想让AI更聪明?学习如何通过短期记忆和长期存储提升其能力,看到就是赚到!
想象一下和一个忘记你说过的所有话的朋友交谈。每一次对话都要从零开始,没有记忆、没有上下文、没有进展。这会让人感到尴尬、疲惫且缺乏人情味。不幸的是,当今大多数人工智能系统的行为正是如此。它们确实很聪明,但缺少一些关键的东西:记忆。让我们首先讨论人工智能中记忆的真正含义以及它为何重要。
前言
想象一下和一个忘记你说过的所有话的朋友交谈。每一次对话都要从零开始,没有记忆、没有上下文、没有进展。这会让人感到尴尬、疲惫且缺乏人情味。不幸的是,当今大多数人工智能系统的行为正是如此。它们确实很聪明,但缺少一些关键的东西:记忆。
让我们首先讨论人工智能中记忆的真正含义以及它为何重要。
1. 引言
1.1 当今人工智能中的记忆错觉
像 ChatGPT 或代码辅助工具这样的工具虽然有用,但你会发现自己需要一遍又一遍地重复指令或偏好。要构建能够学习、进化和协作的智能体,真正的记忆不仅仅是有益的——而是必不可少的。
由上下文窗口和巧妙的提示工程所营造的记忆错觉,让许多人认为智能体已经具备“记忆”。实际上,当今大多数智能体都是无状态的,无法从过去的交互中学习或随时间适应。
要从无状态工具转变为真正智能、自主的**(有状态的)智能体,我们需要赋予它们记忆**,而不仅仅是更大的提示或更好的检索能力。
1.2 人工智能智能体中的记忆指的是什么?
在人工智能智能体的语境中,记忆是跨时间、任务和多次用户交互保留和回忆相关信息的能力。它使智能体能够记住过去发生的事情,并利用这些信息在未来改善行为。
记忆不仅仅是存储聊天历史或将更多标记注入提示中。它是关于构建一个持续的内部状态,这个状态会不断进化,并影响智能体的每一次交互,即使这些交互相隔数周或数月。
智能体的记忆由三大支柱定义:
- 状态:了解当前正在发生的事情
- 持久性:跨会话保留知识
- 选择性:决定哪些内容值得记忆
这三者共同实现了我们前所未有的能力:连续性。
1.3 记忆如何融入智能体架构
让我们将记忆置于现代智能体的架构中。典型组件包括:
- 用于推理和生成回答的 LLM
- 策略或规划器(如 ReAct、AutoGPT 风格)
- 访问 工具/API 的能力
- 用于获取文档或历史数据的 检索器
问题在于:这些组件都无法记住昨天发生的事情。没有内部状态,没有不断进化的理解,没有记忆。
1.4 上下文窗口≠记忆
一个常见的误解是,大的上下文窗口将消除对记忆的需求。
但这种方法由于某些限制而显得不足。调用具有更多上下文的 LLM 的主要缺点之一是:成本高昂:更多标记 = 更高的成本和延迟
上下文窗口帮助智能体在会话内保持一致性,而记忆使智能体能够在会话间保持智能。即使上下文长度达到 100K 标记,缺乏持久性、优先级和显著性也使其不足以实现真正的智能。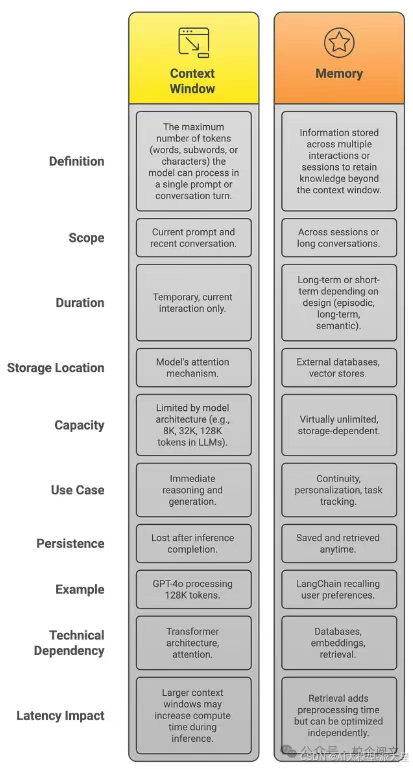
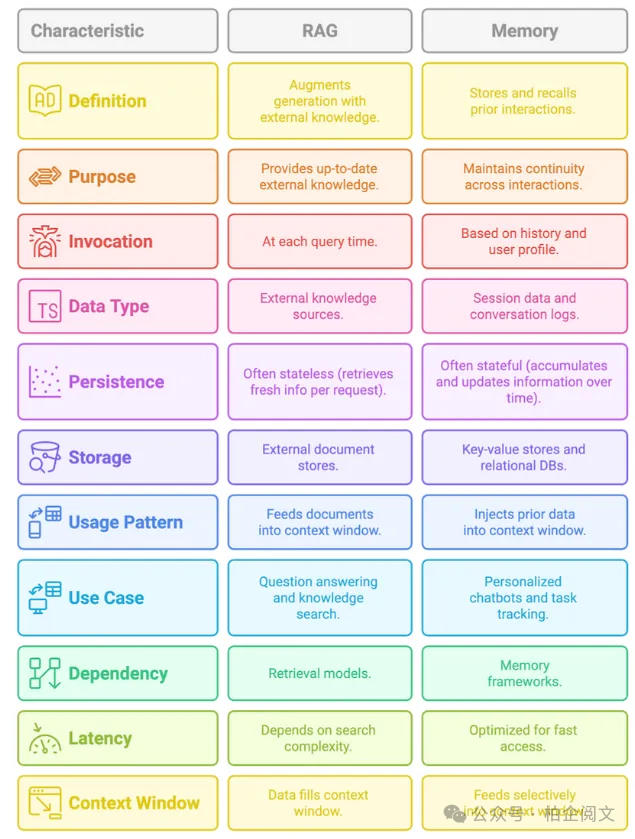
1.5 为什么检索增强生成(RAG)与记忆不同
虽然 RAG(检索增强生成) 和 记忆系统 都检索信息来支持 LLM,但它们解决的问题截然不同。
- RAG 在推理时将外部知识带入提示中,有助于用文档中的事实为回答提供依据。
- 但 RAG 本质上是无状态的——它不知道之前的交互、用户身份,或当前查询与过去对话的关系。
另一方面,记忆带来连续性。它捕捉用户偏好、过去的查询、决策和失败,并在未来的交互中提供这些信息。
可以这样理解:
❝
RAG 帮助智能体更好地回答问题,记忆帮助智能体更聪明地行为。
❝
你需要两者兼具——RAG 为 LLM 提供信息,记忆塑造其行为。
2. 智能体中的记忆类型
从根本上讲,人工智能智能体中的记忆有两种形式:
- 短期记忆:在单次交互中保存即时上下文。
- 长期记忆:跨会话、任务和时间保留知识。
就像人类一样,这些记忆类型服务于不同的认知功能。短期记忆帮助智能体在当下保持连贯,长期记忆帮助其学习、个性化和适应。
👉简单经验法则:
- 短期记忆 = 人工智能在与你交谈时“现在记得”的内容。
- 长期记忆 = 人工智能在多次对话后“学习并稍后回忆”的内容。
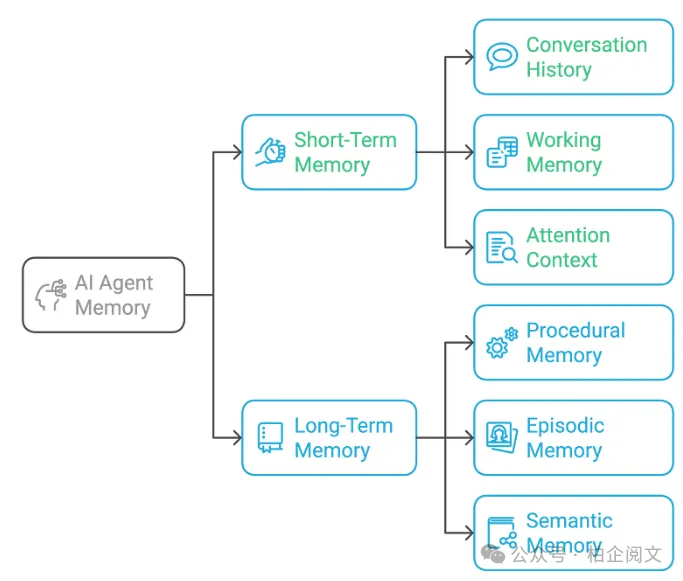
2.1 短期记忆(或工作记忆)
人工智能系统中最基本的记忆形式是保存即时上下文——就像一个人记住对话中刚刚说过的话。这包括:
- 对话历史:最近的消息及其顺序
