从线性回归到大模型落地的血泪通关手册,你准备好避坑了吗?
先问业务“
文章概要
作为一名在机器学习领域摸爬滚的程序猿”,我将带你从最简单的线性回归出发,一路拆解机器学习核心范式,再无缝衔接到大模型时代最热门的RAG检索增强、Agent智能体与MCP模型上下文协议,帮你一次性避开学术研究与工业落地中的高频深坑。
“我跑通了线性回归,结果上线当天把老板气到摔键盘——模型预测房价 1.2 亿/㎡,原因是把‘阳台数量’当连续值,0.5 个阳台被它当成半个阳台,直接乘了个 10 倍系数。”
别笑,这就是我第一次把模型搬出 Jupyter 的真实惨案。今天,我把踩过的坑都画成一张“全景避坑地图”,保你少走弯路,多活几年。
线性回归:看似简单却暗藏玄机的起点
你以为的线性回归
y = wx + b,一条直线搞定天下。
实际上的线性回归
- 特征尺度不统一:把“面积(㎡)”和“离地铁距离(米)”直接丢进去,梯度下降像喝醉的企鹅,左摇右晃。
- 离群点暴击:北京二环里突然出现一套 300 ㎡地下室,模型瞬间“追星”,斜率直奔银河系。
- 多重共线性:房间数和卫生间数高度相关,系数符号一会儿正一会儿负,解释时像极了渣男语录——“我不是不爱你,我只是被别的特征干扰了”。
避坑清单
| 坑位 | 症状 | 解药 |
|---|---|---|
| 特征尺度 | 系数大小差 1000 倍 | StandardScaler 先洗澡 |
| 离群点 | R² 忽高忽低 | RobustScaler + RANSAC 组合拳 |
| 共线性 | VIF > 10 | PCA 或正则化(Ridge/Lasso) |
分类任务:准确率≠业务价值,评估指标如何选?
“模型准确率 96%,老板却把我骂哭:原来 4% 的误报把 200 万条正常短信标成垃圾,用户投诉到工信部。”
场景一:垃圾短信拦截
- Precision(精准率):宁可放过一千,不可错杀一个。
- Recall(召回率):宁可错杀一千,不可放过一个。
- F1:老板看不懂,你就说“综合得分”。
场景二:信贷违约预测
- ROC-AUC:画条曲线给风控看,越靠近左上角越好。
- KS 值:风控最爱,>0.3 才能上线。
一句话总结:先问业务“错杀和漏杀哪个更贵”,再选指标,别让 96% 的准确率成为你的 KPI 杀手。
聚类算法:K-Means不是万能钥匙,如何验证聚类效果?
K-Means 的 3 个灵魂拷问
- K 怎么定?
- 肘部法:画个折线图,假装能看到“肘”。
- 轮廓系数:>0.5 才算“人模人样”。
- 初始质心随机?
- 跑 10 次 k-means++,选最好那次,别让结果像抽盲盒。
- 非球形簇怎么办?
- 换 DBSCAN(密度聚类),专治“月牙形”数据。
验证聚类效果的 3 板斧
- 业务可解释性:簇 0 全是“高消费低活跃”,簇 1 全是“羊毛党”,老板秒懂。
- 外部指标:如果有标签,用 Adjusted Rand Index;没标签,用 Silhouette Score。
- 可视化:t-SNE 降维后画图,一眼看出簇边界是不是“狗啃的”。
可解释性:黑盒模型VS白盒模型,如何向老板讲清楚?
黑盒模型(XGBoost、深度森林)
- SHAP 值:把每个特征贡献画成“瀑布图”,老板看到“房价被阳台数量拉高 30 万”,立刻点头。
- LIME:局部解释,像给模型做“胃镜”——“这套房贵,主要因为学区”。
白盒模型(线性回归、决策树)
- 系数符号:正的就吹“正向贡献”,负的就甩锅“市场规律”。
- 决策路径:树模型直接打印 if-else,老板拿着就能去讲故事。
终极话术
“老板,这个黑盒模型虽然复杂,但我用 SHAP 解释过了,学区、地铁、阳台 三大因素占 80% 权重,和您的直觉完全一致!”
