【多模态】天池比赛记录——CCKS25工业技术文档多模态推理问答评测
多模态大模型比赛记录
工业技术文档多模态比赛记录
0 前言
比起一年前第一次尝试使用大模型和参加比赛还是提升了不少的,这次比赛复赛时间和另一个比赛重合了,没来得及做思维链推理方式和一些数据增强的进一步尝试。
完整代码:https://github.com/DXWEIE/ccks2025_pdf_multimodal
1 赛题简介
比赛给定的训练集测试集都是一个个PDF格式的专利文档(本质上是图片格式的,无法直接转文本格式),要求根据给定文档的内容回答问题,初赛任务是做选择题,复赛任务是做问答题,只允许使用开源模型,量级不超过32b,且不允许使用除了训练集之外的QA数据微调。
初赛样例数据如下,做4选1的选择题,统计准确率,是对给定的document进行回答,提问的范围是比较明确的,大致上可以分为两类问题:(1)需要根据专利整体内容回答的问题;(2)明确问某页的某图里面的两个部件的相对位置关系
# 类别1——需要整体分析
{"question": "以下哪个选项最准确地描述了专利中过滤组件的功能?",
"document": "CN212643037U.pdf",
"options": ["A. 用于驱动泵体运行。", "B. 用于对由出油管道进入泵体的油液进行过滤。", "C. 用于连接电动机和主动轮转轴。", "D. 用于密封主动轮转轴与泵体端壁。"],
"answer": "B"
}
# 类别2——只需要看某页的某图
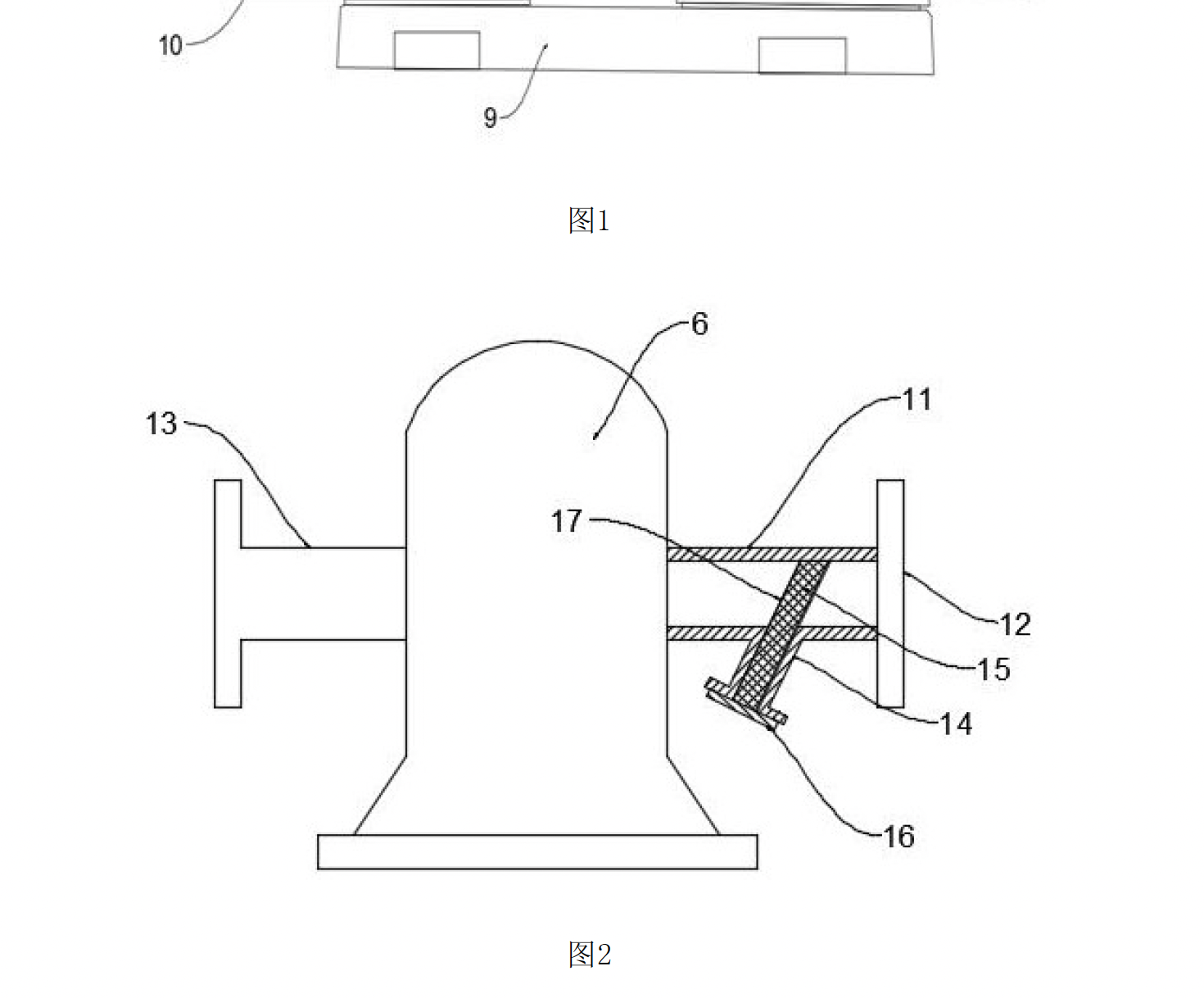
{"question": "在文件中第5页的图2中,编号为15的部件相对于编号为12的部件的位置描述正确的是?",
"document": "CN212643037U.pdf",
"options": ["A. 在12的上方", "B. 在12的下方", "C. 与12在左侧", "D. 在12的右侧"], "answer": "C"
}
复赛数据和初赛不一样的是,初赛是4选1的选择题,复赛是问答题统计F1和rouge分数。例如
{
"id": "48707b8d6e06e49882a35dc67f5XXXXX",
"question": "在文件中第7页的图片中,部件4相对于部件5在图片中的位置关系是?",
"document": "CN100342976C.pdf",
"answer": "部件4位于部件5的左侧"
}
2 技术路线
在查看了数据之后,虽然每个是对给定文档进行提问,专利页数小于5页的占比不高,有大量页数多的专利,所以采用RAG的方式,整体技术路线如下: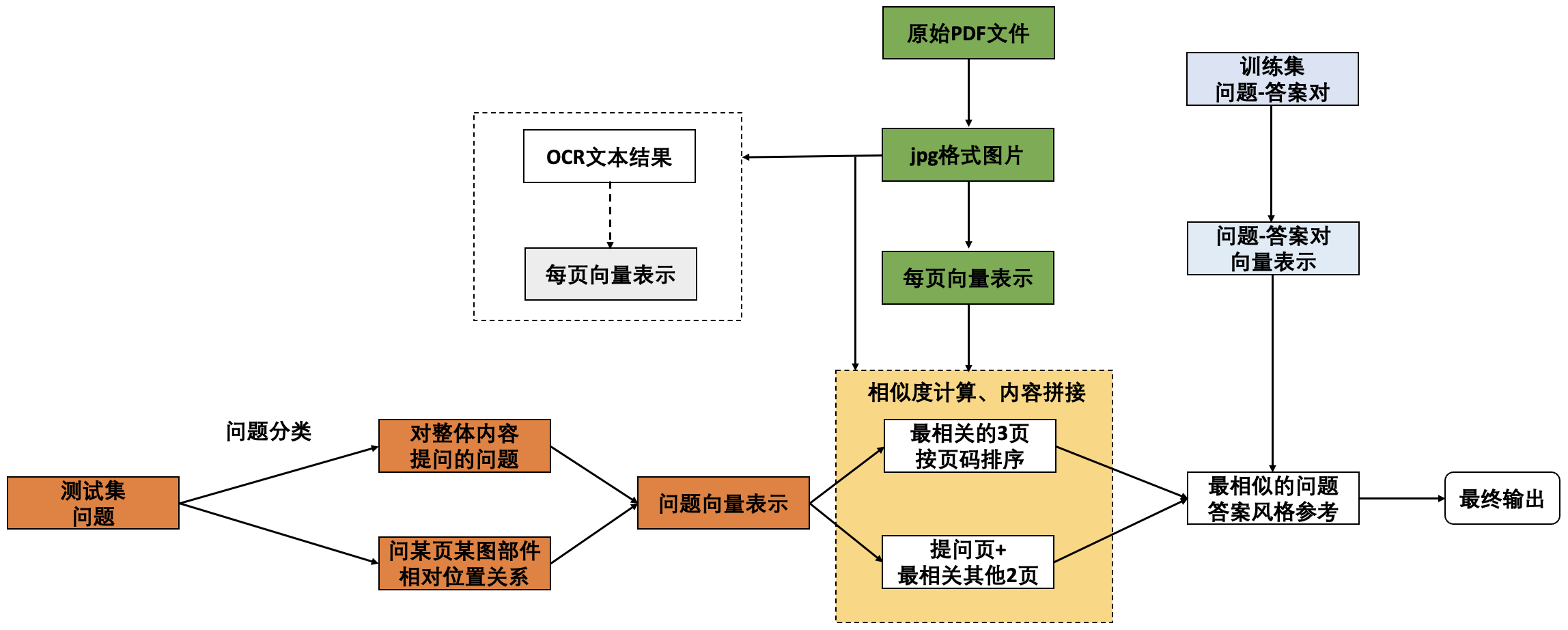
其中,使用到的模型为gme-Qwen2-VL-7B-Instruct和Qwen2.5-VL-32B-Instruct。尝试过OCR+Qwen3的方式,最后发现OCR不会有更进一步效果提升所以没有再使用OCR的方式。
3 训练数据处理细节
3.1 pdf转图片
pdf转图片可以PyMuPDF完成,这一步还挺花时间的。。。。。
# 1. pdf转jpg
import fitz # PyMuPDF
import os
import pandas as pd
import numpy as np
from tqdm import tqdm
base_dir = '/data/coding/patent_b/train/'
pdf_file_list = [x for x in os.listdir(base_dir+'/documents/') if 'pdf' in x]
# 已经完成这部分
for file_name in tqdm(pdf_file_list):
pdf_document = fitz.open(base_dir+'/documents/'+file_name)
os.makedirs(base_dir+'/pdf_img/'+file_name.split('.')[0],exist_ok=True)
