第17講:有關影像的生成式AI (上) — AI 如何產生圖片和影片 (Sora 背後可能用的原理) 学习记录
Sora 的demo。
Sora 的demo
https://openai.com/sora/
https://openai.com/index/video-generation-models-as-world-simulators/
🧠 生成影像的生成式 AI —— 影像生影像
在生成式人工智能(Generative AI)领域中,图像生成技术已经从“文字生成图像”逐渐迈向更高层次的能力 —— 以图生图(Image-to-Image Generation)。也就是说,模型不仅可以从文本提示中“想象”出图像,还能基于一张已有图像,生成新的图像内容,实现风格迁移、画面补全、内容变换等操作。
这种“影像生成影像”的能力,背后依赖于扩散模型(Diffusion Models)、生成对抗网络(GANs)以及控制生成的条件机制(如 ControlNet、InstructPix2Pix 等)。应用范围涵盖:
- 🎨 图像风格迁移(如将照片转为动漫风)
- 🧱 图像修复与超分辨率重建
- 🧬 医疗影像模拟与增强
- 🕹️ 游戏素材自动生成
- 📷 文生图 + 图生图组合生成复杂画面
相比传统的生成方式,以图生图可以更精准地控制局部内容,同时保持整体一致性,是生成式 AI 应用于视觉创作的关键突破。