- 工作记忆:临时变量和状态
- 注意力上下文:对话的当前焦点
2.2 长期记忆
更复杂的人工智能应用会实现长期记忆,以跨对话保留信息。
这包括:
2.2.1 程序性记忆
定义智能体知道如何执行的操作,直接编码在代码中。从简单的模板到复杂的推理流程——这是智能体的逻辑层。
这是智能体的“肌肉记忆”——习得的行为变得自动化。就像你打字时不会有意识地思考每一个按键一样,智能体将内化诸如“始终优先处理关于 API 文档的电子邮件”或“在回复技术问题时使用更有帮助的语气”等流程。
2.2.2 情景记忆(示例)
特定于用户的过去交互和经验,是实现连续性、个性化和随时间学习的关键。
这是智能体的“相册”——过去事件和交互的具体记忆。就像你可能确切记得听到重要消息时的位置一样,智能体将记住“上次这位客户发送关于延期的电子邮件时,我的回复过于生硬,造成了摩擦”或“当电子邮件包含‘快速问题’一词时,通常需要详细的技术解释,而这些解释并不快速”。
2.2.3 语义记忆(事实)
通过向量搜索或 RAG 检索的事实性世界知识。
这是智能体的“百科全书”——它了解的关于世界的事实。就像你知道巴黎是法国的首都,而不记得具体何时或如何学到这一点一样,智能体将记住“Alice 是 API 文档的联系人”或“John 更喜欢上午开会”。这是独立于特定经验存在的知识。
3. 管理记忆
许多人工智能应用需要记忆来跨多次交互共享上下文。LangGraph 支持构建对话智能体所需的两种基本记忆类型:
- 短期记忆:通过在会话中维护消息历史来跟踪正在进行的对话。
- 长期记忆:跨会话存储特定于用户或应用程序级别的数据。
启用短期记忆后,长对话可能会超过 LLM 的上下文窗口。常见的解决方案包括:
- 修剪:删除前 N 条或后 N 条消息(在调用 LLM 之前)
- 总结:总结历史中的早期消息,并用摘要替换它们
- 从 LangGraph 状态中永久删除消息
- 自定义策略(如消息过滤等)
这使智能体能够跟踪对话,而不会超过 LLM 的上下文窗口。
4. 写入记忆
虽然人类通常在睡眠中形成长期记忆,但人工智能智能体需要不同的方法。智能体何时以及如何创建新记忆?至少有两种主要方法可以让智能体写入记忆:“在热路径上”和“在后台”。
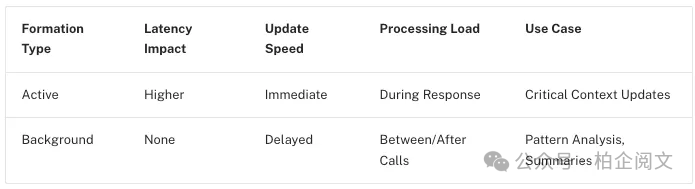
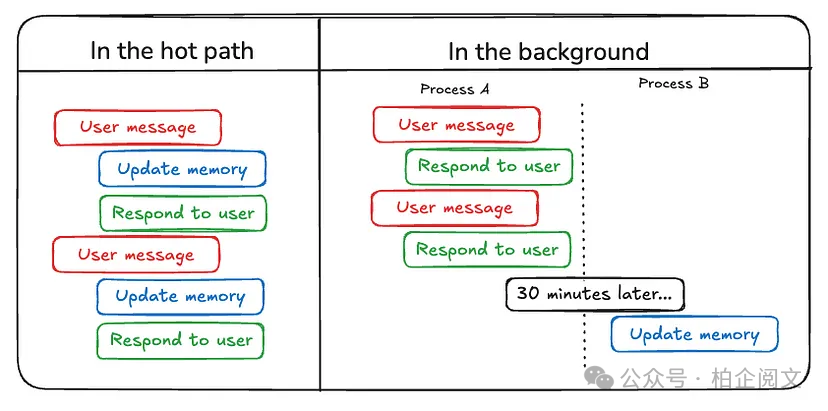
4.1 在热路径上写入记忆
在运行时创建记忆既有优点也有挑战。积极的一面是,这种方法允许实时更新,使新记忆可立即用于后续交互。它还实现了透明度,因为可以在创建和存储记忆时通知用户。
例如,ChatGPT 使用save_memories工具将记忆作为内容字符串插入或更新,并在每条用户消息中决定是否以及如何使用此工具。
4.2 在后台写入记忆
将记忆创建作为单独的后台任务具有多个优点。它消除了主应用程序中的延迟,将应用程序逻辑与记忆管理分离,并允许智能体更专注于完成任务。这种方法还提供了安排记忆创建时间的灵活性,以避免冗余工作。
5. 添加短期记忆
短期记忆(线程级持久性)使智能体能够跟踪多轮对话。要添加短期记忆:
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import InMemorySaver
model = init_chat_model(model="anthropic:claude-3-5-haiku-latest")
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
hi! I'm bob
================================== Ai Message ==================================
Hi Bob! How are you doing today? Is there anything I can help you with?
================================ Human Message =================================
what's my name?
================================== Ai Message ==================================
