实现基于LangChain的RAG系统--学习笔记
本文介绍了LangChain框架及其在大语言模型应用开发中的优势,重点演示了如何基于LangChain实现RAG(检索增强生成)系统。
LangChain介绍
LangChain是什么?
LangChain 的作者是 Harrison Chase,最初是于 2022 年 10 月开源的一个项目。LangChain 目前是有两个语言版本(python 和 nodejs)。Langchain 作为一个大语言模型应用开发框架,解决了现在开发人工智能应用的一些切实痛点。
-
突破 LLM 原生能力限制,拓展应用边界
LangChain 支持长上下文管理(Memory)、与外部工具交互(Tool/Agent)、文档检索(Retriever)等能力,弥补 LLM 在实时性、私有性和多数据源接入等方面的不足。 -
模块化架构,提升复杂应用开发效率
它将 LLM 应用抽象为多个标准模块(如 Prompt、Chain、Memory、Retriever、Tool、Agent),开发者可灵活组合,避免重复造轮子,加速多样化场景的构建。 -
支持生产级部署,降低系统集成和运维成本
LangChain 提供 tracing、调试、异步执行、调用缓存等能力,并与 LangSmith、LangServe 等生态工具无缝集成,助力 AI 应用稳定落地
实现基于LangChain的RAG
1.导入库 & 环境初始化
视频中用的的通义千问的API,我用的OpenAI的API。
import streamlit as st
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.vectorstores import FAISS
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_functions_agent
import os
from dotenv import load_dotenv
load_dotenv(override=True)
2.加载 API 密钥与设置环境变量
openai_api_key = os.getenv("OPENAI_API_KEY")
#KMP_DUPLICATE_LIB_OK 避免某些MKL多线程报错
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
3. 初始化向量 Embedding 模型
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=openai_api_key
)
OpenAIEmbeddings:官方文档
LangChain 框架中集成 OpenAI 接口时用到的不同 模型功能模块(model wrappers)。它们分别代表 OpenAI 提供的不同类型的能力,LangChain 对这些能力做了统一封装和接口适配。
- chat_models:LangChain 封装类为 ChatOpenAI。背后调用的是 OpenAI 的 /v1/chat/completions 接口。
- llms:LangChain 封装类为 OpenAI。背后调用的是OpenAI 的 /v1/completions 接口。
- embeddings:LangChain 封装类为 OpenAIEmbeddings。背后调用的是OpenAI 的 /v1/embeddings 接口。
| 模块名 | LangChain类名 | OpenAI模型示例 | 接口类型 | 主要用途 |
|---|---|---|---|---|
chat_models |
ChatOpenAI |
gpt-3.5-turbo, gpt-4 |
chat/completions |
多轮对话、角色设定、Agent 系统 |
llms |
OpenAI |
text-davinci-003 |
completions |
单轮任务(摘要、问答、改写等) |
embeddings |
OpenAIEmbeddings |
text-embedding-ada-002 |
embeddings |
文本向量化、语义检索、相似度计算 |
4.处理 PDF 文本与向量化逻辑
def pdf_read(pdf_doc):
'''
逐页读取 PDF 内容并拼接。
'''
text = ""
for pdf in pdf_doc:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
def get_chunks(text):
'''
将长文本切片为多个段落(chunk),每段 1000 字,重叠 200 字。
'''
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_text(text)
return chunks
def vector_store(text_chunks):
'''
用 FAISS 建立向量索引,并保存到本地 `faiss_db/`。
'''
vector_store = FAISS.from_texts(text_chunks, embedding=embeddings)
vector_store.save_local("faiss_db")
RecursiveCharacterTextSplitter:递归字符文本切分器。核心思想是递归地尝试使用不同的分隔符来切割文本。它不像简单的字符分割器那样只使用一个固定的分隔符,而是会按照一个预设的列表,依次尝试不同的分隔符。
它的工作流程大致如下:
-
它有一个预设的 分隔符列表,比如 [“\n\n”, “\n”, " ", “”]。
-
它首先尝试使用列表中的第一个分隔符(例如,双换行符 \n\n)来分割文本。如果分割后的片段太长,它会进入下一步。
-
对于那些仍然太长的片段,它会递归地使用列表中的下一个分隔符(例如,单换行符 \n)再次进行分割。
