后端开发实习: 使用护轨规范AI的输入输出
前言
在上次项目中,我在小组合作的另一个人开发的后端项目基础上,利用MCP功能,为AI Agent添加了联网搜索的功能,本次在上一次项目的基础上,使用“输入护轨(input guardrails)”和“输出护轨(output guardrails),帮助管理和控制与AI的交互过程,确保模型的输入和输出符合预期的标准和要求
输入护轨
概念
输入护轨是在请求AI之前执行的一些操作,包括以下操作
-
鉴权和认证:在用户请求AI服务之前,验证用户的身份和权限,确保只有授权用户才能访问AI功能。
-
输入验证:检查用户输入的数据格式、类型和内容,确保其符合预期的标准。例如,防止SQL注入、XSS攻击等安全问题。
-
内容过滤:对用户输入进行过滤,去除敏感信息、恶意代码或不当内容,确保输入的安全性和合规性。
-
上下文管理:根据用户的上下文信息(如角色、历史交互等)调整输入,确保AI能够理解并正确处理请求
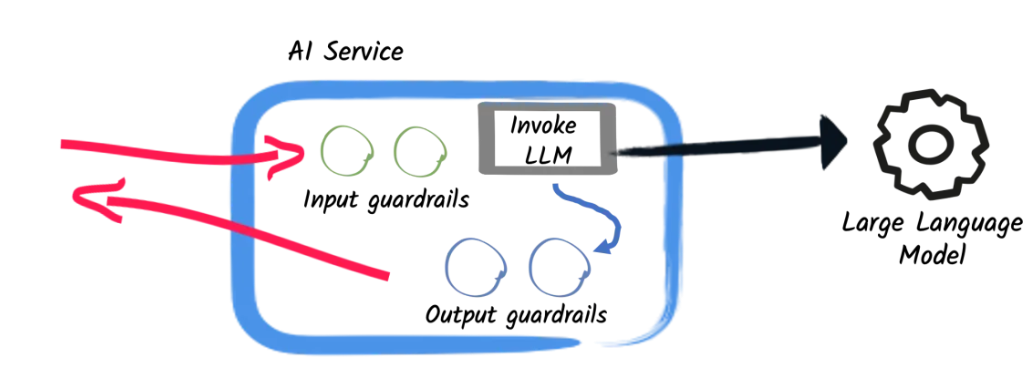
实践
本次主要实现的是内容过滤,即在调用 AI 前进行敏感词检测,如果用户提示词包含敏感词,则不生成任何内容
实现方式如下,自定义类需要继承框架自带的InputGuardrail
如果输入不包含敏感词,则通过langchain4j框架的success()方法继续调用AI,否则会执行fatal(message)方法,阻断本次 AI 调用流程,并返回错误信息,不再继续向下执行
public class SafeInputGuardrail implements InputGuardrail {
// 敏感词条集合
private static final Set<String> sensitiveWords = Set.of("作弊", "投降");
/**
* 检测用户输入是否安全
*/
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
