(!万字血书!)人工智能、AI基础:注意力机制---> 用“查词典”理解AI的“聚焦能力”
各位观众老爷,大家好,我是诗人啊_,今天和各位分注意力机制的理解,包简单, 包会的,一文速通~
(屏幕前的你,帅气低调有内涵,美丽大方很优雅…所以,求个点赞、收藏、关注呗~)
正经标题
目录1.1是结合注意力加Encoder-Decoder框架图解, 这部分理解起来会有一定难度, 建议顺序观看, 到1.1时快速过,或者跳过
目录
- 引言:为什么需要理解注意力机制?
1.1加Attention的Encoder-Decoder框架(用此框架帮助理解) - 核心问题:注意力机制到底在做什么?
- 生活化类比:用“查词典翻译”理解注意力机制
- 3.1 第一步:给词典“贴标签”(生成Key和Value)
- 3.2 第二步:明确“要查什么”(生成Query)
- 3.3 第三步:匹配标签算“相关度”(计算相似度与权重)
- 3.4 第四步:按相关度“挑重点”(加权Value求和)
- 3.5 完整流程演示:翻译“Tom chase Jerry”
- 类比对应模型术语:从生活到AI
- 总结:注意力机制的核心价值
- 作者有话说
1. 引言:为什么需要注意力机制?
在认识注意力之前,我们先简单了解下机器翻译任务:
- 例子:seq2seq(Sequence to Sequence))架构翻译任务
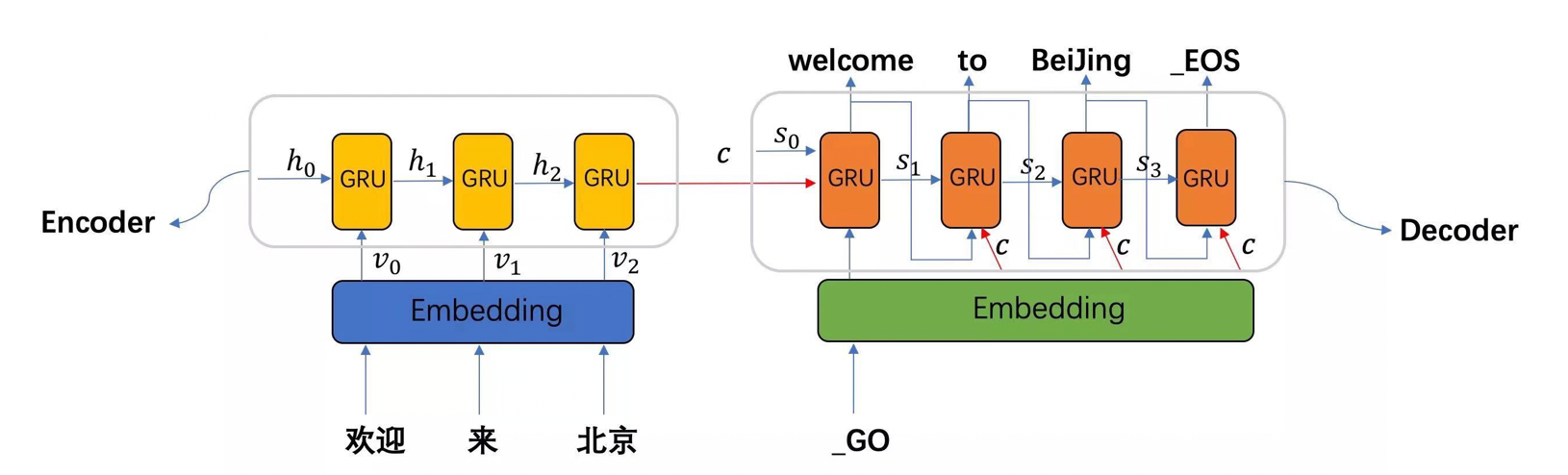
seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。
图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言
早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
- 问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
- 问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。
针对这样的问题,注意力机制被提出
- 注意力机制”实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分’’
举例说明:当我们看到下面这张图时,短时间内大脑可能只对图片中的“锦江饭店”有印象,即注意力集中在了“锦江饭店”处。短时间内,大脑可能并没有注意到锦江饭店上面有一串电话号码,下面有几个行人,后面还有“喜运来大酒家”等信息
- 所以,大脑在短时间内处理信息时,主要将图片中最吸引人注意力的部分读出来了,大脑注意力只关注吸引人的部分, 类似下图所示.

