从零到一搭建RAG系统
RAG技术概述与实现摘要 RAG(检索增强生成)技术通过结合外部知识检索与大模型生成能力,有效解决了基础大模型的四大局限性:知识局限(无法获取实时/非公开数据)、幻觉问题(错误生成)、数据安全(私域数据保护)和上下文限制(有限窗口问题)。其核心流程包括:文本分块、嵌入向量化、向量数据库存储、查询检索和生成响应。实现时需构建嵌入模型(如OpenAI的text-embedding-3系列)、计算余弦相
RAG基础知识
基础大模型存在的局限性
- 知识局限性
模型自身的知识完全源于它的训练数据,而现有的主流大模型的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。 - 幻觉问题
所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。 - 数据安全性
对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。 - 有限的上下文
大模型在实际应用中还会另一个“障碍”,那就是最大上下文限制。由于大模型的本质其实是一个算法,不管是让大模型“知道”有哪些外部工具,还是要给大模型进行“背景设置”,或者是要给模型添加历史对话消息,以及本次对话的输出,都需要占用这个上下文窗口。这就使得我们在一次对话中能够给大模型灌输的知识(文本)其实是有限的。
大型语言模型还存在最大上下文限制,这是由它们的架构和计算方式决定的。每次生成回答时,模型需要把输入文本转换成固定长度的数字序列(称为token),并在内部一次性加载到模型的“上下文窗口”中进行处理。这个窗口的大小是有限的,不同模型一般在几千到几万token之间。如果输入内容超出这个长度,模型要么截断最前面的部分,要么丢弃部分信息,这就会造成对话历史、长文档或先前提到的重要细节的遗失。因为它无法跨越上下文窗口无限地保留信息,所以在面对长对话或者大量背景知识时,模型常常出现上下文断裂、回答不连贯或者忽略先前条件的情况。RAG是解决上述问题的一套有效方案
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)技术。核心思想是借助一些文本检索策略,让大模型每次回答前带入相关文本,以此来改善大模型回答时的准确性。
RAG实现流程
RAG技术已经是非常庞大的技术体系了,从简答的文档切分、存储、匹配,再到复杂的入GraphRAG(基于知识图谱的检索增强),以及复杂文档解析+多模态识别技术等。
1.文本分块:将外部文档拆分成文本块,然后将文本块嵌入并存储在矢量数据库中。
2.嵌入:分块之后,使用嵌入模型来嵌入块。
3.将嵌入存储到向量数据库中
4.用户输入查询
5.嵌入查询,使用外部知识构建文本块时使用的相同嵌入模型,将此查询转换为向量。
6.检索相似块:将向量化的查询与矢量数据库中现有的矢量进行比较,以找到最相似的信息。
7.文本块重排序:检索后,选中的文本块需要进一步细化,确保优先展示相关性最高的文本。
8.生成最终响应:将用户的原始查询与提示模板中检索到的块相结合,以生成综合所选文档信息的响应。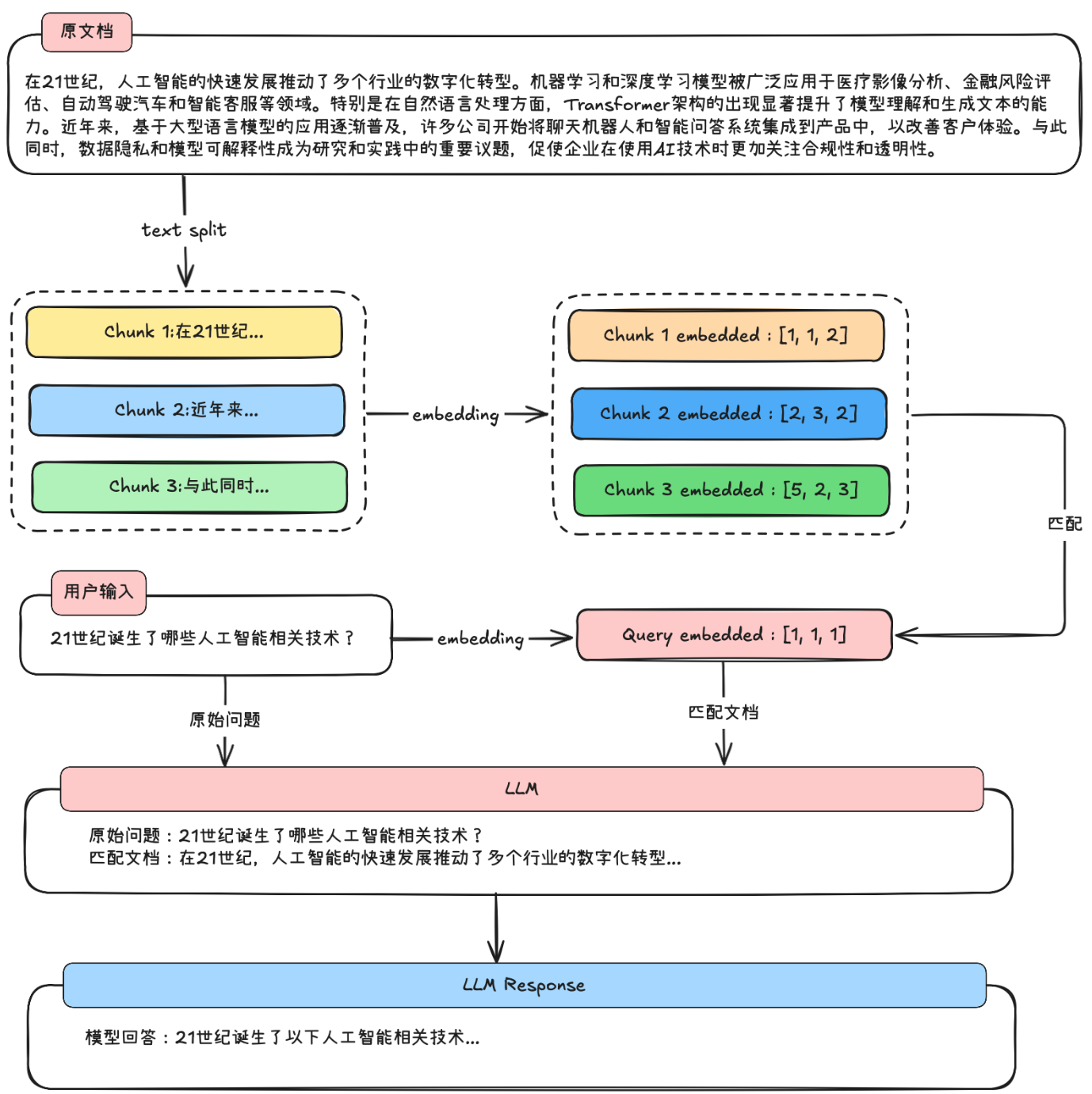
从零到一手动搭建RAG系统
0.环境配置
import os
from openai import OpenAI
import matplotlib.pyplot as plt
import numpy as np
from typing import Dict, List, Optional, Tuple, Union
import PyPDF2
import markdown
import html2text
import json
from tqdm import tqdm
import tiktoken
import re
from bs4 import BeautifulSoup
from IPython.display import display, Code, Markdown
# 临时设置环境变量
os.environ["OPENAI_API_KEY"] = 'your-openai-api-key'
os.environ["OPENAI_BASE_URL"] = "https://ai.devtool.tech/proxy/v1"
enc = tiktoken.get_encoding("cl100k_base")
1.Embedding模型获取
Embedding 是将文本字符串表示为向量(浮点数列表),通过计算向量之间的距离来衡量文本之间的相关性。向量距离越小,表示文本之间的相关性越高;距离越大,相关性越低。常见的 Embedding 应用包括:
- 搜索:根据文本查询的相关性对结果进行排序
- 聚类:根据文本相似性将其分组
- 推荐:根据相关文本字符串推荐项目
- 异常检测:识别与其他内容相关性较低的异常点
- 多样性测量:分析相似性分布
- 分类:将文本字符串根据其最相似的标签进行分类
OpenAI 最新的 Embedding 模型包括 text-embedding-3-small 和 text-embedding-3-large,它们比以往的模型具有更高的性能,且支持更多语言。
