[LLM 应用评估] 改进AI应用 | LLMs & Embeddings | Langchain 封装器
改进AI应用不是艺术,而是科学LLMs 和 Embeddings。它们如同AI语言系统的"大脑"与"翻译器- **LLMs** 作为语言系统的核心,承担内容生成与质量评估双重职责- **Embeddings** 将文本映射至语义空间,实现计算机可处理的语义分析- **封装器模式** 使 Ragas 兼容多平台模型,保障评估流程的统一性
链接:https://docs.ragas.io/en/stable/
改进AI应用获得的一些经验
引言
我们已经发布了AI应用。用户正在使用它。响应没有崩溃,但也不够理想。反馈模糊,满意度评分平庸,每次调整提示词或更换模型都像在黑暗中摸索。
我们尝试不同的工作流程,追逐边缘案例,但仍无法判断是否真正改进。最终,我们停止追踪,开始猜测,然后草率上线。
其实不必如此。读完本文,我们将获得清晰的指南,通过系统化的评估(evals)从零搭建到自动化评估闭环,让AI应用超越用户预期。
这些洞见源于我们在多家企业和初创公司改进LLM应用的经验,以及构建Ragas平台的实践
改进AI应用不是艺术,而是科学。
设定明确指标、构建真实测试集、收集人工反馈、用自动化LLM评估扩展规模。
本指南涵盖从测试数据创建到分析错误、整合用户反馈的全流程,让我们停止猜测,开启系统化改进。
什么是评估?
评估衡量AI系统达成目标的有效性。
AI应用中的评估常与"可观测性"或"安全护栏"混淆。评估的核心是通过明确目标量化系统表现,包含三个关键步骤:
- 构建真实测试集:收集或生成系统预期的输入
- 明确定义成功:具体说明"优秀"结果的标准及其合理性
