爆火的多模态大模型到底是什么?一文讲透概念、技术和应用
在人工智能领域持续创新发展的浪潮中,多模态大模型已成为备受瞩目的焦点,其独特的技术架构和强大的功能,为 AI 应用开拓了全新的维度。今天,让我们深入剖析多模态大模型,全面了解它的内涵、与传统大模型的差异、常见模型代表、应用场景及适用时机、关键技术、主要指标以及主流的开源模型。
在人工智能领域持续创新发展的浪潮中,多模态大模型已成为备受瞩目的焦点,其独特的技术架构和强大的功能,为 AI 应用开拓了全新的维度。今天,让我们深入剖析多模态大模型,全面了解它的内涵、与传统大模型的差异、常见模型代表、应用场景及适用时机、关键技术、主要指标以及主流的开源模型。
一、多模态的概念
多模态,英文为 Multimodal,指的是涉及多种模态信息的处理、融合与交互的技术和概念。这里所说的 “模态”,可以理解为信息的不同表现形式或来源,常见的包括文本、图像、音频、视频、手势、触觉等。
人类在日常生活中,就是通过多模态方式感知世界 —— 比如我们在看电影时,会同时接收画面(视觉模态 - 图像、视频)、台词(语言模态 - 语音、文本)、背景音乐(听觉模态 - 音频)等多种信息。多模态技术旨在让机器模仿人类,能够同时处理和理解多种类型的信息,打破单一模态的局限性,更全面、准确地认识和处理复杂的现实世界问题。
二、多模态大模型与常说的大模型的区别
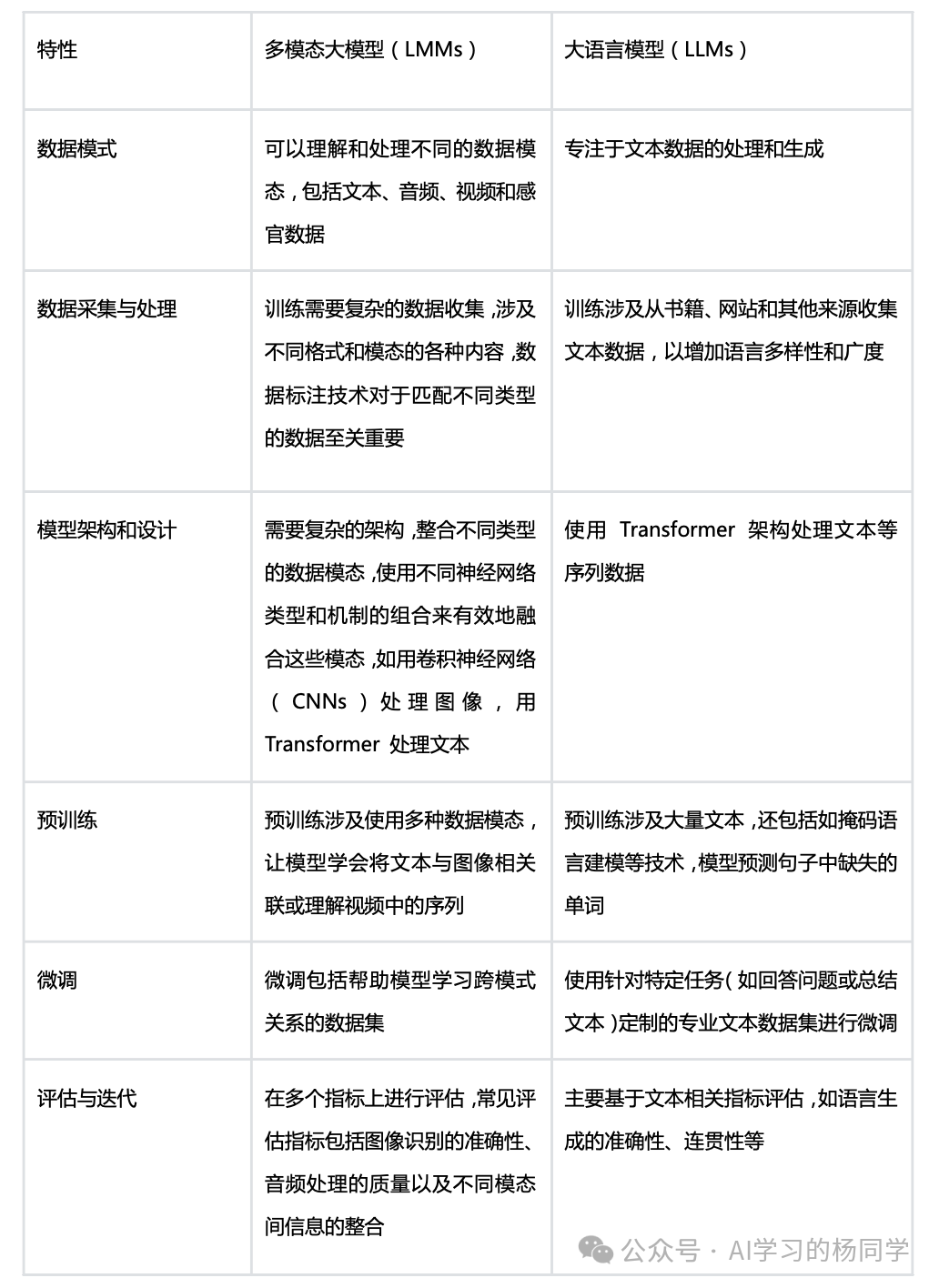
常说的大模型一般指大语言模型(LLMs,Large Language Models),比如 GPT-4 等。这类模型主要专注于文本数据的处理和生成,基于 Transformer 架构,通过对海量文本的学习,具备强大的语言理解和生成能力,能完成文本创作、知识问答、对话交互等任务。例如,给定一个主题,大语言模型可以生成一篇逻辑连贯的文章。
