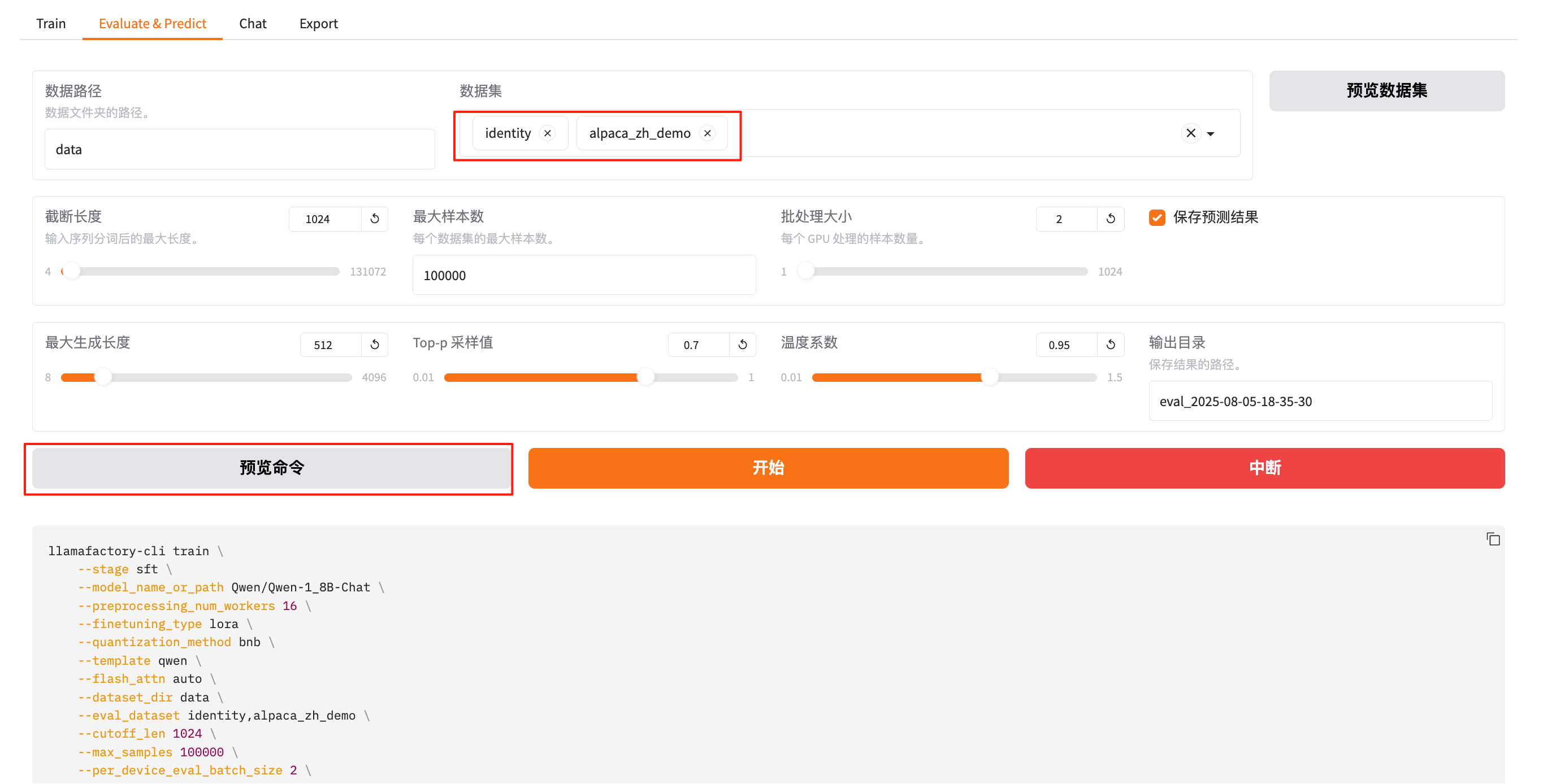
点击预览命令,可以看到内容如下,加上了注释如下:
llamafactory-cli train \ # 使用 llama-factory CLI 工具执行命令(虽然是 train,但通过 --do_predict 实际是在做预测)
--stage sft \ # 任务阶段为 SFT(监督式微调),用于加载相应配置
--model_name_or_path Qwen/Qwen-1_8B-Chat \ # 基础模型为 Qwen 1.8B Chat(从 HuggingFace 加载)
--preprocessing_num_workers 16 \ # 数据预处理时启用 16 个并行 worker,加快数据加载
--finetuning_type lora \ # 使用 LoRA 方式进行微调(或加载已训练的 LoRA 权重)
--quantization_method bnb \ # 使用 BitsAndBytes (bnb) 量化方法,节省显存
--template qwen \ # 使用 Qwen 专属的 prompt 模板,保证输入格式正确
--flash_attn auto \ # 自动判断是否启用 Flash Attention(更快的注意力机制)
--dataset_dir data \ # 数据集所在目录,评估数据集从这里加载
--eval_dataset identity,alpaca_zh_demo \ # 指定两个评估用的数据集(identity 和 alpaca_zh_demo)