-
这个过程会一直持续下去,直到所有片段都小于设定的最大长度,或者所有分隔符都已尝试完毕。如果到最后都无法分割,它会退回到最基本的字符分割。
FAISS:作为矢量数据库。 FAISS 是 Facebook AI Research 开发的一个库,用于高效相似性搜索和密集向量聚类。LangChain在第三方集成模块(Langchain_community)中已经接入了FAISS向量数据库
5.Agent对话链 + 工具调用(核心 RAG)
def get_conversational_chain(tools, ques):
#初始化 OpenAI 模型为 Agent。
llm = ChatOpenAI(model="gpt-3.5-turbo", openai_api_key=openai_api_key)
prompt = ChatPromptTemplate.from_messages([
(
"system",
"""你是AI助手,请根据提供的上下文回答问题,确保提供所有细节,如果答案不在上下文中,请说"答案不在上下文中",不要提供错误的答案""",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
tool = [tools]
#使用 LangChain 的 `create_tool_calling_agent` 构造 Agent,输入:prompt(你设定的系统角色);工具(retriever 工具)
# agent = create_tool_calling_agent(llm, tool, prompt)
#`AgentExecutor.invoke`:LangChain 自动判断是否调用工具,完成“读取上下文 → 查询 → 回答”流程。
# agent_executor = AgentExecutor(agent=agent, tools=tool, verbose=True)
agent = create_openai_functions_agent(llm, tool, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tool, verbose=True, handle_parsing_errors=True)
response = agent_executor.invoke({"input": ques})
print(response)
st.write("🤖 回答: ", response['output'])
6. 用户提问逻辑(调用 FAISS)
def user_input(user_question):
# 检查数据库是否存在
if not check_database_exists():
st.error("❌ 请先上传PDF文件并点击'Submit & Process'按钮来处理文档!")
st.info("💡 步骤:1️⃣ 上传PDF → 2️⃣ 点击处理 → 3️⃣ 开始提问")
return
try:
# 加载FAISS数据库
new_db = FAISS.load_local("faiss_db", embeddings, allow_dangerous_deserialization=True)
retriever = new_db.as_retriever()
retrieval_chain = create_retriever_tool(retriever, "pdf_extractor", "This tool is to give answer to queries from the pdf")
get_conversational_chain(retrieval_chain, user_question)
except Exception as e:
st.error(f"❌ 加载数据库时出错: {str(e)}")
st.info("请重新处理PDF文件")
7.检查数据库是否存在 本地是否已有向量化数据。
def check_database_exists():
"""检查FAISS数据库是否存在"""
return os.path.exists("faiss_db") and os.path.exists("faiss_db/index.faiss")
8.主界面逻辑(Streamlit)
def main():
st.set_page_config("🤖 LangChain RAG 紫了葡萄")
st.header("🤖 LangChain RAG 紫了葡萄")
# 显示数据库状态
col1, col2 = st.columns([3, 1])
with col1:
if check_database_exists():
pass
else:
st.warning("⚠️ 请先上传并处理PDF文件")
with col2:
if st.button("🗑️ 清除数据库"):
try:
import shutil
if os.path.exists("faiss_db"):
shutil.rmtree("faiss_db")
st.success("数据库已清除")
st.rerun()
except Exception as e:
st.error(f"清除失败: {e}")
# 用户问题输入
user_question = st.text_input("💬 请输入问题",
placeholder="例如:这个文档的主要内容是什么?",
disabled=not check_database_exists())
#提交 PDF 后执行的逻辑
if user_question:
if check_database_exists():
with st.spinner("🤔 AI正在分析文档..."):
user_input(user_question)
else:
st.error("❌ 请先上传并处理PDF文件!")