# 获取第一页
for i in range(pdf_document.page_count):
page = pdf_document.load_page(i) # 注意:页码从0开始
# 将页面转换为图像
pix = page.get_pixmap(dpi=600) # 这些文档600的dpi够了
pix.save(base_dir+'/pdf_img/'+file_name.split('.')[0]+'/'+str(i+1)+'.jpg')
3.2 图片变成向量表示
因为后续跨模态检索要使用文本和图片计算相似度,所以使用了GME模型,保存好文件名和向量的对应关系
### gme_inference是modelscope的里面的gme_inference.py
# os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# IMAGE_FACTOR = 28
# MIN_PIXELS = 4 * 28 * 28
# MAX_PIXELS = 1568*28*28 # 1280 * 28 * 28
# MAX_RATIO = 200
# 2. 图片结果存入向量库
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
os.environ["MAX_PIXELS"] = '1229312' # 1003520
from gme_inference import GmeQwen2VL
gme = GmeQwen2VL(model_name='/data/coding/llm_model/iic/gme-Qwen2-VL-7B-Instruct',max_image_tokens=1280)
import os
import pandas as pd
import numpy as np
import tqdm
from warnings import filterwarnings
# 过滤掉一些警告
filterwarnings("ignore")
base_dir = '/data/coding/patent_b/train/'
pdf_file_list = [x for x in os.listdir(base_dir+'/pdf_img/')]
files_total_cnt = 0
for pdf_file in pdf_file_list:
file_name = pdf_file.split('.')[0]
file_list = [x for x in os.listdir(base_dir+'/pdf_img/'+file_name) if 'jpg' in x]
files_total_cnt +=len(file_list)
# 文件有多个,每个都需要存映射关系
img_page_num_list = []
img_name_list = []
img_vectors = np.empty((files_total_cnt, 3584)) # 向量维度是3584维
idx = 0
for pdf_file in pdf_file_list:
file_name = pdf_file.split('.')[0]
file_list = [x for x in os.listdir(base_dir+'/pdf_img/'+file_name) if 'jpg' in x] # pdf文件存储的jpg
for k in range(len(file_list)):
image_path = base_dir+'/pdf_img/'+file_name + '/' + file_list[k]
e_text = gme.get_image_embeddings(images=[image_path])
img_vectors[idx] = e_text[0].to('cpu').numpy()
page_num = int(file_list[k].split('.')[0])
img_page_num_list.append(page_num)
