「手写大模型系列」(1)手写lora
LoRA(Low-Rank Adaptation)是一种高效的大模型微调方法,通过在原始权重矩阵上添加低秩补丁项(ΔW=AB)来调整模型参数。其中A和B是两个小规模可学习矩阵(r≪n,m),训练时仅更新这两个矩阵,冻结原始权重以节省资源。推理时可将补丁项合并回原始权重,不增加计算开销。该方法基于大模型参数空间冗余的假设,证明方向微调即可达到接近全参数微调的效果。代码实现上,通过自定义PyTorch
LoRA 原理简述
指在某些模块插入小规模可学习参数(Low-Rank),冻结原模型权重,减小训练开销。
任意一个矩阵我们都可以对它进行低秩分解,(在大模型中一般就是 QKV 层做 LoRA 或者 FFN 层做 LoRA)设原始权重矩阵为 W0∈Rn×mW_0 \in \mathbb{R}^{n \times m}W0∈Rn×m,
在训练时,为了节省资源,我们不更新它,而是在训练中添加一个 低秩补丁项 ΔW=AB\Delta W = ABΔW=AB:
Wnew=W0+αrAB W_{\text{new}} = W_0 + \frac{\alpha}{r} AB Wnew=W0+rαAB
其中:
- A∈Rn×rA \in \mathbb{R}^{n \times r}A∈Rn×r,B∈Rr×mB \in \mathbb{R}^{r \times m}B∈Rr×m,且 r≪min(n,m)r \ll \min(n, m)r≪min(n,m)
- α\alphaα 是缩放因子
- 训练时 只更新 A 和 B
- 推理时可以将 WnewW_{\text{new}}Wnew 合并为一个矩阵,提高速度
原论文中的图片如下: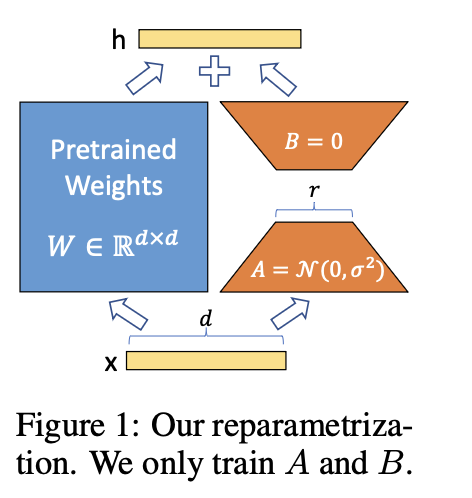
为什么可行?
LoRA 假设:
- 原始矩阵 W0W_0W0 并不需要完全变化,方向上的微调即可。
- 多数深度网络参数空间是冗余的。
- 在实际训练中,只需在低秩子空间中对参数做调整,就能达到接近全参数微调的效果。
代码实现
我们用 PyTorch 自定义一个 LoRA 的线性层来理解其核心机制:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class LinearLoRALayer(nn.Module):
def __init__(self,
in_features, # 输入特征维度
out_features, # 输出特征维度
merge=False, # 是否将 LoRA 参数合并进原始权重(用于推理)
rank=8, # LoRA 的秩(低秩矩阵维度)
lora_alpha=16, # 缩放因子
dropout=0.1, # dropout 比例(防止过拟合)
):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.merge = merge
self.rank = rank
# 原始 Linear 层(不包含 bias)
self.linear = nn.Linear(in_features, out_features)
if rank > 0:
# LoRA 参数 A:大小为 (out_features, rank),初始化为 0
self.lora_a = nn.Parameter(torch.zeros(out_features, rank))
# 使用 He(Kaiming) 初始化,推荐 a=0.01 (适用于 LeakyReLU)
nn.init.kaiming_normal_(self.lora_a, a=0.01)
# LoRA 参数 B:大小为 (rank, in_features),初始化为 0
self.lora_b = nn.Parameter(torch.zeros(rank, in_features))
# 缩放因子,防止 LoRA 输出过大
self.scale = lora_alpha / rank
# 冻结原始权重和 bias,避免它们在训练中被更新
self.linear.weight.requires_grad = False
self.linear.bias.requires_grad = False
# 可选的 dropout,用于抑制过拟合
self.dropout = nn.Dropout(dropout) if dropout > 0 else nn.Identity()
# 如果 merge=True,推理模式,初始化时就将 LoRA 权重合并进原始线性层
if merge:
self.merge_weight()
def forward(self, X):
# 输入 X 形状为 (batch, seq_len, in_features)
if self.rank > 0 and not self.merge:
# LoRA 推理公式: W0·x + α/r · (AB)x
# 其中 (AB)^T = B^T A^T,所以 X @ (AB)^T
output = self.linear(X) + self.scale * (X @ (self.lora_a @ self.lora_b).T)
else:
# 如果已经 merge 或者没有使用 LoRA,直接使用 linear
output = self.linear(X)
return self.dropout(output)
def merge_weight(self):
# 将 LoRA 权重合并进原始 linear 的权重中(推理加速)
if self.merge and self.rank > 0:
self.linear.weight.data += self.scale * (self.lora_a @ self.lora_b)
下面我们进行逐步解析(来自作者的白话解释):
- (1)我们首先来定义原始 Linear 层,这里也就是公式中的WWW,也就是下图的红框部分:
self.linear = nn.Linear(in_features, out_features)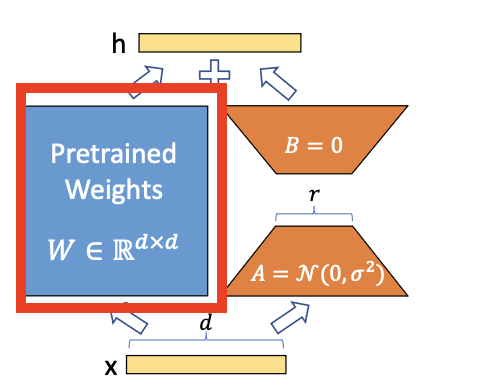
这部分不参与后续的梯度下降更新,因此我们把它的参数冻结:
# 冻结原始权重和 bias,避免它们在训练中被更新
self.linear.weight.requires_grad = False
self.linear.bias.requires_grad = False
-
(2)接下来定义A、BA、BA、B:
self.lora_a = nn.Parameter(torch.zeros(out_features, rank)) # 使用 He(Kaiming) 初始化,推荐 a=0.01 (适用于 LeakyReLU) nn.init.kaiming_normal_(self.lora_a, a=0.01) # LoRA 参数 B:大小为 (rank, in_features),初始化为 0 self.lora_b = nn.Parameter(torch.zeros(rank, in_features))这里的A是初始化为正态分布的,B的初始化是0。
-
(3)到了forward阶段
这里我们讲解一下merge这个标志位:
如果merge为True一般是代表推理状态,需要在初始化的时候把整个网络“组装好”,也就是这里:

防止每次推理时都要重新加上ABABAB,每次都重新加一遍ABABAB,但是ABABAB又没有变化,浪费时间。所以我们要在推理的时候,在初始化阶段就固定self.linear。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)