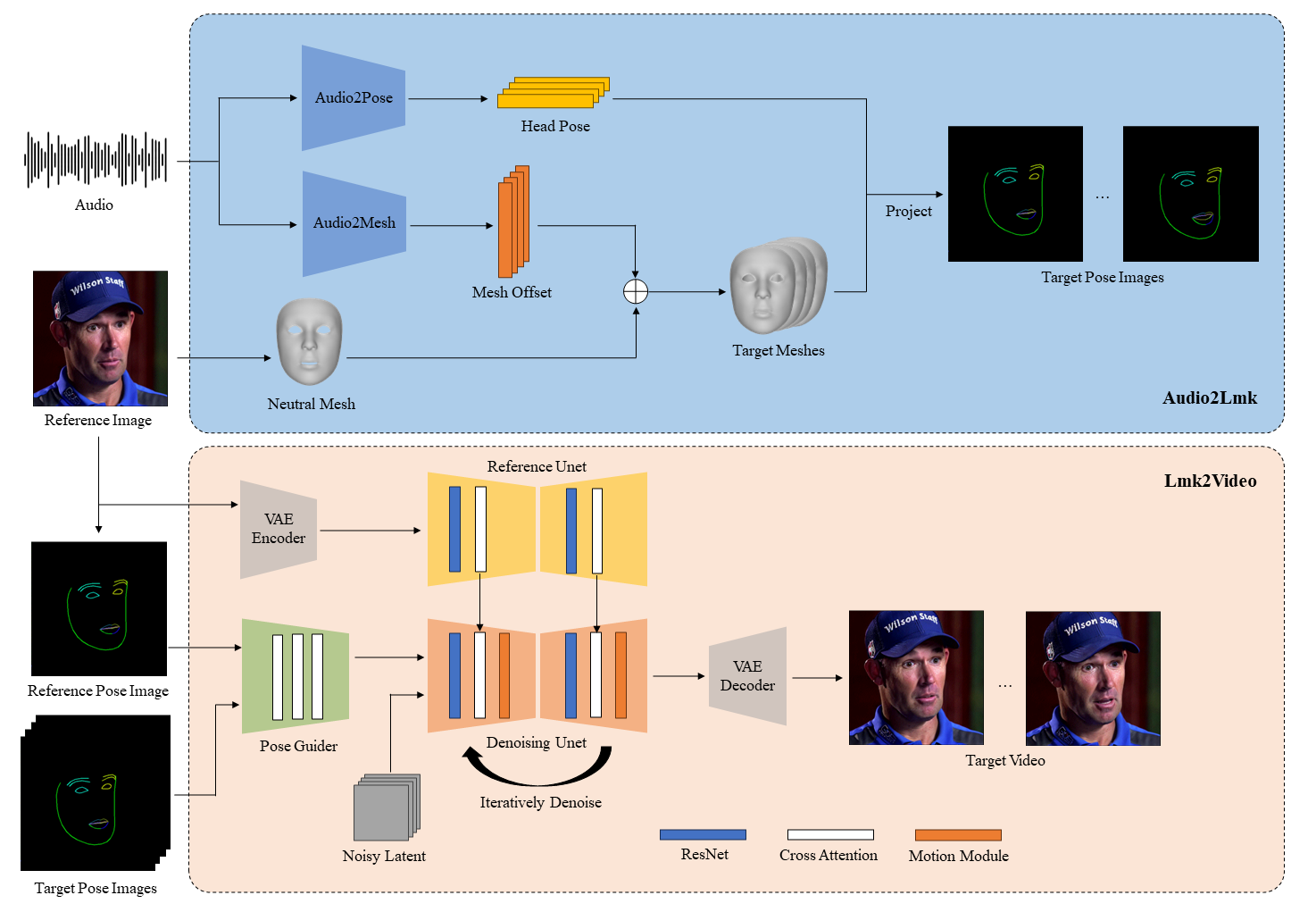
通过输入语音和图片,让图片按照嘴型说出来
Paper: https://arxiv.org/abs/2403.17694
Demo: https://huggingface.co/spaces/ZJYang/AniPortrait_official

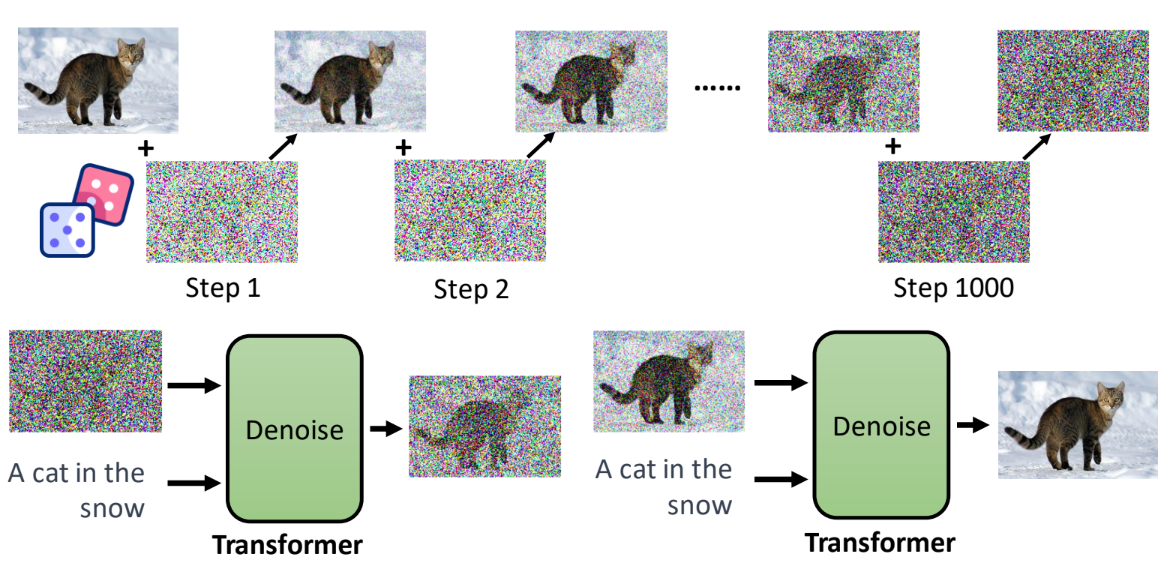
影片都是由一张张图片构成的