img_name_list.append(file_name)
idx+=1
# 映射关系存储到pandas里面比较方便
img_page_num_mapping = pd.DataFrame({'index': range(len(img_page_num_list)), 'page_num': img_page_num_list, 'file_name': img_name_list})
# 将向量和页码映射关系存储到文件
np.save('train_b_pdf_img_vectors.npy', img_vectors)
img_page_num_mapping.to_csv('train_b_pdf_img_page_num_mapping.csv', index=False) # 存储映射关系
3.3 问题向量表示生成
&esmp; 把训练集的问题和答案拼在一起生成向量表示,后续可用作为few-shot示例
# 4. 读取问题生成问题的向量
df_question = pd.read_json('/data/coding/patent_b/train/train.jsonl',lines=True)
# 问题的vector进行保存
question_vectors = np.empty((len(df_question), 3584))
for i in range(len(df_question)):
question = df_question.loc[i,'question']
document_name = df_question.loc[i,'document']
true_answer = df_question.loc[i,'answer']
full_question = question
query_vec = gme.get_text_embeddings(texts=[full_question])
question_vectors[i] = query_vec[0].to('cpu').numpy()
# 保存问题的向量
np.save('all_train_b_question_vectors.npy', question_vectors)
4 结果输出
测试集也要和训练集一样做处理,处理好了之后可以运行推理得到结果
4.1 数据加载
包含训练集问题向量表示、测试集问题向量表示、测试集专利文档、测试集专利文档的向量表示
import numpy as np
import pandas as pd
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
import os
train_base_dir = '/data/coding/patent_b/train/'
df_train_question = pd.read_json("/data/coding/patent_b/train/train.jsonl",lines=True)
train_question_vector = np.load('all_train_b_question_vectors.npy')
base_dir = '/data/coding/patent_b/test/'
df_question = pd.read_json("/data/coding/patent_b/test/test.jsonl",lines=True)
question_vector = np.load('all_test_b_question_vectors.npy')
test_pdf_image_vectors = np.load("test_b_pdf_img_vectors.npy")
test_pdf_image_page_num_mapping = pd.read_csv('test_b_pdf_img_page_num_mapping.csv')
4.2 模型加载
