基于AI MCP协议, 写一个MCP服务用于连接数据库执行sql
它的核心功能是打通AI模型与外部工具、数据源的桥梁,让AI不仅能回答问题,还能直接调用API、操作本地文件、访问数据库等,实现自动化任务处理。简单的说, 它就相当于一个主板, 它可以插入各种各样的usb(工具, 服务, 接口), 然后经过cpu(ai)来分析上下文, 决定调用哪些usb来完成任务.废话不多说, 那如果我们希望ai能连接数据库, 做一些sql分析啊, sql执行啊, 这个usb(如果
现在ai使用越来越广, 很多地方都离不开ai.
最近接触学习了MCP这个工具, 感觉挺好用的.
看下MCP的介绍:
MCP(Model Context Protocol)是由人工智能公司Anthropic在2024年11月推出的一项标准化协议,旨在解决AI模型(如ChatGPT、Claude等)只能“对话”却无法“执行操作”的局限性。它的核心功能是打通AI模型与外部工具、数据源的桥梁,让AI不仅能回答问题,还能直接调用API、操作本地文件、访问数据库等,实现自动化任务处理。
类比理解:
如果AI模型是“大脑”,MCP则相当于“手和脚”,让大脑的指令能转化为实际动作。
类似于USB-C接口,MCP为不同工具和模型提供统一连接标准,避免重复开发。
简单的说, 它就相当于一个主板, 它可以插入各种各样的usb(工具, 服务, 接口), 然后经过cpu(ai)来分析上下文, 决定调用哪些usb来完成任务.
常用的主板(client) 目前有:Claude Desktop Cursor 编辑器,或其他兼容MCP的工具
废话不多说, 那如果我们希望ai能连接数据库, 做一些sql分析啊, sql执行啊, 这个usb(MCP TOOL)怎么实现.
我们新建一个python脚本
import json
from fastmcp import FastMCP
import pymysql
from pydantic import BaseModel
from typing import Dict, List, Optional
# 初始化MCP实例
mcp = FastMCP()
# 数据库连接配置(建议从环境变量加载)
DATABASES = {
"test": {
"host": "localhost",
"user": "test",
"password": "test123",
"port": 3306,
"charset": "utf8mb4"
},
"another": {
"host": "localhost",
"user": "another",
"password": "another123",
"port": 3307,
"charset": "utf8mb4"
}
}
class SQLRequest(BaseModel):
database: str
sql: str
@mcp.tool
def execute_sql(request: dict | str | SQLRequest) -> Dict:
"""
传入数据库名,和一个sql,然后可以在这个数据库中执行这个sql,并返回结果
Args:
request: {
"database": "database_name",
"sql": "SELECT * FROM table"
}
Returns:
{
"success": bool,
"data": list[dict] (for SELECT),
"affected_rows": int (for INSERT/UPDATE/DELETE),
"error": str (if failed)
}
"""
# 处理不同类型的输入
try:
if isinstance(request, str):
# 如果request本身是字符串
request_data = json.loads(request)
request_obj = SQLRequest(**request_data)
elif isinstance(request, dict):
# 如果request是字典
if 'request' in request and isinstance(request['request'], str):
# 如果字典中包含的request字段是字符串
request_data = json.loads(request['request'])
request_obj = SQLRequest(**request_data)
elif 'database' in request and 'sql' in request:
# 如果字典本身就包含database和sql字段
request_obj = SQLRequest(**request)
else:
return {"success": False, "error": "Invalid request format"}
elif isinstance(request, SQLRequest):
# 如果已经是SQLRequest对象
request_obj = request
else:
return {"success": False, "error": "Invalid request type"}
except json.JSONDecodeError:
return {"success": False, "error": "Invalid JSON string"}
except Exception as e:
return {"success": False, "error": f"Request parsing error: {str(e)}"}
# 对SELECT语句添加默认LIMIT 10限制
sql_query = request_obj.sql.strip()
if sql_query.upper().startswith("SELECT"):
# 检查是否已经包含LIMIT子句
if "LIMIT" not in sql_query.upper():
# 简单检查是否指定了全部数据("SELECT * ..."以外的情况)
# 如果没有LIMIT且是SELECT查询,则默认添加LIMIT 10
sql_query += " LIMIT 10"
# 参数验证
if request_obj.database not in DATABASES:
return {"success": False, "error": f"Database {request_obj.database} not configured"}
if not request_obj.sql.strip():
return {"success": False, "error": "SQL cannot be empty"}
# 获取配置
config = DATABASES[request_obj.database].copy()
config["database"] = request_obj.database
try:
# 建立连接
connection = pymysql.connect(**config)
with connection.cursor(pymysql.cursors.DictCursor) as cursor:
cursor.execute(request_obj.sql)
# 处理不同类型SQL的结果
# 判断是否为查询语句(SELECT, SHOW, DESCRIBE, EXPLAIN等)
upper_sql = request_obj.sql.strip().upper()
is_query = (upper_sql.startswith("SELECT") or
upper_sql.startswith("SHOW") or
upper_sql.startswith("DESCRIBE") or
upper_sql.startswith("EXPLAIN"))
if is_query:
return {
"success": True,
"data": cursor.fetchall()
}
else:
connection.commit()
return {
"success": True,
"affected_rows": cursor.rowcount
}
except pymysql.Error as e:
return {
"success": False,
"error": f"Database error: {str(e)}"
}
except Exception as e:
return {
"success": False,
"error": f"Unexpected error: {str(e)}"
}
finally:
if 'connection' in locals() and connection:
connection.close()
if __name__ == "__main__":
# 启动服务(与示例相同的配置风格)
# mcp.run(
# transport="streamable-http",
# host="0.0.0.0",
# port=8000,
# path="/sql-service"
# )
mcp.run(transport='stdio') # 启用调试模式
然后我们打开MCP的工具, 每个工具可能都不太一样, 如果是可视化的这种, 直接添加: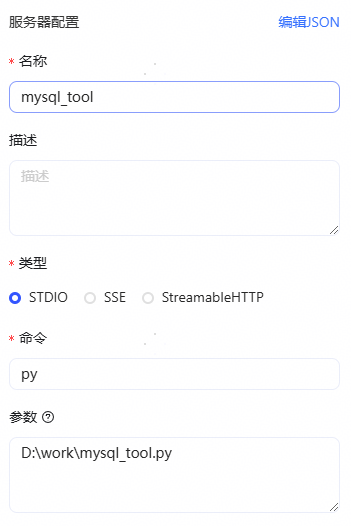
或者用json的方式配置:
{
"mysql_tool": {
"command": "py",
"args": [
"D:\\work\\mysql_tool.py"
],
"env": {}
}
}
这样的话, 在工具内, 选择我们的sql工具后, 输入比如 “我想知道xx表的前20条数据”, 或者"我想知道这个sql怎么优化", 就能获得我们想要的结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)