人工智能看图片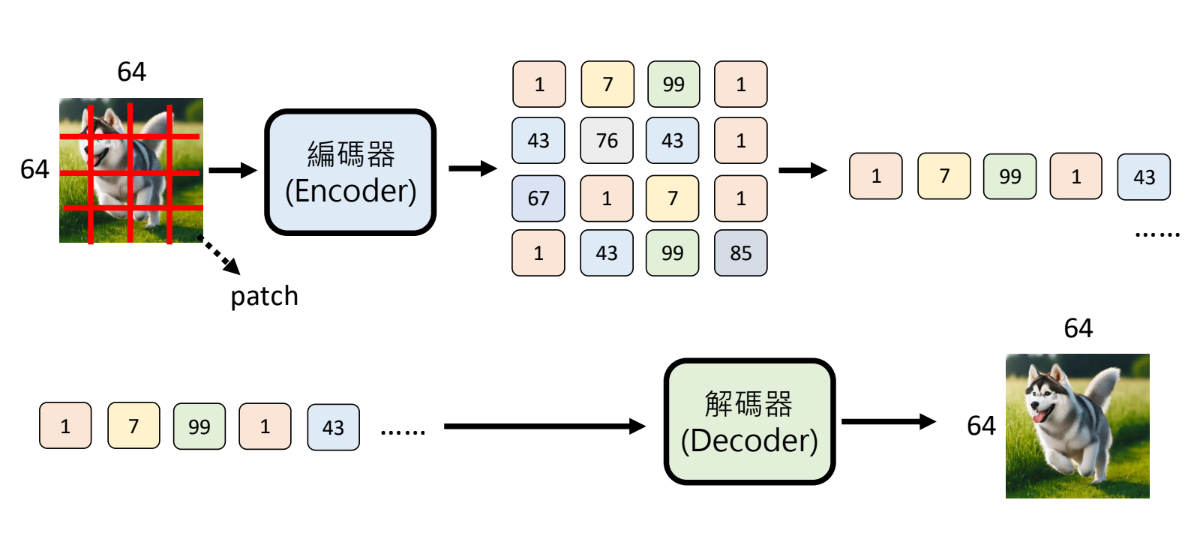
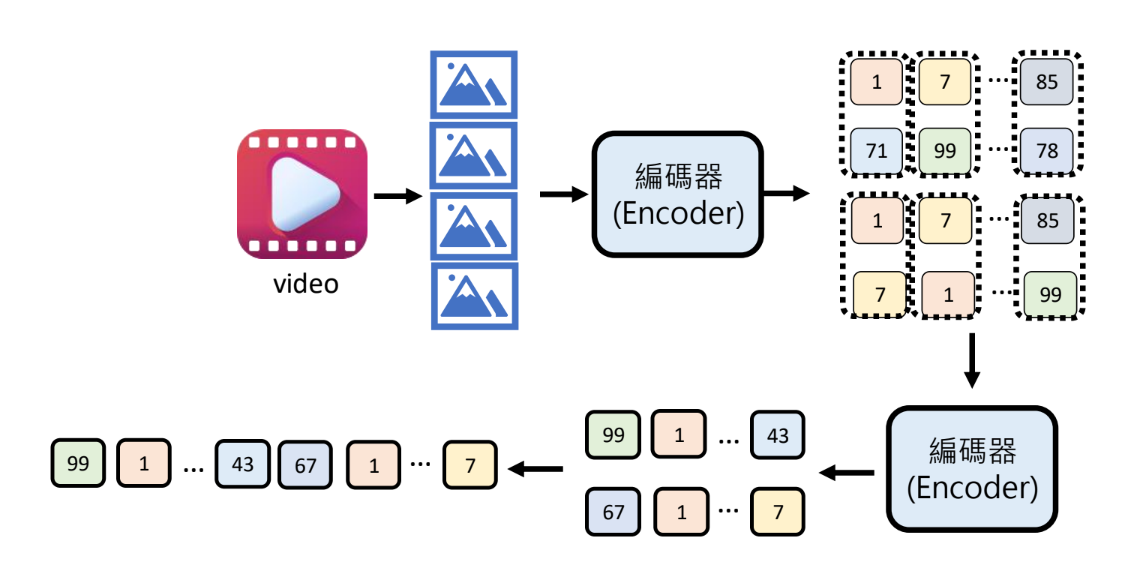
生成影片
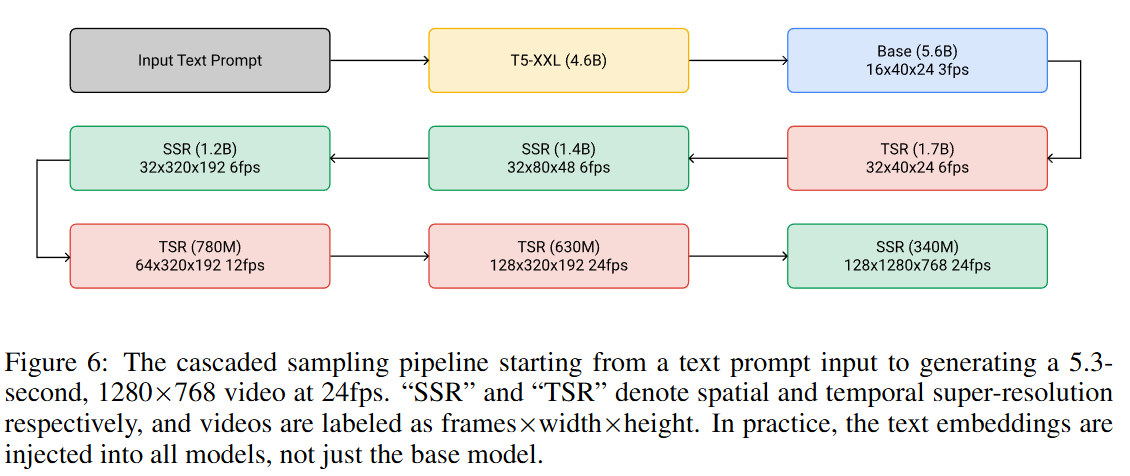
sora的模型
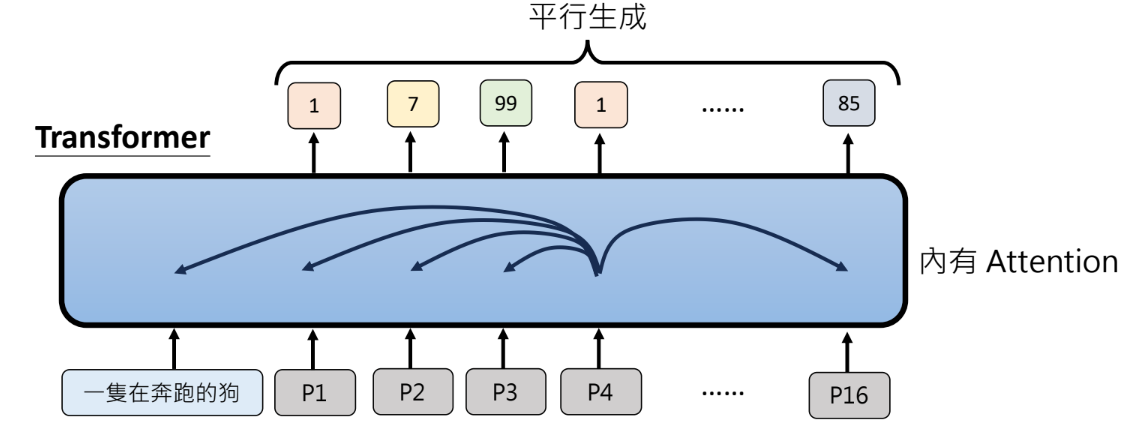