# Embedding基础类
class BaseEmbeddings:
"""
向量化的基类,用于将文本转换为向量表示。不同的子类可以实现不同的向量获取方法。
"""
def __init__(self, path: str, is_api: bool) -> None:
"""
初始化基类。
参数:
path (str) - 如果是本地模型,path 表示模型路径;如果是API模式,path可以为空
is_api (bool) - 表示是否使用API调用,如果为True表示通过API获取Embedding
"""
self.path = path
self.is_api = is_api
def get_embedding(self, text: str, model: str) -> List[float]:
"""
抽象方法,用于获取文本的向量表示,具体实现需要在子类中定义。
参数:
text (str) - 需要转换为向量的文本
model (str) - 所使用的模型名称
返回:
list[float] - 文本的向量表示
"""
raise NotImplementedError
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""
计算两个向量之间的余弦相似度,用于衡量它们的相似程度。
参数:
vector1 (list[float]) - 第一个向量
vector2 (list[float]) - 第二个向量
返回:
float - 余弦相似度值,范围从 -1 到 1,越接近 1 表示向量越相似
"""
dot_product = np.dot(vector1, vector2) # 向量点积
magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2) # 向量的模
if not magnitude:
return 0
return dot_product / magnitude # 计算余弦相似度
这个Embedding基类定义了获取文本向量表示的方法,同时包含一个计算两个向量之间余弦相似度的功能。后面使用不同的向量化模型,只需继承该基类并重写向量获取的逻辑,而不需要重复编写相似度计算部分。
在这个基类基础上,继承它来实现具体的模型。
#使用OpenAI的API来生成文本向量表示,重写get_embedding方法
class OpenAIEmbedding(BaseEmbeddings):
"""
使用 OpenAI 的 Embedding API 来获取文本向量的类,继承自 BaseEmbeddings。
"""
def __init__(self, path: str = '', is_api: bool = True) -> None:
"""
初始化类,设置 OpenAI API 客户端,如果使用的是 API 调用。
参数:
path (str) - 本地模型的路径,使用API时可以为空
is_api (bool) - 是否通过 API 获取 Embedding,默认为 True
"""
super().__init__(path, is_api)
if self.is_api:
# 初始化 OpenAI API 客户端
from openai import OpenAI
self.client = OpenAI()
self.client.api_key = os.getenv("OPENAI_API_KEY") # 从环境变量中获取 API 密钥
self.client.base_url = os.getenv("OPENAI_BASE_URL") # 从环境变量中获取 API 基础URL
def get_embedding(self, text: str, model: str = "text-embedding-3-large") -> List[float]:
"""
使用 OpenAI 的 Embedding API 获取文本的向量表示。
参数:
text (str) - 需要转化为向量的文本
model (str) - 使用的 Embedding 模型名称,默认为 'text-embedding-3-large'
返回:
list[float] - 文本的向量表示
"""
if self.is_api:
# 去掉文本中的换行符,保证输入格式规范
text = text.replace("\n", " ")
# 调用 OpenAI API 获取文本的向量表示
return self.client.embeddings.create(input=[text], model=model).data[0].embedding
else:
raise NotImplementedError # 如果不是 API 模式,这里未实现本地模型的处理
2.文档加载与切分模块创建
在实现了向量化之后,接下来需要编写一个文档加载与切分模块,用于处理不同格式的文档并将其切分为小片段。这是为了确保每个文档片段都尽量保持简短且信息集中,以便于后续的向量化和检索。