# 侧边栏
with st.sidebar:
st.title("📁 文档管理")
# 显示当前状态
if check_database_exists():
st.success("✅ 数据库状态:已就绪")
else:
st.info("📝 状态:等待上传PDF")
st.markdown("---")
# 文件上传
pdf_doc = st.file_uploader(
"📎 上传PDF文件",
accept_multiple_files=True,
type=['pdf'],
help="支持上传多个PDF文件"
)
if pdf_doc:
st.info(f"📄 已选择 {len(pdf_doc)} 个文件")
for i, pdf in enumerate(pdf_doc, 1):
st.write(f"{i}. {pdf.name}")
# 处理按钮
process_button = st.button(
"🚀 提交并处理",
disabled=not pdf_doc,
use_container_width=True
)
if process_button:
if pdf_doc:
with st.spinner("📊 正在处理PDF文件..."):
try:
# 读取PDF内容
raw_text = pdf_read(pdf_doc)
if not raw_text.strip():
st.error("❌ 无法从PDF中提取文本,请检查文件是否有效")
return
# 分割文本
text_chunks = get_chunks(raw_text)
st.info(f"📝 文本已分割为 {len(text_chunks)} 个片段")
# 创建向量数据库
vector_store(text_chunks)
st.success("✅ PDF处理完成!现在可以开始提问了")
st.balloons()
st.rerun()
except Exception as e:
st.error(f"❌ 处理PDF时出错: {str(e)}")
else:
st.warning("⚠️ 请先选择PDF文件")
# 使用说明
with st.expander("💡 使用说明"):
st.markdown("""
**步骤:**
1. 📎 上传一个或多个PDF文件
2. 🚀 点击"Submit & Process"处理文档
3. 💬 在主页面输入您的问题
4. 🤖 AI将基于PDF内容回答问题
**提示:**
- 支持多个PDF文件同时上传
- 处理大文件可能需要一些时间
- 可以随时清除数据库重新开始
""")
if __name__ == "__main__":
main()
9.运行程序
streamlit run test3.py
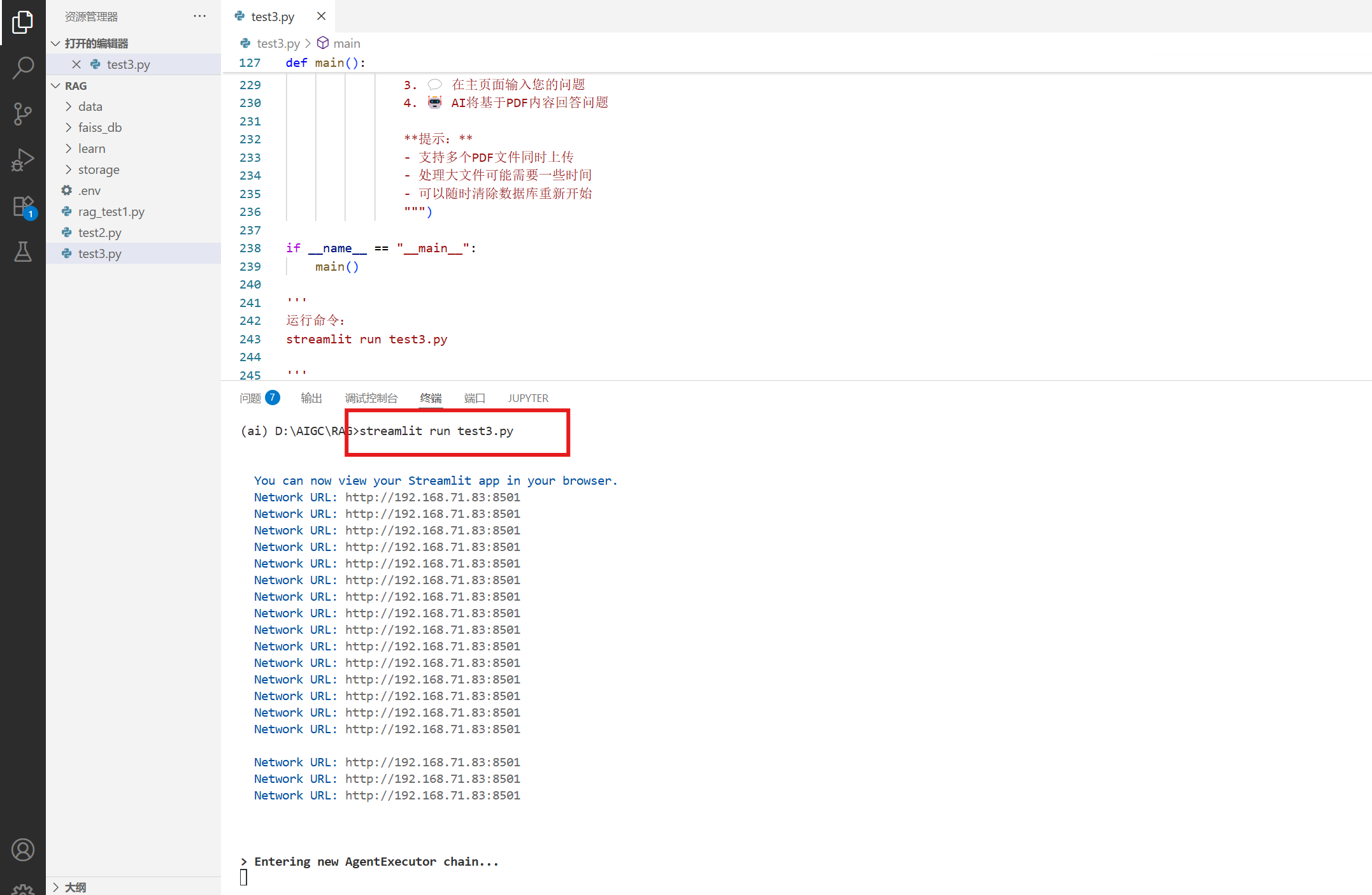
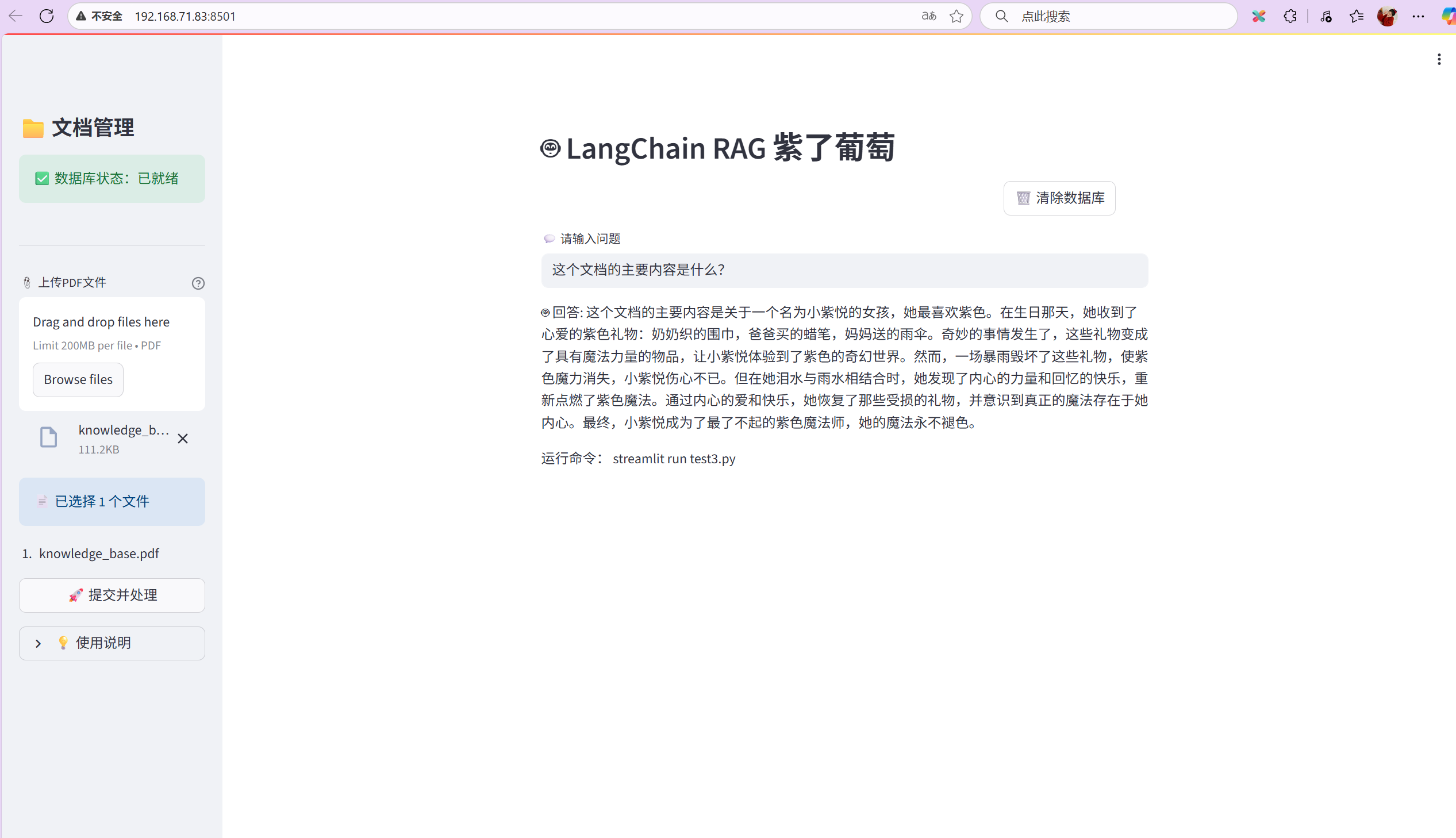

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)