大模型 Transformer模型(上)
这篇主要讲一下Transformer 框架搭建流程,苯人总结了一套:Dataprocess 数据处理 --》Position位置编码 --》Mask掩码 --》MHA多头注意力机制 --》FFN前馈神经网络 --》Encoder编码器 --》Decoder解码器 --》Transformer 模型构建 --》模型训练 --》模型预测。
目录
这篇主要讲一下Transformer 框架搭建流程,苯人总结了一套:
Dataprocess 数据处理 --》Position位置编码 --》Mask掩码 --》MHA多头注意力机制 --》FFN前馈神经网络 --》Encoder编码器 --》Decoder解码器 --》Transformer 模型构建 --》模型训练 --》模型预测
一、Dataprocess 数据处理
数据处理的基本流程就是:拿到文本序列(即任务设定,比如德英翻译)--》定义特殊符号 --》构建词表 --》将文本编码为整数序列 --》自定义数据集以及数据加载器 --》代码调试
代码如下:
import torch
import torch.utils.data as Data
#定义特殊符号
# S: decoding input 的开始符
# E: decoding output 的结束符
# P: padding的占位符
# 法语译英文
#第一列是编码器输入的原始文本序列,第二列是解码器的输入(S开头的译文),第三列是解码器的输出(E结尾的译文)
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
# 构建词汇表
#原始输入文本序列的词汇表
src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
src_vocab_size = len(src_vocab)
src_idx2word = {i: w for i, w in enumerate(src_vocab)}
#译文的词汇表
tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # enc_input最大序列长度(源序列长度)
tgt_len = 6 # dec_input(等于dec_output)最大序列长度(目标序列长度)
# Transformer 参数
d_model = 512 # 嵌入维度大小
d_ff = 2048 # 前馈网络的维度大小
d_k = d_v = 64 # K(等于Q)和V的维度大小
n_layers = 6 # 编码器和解码器层的数量
n_heads = 8 # 多头注意力机制中的头数
# 将传入编码器的文本转为数字序列
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
# 二维列表所以套两个循环
for i in range(len(sentences)):
enc_input = [src_vocab[n] for n in sentences[i][0].split()]
dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]
dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]
'''
首先len(sentences)为2,range(len(sentences))就是(0,2),所以i取0和1,分别表示sentences的第一行和第二行
然后比如sentences[i][0],当i=0时就取的是sentences的第0行第0列,也就是'ich mochte ein bier P'这句,用split按空格分隔后再用 for n 来取到每个词
最后 src_vocab[n]拿到每个词对应的索引,加入到创建的空列表,比如此时 enc_input = [1, 2, 3, 4, 0]
'''
enc_inputs.append(enc_input)
dec_inputs.append(dec_input)
dec_outputs.append(dec_output)
#最后转为张量
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences) #保证了三种数据的形状一致
# print(enc_inputs)
# print(enc_inputs.shape)
# 定义自定义数据集类 MyDataSet
#这里注意我们的数据集结构是:一条样本 = enc_input + dec_input + dec_output 这三部分组成的一套输入输出组
class MyDataSet(Data.Dataset):
#1、定义好数据放哪
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__() # 调用父类的初始化方法
#把三块输入保存下来,类似于装进一个大书包
self.enc_inputs = enc_inputs # 初始化编码器输入数据
self.dec_inputs = dec_inputs # 初始化解码器输入数据
self.dec_outputs = dec_outputs # 初始化解码器输出数据
# 2、告诉一共有多少条数据
def __len__(self):
return self.enc_inputs.shape[0] # 返回数据集样本数量,shape[0]表示有多少行,即多少条样本
#这里只返回 enc_inputs 的shape[0]是因为之前已经确定了三种数据的形状都是一致的,所以只用返回一组
# 3、告诉怎么拿到某一条数据
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx] # 获取指定索引处的样本数据
#比如 idx = 0,则第一条数据集中的样本就是:[1, 2, 3, 4, 0],[6, 1, 2, 3, 4, 8],[1, 2, 3, 4, 8, 7]
# 创建 DataLoader 对象 loader,用于批量加载数据
loader = Data.DataLoader(
MyDataSet(enc_inputs, dec_inputs, dec_outputs), # 自定义数据集对象作为数据源
batch_size=2, # 每个批次的样本数量
shuffle=True # 是否打乱数据集顺序,True 表示打乱
)
# 代码调试
if __name__ == '__main__':
for i, (src_seq, tgt_in_seq, tgt_out_seq) in enumerate(loader):
print(src_seq)
print(tgt_in_seq)
print(tgt_out_seq)
break相关介绍都写在注释里了
运行结果:

二、Position 位置编码
位置编码的代码其实是根据公式来的:
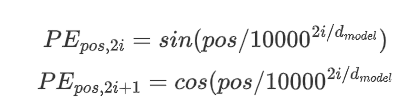
下面是一段模版代码:
# 定义一个位置编码类
import math
import torch
from torch import nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
:param d_model: 词向量的维度