- 同样的如果我们在机器翻译中,我们要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。
回到主题----> 用“查词典”理解AI的“聚焦能力”
现在我们有个任务---->>> 翻译“Tom chase Jerry:
- 在生成(翻译)“汤姆”时,“Tom”最重要
- 在生成(翻译)“追逐”时,“chase”最重要
- 在生成(翻译)“杰瑞”时,“Jerry”最重要
如果AI“平均用力”,翻译结果会很糟糕。而注意力机制的作用,就是让AI学会“聚焦”——自动判断输入中哪些元素更重要,优先关注它们。
1.1 加Attention的Encoder-Decoder框架(用此框架帮助理解)
(ps: 此章节理解会有一定难度, 可能需要花费一定时间消化, 4. 生活化类比:用“查词典翻译”理解注意力机制)
举例说明,为何添加Attention:
比如机器翻译任务—> 输入source为:Tom chase Jerry, 输出target为:“汤姆”,“追逐”,“杰瑞”
在翻译“Jerry”这个中文单词的时候,普通Encoder-Decoder框架中,source里的每个单词对翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要
如果引入Attention模型,在生成“杰瑞”的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:(Tom,0.3)(Chase,0.2) (Jerry,0.5).每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。
因此,基于上述例子所示, 对于target中任意一个单词都应该有对应的source中的单词的注意力分配概率.而且,由于注意力模型的加入,原来在生成target单词时候的中间语义C就不再是固定的,而是会根据注意力概率变化的C,加入了注意力模型的Encoder-Decoder框架就变成了下图所示:
