论文reading学习记录6 - daily - MP3
文章目录
前言
最近越来越忙了,周末也加班,感觉又陷入了死命加班打补丁的恶性循环。但论文阅读绝不能落下,决定每天从早7点到中午粗颗粒度阅读一篇端方向论文,记录在此,先补充广度,再提高深度。
一、题目和摘要
MP3: A Unified Model to Map, Perceive, Predict and Plan
高清地图成本高,很难普及应用。我们提出了MP3,这是一种端到端的无地图驾驶方法。
输入:原始传感器数据和高级命令(例如,在十字路口左转)
MP3以在线地图的形式预测中间表示以及动态代理的当前和未来状态,并在一种新的神经运动规划器中利用它们做出考虑不确定性的可解释决策。
二、引言
现有无图技术的缺陷
1、大多数无地图方法[5,11,19,37,39]都侧重于模仿专家驾驶员的控制(例如转向和加速),而没有提供可以帮助解释自动驾驶车辆决策的中间可解释表示。
2、车道边界或车道中心线的检测方法过于简单,应用层面不够广泛
所以我们提出
1、使用一组概率空间层来模拟环境的静态和动态部分
静态环境:包含在一个以规划为中心的在线地图中,该地图捕获了关于哪些区域可以驾驶以及哪些区域在给定的交通规则下可以到达的信息。
动态环境:捕获在一个新的占用流(novel occupancy flow)中,该占用流提供了随时间变化的占用率和速度估计。
2、运动规划模块在不进行任何后处理的情况下利用这些表示。利用观测数据来检索动态可行的轨迹,在地图上预测一个空间掩模来估计给定抽象目标的路线,并直接利用在线地图和占用流作为可解释的安全计划的成本函数。
三、相关工作
1. 在线建图
离线测绘方法:依赖于卫星图像或使用数据收集车多次通过同一场景来收集密集的信息,并且通常需要有人参与。
在线预测地图方法:[16] [18] 提出了一种网络,可以从单个图像直接预测交通场景中车道的3D布局。[21]提出了一种分层递归神经网络,用于从激光雷达扫描中提取结构化车道边界。但这些都是诊断高速场景,可能会丢失宝贵的不确定性信息。
我们利用了不涉及信息丢失的地图的密集表示,适合在运动规划器中用作可解释的成本函数。
2. 感知和预测
我们在预测场景级表示时遵循[13,20,45,48,51]的规则,但提出了一种改进的占用流参数化,可以模拟多模态行为并提供一致的时间运动场。
3. 运动规划
从传感器数据直接生成控制命令的方法可能存在稳定性和鲁棒性问题。
最近,基于成本图的方法已被证明可以更好地适应具有挑战性的环境,通过在成本图上寻找局部最小值来恢复轨迹。而他们并没有明确预测静态和动态对象,因此缺乏安全性和可解释性。
相比之下,我们的自主模型利用从专家演示中检索来实现高效的轨迹采样器,该采样器不依赖于地图,根据概率地图预测和高级驾驶命令预测空间路线,并通过利用可解释的动态占用场作为场景自由空间和运动的总结来保持安全
四、可解释的无图导航
我们的模型产生了为安全规划、决策和可解释性而设计的中间表示。本节的其余部分,我们首先描述我们的骨干网络,该网络从原始传感器数据中提取有意义的几何和语义特征。然后介绍了我们的中间可解释表示。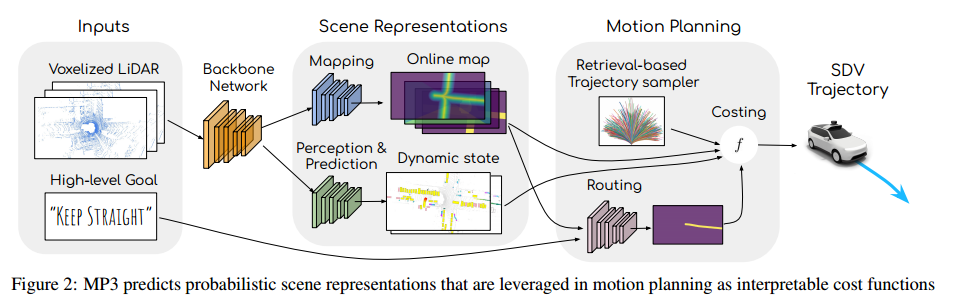