:param dropout: 丢弃比例
:param max_len: 预定义一个最大序列长度
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 定义一个 Dropout 层,用于随机丢弃部分数据,防止过拟合
# 初始化位置编码矩阵 pe,用来保存每个位置的编码向量
pe = torch.zeros(max_len, d_model)
# # shape: (50, 1) * (256,) → (50, 256)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 生成位置的下标,shape: (max_len, 1),升维是为了后面好广播
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # 计算分母项
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用 sin 函数编码位置信息
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用 cos 函数编码位置信息
pe = pe.unsqueeze(0) # 转置并增加一个维度,shape: ( 1, max_len,d_model)
self.register_buffer('pe', pe) # 将位置编码矩阵 pe 注册为模型的缓冲区,不算模型的参数,但希望它随着模型保存、加载
def forward(self, x):
'''
x: [batch_size, seq_len, d_model]
'''
x = x + self.pe[:,:x.size(1), :] # 将输入张量 x 与位置编码矩阵 pe 相加,根据输入序列长度截取对应位置编码
return self.dropout(x) # 对相加后的张量进行 Dropout 操作并返回
# 测试代码
if __name__ == '__main__':
pe = PositionalEncoding(d_model=512)
embed = torch.randn(5, 10, 512)
out = pe(embed)
print(out)
print(out.shape) #torch.Size([5, 10, 512])这里我就直接用老师发的模版代码了 (๑•̀ㅂ•́)و✧
三、Mask 掩码
掩码的两个作用:一个是为了掩盖之前为了固定长度而填充的0(填充掩码),一个是为了掩盖未来的信息(未来掩码),这里详细解释一下未来掩码的原理:
在利用公式计算出注意力分数后(经过softmax激活函数之前)模型会应用一个上三角矩阵,这个上三角矩阵的值通常为负无穷,与原注意力分数相加再经过激活函数后会变为0,下一步在与 V 相乘后得到的实际值仍为0,即不会保留这部分的信息,过程大概如下:

这里解释一下为什么是上三角矩阵呢,是因为这里把“未来”定义成“当前位置右边的 token”,所以就遮住的是上三角部分。
代码如下:
"""
构建所需要的掩码
每个attention都需要mask,只是不同部分所需要的Mask不同
"""
import numpy as np
import torch
def att_pad_mask(seq_k, seq_q):
"""
填充掩码
特别情况:交叉注意力机制
:param seq_k: [b,n1] tensor([[1, 2, 3, 4, 0],[1, 2, 3, 5, 0]])
:param seq_q: [b,n2]
:return:数据格式【b,n2,n1]
"""
batch_size, len_q = seq_q.size()
# 跟sk里面每个数据比较 为0返回True
mask = seq_k.eq(0).unsqueeze(1) # 形状由 [b,n1] -- > [b,1,n1]
mask = mask.repeat(1, len_q, 1) # 【b,n2,n1]
return mask #形状 [batch_size, len_q, len_k] 的布尔矩阵
def att_sub_mask(seq):
"""
未来掩码
:param seq: [b,n]
:return: [b,n,n]
"""
att_shape = [seq.size(0), seq.size(1), seq.size(1)] #构造形状为[batch_size, n, n] 的 mask
sub_mask = np.triu(np.ones(att_shape), k=1) #构建一个上三角矩阵
sub_mask = torch.from_numpy(sub_mask).byte() #从 NumPy 转换为 PyTorch
return sub_mask #输出形状为[batch_size, n, n],未来位置是 1(True),当前和过去是 0(False)
# 测试数据
if __name__ == '__main__':
import torch
seq_q = torch.tensor([[1, 2, 3, 0], [1, 2, 3, 0]])
seq_k = torch.tensor([[1, 2, 3, 0], [1, 2, 3, 0]])
print(att_pad_mask(seq_q, seq_k))
re1 = att_pad_mask(seq_q, seq_k) #填充掩码
print(att_sub_mask(seq_q))
re2 = att_sub_mask(seq_k) #未来掩码
# 合并掩码,如果某位置为0,表示“既不是pad,也不是未来”,是可以看的;否则是要mask掉的
# gt的作用是只要不是0,就返回True,即为要遮住的地方
mask_self = torch.gt((re1 + re2), 0)
print(mask_self)运行结果这里就不贴了,可自行运行
四、MHA 多头注意力机制
多头注意力机制(Multi-Head Attention)是 Transformer 模型中的核心结构,它的设计灵感来自人类“关注多个事物不同方面”的能力,简单来说,它的本质是:在同一个输入上,设置多个“注意力头”来并行地捕捉不同的语义特征或关系。每一个注意力头其实就是一个缩小版的“注意力机制”,它会独立地去计算输入序列中各个位置之间的依赖关系,当然最后会将每个头的结果合并起来然后返回。
实现代码如下:
'''
封装注意力机制 :多头注意力结构+交叉输入 = 多头交叉注意力机制
'''
import math
import torch
from torch import nn
#单头注意力机制 Attention类,实现注意力得分的计算
class Attention(nn.Module):
"""
注意力分数计算公式:Q * K的转置 / 根号下dk
"""
def __init__(self,dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.softmax = nn.Softmax(dim=-1)
def forward(self,q,k,v,mask=None):
# 按照公式算注意力机制
scores = torch.matmul(q,k.transpose(-1,-2))/math.sqrt(k.size(-1))