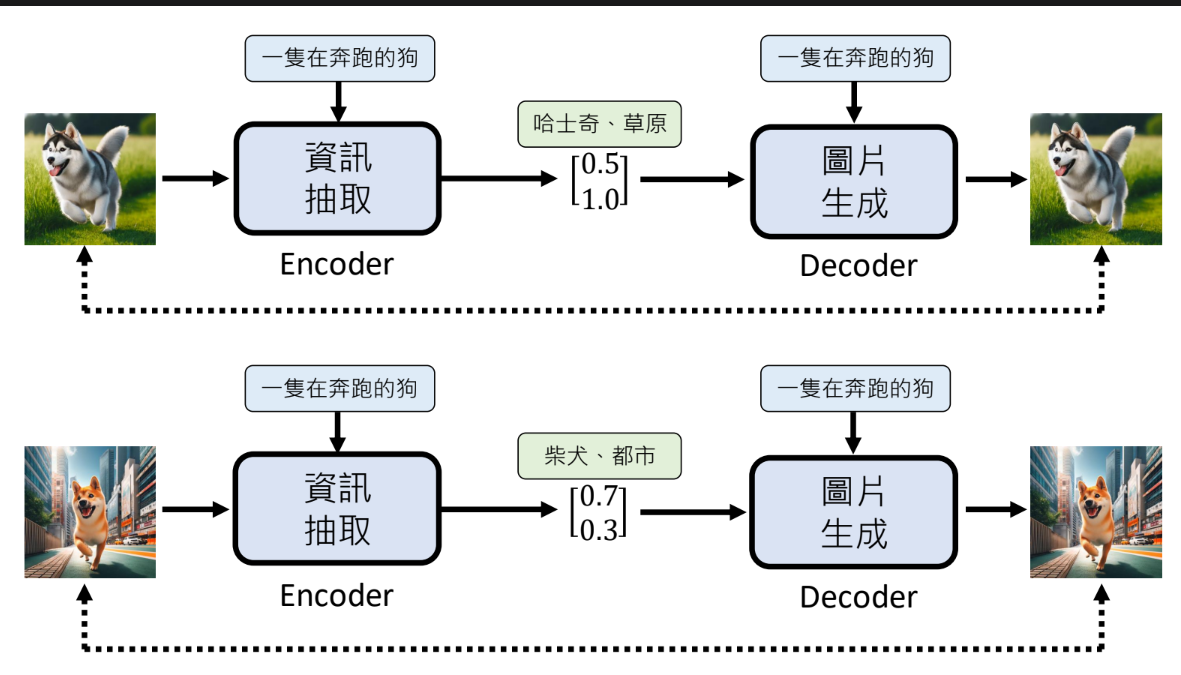
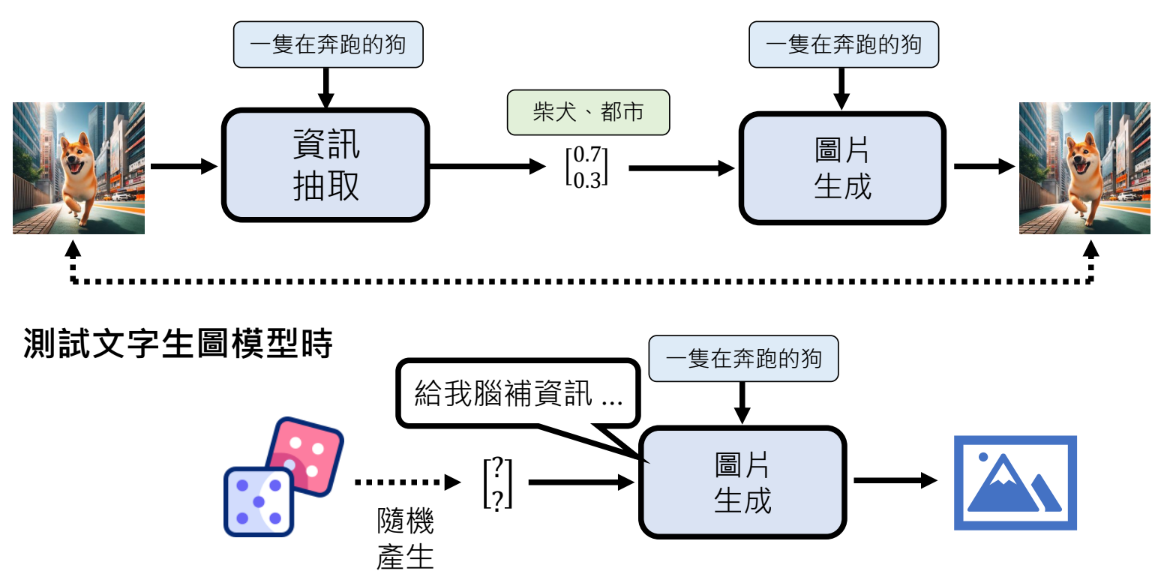
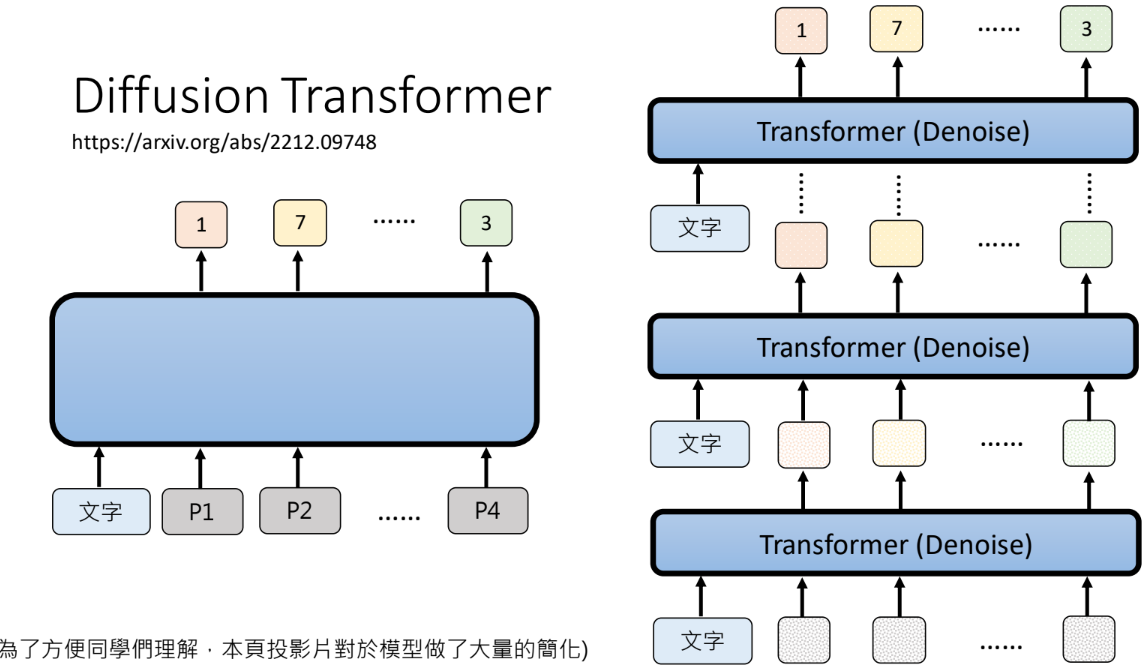
以文字生图为例
https://laion.ai/blog/laion-5b/
image-text Paris 的 LAION 数据集 5.85B
文字生图
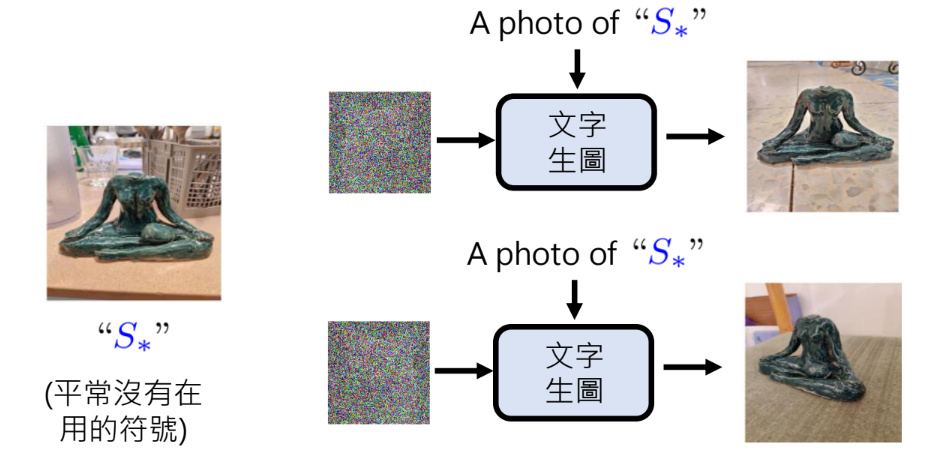