- 选择精准指标:量化每个结果(通过/失败、分数、排序)
另一个常见误区是将评估与基准测试混为一谈。LLM基准测试侧重用学术指标在公开数据集评估不同模型,而这些数据或指标通常与我们的系统任务无关。
这就是为什么公开基准无法帮助我们评估和改进具体系统。
为什么AI工程师需要关注评估?
科学实验是系统化改进AI应用的唯一可靠方法。可能有人问:为什么不快速浏览响应直接部署变更?
评估优于主观检查的三大原因:
- 规模:人工无法检查数百个边缘案例。现实输入复杂多变,模型失败的方式微妙难察
- 客观性:直觉判断因人而异。评估将主观印象转化为可重复的量化指标
- 沟通:"感觉更好"无法对齐团队认知。评估提供具体数据:“新提示词使任务完成率从50%提升至70%”
评估不仅是良好实践,更是
关键基础设施。
如何开始?
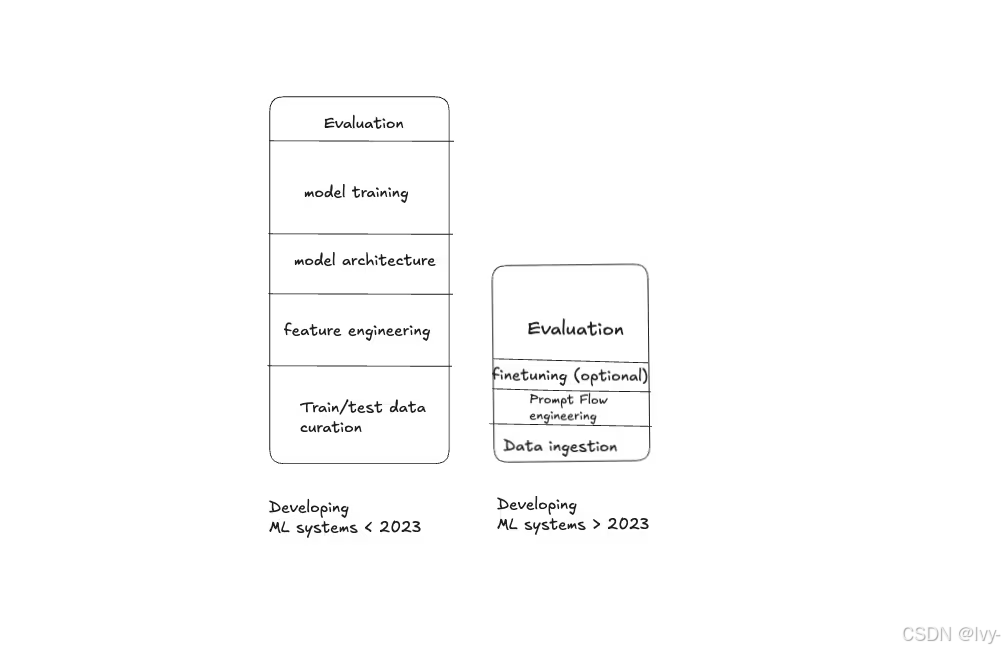
在LLM系统中,迭代快但效果评估慢。与传统机器学习不同,AI应用开发常涉及提示词修改、工具调整或路由逻辑变更——这些变更只需几分钟实现,但评估影响却耗时更久,因为需要人工检查样本响应。
实际上,评估可能占团队迭代时间的30%,特别是涉及多边缘案例测试时。GitHub Copilot、Casetext和Notion等团队的工作流程也印证了评估的重要性。
启动步骤:
- 端到端评估:类似集成测试,验证完整流程是否产出用户关心的结果
- 组件级评估:类似单元测试,调试检索器、重排序器等独立模块
建议从端到端评估开始,确认输出质量后再深入关键组件。
数据集构建
认真改进AI系统的第一步:构建优质测试数据集。
预生产阶段