而多模态大模型(LMMs,Large Multimodal Models)则是在大语言模型基础上的扩展和升级,它能够同时理解和处理多种不同类型的输入数据模态,如文本、图像、音频、视频等。多模态大模型不仅可以处理文本,还能根据图像生成描述、根据语音指令完成任务、将视频内容转化为文字等。例如,当给多模态大模型一张猫的图片和 “描述这张图片” 的文本指令时,它可以输出 “这是一只毛色为橘白相间,眼睛又大又圆,正乖巧坐着的猫咪” 这样的描述。
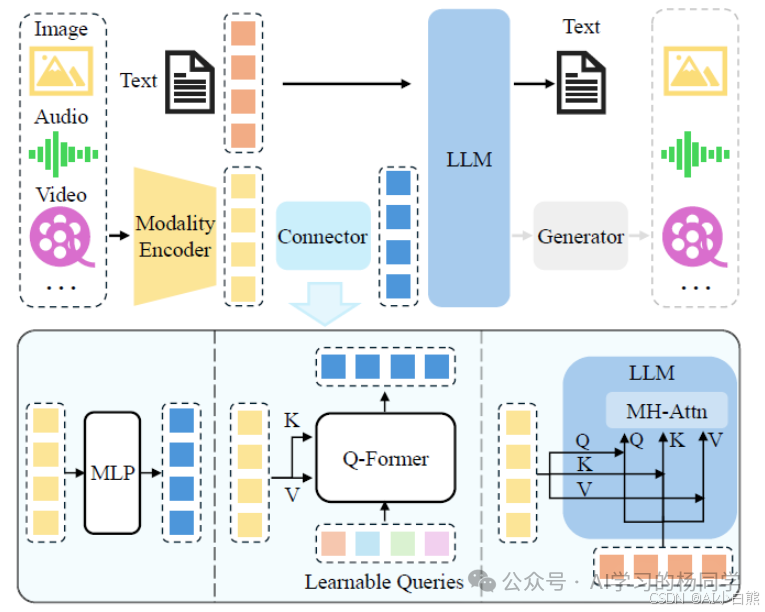
两者对比总结如下:
三、常见的多模态大模型
1. GPT-4V
OpenAI 的 GPT-4 模型升级版,“V” 代表视觉能力,增强了多模态能力,能处理和生成文本与图像信息。它还具备语音能力,可接收语音输入并转换为文本处理,能用多种类似人类的声音生成口头回应。例如在图像描述任务中,输入一张运动会的图片,它能详细描述运动员的动作、表情以及现场的氛围等。同时支持 26 种语言的多语言输入,在视觉问答、场景描述等多模态用例中表现出色。
2. GPT-4o
OpenAI 的最新多模态模型,能实时处理和生成文本、音频、图像和视频,将文本、视觉和音频能力整合到一个模型中。其对音频的反应速度极快,在推理和编码任务上表现优异,支持超过 50 种语言,并能在对话中无缝切换语言。相比 GPT-4 Turbo,它价格便宜 50%,速度快一倍,对开发者十分友好。为了安全考量,OpenAI 邀请外部红队做风险评估;还发布了轻量级版本 GPT-4o-mini,资源需求少但功能强于 GPT 3.5 Turbo.