支持多种格式的文档,例如 PDF、Markdown、TXT 等。每种文件格式都有不同的读取方式。
考虑将文档按Token长度进行切分,设置一个最大的 Token 长度,然后按这个长度进行切分。在这个过程中,要确保每个片段之间有一定的重叠,避免重要信息被切掉。
class ReadFiles:
"""
读取文件的类,用于从指定路径读取支持的文件类型(如 .txt、.md、.pdf)并进行内容分割。
"""
def __init__(self, path: str) -> None:
"""
初始化函数,设定要读取的文件路径,并获取该路径下所有符合要求的文件。
:param path: 文件夹路径
"""
self._path = path
self.file_list = self.get_files() # 获取文件列表
def get_files(self):
"""
遍历指定文件夹,获取支持的文件类型列表(txt, md, pdf)。
:return: 文件路径列表
"""
file_list = []
for filepath, dirnames, filenames in os.walk(self._path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 根据文件后缀筛选支持的文件类型
if filename.endswith(".md"):
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".pdf"):
file_list.append(os.path.join(filepath, filename))
return file_list
def get_content(self, max_token_len: int = 600, cover_content: int = 150):
"""
读取文件内容并进行分割,将长文本切分为多个块。
:param max_token_len: 每个文档片段的最大 Token 长度
:param cover_content: 在每个片段之间重叠的 Token 长度
:return: 切分后的文档片段列表
"""
docs = []
for file in self.file_list:
content = self.read_file_content(file) # 读取文件内容
# 分割文档为多个小块
chunk_content = self.get_chunk(content, max_token_len=max_token_len, cover_content=cover_content)
docs.extend(chunk_content)
return docs
@classmethod
def get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):
"""
将文档内容按最大 Token 长度进行切分。
:param text: 文档内容
:param max_token_len: 每个片段的最大 Token 长度
:param cover_content: 重叠的内容长度
:return: 切分后的文档片段列表
"""
chunk_text = []
curr_len = 0
curr_chunk = ''
token_len = max_token_len - cover_content
lines = text.splitlines() # 以换行符分割文本为行
for line in lines:
line = line.replace(' ', '') # 去除空格
line_len = len(enc.encode(line)) # 计算当前行的 Token 长度
if line_len > max_token_len:
# 如果单行长度超过限制,将其分割为多个片段
num_chunks = (line_len + token_len - 1) // token_len
for i in range(num_chunks):
start = i * token_len
end = start + token_len
# 防止跨单词分割
while not line[start:end].rstrip().isspace():
start += 1
end += 1
if start >= line_len:
break
curr_chunk = curr_chunk[-cover_content:] + line[start:end]
chunk_text.append(curr_chunk)
start = (num_chunks - 1) * token_len
curr_chunk = curr_chunk[-cover_content:] + line[start:end]
chunk_text.append(curr_chunk)
elif curr_len + line_len <= token_len:
# 当前片段长度未超过限制时,继续累加
curr_chunk += line + '\n'
curr_len += line_len + 1