pipeline 图:MP3预测在运动规划中用作可解释成本函数的概率场景表示
1. 提取语义和几何特征
我们的模型利用激光雷达点云的历史,随着时间的推移从场景中提取丰富的几何和语义特征。根据[30],我们在鸟瞰图(BEV)中将Tp=10过去的LiDAR点云体素化,相当于1秒的历史,空间分辨率为a=0.2米/体素。
我们利用里程计来补偿SDV运动,从而在一个共同的坐标系中对所有点云进行体素化。我们感兴趣的区域是W=140m长(SDV前后70m),H=80m宽(SDV两侧各40米),Z=5m高。根据[9],我们沿着通道维度连接高度和时间,以避免使用3D卷积或循环模型,从而节省内存和计算。结果是一个大小为(H a,W a,Z a·Tp)的3D张量,它是我们骨干网络的输入。该网络结合了[9,52]中的思想来提取场景的几何、语义和运动信息。
2. 可解释的场景表示
人类驾驶员能够通过利用对交通规则和社会行为的先验知识。我们希望将这些先验知识纳入SDV的决策中。我们将预测静态环境称为在线地图,以及在我们的动态占用场中捕获的未来动态物体的位置和速度,如下所示: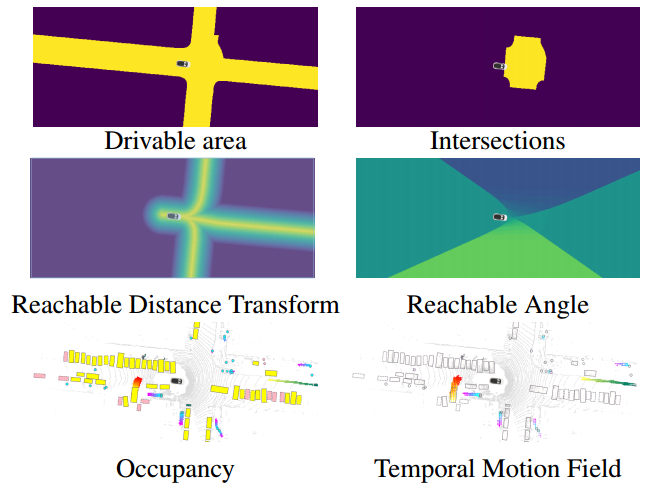
图3,1-4分别为:可行使区域、路口、可达距离转化、可达角度。上述均为可解释的场景表示。对于占用和运动,我们在同一图像中可视化所有时间步长和类别,以节省空间,并通过颜色进行区分。
由于传感器、遮挡和模型的限制,预测的在线地图和动态占用场不会完美,因此对不确定性进行推理以评估每种情况的风险非常重要。
接下来,我们首先描述世界可解释表示中的语义,然后介绍我们的概率模型。
1. 在线地图表示
为了安全驾驶,在BEV中对以下因素进行推理是有用的:
可行驶区域:允许车辆行驶的路面(或人行道),以路缘为界。
可达车道:车道中心线(或运动路径)定义为车辆行驶的标准路径,通常位于2个车道标记的中间。我们将可达车道定义为SDV可以到达的运动路径的子集。在规划轨迹时,我们希望SDV靠近这些可到达的车道,并按照它们的方向行驶。因此,对于地平面中的每个像素,我们预测到最近可达车道中心线的无符号距离,截断为10米,以及最近可达车道中线段的角度。
交叉口:可行驶区域,通过交通信号灯或交通标志控制交通。关于这一点的推理对于处理停车/让行标志和交通灯非常重要。如果交通灯是红灯,我们应该等待进入十字路口。根据[42],我们假设一个单独的基于摄像头的感知系统检测交通信号灯并识别其状态,因为这不是我们的重点。
2. 动态占用领域
作用:动态物体占据了哪个空间,以及这些物体如何随时间移动。
现有方案:基于激光雷达的精确物体探测器[25,34,52,55]来定位动态障碍物,然后是运动预测阶段[7,10,30,41,47]来预测每个物体的未来状态。但所有这些方法都包含不安全的离散决策。
置信阈值和非最大抑制(NMS)可以消除导致不安全情况的真实对象的低置信度预测。[45]提出了一种概率方法,通过利用世界的非参数空间表示来衡量给定SDV机动碰撞的可能性。这种计算与对象的数量无关。