Your name is Bob.
5.1 在生产环境中
在生产环境中,你需要使用由数据库支持的检查点:
示例:使用 MongoDB 检查点
要使用 MongoDB 检查点,你需要一个 MongoDB 集群。如果尚未拥有,请按照this guide创建一个集群。
pip install -U pymongo langgraph langgraph-checkpoint-mongodb
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.mongodb import MongoDBSaver
model = init_chat_model(model="anthropic:claude-3-5-haiku-latest")
DB_URI = "localhost:27017"
with MongoDBSaver.from_conn_string(DB_URI) as checkpointer:
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
5.2 使用子图
如果你的图包含subgraphs,你只需在编译父图时提供检查点。LangGraph 将自动将检查点传播到子图。
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from typing import TypedDict
class State(TypedDict):
foo: str
# 子图
def subgraph_node_1(state: State):
return {"foo": state["foo"] + "bar"}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph = subgraph_builder.compile()
# 父图
def node_1(state: State):
return {"foo": "hi! " + state["foo"]}
builder = StateGraph(State)
builder.add_node("node_1", subgraph)
builder.add_edge(START, "node_1")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
5.3 管理检查点
你可以查看和删除检查点存储的信息:
*查看线程状态(检查点)*
config = {
"configurable": {
"thread_id": "1",
# 可选地提供特定检查点的 ID,否则显示最新检查点
# "checkpoint_id": "1f029ca3-1f5b-6704-8004-820c16b69a5a"
}
}
graph.get_state(config)
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today?), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]}, next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},
metadata={
'source': 'loop',
'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}},
'step': 4,
'parents': {},
'thread_id': '1'
},
created_at='2025-05-05T16:01:24.680462+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
tasks=(),
interrupts=()
)
*查看线程历史(检查点)*
config = {
"configurable": {
"thread_id": "1"
}
}
list(graph.get_state_history(config))
[
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]},
next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},
metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}}, 'step': 4, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:24.680462+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
tasks=(),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?")]},
next=('call_model',),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},
metadata={'source': 'loop', 'writes': None, 'step': 3, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:23.863421+00:00',
parent_config={...},
tasks=(PregelTask(id='8ab4155e-6b15-b885-9ce5-bed69a2c305c', name='call_model', path=('__pregel_pull', 'call_model'), error=None, interrupts=(), state=None, result={'messages': AIMessage(content='Your name is Bob.')}),),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]},
next=('__start__',),
config={...},
metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "what's my name?"}]}}, 'step': 2, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:23.863173+00:00',
parent_config={...},
tasks=(PregelTask(id='24ba39d6-6db1-4c9b-f4c5-682aeaf38dcd', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'messages': [{'role': 'user', 'content': "what's my name?"}]}),),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]},
next=(),
config={...},
metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}}, 'step': 1, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:23.862295+00:00',
parent_config={...},
tasks=(),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content="hi! I'm bob")]},
next=('call_model',),
config={...},
metadata={'source': 'loop', 'writes': None, 'step': 0, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:22.278960+00:00',
parent_config={...},
tasks=(PregelTask(id='8cbd75e0-3720-b056-04f7-71ac805140a0', name='call_model', path=('__pregel_pull', 'call_model'), error=None, interrupts=(), state=None, result={'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}),),
interrupts=()