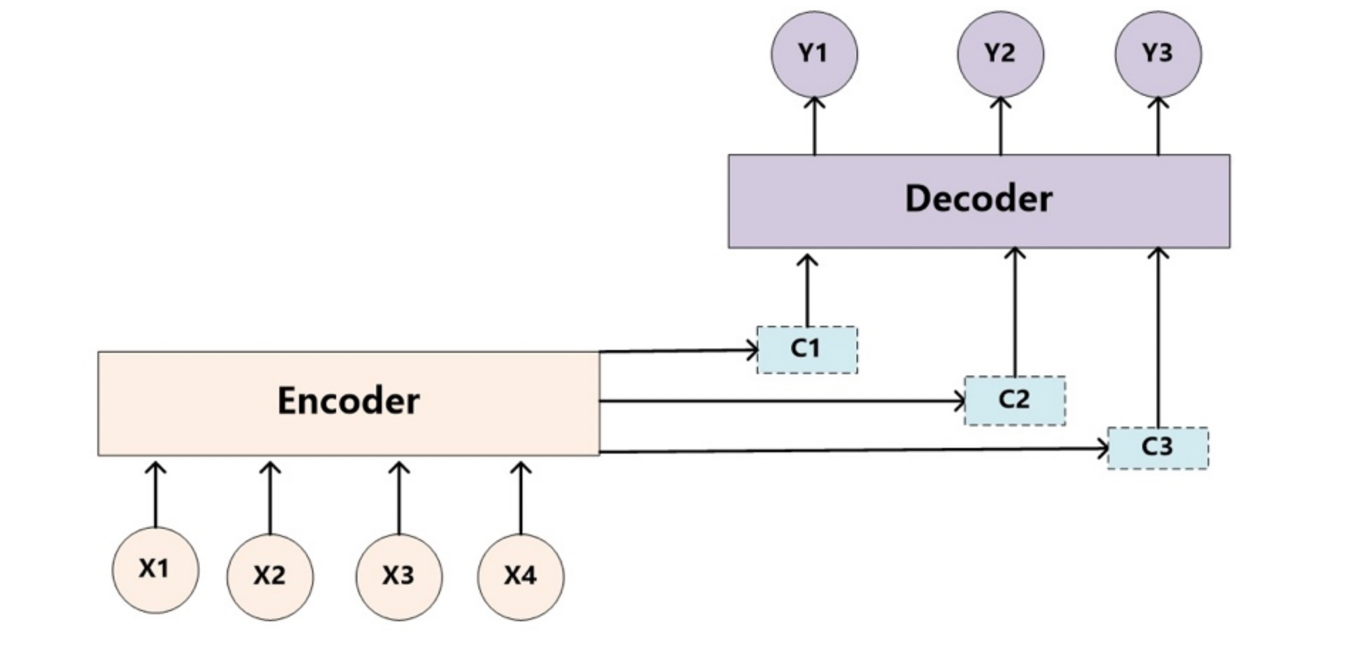
-
即生成目标句子单词的过程成了下面的形式:
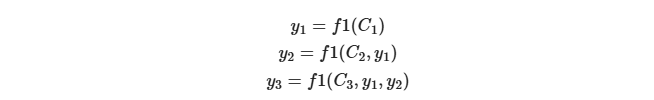
-
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
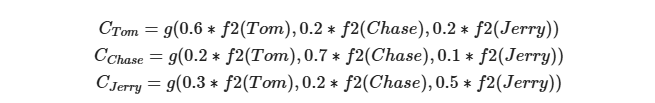
-
f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式
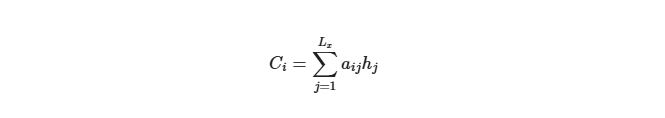
-
Lx代表输入句子source的长度, a_ij代表在Target输出第i个单词时source输入句子中的第j个单词的注意力分配系数, 而hj则是source输入句子中第j个单词的语义编码, 假设Ci下标i就是上面例子所说的’汤姆’, 那么Lx就是3, h1=f(‘Tom’), h2=f(‘Chase’),h3=f(‘jerry’)分别输入句子每个单词的语义编码, 对应的注意力模型权值则分别是0.6, 0.2, 0.2, 所以g函数本质上就是加权求和函数, 如果形象表示的话, 翻译中文单词’汤姆’的时候, 数学公式对应的中间语义表示Ci的形成过程类似下图:
-
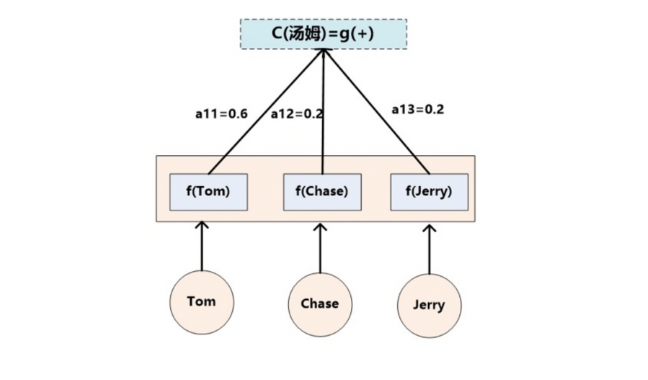
2. 核心问题:注意力机制到底在做什么?
简单说,注意力机制解决的是:
“在生成当前输出时,输入序列中哪些信息最关键?”
它通过一套计算逻辑,给输入序列的每个元素分配一个“关注度权重”,再根据权重提取关键信息,最终辅助生成更精准的输出。
3. 生活化类比:用“查词典翻译”理解注意力机制
我们用一个具体场景类比:假设你是翻译新手,要把英文句子“Tom chase Jerry”翻译成中文,手里有一本特殊的“双语词典”。整个过程和注意力机制的逻辑完全对应!