尚无用户?从编写10-30个代表预期场景的输入开始,关注意图多样性而非数量。初始数据集可通过合成数据生成管道扩展变体。
生产阶段
已有用户?采样30-50个真实系统输入,手动审查质量、多样性和边缘案例。进阶技巧:
- 从生产环境采样1000+系统输入
- 使用嵌入模型编码输入
- 通过KNN或DBSCAN聚类
- 从每个簇中采样典型样本加入测试集
关键原则:小步快跑,保持真实,逐步扩展,避免陷入完美主义陷阱。
高质量合成数据生成技巧
当真实数据不足时,可用LLM生成合成数据。以医疗AI助手为例:
# 定义用户画像
personas = [
"刚开启研究之旅的博士生,需要文献综述和假设形成帮助",
"寻求跨论文综合分析的资深学者",
"处理罕见病例的肿瘤科医生"
]
# 生成提示模板
prompt_template = """
你正在构建医疗AI助手的测试数据集。
请根据以下要素生成用户查询:
- 用户画像:{persona}
- 查询复杂度:{complexity}
- 主题:{topic}
要求:
* 生成该画像用户可能提出的真实查询
* 体现指定复杂度并紧扣主题
* 仅输出查询,不要解释或元数据
"""
我们最初用电子表格管理数据集,后迁移至Notion数据库,因其提供更好的UX和API支持。
人工审核与标注
这是多数团队犯错的关键环节。低估人工审核的重要性,高估其实现难度。
核心原则:若要让AI系统符合人类预期,必须先明确定义这些预期。
操作步骤:
- 定义评估维度:如RAG系统关注响应正确性和引用准确性
- 选择指标类型:
- 二元指标(通过/失败):适用于明确界限的场景
- 数值指标(0-1):适用于需区分程度的场景
