Deepseek模型部署与应用-LLM命令行部署(二)
本文介绍了在Windows系统下部署DeepSeek-R1-Distill-Qwen-1.5B轻量化大模型的方法。详细说明了模型文件下载、命令行部署步骤及参数配置要点,包括对话模式设置、温度参数调整等关键选项。通过实验验证了该模型在个人电脑上的运行效率,包括推理速度和结果稳定性,为轻量化大模型的本地化应用提供了可行性参考。最后展示了模型对话测试效果,证实了其在Windows环境下的实用价值。
目录
2、下载DeepSeek-R1-Distill-Qwen-1.5B模型文件(见上一篇博文)
步骤三、与模型进行对话,比如输入"你是谁?",即可得到结果。
一、任务介绍
二、任务目的
三、任务配置
1、 Windows用户配置思路(见上一篇博文)
2、下载DeepSeek-R1-Distill-Qwen-1.5B模型文件(见上一篇博文)
3、命令行部署
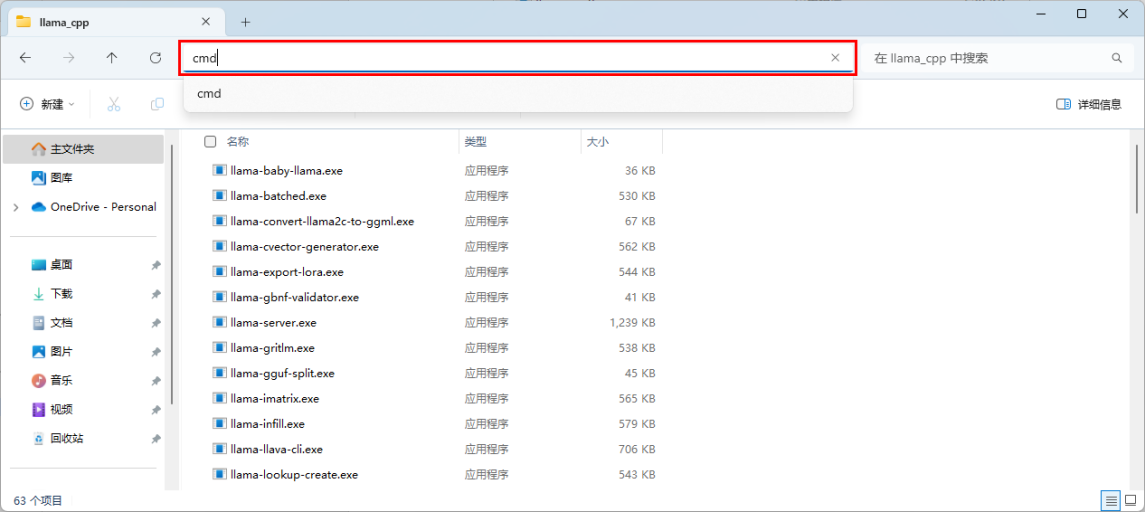
步骤一、单击文件夹上方的导航栏,然后输入cmd命令并回车
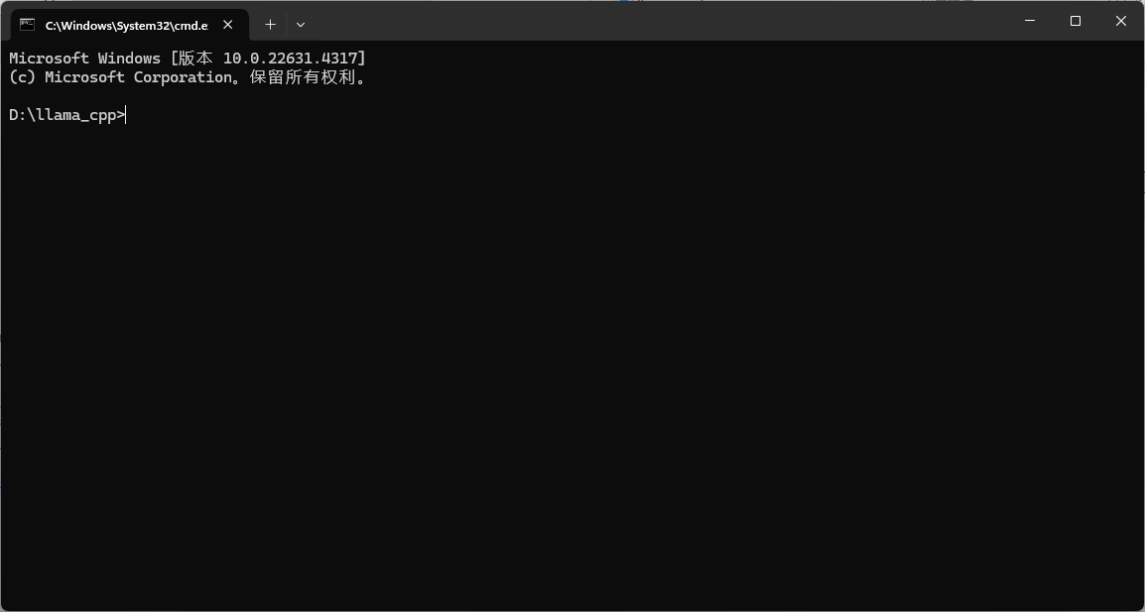
步骤二、输入以下命令对模型执行推理
#对话模式
llama-cli.exe -m DeepSeek-R1-Distill-Qwen-1.5B-Q6_K_L.gguf --temp 0.6 部分参数说明:
-m:模型路径。