--cutoff_len 1024 \ # 每条输入样本最大长度为 1024 个 token,超出将被截断
--max_samples 100000 \ # 最多评估样本数为 100000(防止数据集过大导致 OOM)
--per_device_eval_batch_size 2 \ # 每个设备的评估 batch size 为 2,显存小可调小
--predict_with_generate True \ # 启用生成模式,模型将自动生成输出(而不仅仅评估)
--report_to none \ # 不上报训练日志到任何平台(如 WandB、TensorBoard 等)
--max_new_tokens 512 \ # 模型预测时最多生成 512 个 token 的输出
--top_p 0.7 \ # 使用 nucleus sampling 策略,保留累计概率前 70% 的词进行采样
--temperature 0.95 \ # 控制生成的多样性,越高越随机,越低越确定
--output_dir saves/Qwen-1.8B-Chat/lora/eval_2025-08-05-18-35-30 \ # 推理输出结果保存目录
--trust_remote_code True \ # 允许加载 HuggingFace 上模型时运行远程自定义代码(必要选项)
--ddp_timeout 180000000 \ # 分布式超时时间设置为极大,避免推理过程超时失败
--do_predict True \ # 执行“预测”操作(不是训练),读取 LoRA 权重并推理生成结果
--adapter_name_or_path saves/Qwen-1.8B-Chat/lora/train_2025-08-05-18-35-30 # 加载已训练好的 LoRA Adapter 权重,用于生成输出
点击开始: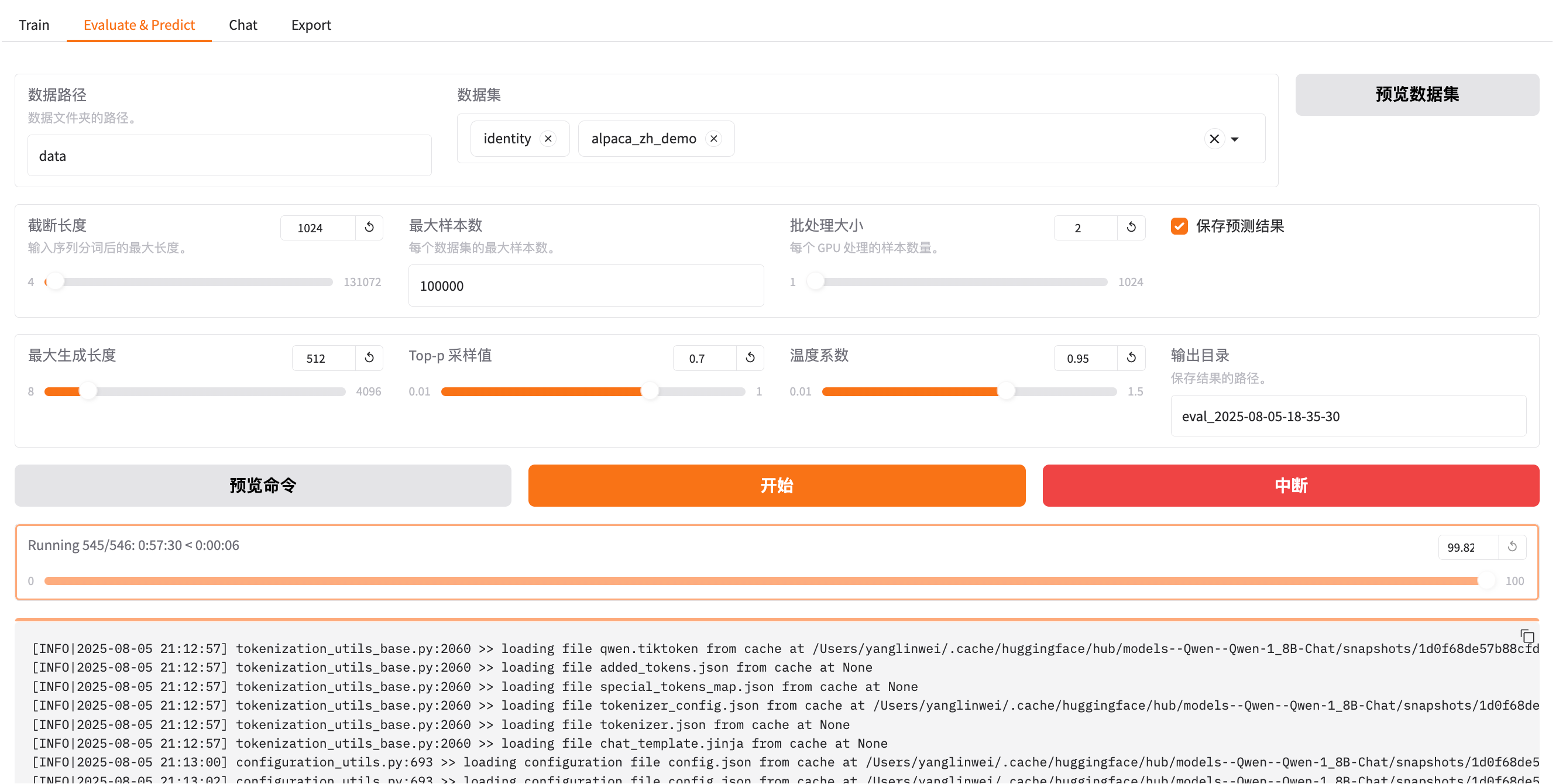
训练完毕之后会提示如下内容: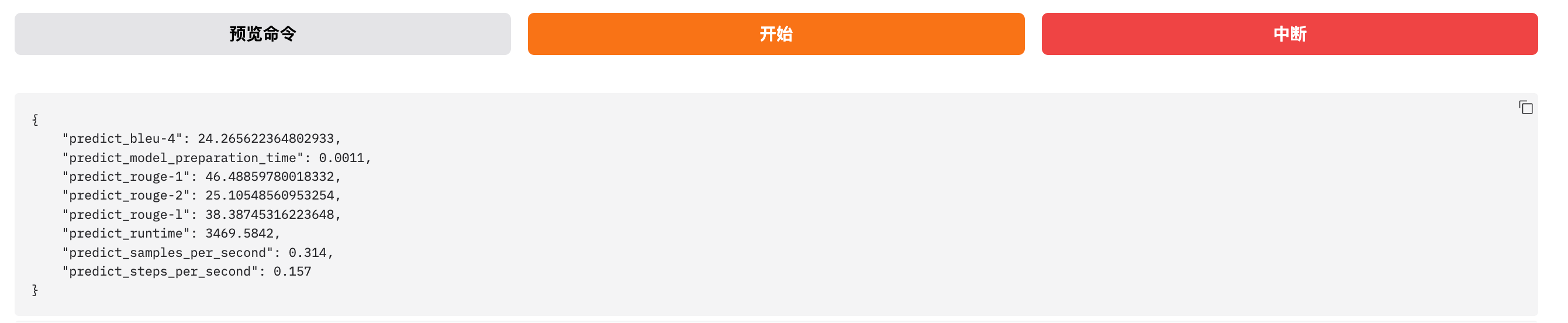
具体的过程结果日志会在 LLaMA-Factory/saves/Qwen-1.8B-Chat/lora/eval_xxx 文件夹记录,详情如下: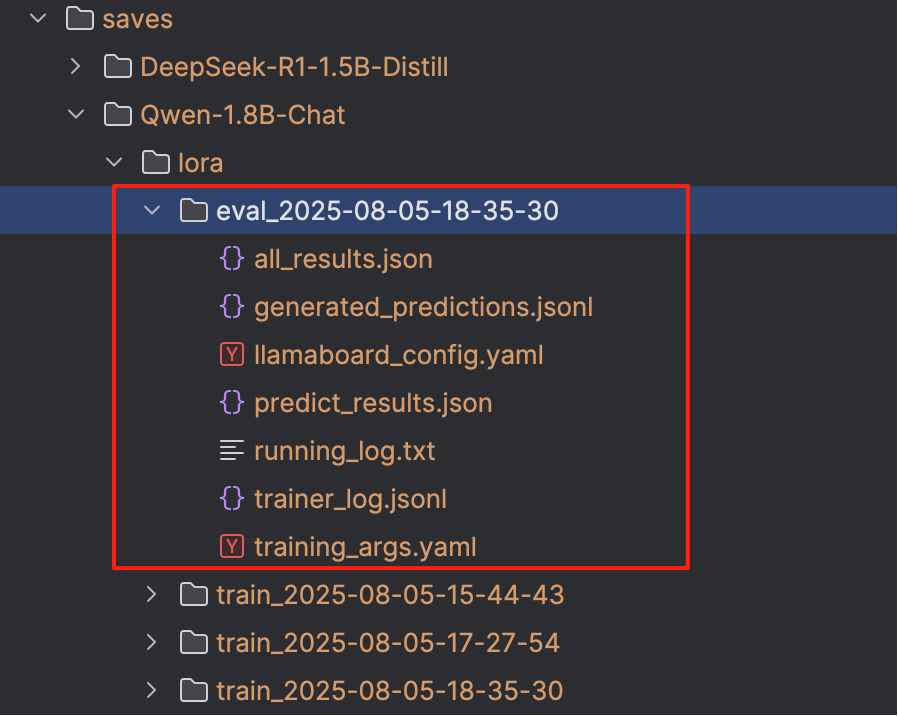
指标详解:
| 键名 | 含义 | 说明 |
|---|---|---|
predict_bleu-4 |
BLEU-4 分数:24.27 | 常用于机器翻译/文本生成评估,表示预测结果与参考答案在 n-gram 上的重合程度。24.26 属于中等偏上的水平。 |
predict_rouge-1 |
ROUGE-1 分数:46.49 | 测量预测与参考答案之间 unigram(单个词) 的重合率,适合评估总结、对话等生成任务。 |
predict_rouge-2 |
ROUGE-2 分数:25.11 | 测量 bigram(2个词组合) 的重合率,越高表示生成更符合参考内容。 |
predict_rouge-l |