- 排序指标:适用于主观性强的输出比较
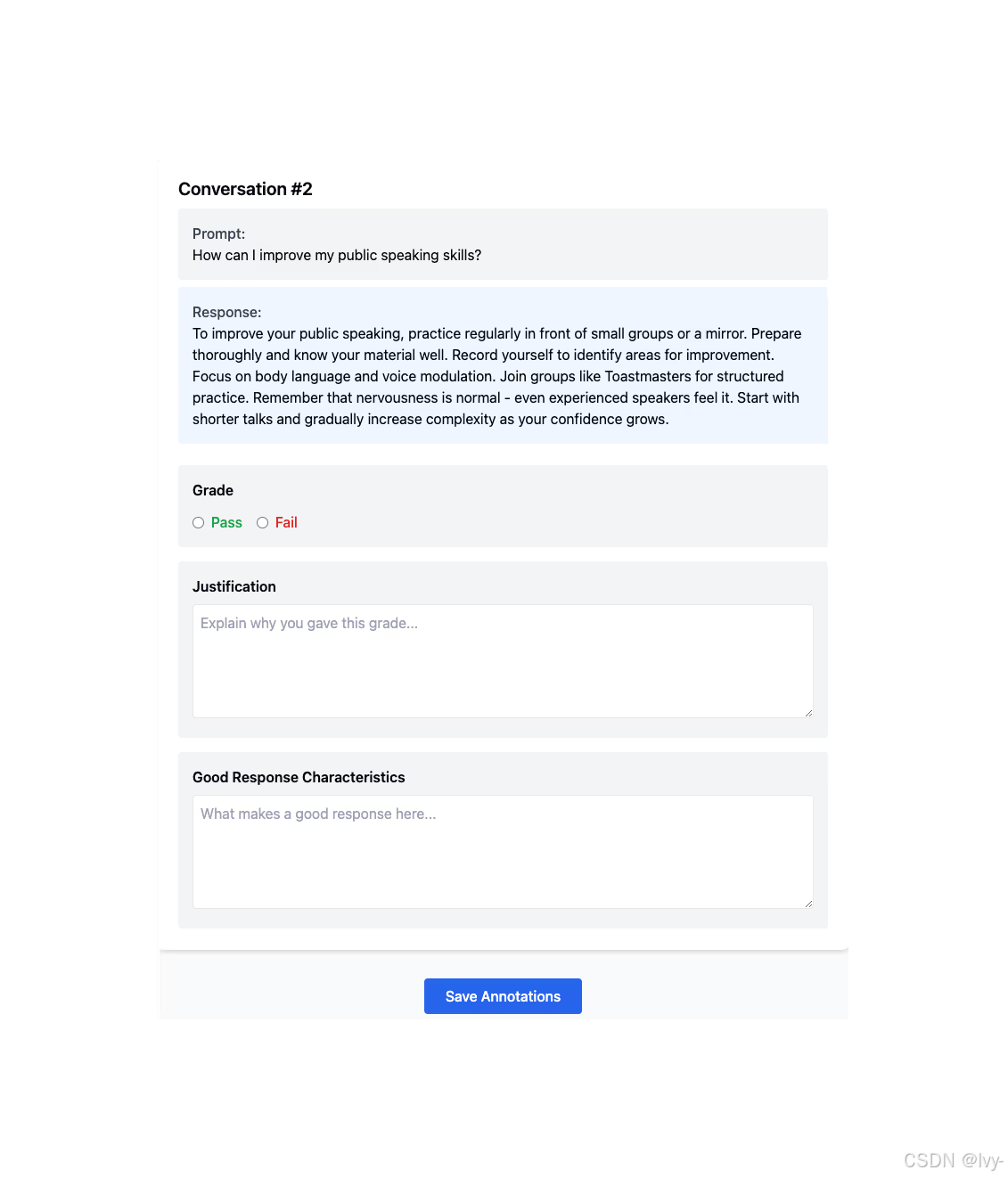
a simple annotation UI for a RAG use-case
关键技巧:
- 开发定制审核UI(如图形化标注工具)
- 收集"失败原因"等解释性数据,用于训练LLM评估器
用LLM评估器扩展规模
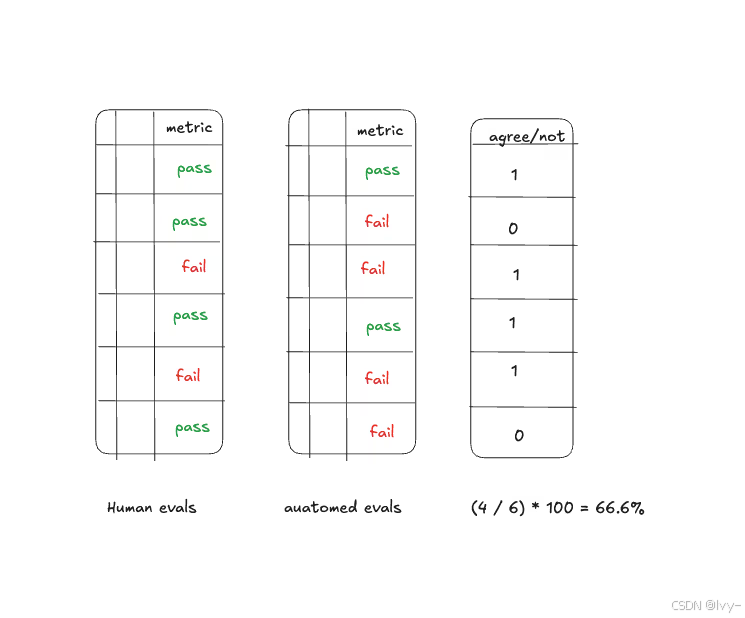
An llm as judge with 66.6% agreement
当人工审核成为瓶颈时,引入LLM作为自动评估器:
def 评估响应(输入, 响应):
# 检索相似标注样本
嵌入 = 嵌入模型.编码(f"{输入} - {响应}")
样本 = 相似性检索(嵌入, 标注索引)
# 构建小样本提示
提示 = f"""
检查响应是否相关。输出:通过/失败。
### 示例
{样本}
### 输入
{输入}
### 响应
{响应}
"""
return LLM.生成(提示)
优化方向:
- 小样本提示配合高质量示例
- 检索增强提示:自动获取相关标注样本
- 使用Spearman等级相关或Cohen’s kappa评估人机一致性
当LLM评估器与人工判断的一致性达80%以上时,可大幅提升迭代效率。
错误分析与实验
评估揭示系统缺陷,错误分析定位根本原因。
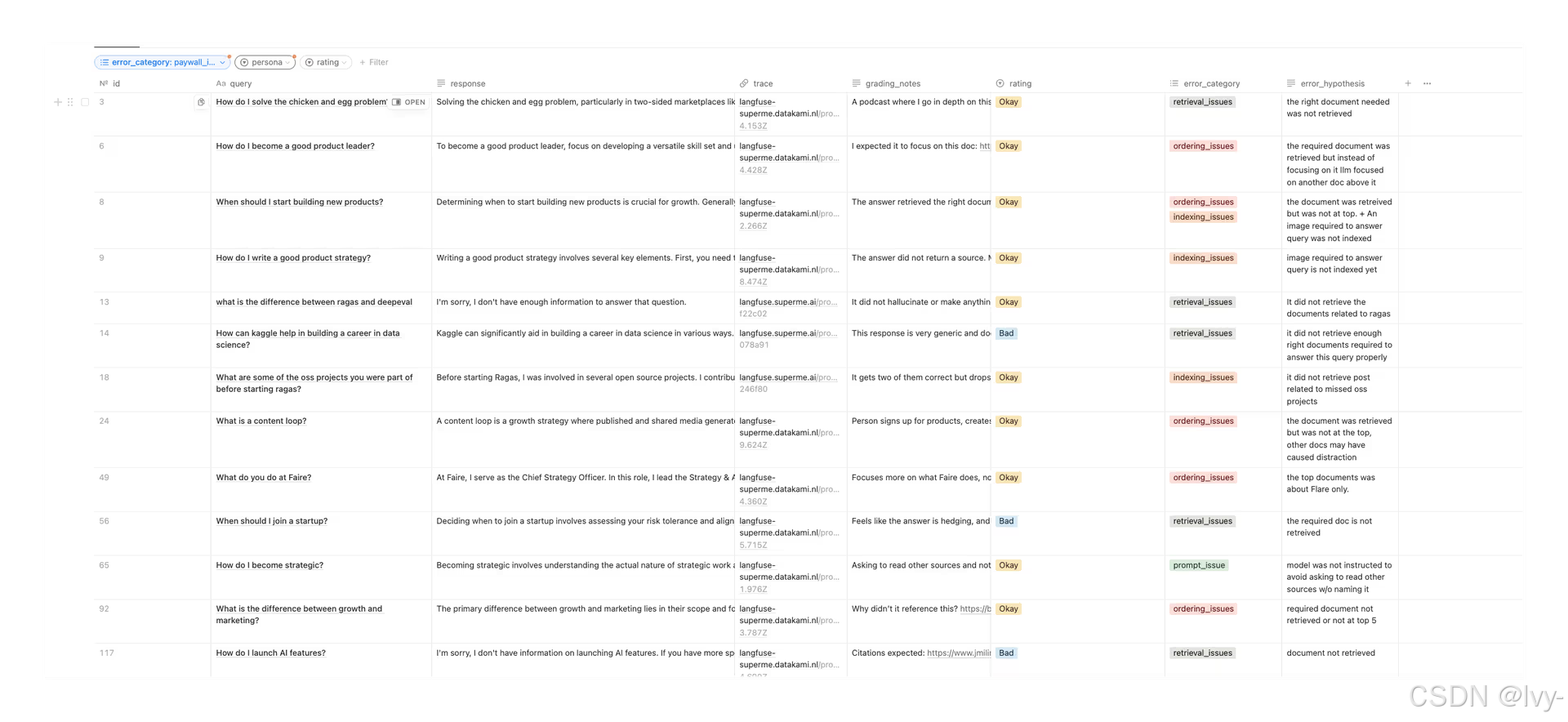
错误分类流程:
- 提出假设:逐条检查失败样本,记录可能原因
- 聚类归因:用LLM自动归类(如"检索失败"、"文档付费墙"等)
- 优先级排序:按频率解决最高发问题
实验方法论:
单变量变更:每次只修改一个组件(如提示词或检索器)AB测试:并行运行新旧版本,比较核心指标决策框架:当指标提升显著时部署,否则尝试其他方案
机器学习反馈闭环
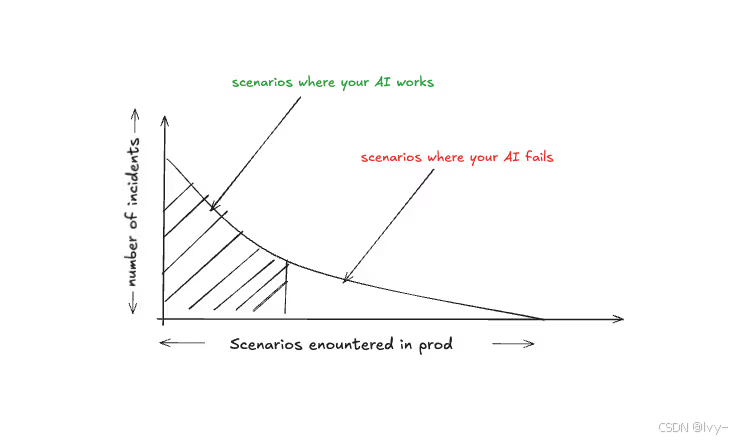
AI问题的长尾性要求持续学习生产环境中的新边缘案例:
信号捕获管道:
- 显式反馈:用户评分、差评
- 隐式信号:用户未复制输出、重复尝试相同输入
闭环流程:
- 识别真实失败案例 → 加入测试集
- 针对性实验改进 → 验证指标提升
- 部署优化版本 → 监控新边缘案例
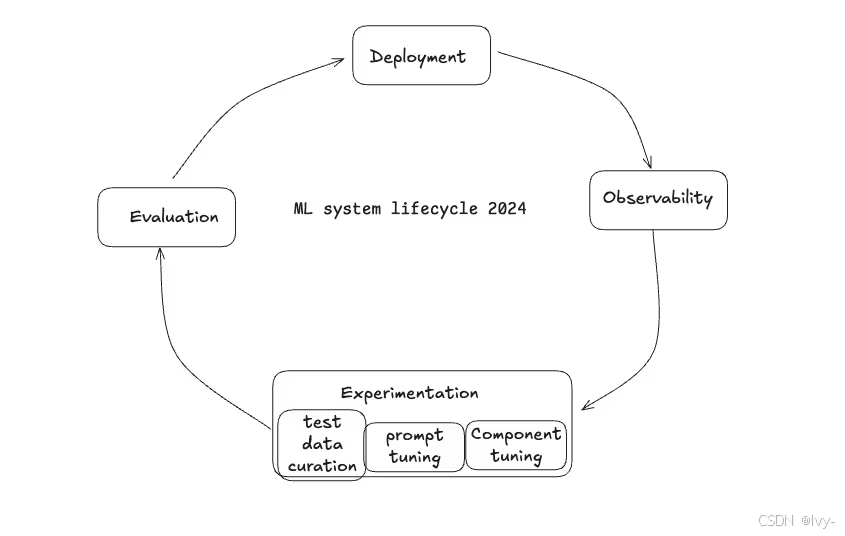
结语
卓越的AI产品源于对评估、实验和持续改进的深度投入。在Ragas,我们正将所有这些经验转化为下一代评估基础设施。如果各位正在探索系统化改进AI应用的方法,欢迎学习。
Ragas 框架
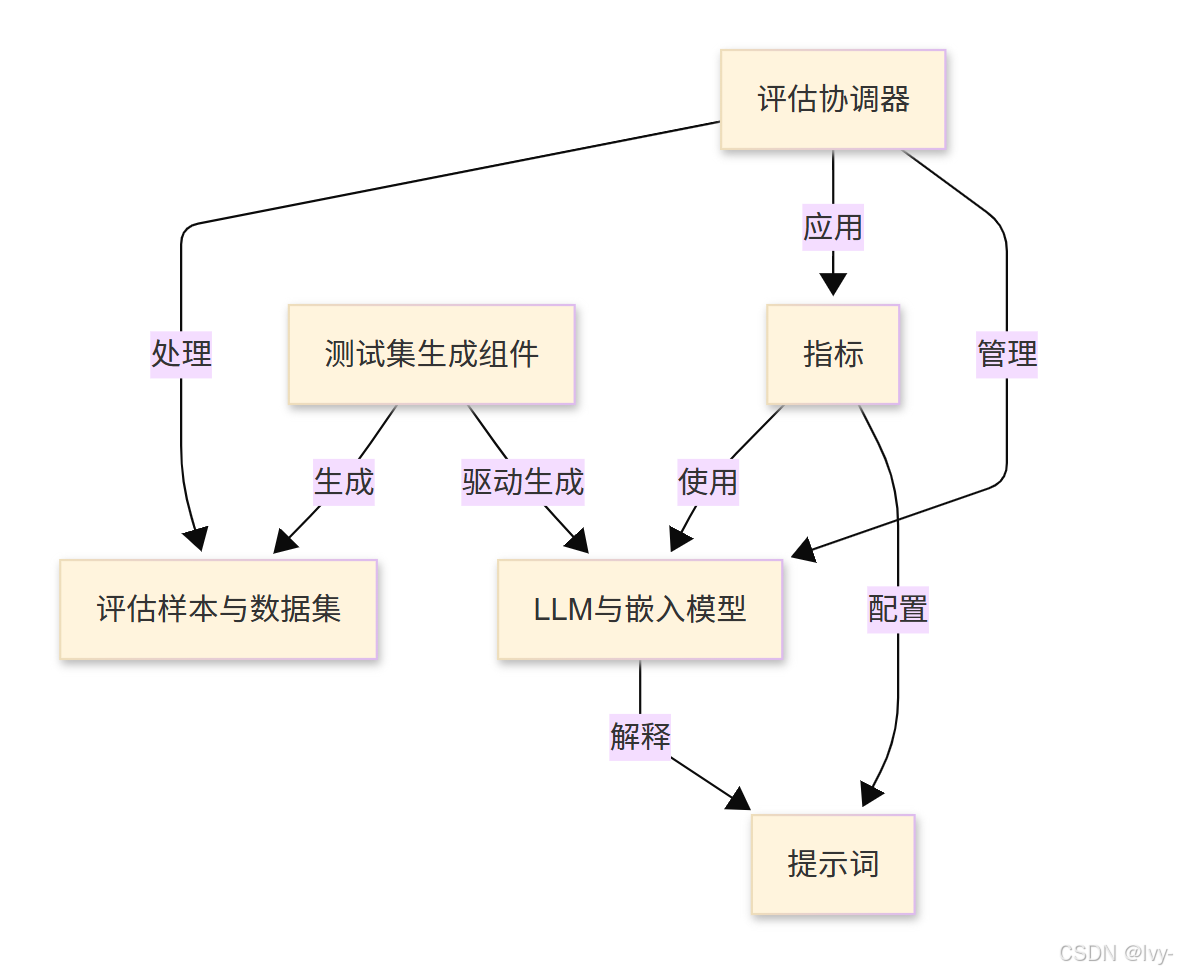
Ragas 是一个开源框架,旨在帮助开发者*评估和改进*基于检索增强生成(RAG)的AI应用。
通过将各类自动化测试(指标)应用于结构化交互数据(评估样本与数据集)来量化AI性能。
Ragas 还能通过测试集生成组件自动生成多样化测试数据,并通过核心评估协调器管理全流程。所有功能均基于LLM与嵌入模型的核心AI能力实现,并通过精确的提示词引导。
架构
核心章节
-
- 大语言模型与向量嵌入技术的基础原理
- 模型选择与性能优化策略
-
- 评估提示词的设计规范
- 动态提示模板与上下文注入
-
- 数据采集与清洗流程
- 多维度数据标注标准
-
- 准确性/相关性/多样性等核心指标
- 自定义指标开发指南