-cnv:对话模式(不打印特殊token和前缀、后缀,使用默认聊天模板,本实验提供的软件包默认开启对话模式,添加参数后反而会降低模型回答质量,因此命令行未添加该参数)。
--chat-template:聊天模板,如果模板与模型不匹配,则会出现模型回答乱码、不停止等问题。
--color:使用不同的颜色区分用户输入与模型输出。
--temp: 调整输出文本的随机性,默认0.8,本实验设置为0.6是因为DeepSeek官方推荐为0.6。
--repeat-penalty: 控制token序列在生成文本中的重复度,默认是1.0,禁用。
--top-k: 从概率最高的K个候选项中选择下一个token,默认是40。
步骤三、与模型进行对话,比如输入"你是谁?",即可得到结果。
步骤四、不同配置参数的效果如下,其中<think></think>中间的文本为模型思考
llama-cli.exe --color -m DeepSeek-R1-Distill-Qwen-1.5B-Q6_K_L.gguf --temp 0.6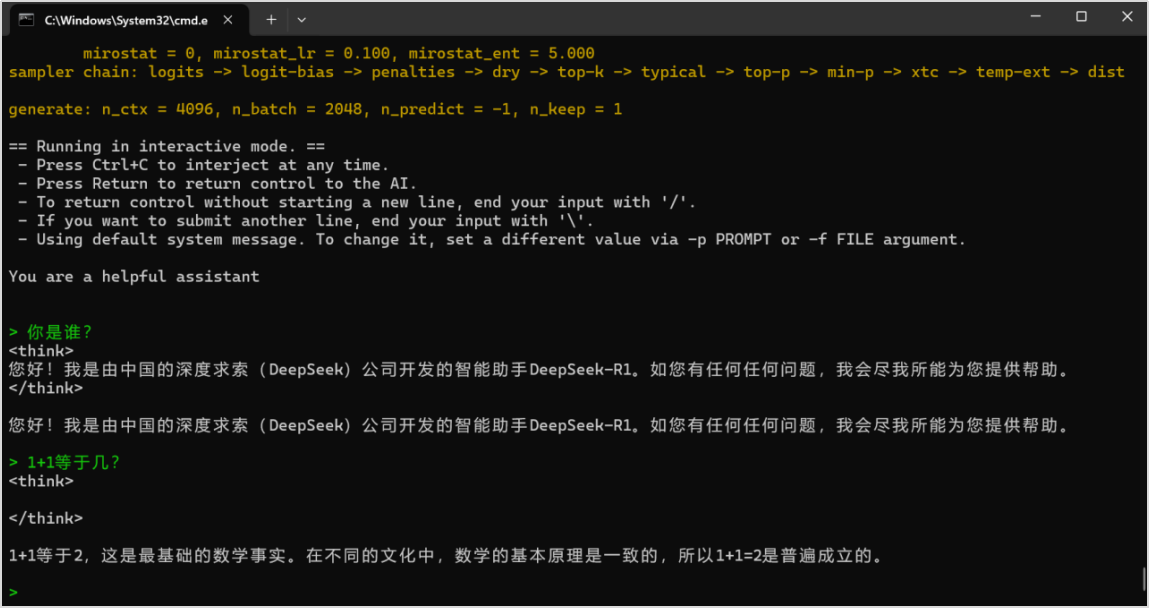
---结束!
小结
实验讲述了DeepSeek-R1-Distill-Qwen在Windows环境下的部署与推理性能,验证了其在个人电脑上的运行效率,包括推理速度及模型推理结果稳定性,为轻量化大模型的本地化应用提供了可行性参考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)