),
StateSnapshot(
values={'messages': []},
next=('__start__',),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-0870-6ce2-bfff-1f3f14c3e565'}},
metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}}, 'step': -1, 'parents': {}, 'thread_id': '1'},
created_at='2025-05-05T16:01:22.277497+00:00',
parent_config=None,
tasks=(PregelTask(id='d458367b-8265-812c-18e2-33001d199ce6', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}),),
interrupts=()
)
]
*删除线程的所有检查点*
thread_id = "1"
checkpointer.delete_thread(thread_id)
6. 添加长期记忆
使用长期记忆(跨线程持久性)来跨对话存储特定于用户或应用程序的数据。这对于聊天机器人等应用程序非常有用,因为你需要记住用户偏好或其他信息。
要使用长期记忆,我们需要在创建图时提供存储:
import uuid
from typing_extensions import Annotated, TypedDict
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
from langgraph.store.base import BaseStore
model = init_chat_model(model="anthropic:claude-3-5-haiku-latest")
def call_model(
state: MessagesState,
config: RunnableConfig,
*,
store: BaseStore,
):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# 如果用户要求模型记住,则存储新记忆
last_message = state["messages"][-1]
if"remember"in last_message.content.lower():
memory = "User name is Bob"
store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
checkpointer = InMemorySaver()
store = InMemoryStore()
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {
"configurable": {
"thread_id": "1",
"user_id": "1",
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
config = {
"configurable": {
"thread_id": "2",
"user_id": "1",
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
Hi! Remember: my name is Bob
================================== Ai Message ==================================
Hi Bob! I'll remember that your name is Bob. How are you doing today?
================================ Human Message =================================
what is my name?
================================== Ai Message ==================================
Your name is Bob.