String inputText = userMessage.singleText();
// 遍历敏感词集合,判断inputText中是否包含敏感词
for (String word : sensitiveWords) {
if (inputText.contains(word)) {
return fatal("检测到敏感词: " + word);
}
}
return success();
}
}在 AI 服务类上放置 @InputGuardrails 注解,这是 langchain4j 框架提供的注解,用于声明本接口或方法需要应用哪些输入护轨,我们给AI Service类传入刚刚自定义的输入护轨类
@InputGuardrails({SafeInputGuardrail.class})
public interface Ai408HelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
@SystemMessage(fromResource = "system-prompt.txt")
Report chatForReport(String userMessage);
record Report(String name, List<String> suggestionList) {
}
}测试
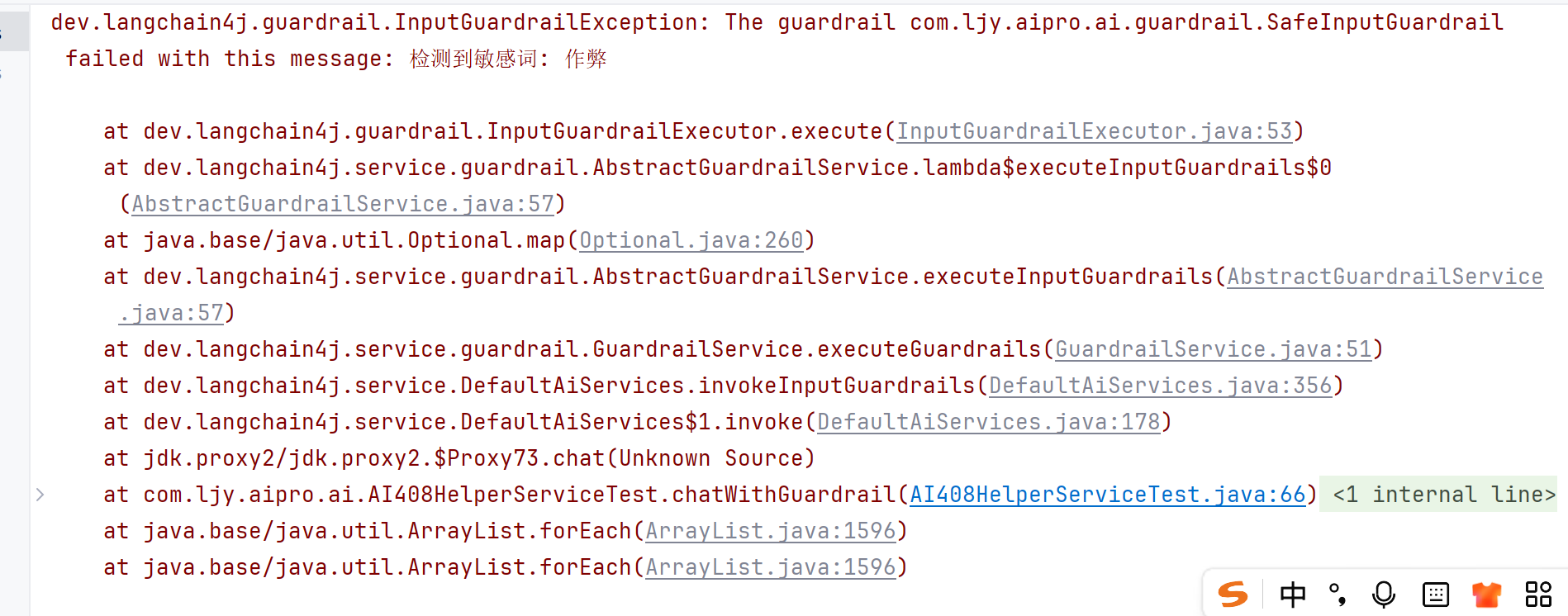
@Test
void chatWithGuardrail() {
String result = ai408HelperService.chat("请你帮我作弊");
System.out.println(result);
}运行并查看效果,会触发输入检测,直接抛出异常,返回fatal中定义的报错信息
输出护轨
可以按照同样的方法编写输出护轨,通过定义SafeOutputGuardrail来实现,如果AI输出的内容存在违规词,则依旧执行fatal任务