5大高频坑位盘点:数据泄漏、特征穿越、过拟合、样本不平衡、评估作弊
| 坑位 | 事故现场 | 一键自救 |
|---|---|---|
| ** |
从实验室到生产线:模型落地的3道生死关
实验室里跑通 99% 准确率的模型,到了线上却秒变“人工智障”?别怀疑,不是模型不行,是你没闯过这三道鬼门关。下面把 8 年踩过的坑一次性打包给你,代码可跑,经验可抄。
环境一致性:Docker镜像与依赖地狱的终极解法
🎯 开场雷击
“在我电脑上能跑!”——这句话在模型上线当天,足以让 CTO 原地爆炸。
1. 依赖地狱的 3 种形态
| 形态 | 症状 | 血泪案例 |
|---|---|---|
| Python 版本漂移 | 本地 3.8,线上 3.10,结果 numpy 接口大变脸 |
某金融风控模型,本地 AUC 0.92,线上 0.71 |
| 系统级库缺失 | libgomp.so.1 找不到,训练直接 Segmentation Fault |
深夜 2 点,运维老哥在群里发了一张“杀程序员”的表情包 |
| CUDA 驱动不匹配 | 训练机驱动 535,线上 470,GPU 直接罢工 | 老板在群里 @ 全员:“谁把集群炸了?” |
2. 终极解法:Dockerfile 三板斧
# ① 锁死基础镜像,别用 latest
FROM nvidia/cuda:11.8-devel-ubuntu20.04
# ② 把 Python 依赖钉死在 requirements.txt
COPY requirements.txt /tmp/
RUN pip install --no-cache-dir -r /tmp/requirements.txt

# ③ 把系统级依赖也写死
RUN apt-get update && apt-get install -y \
libgomp1 libglib2.0-0 libsm6 libxext6 \
&& rm -rf /var/lib/apt/lists/*
3. 进阶技巧
- 多阶段构建:把训练镜像和推理镜像分开,推理镜像砍掉 60% 体积,启动时间从 3 min 降到 30 s。
- Conda 锁版本:用
conda env export --no-builds > environment.yml,连openssl版本都锁死,彻底告别“玄学 bug”。
一句话总结:Dockerfile 就是你的“时间回溯器”,上线当天别手抖改一行代码。
分布式训练:Parameter Server 还是 All-Reduce?