3.1 第一步:给词典“贴标签”(生成Key和Value)
拿到词典后,你先给每个英文单词做两件事:
- 写一个“特征标签”(方便快速匹配需求)
- 写一个“中文解释”(最终要用的内容)
对应到句子“Tom chase Jerry”:
| 英文单词 | 特征标签(Key) | 中文解释(Value) |
|---|---|---|
| Tom | 名字、主语、猫和老鼠里的猫 | 汤姆 |
| chase | 动词、动作、追赶 | 追逐 |
| Jerry | 名字、宾语、猫和老鼠里的老鼠 | 杰瑞 |
类比模型术语:这一步对应Encoder(编码器) 的工作——将输入序列的每个元素编码成Key(特征标签)和Value(语义内容)。
3.2 第二步:明确“要查什么”(生成Query)
开始翻译时,你会根据“翻译进度”和“当前需求”,明确自己“要查什么”。这个“查询需求”就是Query。
- 翻译第一个词时,你的需求是:“找句子的第一个词,应该是主语,可能是名字” → 这是Query1
- 翻译第二个词时,你的需求是:“前面翻了‘汤姆’,接下来应该是动词,表动作” → 这是Query2
- 翻译第三个词时,你的需求是:“前面是‘汤姆追逐’,接下来应该是宾语,可能是名字” → 这是Query3
类比模型术语:Query来自Decoder(解码器) 的当前状态,包含“历史翻译结果”和“当前生成需求”,类似RNN中的隐藏状态。
3.3 第三步:匹配标签算“相关度”(计算相似度与权重)
有了Query(查询需求),你会拿着它和词典里的每个Key(特征标签)比对,判断“相关度”:
-
翻译第一个词时(Query1:找主语、名字):
- 和Tom的Key比对:“完全匹配!” → 相关度得分:90
- 和chase的Key比对:“不匹配(是动词)” → 相关度得分:5
- 和Jerry的Key比对:“部分匹配(是名字但不是主语)” → 相关度得分:5
然后把得分转化为“权重”(总和为100%):
- Tom:90%(高权重,最相关)
- chase:5%(低权重)
- Jerry:5%(低权重)
类比模型术语:这一步对应相似度计算(如点积、余弦相似性)和Softmax归一化——将相关度得分转化为权重,确保总和为1。
3.4 第四步:按相关度“挑重点”(加权Value求和)
根据权重,你会重点看高权重单词的解释,忽略低权重的:
- 翻译第一个词时,90%关注Tom的Value(“汤姆”),5%关注其他 → 最终结果:“汤姆”
- 翻译第二个词时,90%关注chase的Value(“追逐”) → 最终结果:“追逐”
- 翻译第三个词时,90%关注Jerry的Value(“杰瑞”) → 最终结果:“杰瑞”
类比模型术语:这一步对应加权求和——用权重乘以对应的Value,得到融合了关键信息的“上下文向量”,用于生成当前输出。
3.5 完整流程演示:翻译“Tom chase Jerry”
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# -------------------------- 数据准备 --------------------------
# 源词汇表和目标词汇表(包含特殊符号)
# 源序列是 “输入”,模型只需要 “理解它的内容”,不需要标记开始和结束(因为模型会按顺序完整处理整个序列)
# 只在长度不足时用 <PAD> 填充,比如短句子补成长度一致的格式
source_vocab = {'Tom': 0, 'chase': 1, 'Jerry': 2, '<PAD>': 3}
target_vocab = {'汤姆': 0, '追逐': 1, '杰瑞': 2, '<SOS>': 3, '<EOS>': 4, '<PAD>': 5}
# 反向映射(用于结果解析)
source_idx2word = {v: k for k, v in source_vocab.items()}
target_idx2word = {v: k for k, v in target_vocab.items()}
# 输入输出数据(转为索引)
source_sentence = ['Tom', 'chase', 'Jerry']
# 目标序列是 “输出”,模型需要 “生成它”,必须明确 “从哪里开始” 和 “到哪里结束”。
# 固定格式:[<SOS>, 词1, 词2, ..., 词n, <EOS>]
target_sentence = ['<SOS>', '汤姆', '追逐', '杰瑞', '<EOS>']
source_indices = torch.tensor([source_vocab[word] for word in source_sentence]).unsqueeze(0) # 形状: [1, 3]
target_indices = torch.tensor([target_vocab[word] for word in target_sentence]).unsqueeze(0) # 形状: [1, 5]
# -------------------------- 模型定义 --------------------------
class AttentionRNN(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, embed_dim=16, hidden_dim=32):
super(AttentionRNN, self).__init__()
self.hidden_dim = hidden_dim
# 1. 嵌入层(将单词索引转为向量)
self.src_embedding = nn.Embedding(src_vocab_size, embed_dim, padding_idx=source_vocab['<PAD>'])