else:
chunk_text.append(curr_chunk) # 保存当前片段
curr_chunk = curr_chunk[-cover_content:] + line
curr_len = line_len + cover_content
if curr_chunk:
chunk_text.append(curr_chunk)
return chunk_text
@classmethod
def read_file_content(cls, file_path: str):
"""
读取文件内容,根据文件类型选择不同的读取方式。
:param file_path: 文件路径
:return: 文件内容
cls在 @classmethod 装饰的方法中作为第一个参数,代表调用该方法的类本身,而不是类的实例。
允许通过类名直接调用方法,而不需要先创建实例
"""
if file_path.endswith('.pdf'):
return cls.read_pdf(file_path)
elif file_path.endswith('.md'):
return cls.read_markdown(file_path)
elif file_path.endswith('.txt'):
return cls.read_text(file_path)
else:
raise ValueError("Unsupported file type")
@classmethod
def read_pdf(cls, file_path: str):
"""
读取 PDF 文件内容。
:param file_path: PDF 文件路径
:return: PDF 文件中的文本内容
"""
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
text += reader.pages[page_num].extract_text()
return text
@classmethod
def read_markdown(cls, file_path: str):
"""
读取 Markdown 文件内容,并将其转换为纯文本。
:param file_path: Markdown 文件路径
:return: 纯文本内容
"""
with open(file_path, 'r', encoding='utf-8') as file:
md_text = file.read()
html_text = markdown.markdown(md_text)
# 使用 BeautifulSoup 从 HTML 中提取纯文本
soup = BeautifulSoup(html_text, 'html.parser')
plain_text = soup.get_text()
# 使用正则表达式移除网址链接
text = re.sub(r'http\S+', '', plain_text)
return text
@classmethod
def read_text(cls, file_path: str):
"""
读取普通文本文件内容。
:param file_path: 文本文件路径
:return: 文件内容
"""
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
3.词向量数据库与向量检索模块
向量数据库用于存储文档片段及其对应的向量表示,而检索模块则根据用户提出的问题(Query)在数据库中检索相关的文档片段。通过这些功能,RAG 能够根据输入的查询快速找到最相关的文档片段。
为了构建这个向量数据库,需要以下几个关键功能:
- 持久化存储(persist): 将数据库存储到本地,便于下次加载使用。
- 加载数据库(load_vector): 从本地文件加载已经存储的向量和文档。
- 获取向量表示(get_vector): 将文档转化为向量表示并存储。
创建一个基础的 VectorStore 类,提供上述功能的框架。通过这个类,我们能够将文档片段转化为向量存储,加载本地数据库,进行检索。
class VectorStore:
def __init__(self, document: List[str] = None) -> None:
"""
初始化向量存储类,存储文档和对应的向量表示。
:param document: 文档列表,默认为空。
"""
if document is None:
document = []
self.document = document # 存储文档内容
self.vectors = [] # 存储文档的向量表示
def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:
"""
使用传入的 Embedding 模型将文档向量化。
:param EmbeddingModel: 传入的用于生成向量的模型(需继承 BaseEmbeddings 类)。
:return: 返回文档对应的向量列表。
"""