然而,这种表示法不能提供速度估计,因此它不适用于跟车行为和速度相关的安全缓冲推理。此外,决策算法无法正确推理交互,因为对于给定的未来占用,其起源无法追溯。
相比之下,在本文中,我们提出了一种占用流,该占用流由当前世界状态下动态对象的占用率和未来的时间运动场参数化,描述了对象如何移动(以及它们未来的占用率),两者都被离散化为BEV上分辨率为0.4 m/像素的空间网格,如图4所示: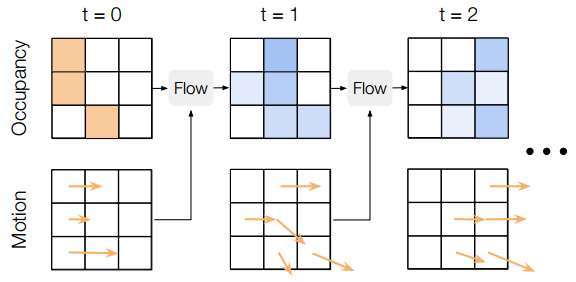
运动场随时间扭曲占用率。
透明度表示概率。色差——网络预测的层和未来的占用率。我们描述了单峰运动(K=1)的特殊情况。
- 初始占用:如果BEV网格单元的中心位于由对象形状及其当前姿态给出的多边形内部,则该单元处于活动状态(被占用)。
- 时间运动场:为未来特定时间占用的像素定义。每个被占用的像素运动都用2D BEV速度矢量(单位为m/s)表示。我们将这个运动场离散化为未来T=11个时间步长(每0.5秒最多5秒)。
由于SDV行为应适应不同类别的物体(例如,在行人和骑自行车的弱势道路使用者周围需要格外小心),我们将车辆、行人和自行车视为单独的类别,每个类别都有自己的占用流量。
3. 概率模型
我们想对在线地图和动态占用场中的不确定性进行推理。
为了实现这一目标,我们将在线地图M的每个语义通道建模为每个BEV网格单元的独立变量集合。这种假设使模型非常简单有效。为了简化表示法,我们使用字母i表示网格上的空间索引,而不是从现在开始的两个索引(行、列)。我们将可驾驶区域和交叉口通道中的每个BEV网格单元建模为伯努利。
3. 规划器
运动规划器的目标是生成安全、舒适且朝着目标前进的轨迹。
我们设计了一个基于样本的运动规划器,其中生成了一组运动学上可行的轨迹,然后使用学习到的评分函数进行评估。评分函数利用概率动态占用场对可能机动的安全性进行编码,鼓励避免占用区域的谨慎行为,并保持与SDV前方占用区域的安全前进。
我们在线地图中的概率层用于评分功能,以确保SDV在可驾驶区域行驶,靠近车道中心,方向正确,在不确定的地区保持谨慎,并朝着输入高级命令指定的目标前进。规划器并行评估所有采样轨迹,并选择成本最小的轨迹: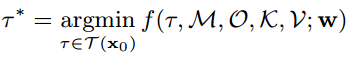
f为评分函数,w为模型的可学习参数,M为地图层,O、K、V分别为占用和运动模式概率和向量层,T(x0)表示根据SDV的当前状态生成的可能轨迹x0
1. 轨迹采样
车道中心和拓扑结构是构建SDV要执行的潜在轨迹的强先验。
当高清地图可用时,可以利用车道几何形状来指导轨迹采样过程。例如,一种流行的方法是在目标车道中心的Frenet坐标系中对轨迹进行采样,将采样限制在与所需车道偏差不大的运动[1,45,46,50]。
然而,在无地图驾驶中,我们需要采取不同的方法,因为高清地图不可用。因此,我们使用从真实轨迹的大规模数据集中检索。这种方法从专家演示中提供了大量轨迹,同时避免了随机采样或任意选择加速度/转向曲线[36,53]