3. Gemini
Google 开发的多模态 AI 模型,从设计之初就是本地多模态,在不同类型数据上进行预训练,可整合文本、图像、音频、代码和视频等多种模态。它有三个版本:Gemini Nano 是适用于移动设备的轻量级模型;Gemini Pro 能执行广泛任务,用于大规模部署;Gemini Ultra 是最大的模型,用于处理高度复杂、资源密集型任务,在 32 个广泛使用的评估基准中的 30 个上超越当前最先进结果。Gemini 具备创造性和表现力能力,如艺术和音乐生成、多模态叙事和语言翻译等,还能分析多个数据源以验证输出,其在 Massive Multitask Language Understanding (MMLU) 基准测试中得分 90%,是第一个超越人类专家的模型,并且与 Google 的工具、服务和广泛的知识库集成。
四、多模态大模型的应用场景及适用时机
多模态大模型的价值在于应对单模态技术难以处理的复杂场景,以下是典型应用场景及对应的使用契机:
(一)智能驾驶领域
适用时机:当驾驶环境感知需要结合视觉、传感器等多维度信息,且单一模态易受极端条件干扰时。
在自动驾驶场景中,多模态大模型融合摄像头图像(视觉模态)、激光雷达点云数据(传感器模态)以及 GPS 定位数据(位置信息模态)等。在雨雾天气或夜间场景下,单一摄像头易失效,雷达点云数据难以识别物体语义,而多模态模型通过时空对齐这些数据,增强对环境的感知。
(二)医疗诊断方面
适用时机:疾病诊断需结合影像、文本病历、生理数据等多源信息,且单一模态分析易导致漏诊时。
医学诊断依赖影像(CT、X 光等,视觉模态)、病历文本(文本模态)和生理数据(数据模态)等多源信息,单一模态分析易漏诊罕见病或复杂病变。多模态模型融合影像特征与患者病史进行综合推理。
(三)智能客服行业
适用时机:用户咨询涉及非文本信息(如图文故障描述),且纯文本交互无法满足精准沟通需求时。
用户咨询问题时常常涉及产品图片故障描述或操作视频(图像、视频模态),纯文本客服难以理解。多模态模型同步解析用户上传的图片 / 视频与文字描述,提供精准指导。
(四)内容创作产业
适用时机:内容生产需跨模态分析(如视频画面与文本弹幕结合),且单模态处理效率低下时。
在短视频内容创作和营销领域,多模态模型解析视频画面、语音解说及弹幕文本,生成营销策略。
五、多模态大模型的关键技术
多模态核心技术聚焦于实现跨模态信息的融合、理解与生成,核心目标是打破单一模态局限,让模型具备跨模态感知、推理和交互能力。
(一)模态表示学习
将文本、图像、音频等原始数据转化为计算机可理解的向量(Embedding),是多模态任务的基础。
单模态编码:文本用 BERT、GPT 等 Transformer 模型;图像用 ResNet、ViT 等 CNN 模型;音频结合梅尔频谱与 Wav2Vec 等;视频在图像编码基础上加入 3D CNN 等时序模型。
统一空间:通过对比学习(如 CLIP)、自监督学习,将不同模态特征映射到共享向量空间,使语义相似内容距离更近,如同将不同语言翻译成同一种语言。
(二)模态对齐
解决不同模态间的语义关联问题,找到信息对应关系。
细粒度对齐:文本与图像的 “区域 - 单词” 匹配(如 VisualBERT)、音频与视频的 “声音 - 动作” 同步(如演讲视频语音与唇动)。
全局对齐:通过余弦相似度等度量整体语义匹配度,或用对比损失函数让匹配样本距离更近、不匹配样本距离更远,类似建立 “图文对应字典”。
(三)模态融合
将不同模态特征有效结合,生成更全面的语义表示,按阶段分为:
早期融合:直接融合原始特征,保留细节但易受模态差异影响。
中期融合:对高层特征融合,常用特征拼接、注意力机制(聚焦相关特征)、门控机制(筛选重要特征)。
晚期融合:融合各模态任务输出结果,模态独立性强但丢失深层关联。
跨模态注意力:当前主流,如 Transformer 交叉注意力,让文本特征聚焦相关视觉信息(如 GPT-4 图文理解),类似不同烹饪顺序的 “什锦菜”。
(四)跨模态生成