# 遍历所有文档,获取每个文档的向量表示
self.vectors = [EmbeddingModel.get_embedding(doc) for doc in self.document]
return self.vectors
def persist(self, path: str = 'storage'):
"""
将文档和对应的向量表示持久化到本地目录中,以便后续加载使用。
:param path: 存储路径,默认为 'storage'。
"""
if not os.path.exists(path):
os.makedirs(path) # 如果路径不存在,创建路径
# 保存向量为 numpy 文件
np.save(os.path.join(path, 'vectors.npy'), self.vectors)
# 将文档内容存储到文本文件中
with open(os.path.join(path, 'documents.txt'), 'w') as f:
for doc in self.document:
f.write(f"{doc}\n")
def load_vector(self, path: str = 'storage'):
"""
从本地加载之前保存的文档和向量数据。
:param path: 存储路径,默认为 'storage'。
"""
# 加载保存的向量数据
self.vectors = np.load(os.path.join(path, 'vectors.npy')).tolist()
# 加载文档内容
with open(os.path.join(path, 'documents.txt'), 'r') as f:
self.document = [line.strip() for line in f.readlines()]
def get_similarity(self, vector1: List[float], vector2: List[float]) -> float:
"""
计算两个向量的余弦相似度。
:param vector1: 第一个向量。
:param vector2: 第二个向量。
:return: 返回两个向量的余弦相似度,范围从 -1 到 1。
"""
dot_product = np.dot(vector1, vector2)
magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)
if not magnitude:
return 0
return dot_product / magnitude
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
"""
根据用户的查询文本,检索最相关的文档片段。
:param query: 用户的查询文本。
:param EmbeddingModel: 用于将查询向量化的嵌入模型。
:param k: 返回最相似的文档数量,默认为 1。
:return: 返回最相似的文档列表。
"""
# 将查询文本向量化
query_vector = EmbeddingModel.get_embedding(query)
# 计算查询向量与每个文档向量的相似度
similarities = [self.get_similarity(query_vector, vector) for vector in self.vectors]
# 获取相似度最高的 k 个文档索引
top_k_indices = np.argsort(similarities)[-k:][::-1]
# 返回对应的文档内容
return [self.document[idx] for idx in top_k_indices]
上述代码解释如下:
- get_vector 方法: 这个方法使用传入的
EmbeddingModel对所有文档进行向量化,并将这些向量存储在self.vectors中。 - persist 方法: 该方法将文档片段及其向量表示保存到本地文件系统,便于持久化存储。
- load_vector 方法: 从本地文件系统加载已保存的文档片段和向量,供后续检索使用。
- get_similarity 方法: 计算两个向量之间的余弦相似度,用于比较查询和文档向量的相似度。
- query 方法: 接收用户输入的查询,通过向量化后在数据库中检索最相关的文档片段,并返回最匹配的文档。
4.大模型问答模块
基类 BaseModel,它包含两个主要方法:
chat:负责处理用户的输入并生成回答。load_model:如果是使用本地模型,这个方法负责加载模型。如果使用 API 模型(如 OpenAI),可以不用实现这个方法。
"""
基础模型类,作为所有模型的基类。
包含一些通用的接口,如加载模型、生成回答等。
"""
def __init__(self, path: str = '') -> None:
self.path = path # 用于存储模型文件的路径,默认为空。
def chat(self, prompt: str, history: List[dict], content: str) -> str:
"""
使用模型生成回答的抽象方法。
:param prompt: 用户的提问内容