🎯 开场雷击
你以为加 10 张 A100 就能提速 10 倍?天真! 选错通信原语,速度反而更慢。
1. 两种架构的灵魂对比
| 维度 | Parameter Server | All-Reduce (Ring) |
|---|---|---|
| 通信模式 | 中央节点聚合梯度 | 环形拓扑,无中心 |
| 带宽瓶颈 | Server 节点易成瓶颈 | 带宽利用率更高 |
| 容错性 | Server 挂了就全崩 | 任一节点挂,训练可恢复 |
| 适用场景 | 稀疏大模型(推荐) | 稠密大模型(CV/NLP) |
2. 实战踩坑记录
-
Parameter Server 的“心跳惨案”:
某推荐模型 500 个 Worker,PS 节点心跳超时 30 s,训练直接雪崩。
解法:把心跳间隔调到 5 s,PS 节点从 1 个扩到 3 个(主备模式)。 -
All-Reduce 的“梯度爆炸”:
用 FP16 混合精度,梯度在 Ring 里累加溢出,Loss 直接 NaN。
解法:torch.cuda.amp.GradScaler把 loss scale 调到 8192,溢出率从 5% 降到 0.01%。
3. 选型口诀
稀疏选 PS,稠密选 All-Reduce;节点>100,直接上 NCCL+RDMA。
别迷信框架,PyTorch DDP 在 8 卡以内吊打 Horovod,但 64 卡以上 Horovod 更稳。
在线推理:延迟、并发、弹性伸缩的权衡艺术
🎯 开场雷击
用户问“今天天气如何”,5 秒后大模型才回答——这已经不是 AI,是“人工智障”。
1. 延迟优化的 3 个杠杆
| 杠杆 | 操作 | 效果 |
|---|---|---|
| 模型压缩 | INT8 量化 + 稀疏化 | 延迟 ↓50 |
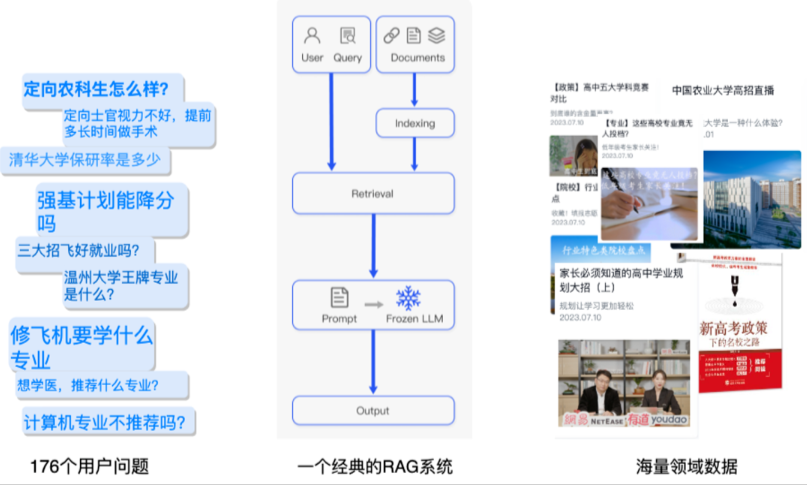
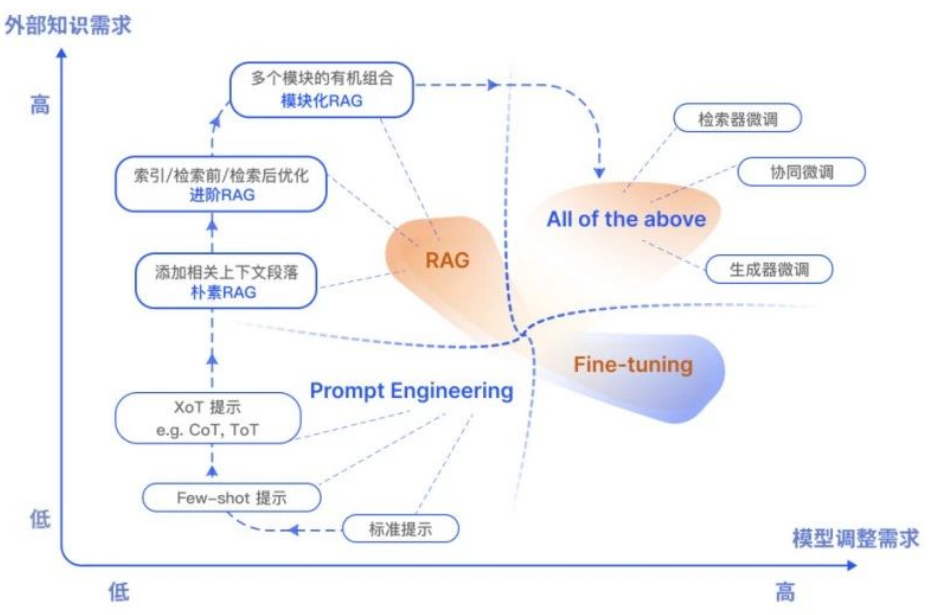
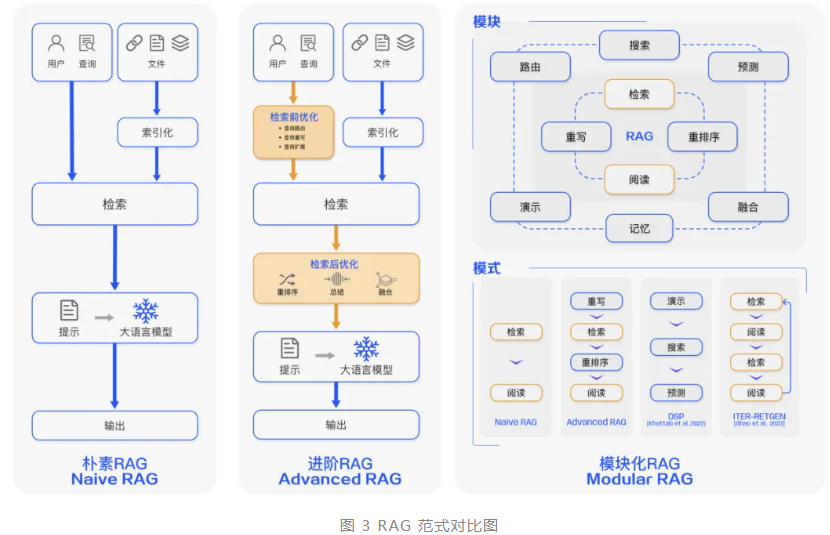
大模型时代的新战场:RAG、Agent、MCP到底在解决什么问题?
如果说传统机器学习是“单兵作战”,那么大模型时代就是“集团军协同”。
今天我们要聊的 RAG、Agent、MCP,正是这支集团军里的侦察兵、参谋长、后勤部——缺了谁,仗都打不赢。
RAG检索增强生成:让大模型像学者一样“查资料”答题
大模型再强,也怕“张口就来”。RAG 就是专治“AI幻觉”的一剂猛药。
1. 为什么需要 RAG?