6.1 在生产环境中
在生产环境中,你需要使用由数据库支持的检查点:
示例:使用 Postgres 存储
首次使用 Postgres 存储时,需要调用store.setup()
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres
from langchain_core.runnables import RunnableConfig
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
from langgraph.store.base import BaseStore
model = init_chat_model(model="anthropic:claude-3-5-haiku-latest")
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with (
PostgresStore.from_conn_string(DB_URI) as store,
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
):
# store.setup()
# checkpointer.setup()
def call_model(
state: MessagesState,
config: RunnableConfig,
*,
store: BaseStore,
):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"You are a helpful assistant talking to the user. User info: {info}"
# 如果用户要求模型记住,则存储新记忆
last_message = state["messages"][-1]
if"remember"in last_message.content.lower():
memory = "User name is Bob"
store.put(namespace, str(uuid.uuid4()), {"data": memory})
response = model.invoke(
[{"role": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
config = {
"configurable": {
"thread_id": "1",
"user_id": "1",
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},
config,
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
config = {
"configurable": {
"thread_id": "2",
"user_id": "1",
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config,
stream_mode="values",
):
chunk["messages"][-1].pretty_print()
6.2 语义搜索
你可以在图的记忆存储中启用语义搜索:这使图智能体能够通过语义相似性搜索存储中的项目。
from typing import Optional
from langchain.embeddings import init_embeddings
from langchain.chat_models import init_chat_model
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
from langgraph.graph import START, MessagesState, StateGraph
llm = init_chat_model("openai:gpt-4o-mini")
# 创建启用语义搜索的存储
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(
index={
"embed": embeddings,
"dims": 1536,
}
)
store.put(("user_123", "memories"), "1", {"text": "I love pizza"})
store.put(("user_123", "memories"), "2", {"text": "I am a plumber"})
def chat(state, *, store: BaseStore):
# 根据用户的最后一条消息搜索
items = store.search(
("user_123", "memories"), query=state["messages"][-1].content, limit=2
)
memories = "\n".join(item.value["text"] for item in items)
memories = f"## Memories of user\n{memories}"if memories else""
response = llm.invoke(
[
{"role": "system", "content": f"You are a helpful assistant.\n{memories}"},
*state["messages"],