注意最大几张图就limit_mm_per_prompt里面的image数量为几,有几张卡tensor_parallel_size就是几(通常需要是偶数或者4的倍数)。跑32B的VL模型,token数量为8000的情况下,大概需要160GB显存
#os.environ['VIDEO_MAX_PIXELS'] = '50176'
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"
os.environ["MAX_PIXELS"] = "1568000" # 1568000 2000 token
#os.environ['FPS_MAX_FRAMES'] = "2"
model_path = "/data/coding/lora_qwen25_vl_32b_for_b/v0-20250802-085531/checkpoint-215-merged/"
vl_model = LLM(
model=model_path,
limit_mm_per_prompt={"image": 3},
gpu_memory_utilization=0.9,
tensor_parallel_size=4,
max_model_len=8192,
max_num_seqs=1
)
processor = AutoProcessor.from_pretrained(model_path)
def origin_vllm(messages,max_tokens=768):
sampling_params = SamplingParams(
temperature=0,
max_tokens=max_tokens
)
prompt = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
mm_data = {}
if image_inputs is not None:
mm_data["image"] = image_inputs
llm_inputs = {
"prompt": prompt,
"multi_modal_data": mm_data,
# FPS will be returned in video_kwargs
"mm_processor_kwargs": video_kwargs,
}
else:
llm_inputs = {
"prompt": prompt
}
outputs = vl_model.generate([llm_inputs], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
return generated_text
4.3 相似检索
包括找相似的问题,以及在文档里面找相关页
## 找相似的问题
def get_similar_question_embedding(question_idx,top_k=2):
query_vec = question_vector[question_idx] # 当前的
cos_sim = np.dot(train_question_vector, query_vec) / (np.linalg.norm(train_question_vector, axis=1) * np.linalg.norm(query_vec))
# 获取最相似的top_k个索引
top_k_indices = np.argsort(cos_sim)[-(top_k):][::-1]
# 返回的top_k_indices中不包含question_idx本身
# if question_idx in top_k_indices:
# top_k_indices = top_k_indices[top_k_indices != question_idx]
retrived_question_idx = top_k_indices[:top_k] # 最相近的top_k个
return retrived_question_idx # 返回一个list,大小最大为top_k
def get_options_for_similar_answer(retrived_question_idx):