从一种模态输入生成另一种模态输出,核心是保证内容准确性和一致性。文本到图像:如 DALL・E、Midjourney,基于扩散模型结合 CLIP 文本特征生成匹配图像。图像到文本:如图像描述(BLIP 模型),需完成物体识别与语义组织。音频到文本 / 图像:语音转文本并生成摘要,或根据环境音生成对应场景图像。多模态到多模态:如输入 “文本 + 图像” 生成 “视频 + 音频”,需保证时空一致性。
(五)其他关键技术
联合学习:迁移学习让模型从一种模态学到的知识辅助处理其他模态,如图像物体识别知识辅助文本理解。
模态转换:解决模态缺失问题,如无文本时从图像生成文本补充。
鲁棒性优化:减少模糊图像、含杂音音频等模态噪声的影响。
轻量化部署:通过知识蒸馏、量化等压缩模型,适应移动端等资源受限场
六、多模态大模型的主要指标
1. 准确性指标
在图像识别任务中,准确率是指模型正确识别图像中物体或场景类别的比例,计算公式为 “正确识别的样本数 ÷ 总识别样本数 ×100%”。例如在一个包含 100 张动物图片的测试集中,模型正确识别出 85 张,那么准确率就是 85%。在视觉问答任务中,答案准确率衡量模型回答问题的正确性,比如问 “图中有几只鸟”,模型回答正确的次数占总提问次数的比例就是该指标。
2. 召回率指标
在多模态信息检索任务中,召回率用于衡量模型能够检索到的相关信息占全部相关信息的比例,计算公式为 “检索到的相关信息数 ÷ 所有相关信息总数 ×100%”。比如从 100 条与 “人工智能发展” 相关的多媒体资料中,模型检索到 70 条,那么召回率就是 70%。召回率越高,说明模型找到的相关资料越全面。
3. BLEU(Bilingual Evaluation Understudy)得分
常用于评估多模态模型生成文本与参考文本的相似程度,特别是在图像描述生成等任务中。它通过计算生成文本与参考文本中 n-gram(连续的 n 个词)的重叠率来得出分数,得分范围在 0-100 之间,得分越高,表明生成的文本与参考文本越接近。例如生成的图像描述与人工撰写的参考描述重叠度越高,BLEU 得分就越高。
4. FID(Fréchet Inception Distance)
用于评估生成图像的质量,通过计算生成图像和真实图像在特征空间中的距离来衡量。距离越小,说明生成图像越接近真实图像。比如用模型生成一批 “猫” 的图像,将这些图像与真实的猫图像输入到预训练的 InceptionV3 模型中提取特征,再计算两者特征分布的 Fréchet 距离,这个距离就是 FID 值,FID 值越小,生成图像质量越好。
七、目前主流的开源多模态大模型
主流开源多模态大模型中,字节跳动BAGEL和蚂蚁联合研发的Ming-Omni表现突出。
-
BAGEL 为140亿参数(70亿活跃),采用MoT架构,双编码器捕捉图像像素与语义特征,性能媲美Gemini、GPT-4V,MME等榜单成绩优异,文生图质量接近SD3。电商场景中,其自动校验商品图文匹配,降本约30%,代码与模型已开源。
-
Ming-Omni 实现图、文、音、视频四模态统一处理,性能比肩GPT-4o。通过专用编码器提取特征,MoE架构(Ling模块)融合,混合线性注意力突破长上下文瓶颈。智能会议场景中,多模态协同处理使纪要效率升80%,遗漏率低于5%,代码与权重开源,降低中小企业开发门槛。
总结
多模态大模型融合了多种技术,打破了单一模态的局限,为人工智能的发展开辟了新的道路。从概念、与传统大模型的差异,到常见模型、应用场景及适用时机、关键技术、主要指标以及主流开源模型,它展现出了巨大的潜力和价值。然而,目前多模态大模型仍面临一些挑战,如模型的复杂性导致训练成本高、不同模态数据融合的精度和效率有待提升等。
未来多模态大模型的发展方向一是降低成本,通过创新架构和算法优化,使更多机构和个人能够参与研究和应用;二是提高融合精度,进一步完善多模态融合技术,提升模型对复杂信息的处理能力;三是拓展应用边界,在更多领域发挥作用,推动各行业的智能化变革。相信随着技术的不断进步,多模态大模型将为我们的生活和工作带来更多的惊喜和改变。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献186条内容
已为社区贡献186条内容

所有评论(0)