ROUGE-L 分数:38.39 | 衡量预测与参考答案之间的最长公共子序列(LCS),体现句子结构与顺序的匹配程度。 |
性能相关指标:
| 键名 | 含义 | 说明 |
|---|---|---|
predict_model_preparation_time |
模型加载准备耗时(秒):0.0011 | 几乎忽略不计,说明模型已提前加载好或在内存中。 |
predict_runtime |
预测耗时:3469.58 秒 | 整体预测任务总耗时(约 57 分钟),与评估的数据量和硬件环境有关。 |
predict_samples_per_second |
平均每秒处理样本数:0.314 | 说明每秒大约能预测 0.314 条样本,较慢,可能是模型大/显存限制/生成长度较长导致。 |
predict_steps_per_second |
每秒执行 step 数:0.157 | 每秒的 forward 推理 step 次数,一般用于性能调优参考。 |
主要生成质量指标如下:
- 生成结果与参考答案在 BLEU-4 上达到了 24.26
- ROUGE 指标表现良好,ROUGE-1 为 46.49%,ROUGE-L 为 38.39%
- 说明模型已经能够生成较有质量的文本
- 性能上处理速度较慢(每秒不到 1 条样本),但正常
7. 导出模型(Export)
最后,可以将微调好的模型导出为标准格式,以便于部署、推理或集成到其他系统中使用。输入导出的目录,然后点击“开始导出”: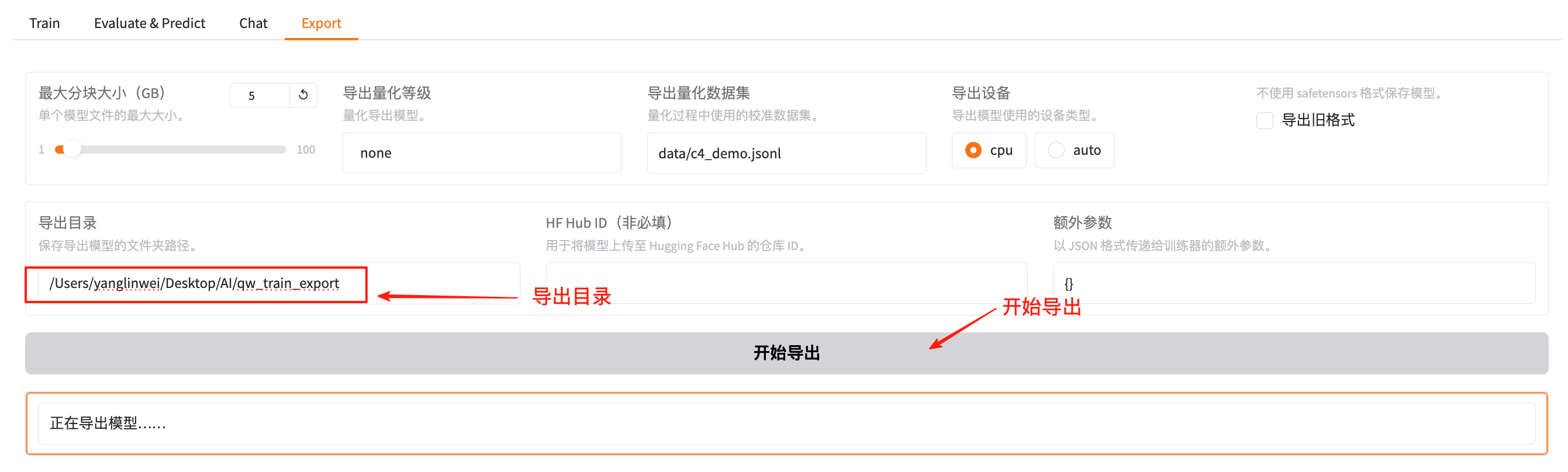
打开导出目录,可以看到如下内容:
最后这里的模型可以给其它的推理框架导入,比如使用Ollama可以通过如下命令即可导入并使用:
# 进入模型导出目录
bash-3.2$ cd 模型导出目录
# Ollama导入模型
bash-3.2$ ollama create my-qwen-model -f Modelfile
# Ollama运行模型
ollama run my-qwen-model
导入的日志如下,此处不再赘述。
8. 总结
通过本文的讲解,我们成功地在 Mac M系列芯片 环境下完成了 LLaMA-Factory 的安装、模型加载、微调训练以及评估预测的全流程操作,验证了该项目对 Apple Silicon 架构的良好兼容性。
LLaMA-Factory 提供了极其丰富的功能组件和模块选项,不仅支持主流的大模型(如 Qwen、LLaMA、ChatGLM 等),也兼容多种微调范式(全参数、LoRA、QLoRA 等)和评估方式(BLEU、ROUGE 等),并提供了直观的可视化界面(LLaMA Board),极大地提升了使用体验。
在 Mac 上运行虽然无法发挥 GPU 最大算力,但通过合理的设置和精简模型,依然能够完成从训练到部署的全流程。这对于开发者而言,意味着可以使用日常办公设备进行模型原型验证和实验探索,而不再强依赖昂贵的服务器资源。
最后: 如果你希望在本地轻松完成大模型的微调和部署,或者希望深入了解训练细节并参与优化,那么 LLaMA-Factory 是一个值得深入探索和投入的开源项目。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)