]
)
return {"messages": [response]}
builder = StateGraph(MessagesState)
builder.add_node(chat)
builder.add_edge(START, "chat")
graph = builder.compile(store=store)
for message, metadata in graph.stream(
input={"messages": [{"role": "user", "content": "I'm hungry"}]},
stream_mode="messages",
):
print(message.content, end="")
输出结果:
Hi there! I see you mentioned being hungry. Since you love pizza, would you like recommendations for pizza places or recipes? I'm also a plumber, but maybe that's not related right now—let me focus on your hunger!
在设计智能体时,以下问题可作为有用指南:
- 什么类型的内容 应该让智能体学习:事实/知识?过去事件的摘要?规则和风格?
- 何时 应该形成记忆(以及谁 应该形成记忆)?
- 在哪里 存储记忆(本地数据库、向量存储、云服务)?
- 如何 确保记忆的隐私性和安全性?
- 如何 防止过时或错误的记忆污染智能体决策?
7. 构建电子邮件智能体:分步指南
现在让我们将理论转化为实践,构建一个记忆增强的电子邮件智能体。这个智能体将:
- 记住用户的偏好和历史邮件
- 使用情景记忆(用户交互历史)和语义记忆(事实数据)
- 通过程序性记忆自动化重复任务
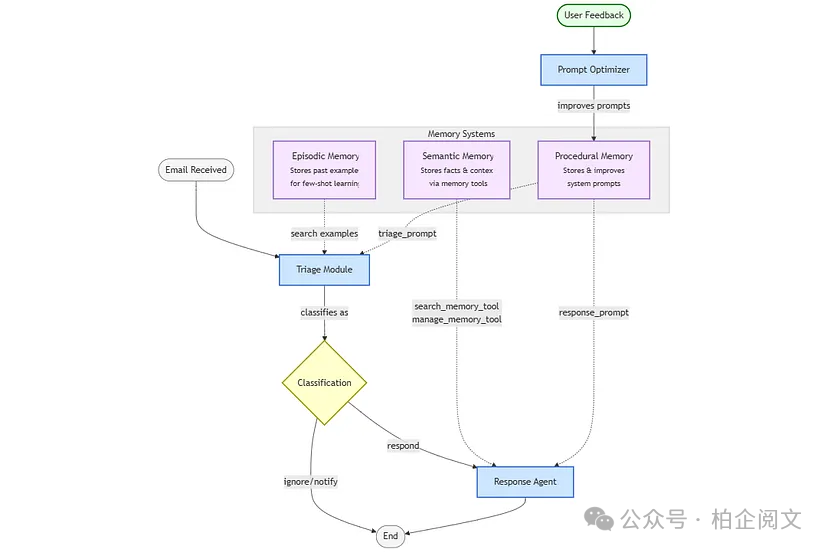
我们将使用 LangGraph 和 LangChain 实现以下架构:
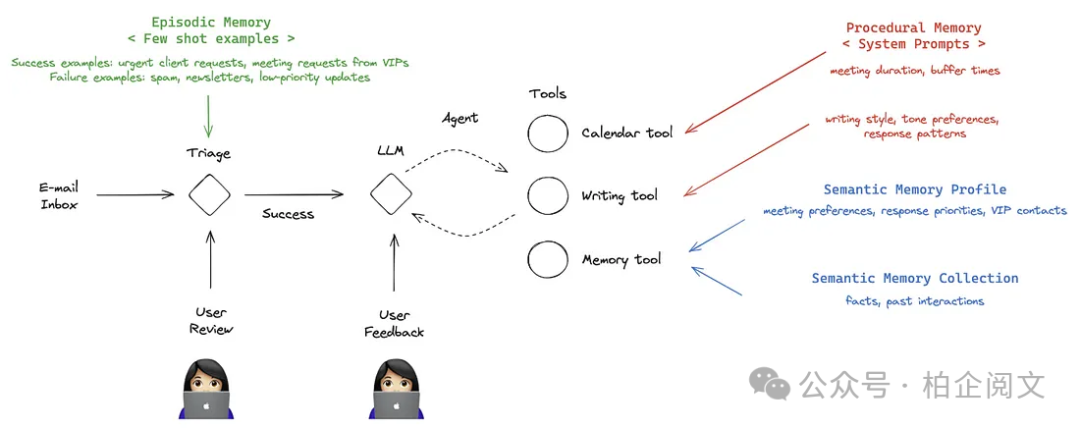 电子邮件智能体架构图
电子邮件智能体架构图
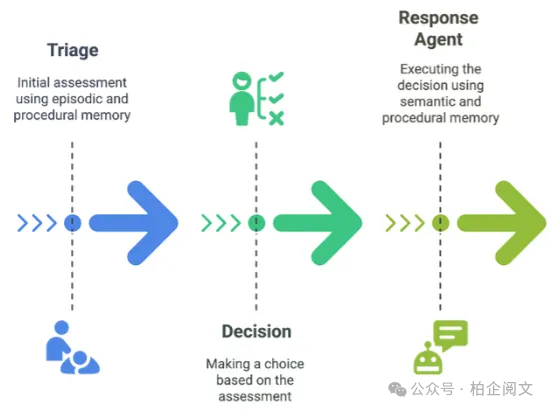
7.1 定义智能体的“大脑”:状态
首先定义智能体需要跟踪的状态:
from typing_extensions import TypedDict
from langgraph.graph import MessagesState
class EmailState(TypedDict, total=False):
"""电子邮件智能体的状态"""
messages: MessagesState # 对话历史(短期记忆)
user_preferences: dict # 用户偏好(长期语义记忆)
email_threads: dict # 邮件线程历史(长期情景记忆)
tool_responses: dict # 工具调用结果(工作记忆)
7.2 分类中心:决策(使用情景记忆)
创建一个分类器,根据邮件内容和历史决定操作:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import SystemMessage
classification_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="""
你是一个电子邮件分类器。根据邮件内容和用户历史,决定以下操作:
- "reply":直接回复邮件
- "forward":转发给特定联系人
- "escalate":标记为需要上级处理
- "archive":归档邮件(如果无关紧要)
用户历史:{user_history}
""")
])
def classify_email(state: EmailState):
prompt = classification_prompt.format_prompt(
user_history=state.get("email_threads", {})
).to_messages()
response = llm.invoke(prompt)
return {"action": response.content.lower()}
7.3 使用语义记忆定义工具
定义智能体可调用的工具(基于用户存储的事实数据):
from langgraph.tools import Tool
# 从语义记忆中获取联系人列表
def get_contacts():
return {
"developers": ["alice@company.com", "bob@techteam.com"],
"managers": ["charlie@company.com", "diana@executive.com"]
}
tools = [
Tool(
name="get_contacts",
description="获取公司联系人列表(需要用户授权)",
func=get_contacts
),
Tool(
name="send_email",
description="发送邮件(需要邮件 API 权限)",
func=lambda to, subject, body: f"邮件已发送至 {to}: {subject}"
)
]
7.4 响应智能体:创建核心助手(使用语义记忆)
构建根据用户偏好生成回复的模块:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.7)