:param history: 之前的对话历史(字典列表)
:param content: 提供的上下文内容
:return: 模型生成的答案
"""
pass # 具体的实现由子类提供
def load_model(self):
"""
加载模型的方法,通常用于本地模型。
"""
pass # 如果是 API 模型,可能不需要实现
5.2 借助GPT4o模型进行对话
class GPT4oChat(BaseModel):
"""
基于 GPT-4o 模型的对话类,继承自 BaseModel。
主要用于通过 OpenAI API 来生成对话回答。
"""
def __init__(self, api_key: str, base_url: str = "https://ai.devtool.tech/proxy/v1") -> None:
"""
初始化 GPT-4o 模型。
:param api_key: OpenAI API 的密钥
:param base_url: 用于访问 OpenAI API 的基础 URL,默认为代理 URL
"""
super().__init__()
self.client = OpenAI(api_key=api_key, base_url=base_url) # 初始化 OpenAI 客户端
def chat(self, prompt: str, history: List = [], content: str = '') -> str:
"""
使用 GPT-4o 生成回答。
:param prompt: 用户的提问
:param history: 之前的对话历史(可选)
:param content: 可参考的上下文信息(可选)
:return: 生成的回答
"""
# 提示词模板
PROMPT_TEMPLATE = dict(
GPT4o_PROMPT_TEMPLATE="""
下面有一个或许与这个问题相关的参考段落,若你觉得参考段落能和问题相关,则先总结参考段落的内容。
若你觉得参考段落和问题无关,则使用你自己的原始知识来回答用户的问题,并且总是使用中文来进行回答。
问题: {question}
可参考的上下文:
···
{context}
···
有用的回答:"""
)
# 构建包含问题和上下文的完整提示
full_prompt = PROMPT_TEMPLATE['GPT4o_PROMPT_TEMPLATE'].format(question=prompt, context=content)
# 调用 GPT-4o 模型进行推理
response = self.client.chat.completions.create(
model="gpt-4o-mini", # 使用 GPT-4o 小型模型
messages=[
{"role": "user", "content": full_prompt}
]
)
# 返回模型生成的第一个回答
return response.choices[0].message.content
5.运行项目
def run_mini_rag(question: str, knowledge_base_path: str, k: int = 1) -> str:
"""
运行一个简化版的RAG项目。
:param question: 用户提出的问题
:param knowledge_base_path: 知识库的路径,包含文档的文件夹路径
:param api_key: OpenAI API密钥,用于调用GPT-4o模型
:param k: 返回与问题最相关的k个文档片段,默认为1
:return: 返回GPT-4o模型生成的回答
"""
api_key = os.getenv("OPENAI_API_KEY")
base_url=os.getenv("OPENAI_BASE_URL")
# 1. 加载并切分文档
docs = ReadFiles(knowledge_base_path).get_content(max_token_len=600, cover_content=150)
vector = VectorStore(docs)
# 2. 使用 OpenAI Embedding 模型进行向量化
embedding = OpenAIEmbedding()
vector.get_vector(EmbeddingModel=embedding)
# 3. 将向量和文档保存到本地(可选)
vector.persist(path='storage')
# 4. 在数据库中检索最相关的文档片段 报错
content = vector.query(question, EmbeddingModel=embedding, k=k)[0]
# 5. 使用 GPT-4o 生成答案
chat = GPT4oChat(api_key=api_key,base_url=base_url)
answer = chat.chat(question, [], content)
return answer
if __name__ == "__main__":
question = "紫色魔法师是一个什么样的故事?"