-
- 分布式任务调度架构
- 实验版本控制与结果溯源
-
- 合成数据生成算法
- 边缘案例模拟与压力测试
说明
- 架构特性:采用模块化设计,各组件通过标准接口通信,支持第三方工具无缝集成
- 性能优化:内置异步处理管道,
单节点可并行处理 500+ 评估任务 - 可视化支持:集成 Jupyter Notebook 插件,支持实时监控评估指标热力图
- 扩展能力:提供
Python SDK和REST API两种集成方式,适配云原生环境
🎢Python SDK vs REST API
Python SDK是封装好的工具包,直接调用现成函数即可使用,适合快速开发REST API是标准化接口,需手动发送HTTP请求并处理返回数据,灵活性更高但代码量稍多。
OpenCV 是用于图像处理的库
OpenGL 是用于图形渲染的 API
两者可以结合使用(比如用 OpenCV
处理图像后通过 OpenGL 显示或进一步渲染)。
第一章:大语言模型与向量嵌入
欢迎来到 Ragas
本章我们将解析两大核心概念——大语言模型(LLMs)和向量嵌入(Embeddings),它们是理解AI语言系统工作原理及Ragas评估机制的关键。
假设我们正在构建智能聊天机器人,用于回答类似"《泰坦尼克号》主角是谁?"的问题。如何判断机器人给出的答案是否准确、有用且符合逻辑?这正是 Ragas 的价值所在
Ragas 作为评估工具,帮助量化基于语言的AI系统表现。
要实现这一点,Ragas 自身需要具备理解语言的能力,这便依赖于LLMs 和 Embeddings。它们如同AI语言系统的"大脑"与"翻译器",构成评估体系的基石。
什么是大语言模型(LLMs)?