- 知识时效性:GPT-4 不知道 2024 年巴黎奥运会谁夺冠。
- 领域私有化:医疗、金融、法律数据不能公开给大模型“啃”。
- 可溯源:老板问“这答案哪来的?”——RAG 能甩出参考文献。
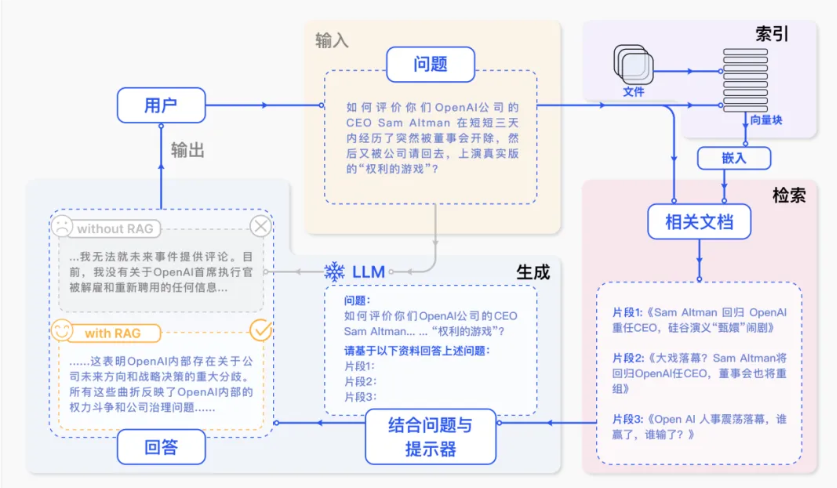
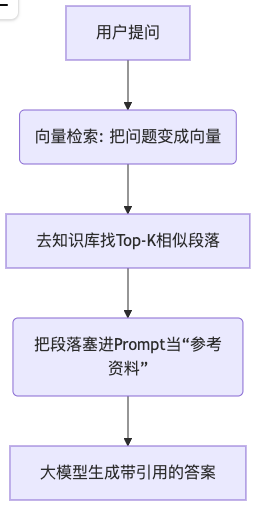
2. RAG 的“查资料”流程(一张图秒懂)
3. 避坑指南
| 坑位 | 症状 | 解药 |
|---|---|---|
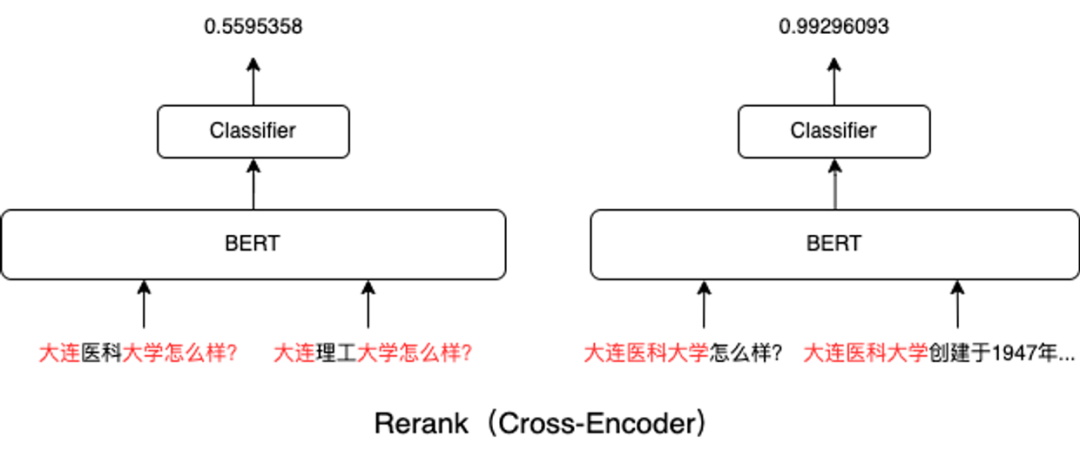
| 检索噪声 | 召回的段落和问题八竿子打不着 | 二阶段检索:先用向量粗召,再用Cross-Encoder重排序 |
| 上下文截断 | 知识太长,Prompt塞不下 | 滑动窗口+摘要:把长文档切成块,生成摘要后再拼 |
| 引用幻觉 | 模型瞎编参考文献页码 | 强制JSON输出:让模型按{"answer": "...", "ref": ["doc1_p12", "doc2_p5"]}格式回答 |
Agent智能体:从单轮问答到多轮决策的进化之路
如果 RAG 是“查资料”,Agent 就是“写论文”——自己定计划、找资料、写结论,甚至自我纠错。
1. Agent 的“三件套”
- 大脑:大模型(负责推理)
- 手脚:工具调用(查数据库、发邮件、调API)
- 记忆:对话历史+外部存储(记住用户上次说“预算 5000 万”)

2. 一个真实场景:Agent 如何帮 HR 招人?