def generate_response(state: EmailState):
preferences = state.get("user_preferences", {})
tone = preferences.get("tone", "professional")
template = f"""
根据以下用户偏好生成回复:
- 语气:{tone}
- 签名:{preferences.get("signature", "Best regards, [Your Name]")}
邮件内容:{state["messages"][-1].content}
"""
response = llm.invoke(template)
return {"reply": response.content}
7.5 构建图:连接各个部分
使用 LangGraph 组合组件,形成可执行的工作流:
from langgraph.graph import StateGraph, START
builder = StateGraph(EmailState)
# 1. 分类邮件
builder.add_node("classify", classify_email)
# 2. 根据分类结果选择工具
builder.add_choice_node(
"route",
input_key="action",
choices={
"reply": ("generate", generate_response),
"forward": ("get_contacts", tools[0].func),
"escalate": ("escalate", lambda _: {"escalated": True}),
"archive": ("archive", lambda _: {"archived": True})
}
)
# 3. 发送邮件(如果需要)
builder.add_node("send", tools[1].func)
# 连接节点
builder.add_edge(START, "classify")
builder.add_edge("classify", "route")
builder.add_edge("route:reply", "generate")
builder.add_edge("generate", "send")
builder.add_edge("route:forward", "get_contacts")
builder.add_edge("get_contacts", "send")
graph = builder.compile()
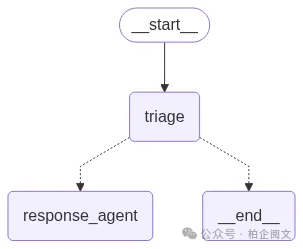
7.6 运行它!(并存储一些记忆)
初始化用户偏好(语义记忆)并处理邮件:
initial_state: EmailState = {
"user_preferences": {
"tone": "friendly",
"signature": "Cheers, Alex"
}
}
# 处理第一封邮件
email1 = """
主题:项目更新
内容:Hi Alex, 我们的团队已提前完成阶段一任务,是否需要安排会议讨论下一阶段?
"""
result = graph.invoke(
{
"messages": [{"role": "user", "content": email1}],
**initial_state
}
)
# 存储邮件线程(情景记忆)
graph.store("email_threads", {"project_update": email1})
7.7 添加程序性记忆(更新指令)——最后一步!
通过更新智能体的决策逻辑(代码)注入程序性记忆:
# 新增规则:如果邮件包含“紧急”,则自动标记为需要 escalation
def classify_email_updated(state: EmailState):
# 重用原有逻辑,但添加新条件
original_action = classify_email(state)["action"]
if "urgent" in state["messages"][-1].content.lower():
return {"action": "escalate"}
return original_action
# 替换图中的分类节点
builder.nodes["classify"] = classify_email_updated
graph = builder.compile() # 重新编译图以应用变更
7.8 运行完整的记忆增强智能体!
处理包含“紧急”关键词的邮件,测试新规则:
email2 = """
主题:紧急:服务器故障
内容:Hi Alex, 生产服务器出现严重故障,需要立即处理!
"""
result = graph.invoke(
{
"messages": [{"role": "user", "content": email2}],
**initial_state
}
)
print(result["action"]) # 输出: "escalate"
8. 结论
记忆是将无状态工具转变为智能、协作型智能体的核心。通过结合短期记忆(保持对话连贯)、长期记忆(跨会话学习)和语义搜索(智能检索),我们构建了能够理解上下文、适应需求并随着时间改进的系统。
最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)