self.tgt_embedding = nn.Embedding(tgt_vocab_size, embed_dim, padding_idx=target_vocab['<PAD>'])
# 2. 编码器RNN(处理源句子)
self.encoder_rnn = nn.RNN(
input_size=embed_dim,
hidden_size=hidden_dim,
batch_first=True # 输入形状: [batch, seq_len, feature]
)
# 3. 解码器RNN(生成目标句子)
self.decoder_rnn = nn.RNN(
input_size=embed_dim + hidden_dim, # 输入 = 目标词嵌入 + 上下文向量
hidden_size=hidden_dim,
batch_first=True
)
# 4. 注意力机制(计算权重的线性层)
self.attention = nn.Linear(hidden_dim * 2, 1) # 输入: 编码器状态 + 解码器状态
# 5. 输出层(预测下一个单词)
self.output_linear = nn.Linear(hidden_dim, tgt_vocab_size)
def forward(self, src_seq, tgt_seq, teacher_forcing=True):
batch_size = src_seq.size(0)
tgt_seq_len = tgt_seq.size(1)
# -------------------------- 编码器 --------------------------
# 源句子嵌入: [batch, src_len, embed_dim]
src_embed = self.src_embedding(src_seq)
# 编码器输出: [batch, src_len, hidden_dim];最终隐藏状态: [1, batch, hidden_dim]
encoder_outputs, encoder_hidden = self.encoder_rnn(src_embed)
# -------------------------- 解码器 --------------------------
# 初始化解码器隐藏状态(用编码器最终状态)
decoder_hidden = encoder_hidden # [1, batch, hidden_dim]
# 存储输出和注意力权重
outputs = []
attn_weights_list = []
# 第一个输入是<SOS>(取tgt_seq的第0列)
current_input = tgt_seq[:, 0:1] # [batch, 1]
for t in range(tgt_seq_len - 1): # 生成到倒数第二个词(最后一个是<EOS>)
# 目标词嵌入: [batch, 1, embed_dim]
tgt_embed = self.tgt_embedding(current_input)
# ---------------------- 计算注意力权重 ----------------------
# 扩展解码器状态,与编码器输出形状匹配: [batch, src_len, hidden_dim]
decoder_hidden_expanded = decoder_hidden.permute(1, 0, 2).repeat(1, encoder_outputs.size(1), 1)
# 拼接编码器状态和解码器状态: [batch, src_len, 2*hidden_dim]
attn_input = torch.cat([encoder_outputs, decoder_hidden_expanded], dim=2)
# 计算注意力得分: [batch, src_len, 1]
attn_scores = self.attention(attn_input)
# 归一化得分得到权重: [batch, src_len, 1]
attn_weights = torch.softmax(attn_scores, dim=1)
attn_weights_list.append(attn_weights.squeeze(0)) # 存储权重
# 计算上下文向量(编码器输出 × 注意力权重): [batch, 1, hidden_dim]
context = torch.bmm(attn_weights.permute(0, 2, 1), encoder_outputs)
# ---------------------- 解码器前向传播 ----------------------
# 拼接目标词嵌入和上下文向量: [batch, 1, embed_dim + hidden_dim]
decoder_input = torch.cat([tgt_embed, context], dim=2)
# 解码器输出: [batch, 1, hidden_dim];更新隐藏状态
decoder_output, decoder_hidden = self.decoder_rnn(decoder_input, decoder_hidden)
# 预测下一个词: [batch, 1, tgt_vocab_size]
output = self.output_linear(decoder_output)
outputs.append(output.squeeze(1)) # 存储输出
# 确定下一个输入(教师强制或自己预测的词)
if teacher_forcing:
current_input = tgt_seq[:, t + 1:t + 2] # 用真实标签(教师强制)
else:
current_input = output.argmax(dim=2) # 用预测结果