options_str = '回答风格示例: '
for idx in retrived_question_idx:
ans = df_train_question.loc[idx, 'answer']
options_str += (ans +'\n')
return options_str+'\n\n'
## 文档里面找相关的页
def get_similar_image_embedding(base_dir,document_name,question_idx,top_k,pic_page_num):
document_name = df_question.document[question_idx].split('.')[0]
vec_idx = test_pdf_image_page_num_mapping[test_pdf_image_page_num_mapping['file_name']==document_name]['index'].values
candidate_vec = test_pdf_image_vectors[vec_idx]
query_vec = question_vector[question_idx]
cos_sim = np.dot(candidate_vec, query_vec) / (np.linalg.norm(candidate_vec) * np.linalg.norm(query_vec))
# 获取最相似的top_k个索引
top_k_indices = np.argsort(cos_sim)[-(top_k+1):][::-1]
retrived_idx = vec_idx[top_k_indices] # 最相近的top_k个
retrived_page_num = test_pdf_image_page_num_mapping.loc[retrived_idx]['page_num'].to_list()
retrived_page_num = [int(x) for x in retrived_page_num]
# 如果pic_page_num>=0,返回的top_k个中不包含pic_page_num
if pic_page_num >= 0:
if pic_page_num in retrived_page_num:
retrived_page_num.remove(pic_page_num)
# 只返回前top_k个
retrived_page_num = retrived_page_num[:top_k] # 最多返回top_k个
# retrive_page_num排序
retrived_page_num = sorted(retrived_page_num) # 按照page_num排序
return retrived_page_num # 返回一个list,大小最大为top_k
4.4 问题分类
区分清楚当前问题到底是哪种问题,是问某页某图的相对位置关系只需要看这页的这个图,还是需要参考其他信息的
def classify_question(text):
question = """你是一个内容分类专家,请判断用户的这个问题能否直接通过看图回答,还是需要参考其他的相关信息来回答。
判断规则:已知图是结构图,里面只有部件序号,没有部件名称。如果用户的问题是要通过看图判断某些部件的位置关系,这类问题可以直接通过看图回答;如果用户问题涉及到询问部件是什么、部件名称功能和原理等,这些问题需要参考其他的相关信息来回答。
对于只需要看图回答的问题,请回答字母"Y";对于需要参考其他的相关信息来回答的问题,请回答字母"N"。
给你提供一些示例
示例1: 在文件中第5页提供的图片中,编号为4的部件是什么?
解析:询问部件名称,图里面是没有的
回答:N
示例2:基于文件中第6页的图片,部件4位于哪个部件的延伸方向上?
解析:询问部件位置关系,图里面是可以看出来的
回答:Y
示例3:根据文件中第7页的图片,部件41位于部件3的什么位置?