knowledge_base_path = "data"
answer = run_mini_rag(question, knowledge_base_path)
print(answer)
结果: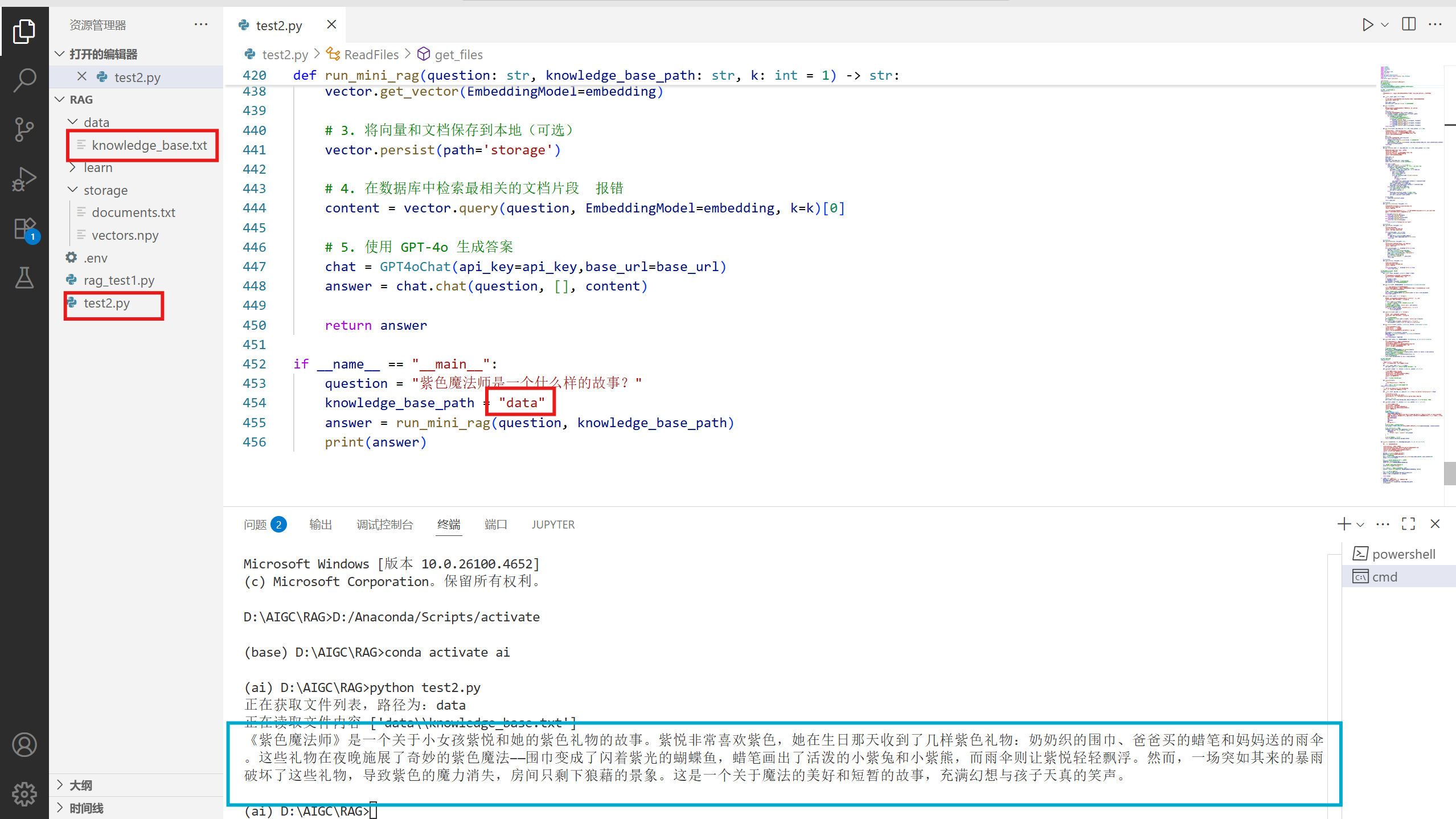
学习参考资料:
九天【手撕】从零到一搭建RAG系统

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)