# 拼接所有输出: [batch, tgt_seq_len-1, tgt_vocab_size]
outputs = torch.stack(outputs, dim=1)
return outputs, attn_weights_list
# -------------------------- 模型训练与测试 --------------------------
# 初始化模型、损失函数和优化器
model = AttentionRNN(
src_vocab_size=len(source_vocab),
tgt_vocab_size=len(target_vocab)
)
criterion = nn.CrossEntropyLoss(ignore_index=target_vocab['<PAD>']) # 忽略PAD符号
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练(简化版,实际需要多轮迭代)
model.train()
for epoch in range(100):
optimizer.zero_grad()
# 前向传播(使用教师强制)
outputs, _ = model(source_indices, target_indices, teacher_forcing=True)
# 计算损失(输出形状: [1, 4, 6];目标形状: [1, 4])
loss = criterion(outputs.squeeze(0), target_indices[:, 1:].squeeze(0))
# 反向传播
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch {epoch + 1}, Loss: {loss.item():.4f}")
# 测试
model.eval()
with torch.no_grad():
outputs, attn_weights = model(source_indices, target_indices, teacher_forcing=False)
# 取预测索引
predicted_indices = outputs.argmax(dim=2).squeeze(0).tolist()
# -------------------------- 结果展示 --------------------------
print("\n源句子:", source_sentence)
print("目标句子:", target_sentence[1:-1]) # 排除<SOS>和<EOS>
print("预测句子:", [target_idx2word[idx] for idx in predicted_indices[:3]]) # 取前3个有效词
# 打印注意力权重矩阵
print("\n注意力权重(行:目标词,列:源词):")
print("源词: ", source_sentence)
for i, (word, weights) in enumerate(zip(target_sentence[1:-1], attn_weights[:3])):
# 权重形状: [src_len, 1] → 转为列表
weights_np = weights.squeeze().detach().numpy()
print(f"{word}: {[f'{w:.4f}' for w in weights_np]}")
- 输出结果为:
Epoch 20, Loss: 0.0086
Epoch 40, Loss: 0.0020
Epoch 60, Loss: 0.0013
Epoch 80, Loss: 0.0011
Epoch 100, Loss: 0.0009
源句子: ['Tom', 'chase', 'Jerry']
目标句子: ['汤姆', '追逐', '杰瑞']
预测句子: ['汤姆', '追逐', '杰瑞']
注意力权重(行:目标词,列:源词):
源词: ['Tom', 'chase', 'Jerry']
汤姆: ['0.4371', '0.3895', '0.1733']
追逐: ['0.4371', '0.3895', '0.1733']
杰瑞: ['0.4371', '0.3895', '0.1733']
4. 类比对应模型术语:从生活到AI
| 生活场景(查词典翻译) | 注意力机制(AI模型) | 核心作用 |
|---|---|---|
| 英文单词的“特征标签” | Key(键向量) | 用于匹配Query,判断相关性 |
| 英文单词的“中文解释” | Value(值向量) | 存储核心信息,用于生成输出 |
| “当前要查什么”的需求 | Query(查询向量) | 代表当前生成目标,驱动注意力分配 |
| 标签匹配的“相关度” | 相似度得分 | 衡量Query与每个Key的关联程度 |
| 按相关度分配的“关注比例” | 注意力权重(Softmax输出) | 量化每个输入元素的重要程度 |
| 按比例整合的“翻译结果” | 上下文向量(加权Value求和) | 融合关键信息,辅助生成输出 |
5. 总结:注意力机制的核心价值
通过“查词典”的类比可以发现,注意力机制的本质是:
让AI像人一样,根据当前任务需求,动态聚焦于输入中最相关的信息
它解决了传统模型“平均用力”的问题,让AI在翻译、文本生成等任务中更精准。记住这个“查词典”的例子,再看复杂的公式和模型结构时,就能快速抓住核心逻辑了~
6. 作者有话说:
燃尽了,临时起意完成此文。或许存在逻辑不太自洽或引用错误的地方,如果有,请大家斧正。另外,各位观众老爷们,留个点赞、关注、不迷路呗~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)