LLMs 如同博览群书的智能机器人,通过海量文本(书籍、文章、网页等)训练,掌握理解、生成和总结人类语言的复杂能力。
在 Ragas 中,LLMs 承担双重角色:
- 被评估系统:我们构建的聊天机器人或AI应用(通常由 GPT-4o、Claude 或 Gemini 等LLM驱动)。Ragas 评估该LLM的表现质量。
- AI裁判:Ragas 内部使用高性能LLM作为评估助手。这些"裁判"LLM负责判断响应质量,例如:“该回答是否准确解答问题?” 或 “信息是否源于可靠数据源?”
无论是生成答案还是评估质量,LLMs 都承担着理解与生成类人文本的核心任务。
什么是向量嵌入(Embeddings)?
如果说 LLMs 是理解语言的"大脑",Embeddings 则是将语言转化为计算机可处理形式的"翻译器"。
计算机擅长处理数字,却无法直接理解文字含义。
嵌入模型将文本(单词、句子或段落)转换为数值向量——这些向量构成语义空间的坐标。
例如:"快乐小狗"与"开心幼犬"的向量位置相近,但与"悲伤猫咪"相距甚远~
在 Ragas 中,Embeddings 用于需要衡量文本相似性或语义关联的任务。例如评估聊天机器人响应与问题的相关性时,Ragas 将两者转换为向量并计算空间距离,距离越近则语义越相似。
在 Ragas 中配置 LLMs 与 Embeddings
使用 Ragas 需指定其"AI裁判"和"翻译器"的具体模型。Ragas 支持 OpenAI、AWS、Google Cloud 等主流服务商。以下以 OpenAI 为例演示配置流程:
步骤1:安装依赖库
pip install langchain-openai
步骤2:设置API密钥
import os
# 将"your-openai-key"替换为实际密钥(建议通过环境变量读取)
os.environ["OPENAI_API_KEY"] = "your-openai-key"
步骤3:初始化模型
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 初始化LLM(选用gpt-4o作为裁判模型)
evaluator_llm = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o"))
# 初始化Embeddings(选用text-embedding-ada-002)
evaluator_embeddings = LangchainEmbeddingsWrapper(OpenAIEmbeddings(model="text-embedding-ada-002"))
说明:
ChatOpenAI实例化 OpenAI 的 LLM,作为评估决策核心OpenAIEmbeddings实例化嵌入模型,负责语义向量转换LangchainLLMWrapper和LangchainEmbeddingsWrapper作为适配器,确保不同服务商模型与 Ragas 兼容
原理:Ragas 如何与模型交互
Ragas 通过封装器模式桥接内部评估逻辑与外部模型服务,实现跨平台兼容性。以下为交互流程示意:
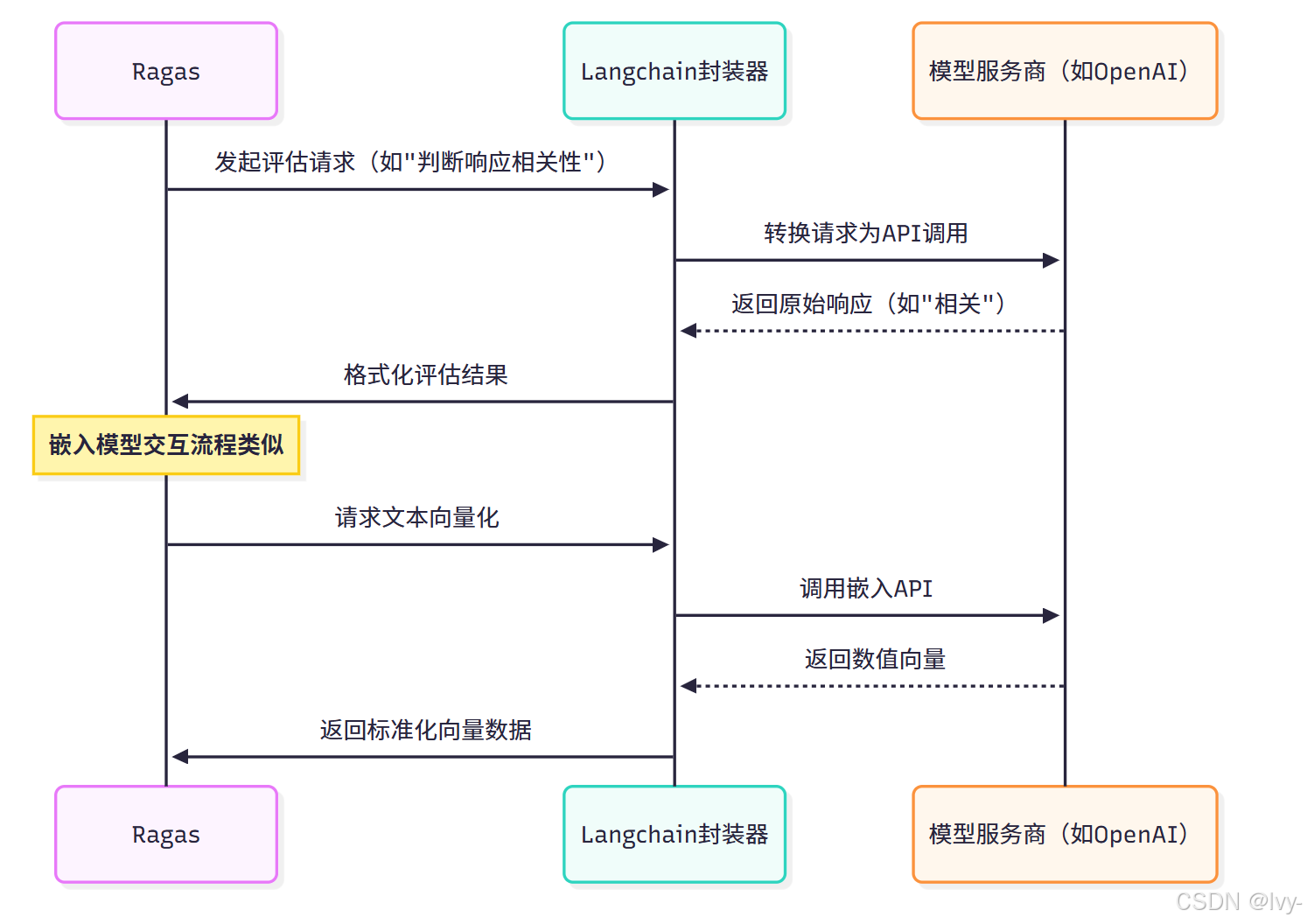
⭕Langchain 封装器
一个简化大模型(如GPT)调用流程的工具,将复杂的技术细节(如API连接、数据处理)打包成易用的接口,让开发者快速集成AI能力到应用中。
类比:像“充电器转换头”一样,让不同型号的充电器(模型)能适配同一插座(应用)。
代码层解析
Ragas 通过抽象基类定义统一接口,具体实现由封装器完成:
LLM 抽象基类(base.py)
# 简化自 ragas/src/ragas/llms/base.py
from abc import ABC, abstractmethod
class BaseRagasLLM(ABC):
@abstractmethod
def generate_text(self, prompt, n=1, temperature=1e-8) -> LLMResult:
"""同步生成文本"""
@abstractmethod
async def agenerate_text(self, prompt, n=1) -> LLMResult:
"""异步生成文本"""
Langchain 封装器实现
class LangchainLLMWrapper(BaseRagasLLM):
def __init__(self, langchain_llm):
self.langchain_llm = langchain_llm # 如ChatOpenAI实例
def generate_text(self, prompt, n=1, temperature=None):
return self.langchain_llm.generate_prompt([prompt], n=n)
同理,Embeddings 抽象类定义向量化接口,封装器将其转发至具体模型服务。
该设计使 Ragas 可灵活接入不同服务商,而无需修改核心逻辑。
小结
- LLMs 作为语言系统的核心,承担内容生成与质量评估双重职责
- Embeddings 将文本
映射至语义空间,实现计算机可处理的语义分析 - 封装器模式 使 Ragas 兼容多平台模型,保障评估流程的统一性
掌握这些基础后,我们已准备好探索如何通过提示词(Prompts)精确控制模型行为。下一章将深入 提示词工程,揭秘如何通过指令设计优化评估效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)