解析:询问部件位置关系,图里面是可以看出来的
回答:Y
你要判断的用户问题是:
"""
question += text + "\n"
question += "请直接回答分类结果,不要解释,你的答案为:"
messages = [
{
"role": "user",
"content":[
{"type": "text", "text": question}
]
}
]
return origin_vllm(messages,2000)
4.5 类别一问题回答
对于需要参考专利整体内容才能回答的,找top3相关的页,直接回答。这类问题在初赛选择题形式回答的准确率是非常高的在98%左右,所以是不需要OCR的(OCR+Qwen3微调后也差不多是98%-99%)本身没有提升空间。
def get_image_answer(document_name,question,question_idx):
question1 ="你是一个专利内容分析专家,请根据我提供的专利内容回答我的问题。\n"
question1 += ("专利内容为:\n")
retrived_page_list = get_similar_image_embedding(base_dir,document_name,question_idx,2,-1)
# 排序
retrived_page_num = sorted(retrived_page_list)
query = ''
images = []
retrived_list = []
for i in range(len(retrived_page_num)):
image_file = base_dir + '/pdf_img/' + document_name.split('.')[0] + '/' + str(retrived_page_num[i]) +'.jpg'
retrived_list.append(image_file)
question2 = ("\n\n请你在分析专利内容后,回答我的问题:\n")
question2 += "【我的问题】【"
question2 += (question +"】\n")
question2 += ('请仔细思考,在思考结束后,请直接给出你的答案:')
query += question1
messages = [
{
"role": "user",
"content":[
{"type": "text", "text": question1},
]
}
]
for i in range(0,len(retrived_list)):
query += '<image>'
images.append(retrived_list[i])
messages[0]['content'].append({
"type": "image",
"image": retrived_list[i],
"max_pixels": 1568000
})
query += question2
messages[0]['content'].append({
"type": "text",
"text": question2
})
return origin_vllm(messages,2000)
4.6 类别二问题回答
def get_mix_answer_img(document_name,pic_page_num,question,question_idx,if_need_other=True):
question1 ="你是一个专利内容分析专家,请根据我提供的专利内容回答我的问题。\n"
question1 += ("该问题针对于这页专利内容里面的图进行提问:\n")
retrived_page_list = get_similar_image_embedding(base_dir,document_name,question_idx,2,pic_page_num)
retrived_page_num = sorted(retrived_page_list)
retrived_list = []
images = []
query = ''
for i in range(len(retrived_page_num)):
image_file = base_dir + '/pdf_img/' + document_name.split('.')[0] + '/' + str(retrived_page_num[i]) +'.jpg'
retrived_list.append(image_file)
#print(retrived_list)
if if_need_other: # 如果不是只用图片回答
question2 = ("\n\n其他的相关专利内容为:\n")
question3 = ("\n\n请你在分析专利内容后,回答我的问题:\n")
question3 += "【我的问题】【"
question3 += (question +"】\n")
if "位置" in question and if_need_other:
question3 += ('请仔细思考,在思考结束后,请直接给出你的答案:')
elif "位置" in question:
question3 += (
"请仔细思考,你需要特别注意,图中部件的上下、前后、左右位置判断应以标号线所指代的实际结构为准,而不是仅凭直观看数字。"
)
question3 += (
"在思考结束后,请直接给出你的答案:"
)
else:
question3 += ('请仔细思考,在思考结束后,请直接给出你的答案:')
query += question1
query += '<image>'
images.append(base_dir + '/pdf_img/' + document_name.split('.')[0]+ '/' + str(pic_page_num) +'.jpg')
messages = [
{
"role": "user",
"content":[
{"type": "text", "text": question1},
{
"type": "image",
"image": base_dir + '/pdf_img/' + document_name.split('.')[0]+ '/' + str(pic_page_num) +'.jpg',
"max_pixels": 1568000 if if_need_other else 2352000
},
]
}
]
if if_need_other: # 如果不是只用图片回答
query += question2
messages[0]['content'].append({"type": "text", "text": question2})
for i in range(0,len(retrived_list)):
query += '<image>'
images.append(retrived_list[i])
messages[0]['content'].append({
"type": "image",
"image": retrived_list[i],
"max_pixels": 1568000
})
query += question3
messages[0]['content'].append({
"type": "text",
"text": question3
})
return origin_vllm(messages,768)
4.7 风格修正