我们通过基于SDV初始状态进行分箱,对每个分箱的轨迹进行聚类,并使用聚类原型来提高效率,从而创建了一个专家演示数据集。
2. 路线预测
假设我们得到一个驱动命令作为元组c=(a,d),其中a∈{保持车道,左转,右转}是一个离散的高级动作,d是到动作的近似纵向距离。这些信息类似于现成的基于GPS的导航系统为人类驾驶员提供的信息。为了模拟GPS误差我加噪声。我们将路线建模为伯努利随机变量的集合,BEV中的每个网格单元都有一个随机变量。给定驾驶命令c和预测图M,路由网络预测BEV中的密集概率图R。路由网络由3个CNN组成,它们充当可能的高级操作的交换机。请注意,只有与给定驾驶命令对应的一个CNN才会在推理时运行。结合预测的地图层,我们将动作的纵向距离d“光栅化”为一个额外的通道(即在空间上重复),并利用Coord-Conv[29]打破CNN的平移不变性。
3. 轨迹评分
我们使用以下成本函数的线性组合对采样轨迹进行评分。
道路上的路线和驾驶:为了鼓励SDV执行高级命令,我们使用了一个评分函数,鼓励在R中概率较高的区域行驶更长距离的轨迹。我们使用以下评分函数(类似LSS中的最小熵):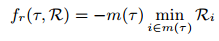
其中m(τ)是在轨迹τ中与SDV多边形重叠的BEV网格单元。此评分功能可确保SDV保持在路线上,并且仅在路线内移动时获得奖励。我们引入了一个额外的成本,该成本考虑了超出规划范围的预测路线。
当地平线尽头有转弯并且SDV速度很高时,这一点很重要。具体来说,我们计算了所有与SDV在轨迹视界之外重叠的BEV网格单元j的1-Rj的平均值,假设SDV保持恒定的速度和航向。
SDV在路上需要始终靠近可达车道的中心。因此,我们使用预测的可达车道距离变换MD来惩罚远处的轨迹点。为了在MD和Mθ存在高度不确定性时促进谨慎行为,我们使用了一个成本函数,该函数是SDV速度与MD和Mω中与SDV重叠的细胞概率分布的标准差的乘积。这促进了在地图不确定的情况下缓慢机动。
SDV还需要留在路上,避免侵占人行道或路缘。因此,我们使用预测的可行驶区域MA来惩罚偏离道路的轨迹: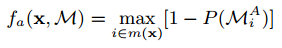
其中m(x)是在轨迹点x与SDV重叠的BEV网格单元集。同样,SDV需要避免,红绿灯路口。因此。我们使用预测的交叉口概率图MJ来惩罚违反红绿灯的机动行为,类似于路线成本。
4. 安全性
预测的占用层和运动预测用于对轨迹样本的安全性进行评分。我们惩罚SDV与被占领区域重叠的轨迹。对于每个轨迹点,我们使用与SDV多边形重叠的所有网格单元中概率最大的BEV网格单元,并将该概率直接用作碰撞成本。最大值运算符确保在SDV占用的区域内考虑最坏的占用情况
上述目标促进了不与被占领区域重叠的轨迹。但是,SDV还需要与SDV运动方向上的物体保持安全距离。该车头间距是SDV相对于其他物体的相对速度的函数。为了计算每个轨迹点x的成本,我们检索x处SDV前方的所有BEV网格单元,并测量是否违反了安全距离,如果每个网格单元处的物体以硬减速停止,并且状态为xt的SDV以舒适的减速反应。