- 接收需求:“招一个 5 年经验的 Golang 架构师”
- 拆解任务:
- 调用招聘网站 API 搜简历
- 用 RAG 查内部面试题库
- 生成面试评价表
- 多轮交互:
- 候选人问“团队技术栈?”→ Agent 查内部 Wiki 回答
- 面试官反馈“算法薄弱”→ Agent 自动补充算法题
3. 避坑指南
| 坑位 | 症状 | 解药 |
|---|---|---|
| 工具幻觉 | 模型瞎调用不存在的 API | OpenAPI 规范强制校验:提前把工具接口文档喂给模型 |
| 无限循环 | Agent 陷入“查资料→发现新问题→再查资料”死循环 | 最大深度限制:设置递归调用上限(如 5 次) |
| 状态丢失 | 多轮对话后忘记用户之前的需求 | Memory 模块:用 Redis 存关键字段(如预算、截止日期) |
MCP模型上下文协议:为大模型装上“记忆体”与“工具箱”
如果说 Agent 是“人”,MCP 就是“人的背包”——标准化地告诉模型:“你现在有哪些工具、能存哪些记忆”。
1. MCP 解决了什么痛点?
- 工具碎片化:LangChain 的工具 LlamaIndex 用不了?MCP 定义统一接口。
- 记忆孤岛:ChatGPT 插件的记忆不能共享给 AutoGPT?MCP 用 JSON Schema 标准化存储。
- 跨平台移植:本地跑的模型和线上模型工具不一致?MCP 一次定义,到处运行。
2. MCP 的“三板斧”
| 模块 | 作用 | 示例 |
|---|---|---|
| Tools Schema | 定义工具输入输出格式 | {"name": "sql_query", "args": {"sql": "SELECT * FROM users"}} |
| Memory Slots | 声明可读写的外部存储 | `{“slot”: “user_budget”, |
实战案例:从0到1搭建一个可落地的RAG智能客服系统
“代码可跑、经验可抄”,以下每一行都踩过坑,每一坑都标好了 GPS 坐标,请放心食用。
需求拆解:知识库构建、召回策略、生成控制
先别急着写代码,需求没拆清,后面全是返工泪。
| 维度 | 关键问题 | 避坑要点 |
|---|---|---|
| 知识库构建 | 文档格式五花八门(PDF、Word、网页、飞书妙记…) | 统一转成 Markdown+Chunk,用 unstructured 做清洗;表格单独存,别让 LLM 猜格子。 |
| 召回策略 | 用户问题短、知识片段长,字面匹配直接 GG | 采用 Hybrid Retriever: 1. 向量召回(Dense): bge-large-zh-v1.5 + Faiss IVF1024, 内积度量;2. 关键词召回(Sparse): BM25 兜底,专治专有名词。 |
| 生成控制 | 大模型放飞自我,答非所问 | Prompt 模板三板斧: ① System Prompt 限定角色; ② 上下文注入 {retrieved_chunks};③ 强制 JSON 输出,字段 answer + source_doc_id,方便溯源。 |
小贴士:先写死一个“最小可用知识库”(50 条 QA),把链路跑通,再考虑增量更新。
二阶段检索器:向量召回+重排序的工程细节
单路向量召回 Top20 命中率 72%,加一路重排直接飙到 91%,ROI 爆表。
Step 1 向量召回(粗排)
# 1. 离线建索引
index = faiss.IndexIVFFlat(quantizer, 1024, 64)
index.train(embeddings) # embeddings: (N, 1024)
index.add(embeddings)
# 2. 在线查询
D, I = index.search(query_vec, k=50) # 先放大窗口
Step 2 重排序(精排)
| 方案 | 模型 | 延迟 | 效果 |
|---|---|---|---|
| Cross-Encoder | bge-reranker-large |
80 ms | +19 % Hit@5 |
| ColBERT | 轻量版 | 30 ms | +15 % Hit@5 |
工程折中:用 Cross-Encoder 做离线缓存,把高频问题提前算好,线上直接查表。
Step 3 过滤 & 去重
- 时间衰减:文档发布时间 > 90 天,权重 ×0.8