# 判断掩码
if mask is not None:
# 根据mask判断哪个值是true 然后乘以-1e9,一个超大负数
scores = scores.masked_fill_(mask, -1e9)
#注意力得分经过softmax激活函数
att = self.softmax(scores)
#拿到最终加权的实际值
output = torch.matmul(att,v)
return self.dropout(output)
#多头注意力机制 MultiHeadAttention类,分成多个头,每个头都调用Attention类,最后合并结果
class MultiHeadAttention(nn.Module):
def __init__(self,d_model,num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model//num_heads #每个头的维度
#初始化权重矩阵
self.Wq = nn.Linear(d_model,d_model)
self.Wk = nn.Linear(d_model,d_model)
self.Wv = nn.Linear(d_model,d_model)
self.Wo = nn.Linear(d_model, d_model)
self.attention = Attention()
self.dropout = nn.Dropout(0.1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self,enc_inputs,dec_inputs,mask=None):
res = dec_inputs
# 交叉输入:这里要注意 Q是来自解码器,K、V来自编码器
q = self.Wq(dec_inputs)
k = self.Wk(enc_inputs)
v = self.Wv(enc_inputs)
# 多头的实现,实际就是拆分QKV
Q = q.view(q.size(0),-1,self.num_heads,self.d_k).transpose(1,2)
K = k.view(k.size(0),-1,self.num_heads,self.d_k).transpose(1,2)
V = v.view(v.size(0),-1,self.num_heads,self.d_k).transpose(1,2)
# 处理mask的维度:[b,n,n]--->【b,h,n,n】,确保每个头都能使用
# repeat 是重复几次的方法
if mask is not None:
mask = mask.unsqueeze(1).repeat(1,self.num_heads,1,1)
# 计算注意力 形状是:[batch, heads, seq_len, d_k]
output = self.attention(Q,K,V,mask)
# 多头处理
#首先合并多个头,形状变回来:[batch, heads, seq_len, d_k] → [batch, seq_len, heads * d_k]
output = output.transpose(1,2).contiguous().view(output.size(0),-1,self.d_model)
output = self.Wo(output) #恢复为 d_model 的 shape
output = self.dropout(output)
output = self.layer_norm( output+ res) #残差连接+层归一化
return output
if __name__ == '__main__':
# 测试
# 上个代码生成的掩码
mask = [[[False, True, True, True],
[False, False, True, True],
[False, False, False, True],
[False, False, False, True]],
[[False, True, True, True],
[False, False, True, True],
[False, False, False, True],
[False, False, False, True]]]
mask = torch.tensor(mask)
mha = MultiHeadAttention(d_model=512,num_heads=8)
#输入:[batch=2, seq_len=4, d_model=512]
enc_inputs = torch.randn(2,4,512)
dec_inputs = torch.randn(2,4,512)
output = mha(enc_inputs,dec_inputs,mask)
print(output.shape) #torch.Size([2, 4, 512])可以看到最后的数据形状还是与输入一样,只是表达效果更强了
五、FFN 前馈神经网络
前馈神经网络(Feed-Forward Neural Network, FFN)是一种基础构建模块,像一个勤劳的“信息加工厂”,通过多层线性变换和非线性激活函数,将输入数据逐层加工成更有意义的表示,一般是像个三明治一样两个线性层中间夹一层激活函数,具体代码如下:
"""
搭建FFN子层
"""
import torch
from torch import nn
#全连接前馈网络 像三明治一样两个线性层中间夹一层激活函数
class FFN(nn.Module):
def __init__(self,d_model,d_ff):
super(FFN, self).__init__()
self.ffn = nn.Sequential(
nn.Linear(d_model,d_ff), #把输入维度从 d_model(通常是512)升维到 d_ff(通常是2048)
nn.ReLU(), #激活函数
nn.Dropout(0.1),
nn.Linear(d_ff,d_model) #把维度从 d_ff 降回 d_model
)
self.dropout = nn.Dropout(0.1)
self.layer_norm = nn.LayerNorm(d_model) #层归一化
def forward(self,x):
res = x #保留原始输入
x = self.ffn(x) #传入三明治ffn网络
x = self.dropout(x)
output = self.layer_norm(x+res) #x+res 形成残差结构,再送入层归一化
return output
# 测试数据
if __name__ == '__main__':
batch_size = 2
seq_len = 4
d_model = 512
d_ff = 2048
ffn = FFN(d_model,d_ff)
x = torch.randn(batch_size,seq_len,d_model)
output = ffn(x)
print(output.shape) #torch.Size([2, 4, 512])同样输出形状不变
因为文本与时间原因暂时写一半,剩下的下篇继续 (๑•̀ㅂ•́)و✧
以上有问题可以指出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)