舒适性:我们还惩罚颠簸、横向加速度、曲率及其变化率,以促进舒适驾驶
4. 训练
我们分两个阶段优化我们的驾驶模式。我们首先训练在线地图、动态占用字段和路线。
一旦这些部分收敛,在第二阶段,我们将这些部分保持不变,并训练评分函数线性组合的规划权重。我们发现,根据经验,这种两阶段训练比端到端训练更稳定:
1. 在线地图
我们在数据分布下使用负对数似然(NLL)训练在线地图。这意味着,高斯NLL用于可达车道距离变换MD,Von Mises NLL用于交通方向Mθ,二进制交叉熵用于可行驶区域MA和交叉口MJ。
可达车道:用高斯的负对数似然来训练 → 目标是让模型预测出车道的“距离场”越接近真实越好。
道路方向:用Von Mises分布的负对数似然(专门用来预测方向的概率分布)→ 训练目标是让预测方向接近真实方向。
可行驶区域/路口:用二分类交叉熵 → 判断一个位置是不是车能走的,预测值越接近真实越好。
2. 动态占用区域
为了了解动态对象在当前和未来的占用,我们采用交叉熵损失和硬负挖掘来解决数据中的高度不平衡问题(即大部分空间是空闲的)。为了学习概率运动场,通过分类交叉熵以无监督的方式学习运动模式K,其中真实模式被定义为相关运动向量最接近地面真实运动的模式ℓ2距离。然后,仅通过Huber损失训练来自真实模式的相关运动向量:
这是对场景中其他动态物体(如车辆、行人)的预测。
预测每个位置是不是被障碍物占用:用交叉熵损失(配合硬负样本挖掘,因为大部分地方是空的)。
对障碍物未来的运动方向预测:模型会生成多个运动模式(比如左转、右转、直行),然后:
选择与真实轨迹最接近的模式。
用Huber损失训练那个模式的运动向量 → 目标是让它的速度、加速度预测得更像真实。
3. 导航意图预测routing
我们用二进制交叉熵损失训练路由预测。为了学习更好的routing模型,我们对给定场景的所有可能命令进行监督,而不仅仅是SDV在观测数据中遵循的命令。这不需要额外的人工注释,因为我们可以从地面实况高清地图中提取所有可能的(命令、路线)对。
预测车应该走哪个方向(比如左转、直行、右转)。用二分类交叉熵来训练。
创新点在于:不仅学习车实际执行的指令,也同时学习所有可能执行的导航命令及其路径,这可以用已有地图自动生成,不需要额外人工标注。
4. 评分
由于在离散集中选择最小成本轨迹是不可微的,我们使用最大边际损失[40,45]来惩罚成本较小但与人类演示不同或不安全的轨迹。
这是模型从多个可能的轨迹中选一个最好的。
额外训练的目的:
因为选轨迹这个过程不是“连续的”而是“离散的”(选A不选B),不能直接用传统的梯度反向传播训练。
用最大间隔损失函数(max-margin loss)解决:
如果一个轨迹评分低但却不安全、和人类示范偏离大,就对它“惩罚”一下。所谓“惩罚”就是加一项损失值,让模型以后少选这样的轨迹。
训练总结:
第一阶段:先训练 在线地图、动态障碍物建模、导航意图预测。
第二阶段:冻结前面训练好的部分,只训练 轨迹评分模块(即最后从多个轨迹中挑一个的部分)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)