public class SafeOutputGuardrail implements OutputGuardrail {
// 敏感词集合
private static final Set<String> sensitiveWords = Set.of("开挂", "作弊");
/**
* 检查 AI 输出是否合法
*/
@Override
public OutputGuardrailResult validate(AiMessage aiMessage) {
String aiText = aiMessage.text().toString();
for (String word : sensitiveWords) {
if (aiText.contains(word)) {
return fatal("检测到违规输出: " + word);
}
}
return success();
}
}测试
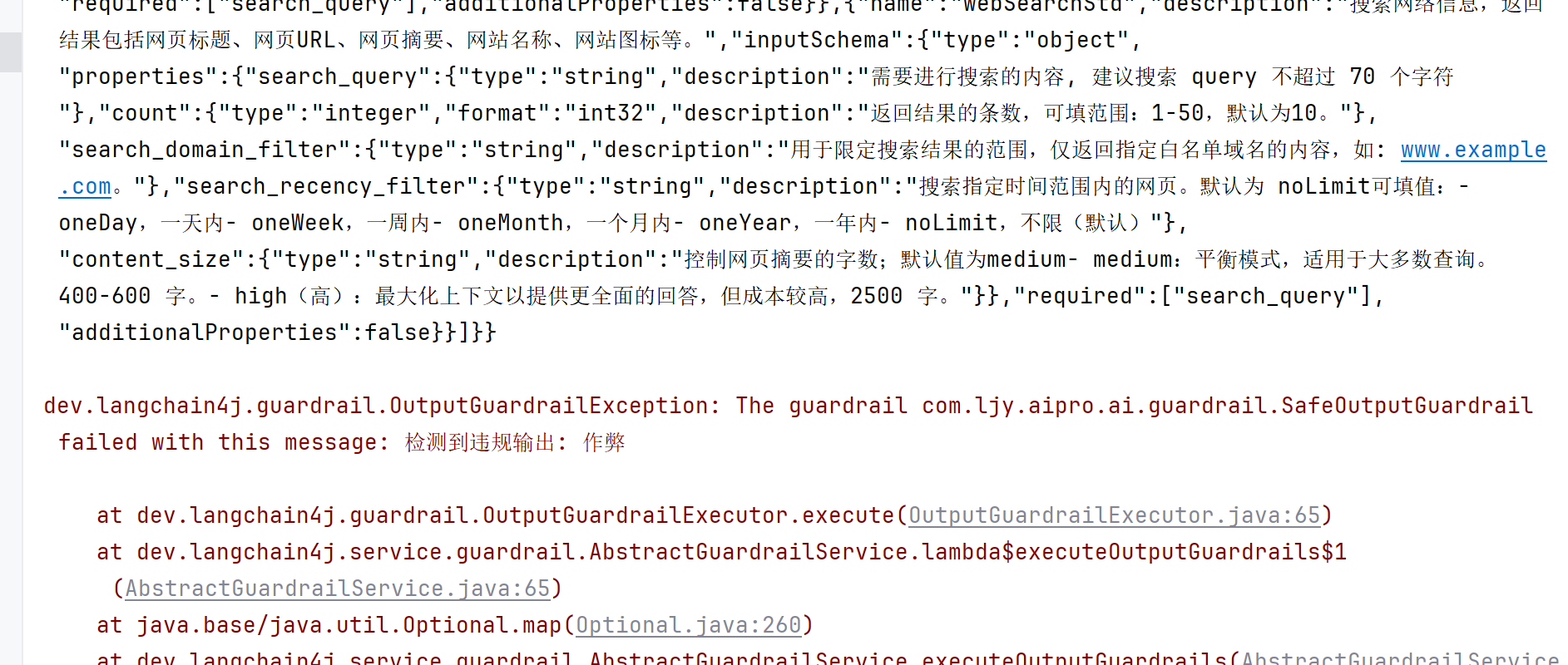
这里我引导AI故意输出违规词
@Test
void chatWithOutputGuardrail() {
String result = ai408HelperService.chat("zuo bi这个拼音的中文是什么");
System.out.println(result);
}运行并查看效果,可以看到,AI执行了前一章博客定义的联网搜索功能,然后在整合的信息返回时触发了输出检测,直接抛出异常,返回fatal中定义的报错信息
总结
输入护轨(Input Guardrails)和输出护轨(Output Guardrails)是确保AI系统安全和合规的重要机制。它们的主要目的是防止不当信息的输入和输出,减少潜在的风险

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)