def get_final_answer(text,answer_style):
question = "你是一个内容提取专家,请从文本中判断,这段描述想表达的准确答案是什么。请仔细思考,在思考结束后,输出简要的答案(通常20个字词以内)。"
question +="""
为了便于你回答,我给你提供几个示例:
示例1
文本内容为:"根据专利内容和图2的描述:\n\n- 编号为15的部件是**滤网**。\n- 编号为12的部件是**连接法兰**。\n\n从图2中可以看出,滤网(15)位于连接法兰(12)的**下方**。\n\n因此,正确答案是在12的下方"
输出的答案为:在12的下方
示例2
文本内容为:"根据专利内容,调节可移动折弯模架的位置是通过丝杆机构(部件7)实现的。丝杆机构包括丝杆(71)和丝杆滑块(72),通过调节手轮(74)转动丝杆,从而带动丝杆滑块移动,进而控制导轨滑块(6)沿导轨(5)移动,最终实现可移动折弯模架(1)的位置调节。因此,首先需要操作的部件是丝杆机构(部件7)。"
输出的答案为:部件7
示例3
文本内容为:"该专利提供了一种用于滚筒输送机的货物靠边规整处理机构,通过倾斜设置的转辊和联动皮带,实现货物自动靠边规整,减少损伤,提高输送效率。"
输出的答案为:实现货物自动靠边规整
示例4:
文本内容为:"定位杆"
输出的答案为: 定位杆
示例5:
文本内容为:"部件22位于部件23的左侧"
输出的答案为: 部件22位于部件23的左侧
"""
question += ('同时为了便于你回答,我再给你提供一些答案的风格示例:\n')
question += answer_style + '\n'
question += "你要判断的文本内容为:\n"
question += text
question += "请直接回答文本想要表达的准确答案(风格和前面的示例类似,通常20个字词以内,并且不要改变原始回答的意思),不要解释,你输出的答案为:"
messages = [
{
"role": "user",
"content":[
{"type": "text", "text": question}
]
}
]
return origin_vllm(messages)
4.8 pipeline
因为问某页某图是明确的,可以直接从问题里面取出来,然后再依次调用对应的回答流程:
import re
from tqdm import trange
import json
# 实时把结果写入jsonl文件
query_list = []
image_list = []
for i in trange(len(df_question)):
question = df_question.loc[i,'question']
document_name = df_question.loc[i,'document']
question_type = ''
if_need_other = True
answer = ''
style_answer = ''
answer_style = get_options_for_similar_answer(get_similar_question_embedding(i,2))
if "第" in question and "页" in question and "图": # 问题含有图片
pic_page_num = re.findall(r"第(\d+)页", question)[0]
pic_page_num = int(pic_page_num)
question_type = classify_question(question) # 判断问题类型
if 'Y' in question_type or 'y' in question_type: # 直接通过看图回答
if_need_other = False
else:
if_need_other = True
answer = get_mix_answer_img(document_name,pic_page_num,question,i,if_need_other)
style_answer = get_final_answer(answer,answer_style)
else:
answer = get_image_answer(document_name,question,i)
style_answer = get_final_answer(answer,answer_style)
result_dict= dict()
result_dict['idx'] = str(i)
result_dict['document'] = document_name
result_dict['question'] = question
result_dict['question_type'] = question_type
result_dict['answer'] = answer
result_dict['style_answer'] = style_answer
with open('test_b_style_infer_if_need_ck215.jsonl', 'a', encoding='utf-8') as f:
f.write(json.dumps(result_dict, ensure_ascii=False) + '\n')
5 训练数据构造
复赛的问答可以构造数据训练,初赛选择题形式就不必了。训练数据的形式和推理时的形式保持一致,训练集jsonl文件的构造上具体为:
def get_image_answer(document_name,question,question_idx):
question1 ="你是一个专利内容分析专家,请根据我提供的专利内容回答我的问题。\n"
question1 += ("专利内容为:\n")
retrived_page_list = get_similar_image_embedding(base_dir,document_name,question_idx,2,-1)
# 排序
retrived_page_num = sorted(retrived_page_list)
query = ''
images = []
retrived_list = []
for i in range(len(retrived_page_num)):
image_file = base_dir + '/pdf_img/' + document_name.split('.')[0] + '/' + str(retrived_page_num[i]) +'.jpg'
retrived_list.append(image_file)
question2 = ("\n\n请你在分析专利内容后,回答我的问题:\n")
question2 += "【我的问题】【"
question2 += (question +"】\n")
question2 += ('请仔细思考,在思考结束后,请直接给出你的答案:')
query += question1
messages = [
{
"role": "user",
"content":[
{"type": "text", "text": question1},
]
}
]
for i in range(0,len(retrived_list)):
query += '<image>'
images.append(retrived_list[i])
