从 “猜水果” 到 AI 决策:KNN 分类模型如何让机器学会 “举一反三”?
什么是 KNN?一句话看懂核心逻辑KNN 的全称是 K-Nearest Neighbors,翻译过来就是 “K 近邻算法”。它的思路简单到让人惊讶:当要判断一个新事物的类别时,只需要看看它周围最近的 K 个 “邻居” 是什么类别,然后跟着多数派 “站队” 就行。举个例子:假设你不知道 “猕猴桃” 是什么水果,但你发现它周围最近的 3 个水果(K=3)里,有 2 个是 “浆果”、1 个是 “核果”,
目录
一、情景导入
假设你第一次走进一家咖啡馆,面对菜单上陌生的咖啡名字不知所措。这时,你可以用KNN的思路来决策:先观察周围口味相似的顾客都点了什么——如果离你最近的3位顾客中,有2位点了「燕麦拿铁」且表情享受,而1位点了「美式」但皱着眉头,系统就会推荐你选择「燕麦拿铁」。这就是KNN的核心:让相似的数据替你做决定。无论是咖啡口味、电影推荐还是疾病诊断,机器都在用这种「物以类聚」的方式学习人类的判断逻辑。
二、模型介绍
什么是 KNN?一句话看懂核心逻辑
KNN 的全称是 K-Nearest Neighbors,翻译过来就是 “K 近邻算法”。它的思路简单到让人惊讶:当要判断一个新事物的类别时,只需要看看它周围最近的 K 个 “邻居” 是什么类别,然后跟着多数派 “站队” 就行。
举个例子:假设你不知道 “猕猴桃” 是什么水果,但你发现它周围最近的 3 个水果(K=3)里,有 2 个是 “浆果”、1 个是 “核果”,那么 KNN 就会把猕猴桃归为 “浆果”。这种 “少数服从多数” 的朴素逻辑,正是 KNN 的魅力所在 —— 它不需要复杂的公式推导,却能解决很多实际问题。
三、模型原理
要让 KNN 顺利工作,有三个关键要素缺一不可:
1. 距离度量:如何定义 “远近”?
在现实世界中,我们用厘米、公里衡量物理距离;在数据世界里,KNN 用 “欧氏距离”(类似两点间直线距离)、“曼哈顿距离”(类似城市中沿街道行走的距离)等指标判断数据点的相似度。距离越近,说明两个数据的 “特征” 越相似。比如判断水果时,颜色饱和度、甜度、果皮厚度等特征都会被转化为数字,用来计算距离。
2. K 值选择:邻居数量决定结果
K 值是 KNN 的 “灵魂参数”:
当 K=1 时,模型完全相信 “最近的那个邻居”,容易被异常数据干扰(比如把一个染色的苹果误判为草莓);
当 K 过大时,模型会被更多 “远亲” 影响,反而模糊了真相(比如把香蕉归为浆果,因为周围水果里浆果数量多)。
通常,我们会通过测试不同的 K 值(比如从 3 到 15),找到让模型准确率最高的那个 “黄金数字”。
3. 分类规则:多数派获胜
默认情况下,KNN 采用 “简单多数投票制”—— 哪个类别在 K 个邻居中占比最高,新数据就属于哪个类别。如果遇到平局(比如 K=4 时,两类各占 2 个),可以缩小 K 值重算,或者给距离更近的邻居赋予更高权重(“加权投票”)。
四、应用场景
别看 KNN 原理简单,它在现实中可是 “多面手”:
垃圾邮件识别:把新邮件和已知的 “垃圾邮件”“正常邮件” 比较,根据相似性判断是否拦截;
疾病诊断:通过患者的症状数据(体温、血压等),对比已知病例,辅助判断患病类型;
推荐系统:如果你的浏览习惯和 “喜欢某类商品” 的用户高度相似,平台就会给你推送同类好物。
不过,KNN 也有 “短板”:当数据量特别大时,计算所有 “邻居” 的距离会很耗时,就像在 10 万人的通讯录里找相似好友一样费劲。但这并不妨碍它成为入门者理解机器学习的 “绝佳案例”。
五、案例演示
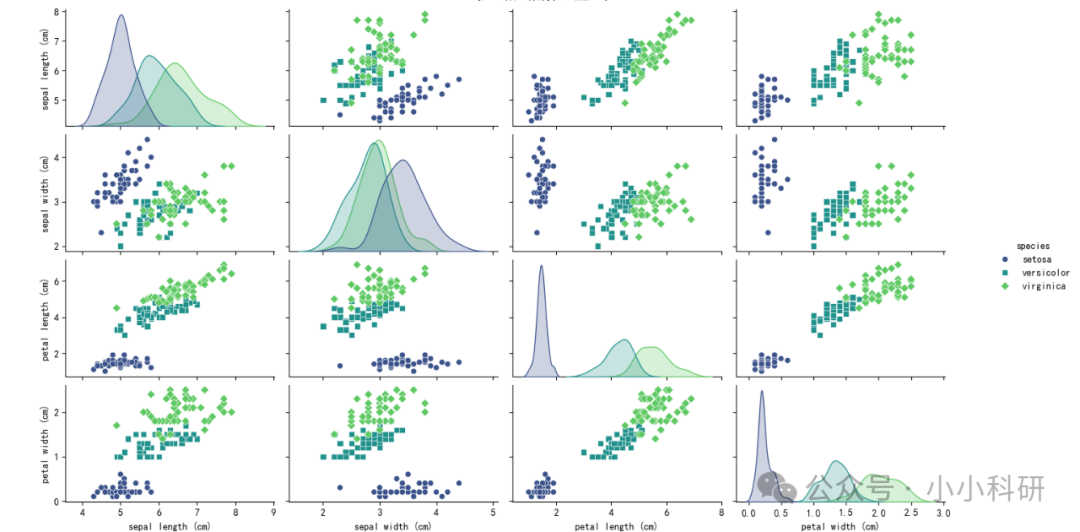
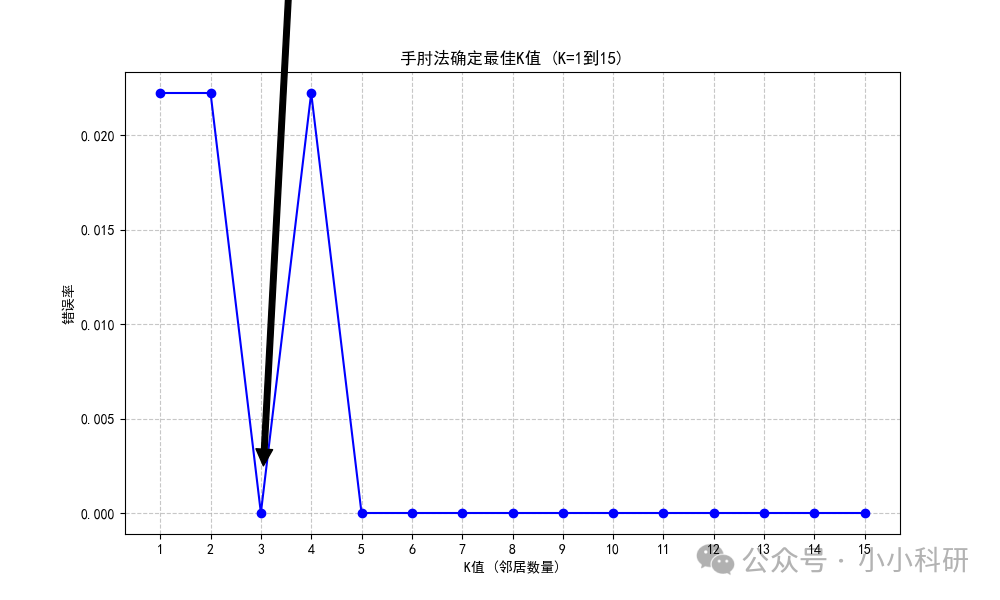
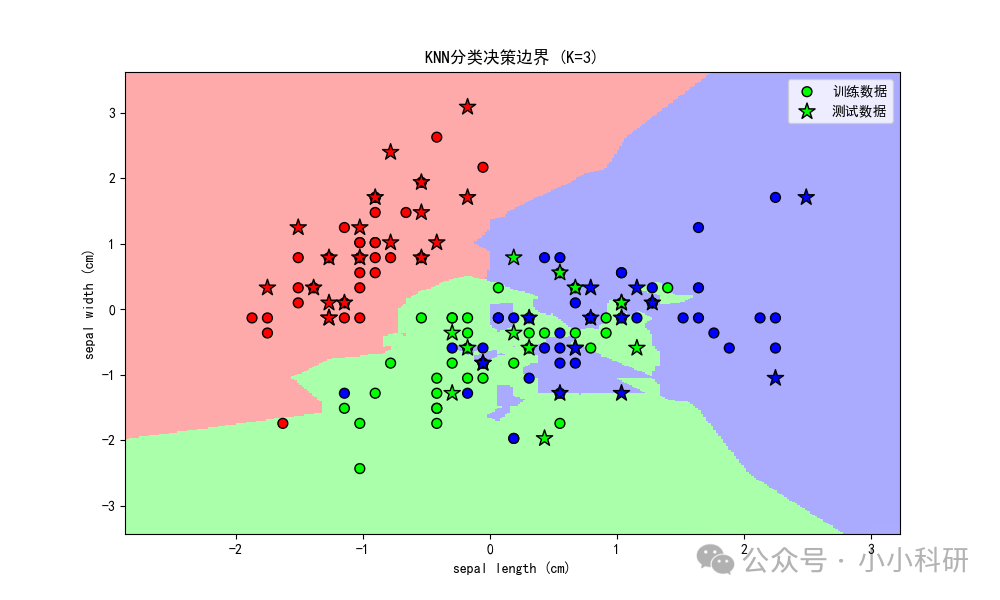
以下我们以鸢尾花分类为例:我们借助特征散点矩阵可视呈现不同品种鸢尾花在各特征上的分布及关联;利用手肘法(K 取 1 - 15),依据错误率曲线确定最佳 K 值为 3 ,此时模型泛化能力较好;再以二维特征绘制 KNN 决策边界,直观展示分类逻辑,少量测试点跨边界属正常误差,整体说明鸢尾花特征分布利于 KNN 分类。
六、总结
KNN 分类模型用最贴近人类直觉的方式告诉我们:机器学习不一定需要复杂的公式,有时候,学会 “看邻居、随大流”,就能解决大问题。下次再遇到 AI 做决策时,不妨想想 —— 它是不是也在偷偷 “观察邻居” 呢?
关注【小小科研】公众号,了解更多模型哦,感谢支持!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)