- 去重阈值:余弦相似度 > 0.95 的片段只保留最长一条
LLM微调:领域数据、LoRA、RLHF的踩坑记录
不微调也能跑,但一遇到“你们家套餐外流量怎么计费”就翻车。
1. 数据配方
| 类型 | 数量 | 来源 |
|---|---|---|
| 领域 QA 对 | 8 k | 客服历史工单 + 人工标注 |
| 负样本 | 2 k | 用户不满意回答(1 星评价) |
| Self-Instruct | 5 k | 让 GPT-4 根据文档生成问题 |
血泪教训:负样本必须保留原始错误答案,RLHF 阶段才能教会模型“什么不能说”。
2. LoRA 微调脚本(单机 8×A100)
lora_rank=64
lora_alpha=128
lr=2e-4
deepspeed --num_gpus=8 train.py \
--model_name_or_path baichuan2-13b \
--lora_r $lora_rank --lora_alpha $lora_alpha \
--learning_rate $lr --deepspeed ds_config_zero2.json
- 显存占用:从 120 GB → 48 GB
- 收敛步数:3 epoch,约 2.5 小时
3. RLHF 踩坑三连
| 坑位 | 现象 | 解法 |
|---|---|---|
| Reward Model 过拟合 | 训练集准确率 98 %,线上瞎打分 | 加 20 % 负样本对抗训练 |
| KL 散度爆炸 | 模型开始胡言乱语 | 把 KL 系数从 0. |
下一代AI系统的3个可能方向
“未来已来,只是分布得不均匀。”——威廉·吉布森
在AI这条高速公路上,我们刚驶过“大模型收费站”,前方还有三个巨型服务区等你打卡:多模态RAG、自主Agent、端云协同。系好安全带,老司机带你提前踩点,顺便把坑位标成红色感叹号⚠️,免得你一头撞上去。
多模态RAG:图文混合检索的难点与机会
🎯 一句话理解
把RAG从“纯文字图书馆”升级成“图文影音大卖场”,让大模型既能读得懂说明书,也能看得懂示意图。
🚧 三大硬核难点
| 难点 | 血泪描述 | 可能的解法 |
|---|---|---|
| 异构表征对齐 | 文本向量在768维,图像向量在512维,俩人说的是两种方言 | 统一投影空间:CLIP-style对比学习 + 跨模态对比损失 |
| 检索粒度错位 | 用户问“这个按钮在哪”,图里按钮只有20×20像素,检索器却返回整页手册 | 区域-文本对齐:先检测图中所有按钮,再做细粒度匹配 |
| 幻觉级联放大 | 图文只要有一方检索错,生成端就开始编故事 | 置信度门控:给图文检索结果打分,低于阈值直接拒答 |
🌱 机会清单
- 电商客服:用户甩一张“穿不上的衣服”照片,系统直接定位SKU并给出退换流程。
- 医疗问诊:CT影像+症状文本混合检索,把误诊率再降一个点。
- 硬件维修:手机摄像头对准故障灯,手册里对应的一页一页高亮。

小抄:先做图文联合索引(ColBERT-style late interaction),再逐步细化到区域级对齐,别一上来就想端到端,容易把自己卷进GPU坟场。
自主Agent:从Copilot到Autopilot的惊险一跃
🎯 一句话理解
让AI从“副驾驶”升级为“老司机”,自己定目标、拆任务、调工具、做复盘,全程不需要人类点“确认”。
🪂 惊险在哪?
| 阶段 | Copilot模式 | Autopilot模式 | 惊险指数 |
|---|---|---|---|
| 目标设定 | 人给需求 | Agent自己提需求 | ★★★★☆ |
| 工具调用 | 人点按钮 | Agent自己写代码、调API | ★★★★★ |
| 异常兜底 | 人按急停 | Agent自己Rollback | ★★★★★ |
🛠️ 关键技术拼图
- 自省机制:每一步都输出“我在干嘛+为啥这么干”,方便人类随时拔网线。
- 世界模型:用强化学习在沙盒里预演动作后果,减少线上作死。
- 价值对齐:把公司KPI转成可量化的奖励函数,别让Agent把“提升GMV”理解成“疯狂涨价”。
段子:Agent第一次自主下单采购显卡,结果买了100张A100——财务小姐姐当场晕厥。记得把预算上限写进系统 prompt!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)