messages[0]['content'].append({
"type": "image",
"image": retrived_list[i],
"max_pixels": 1568000
})
query += question2
messages[0]['content'].append({
"type": "text",
"text": question2
})
return query,images
def get_mix_answer_img(document_name,pic_page_num,question,question_idx,if_need_other=True):
question1 ="你是一个专利内容分析专家,请根据我提供的专利内容回答我的问题。\n"
question1 += ("该问题针对于这页专利内容里面的图进行提问:\n")
retrived_page_list = get_similar_image_embedding(base_dir,document_name,question_idx,2,pic_page_num)
retrived_page_num = sorted(retrived_page_list)
retrived_list = []
images = []
query = ''
for i in range(len(retrived_page_num)):
image_file = base_dir + '/pdf_img/' + document_name.split('.')[0] + '/' + str(retrived_page_num[i]) +'.jpg'
retrived_list.append(image_file)
#print(retrived_list)
if if_need_other: # 如果不是只用图片回答
question2 = ("\n\n其他的相关专利内容为:\n")
question3 = ("\n\n请你在分析专利内容后,回答我的问题:\n")
question3 += "【我的问题】【"
question3 += (question +"】\n")
if "位置" in question and if_need_other:
question3 += ('请仔细思考,在思考结束后,请直接给出你的答案:')
elif "位置" in question:
question3 += (
"请仔细思考,你需要特别注意,图中部件的上下、前后、左右位置判断应以标号线所指代的实际结构为准,而不是仅凭直观看数字。"
)
question3 += (
"在思考结束后,请直接给出你的答案:"
)
else:
question3 += ('请仔细思考,在思考结束后,请直接给出你的答案:')
query += question1
query += '<image>'
images.append(base_dir + '/pdf_img/' + document_name.split('.')[0]+ '/' + str(pic_page_num) +'.jpg')
messages = [
{
"role": "user",
"content":[
{"type": "text", "text": question1},
{
"type": "image",
"image": base_dir + '/pdf_img/' + document_name.split('.')[0]+ '/' + str(pic_page_num) +'.jpg',
"max_pixels": 1568000 if if_need_other else 2352000
},
]
}
]
if if_need_other: # 如果不是只用图片回答
query += question2
messages[0]['content'].append({"type": "text", "text": question2})
for i in range(0,len(retrived_list)):
query += '<image>'
images.append(retrived_list[i])
messages[0]['content'].append({
"type": "image",
"image": retrived_list[i],
"max_pixels": 1568000
})
query += question3
messages[0]['content'].append({
"type": "text",
"text": question3
})
#return origin_vllm(messages,768)
return query,images
训练脚本如下,lora微调需要大约300GB的显存,A100训练时间约7小时,推理时间初赛4000条大约7小时,复赛3500条大约6小时,开销都比较大。。。。
# 1229312 1568000
MAX_PIXELS=1229312 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 swift sft \
--model /data/coding/llm_model/Qwen/Qwen2___5-VL-32B-Instruct \
--dataset /data/coding/train_b_dataset_for_image_0801.jsonl \
--train_type lora \
--device_map auto \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--split_dataset_ratio 0.1 \
--output_dir /data/coding/lora_qwen25_vl_32b_b/ \
--num_train_epochs 5 \
--lorap_lr_ratio 10 \
--save_steps 10 \
--eval_steps 10 \
--save_total_limit 4 \
--logging_steps 5 \
--seed 42 \
--learning_rate 1e-4 \
--init_weights true \
--lora_rank 8 \
--lora_alpha 32 \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-08 \
--weight_decay 0.1 \
--gradient_accumulation_steps 16 \
--max_grad_norm 1 \
--lr_scheduler_type cosine \
--warmup_ratio 0.05 \
--warmup_steps 0 \
--gradient_checkpointing false
6 待提升的点
- 发现还是问相对位置关系类的题回答不准,一个想法是先对文档结构化,把问某页某图的只让模型看到这页的这个图,这样分辨率也可以提升图片变大,可以做进一步的微调
- 数据增强上让模型生成一些推理链放到训练集里面,推理测试集的时候对于相对位置关系这类问题让模型把思考过程也一步步输出然后输出结果
- 前一个WWW的比赛,300个样本,有朋友表示lora微调效果不好,全参微调一把效果上去,可能也可以试试全参微调

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)