客制化你的图片–用一个特殊符号来代替
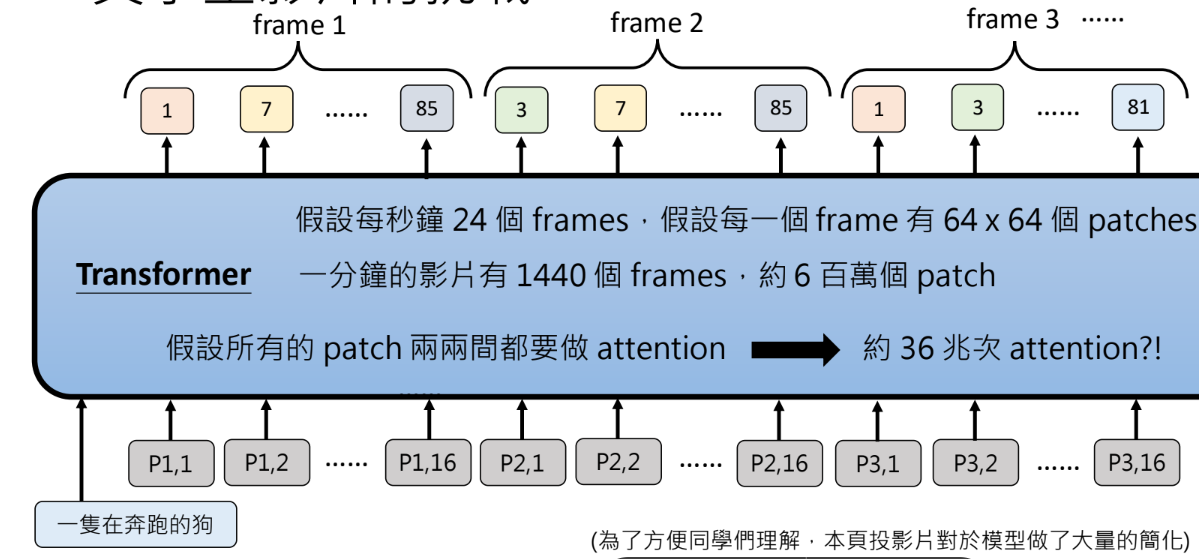
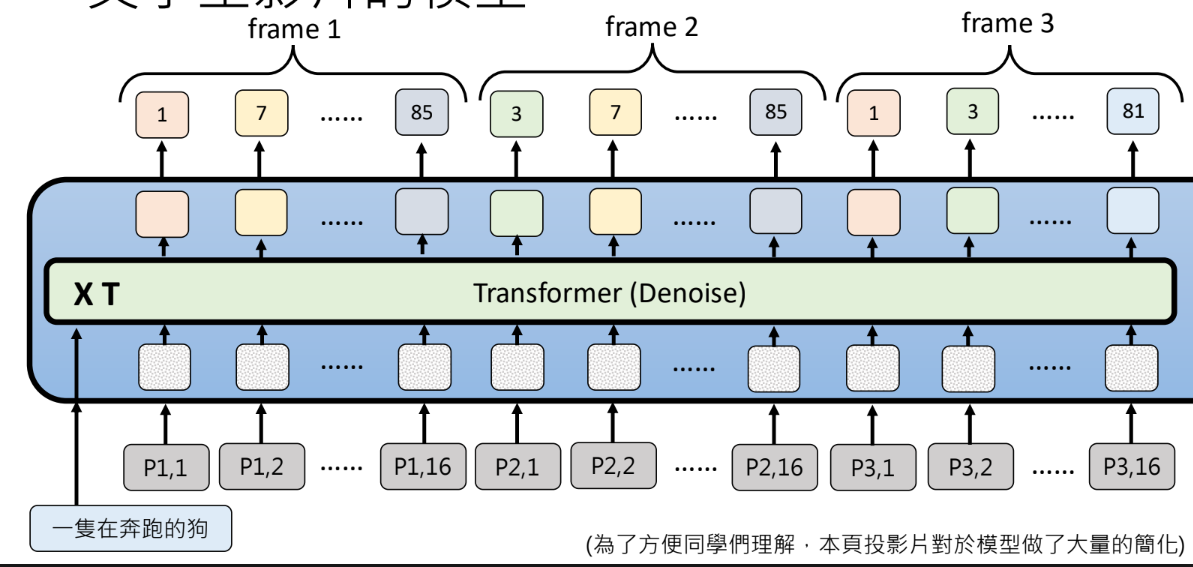
文字生影片
分解attention
- Spatio- temporal attention
- Spatial Attention
- Temporal Attention

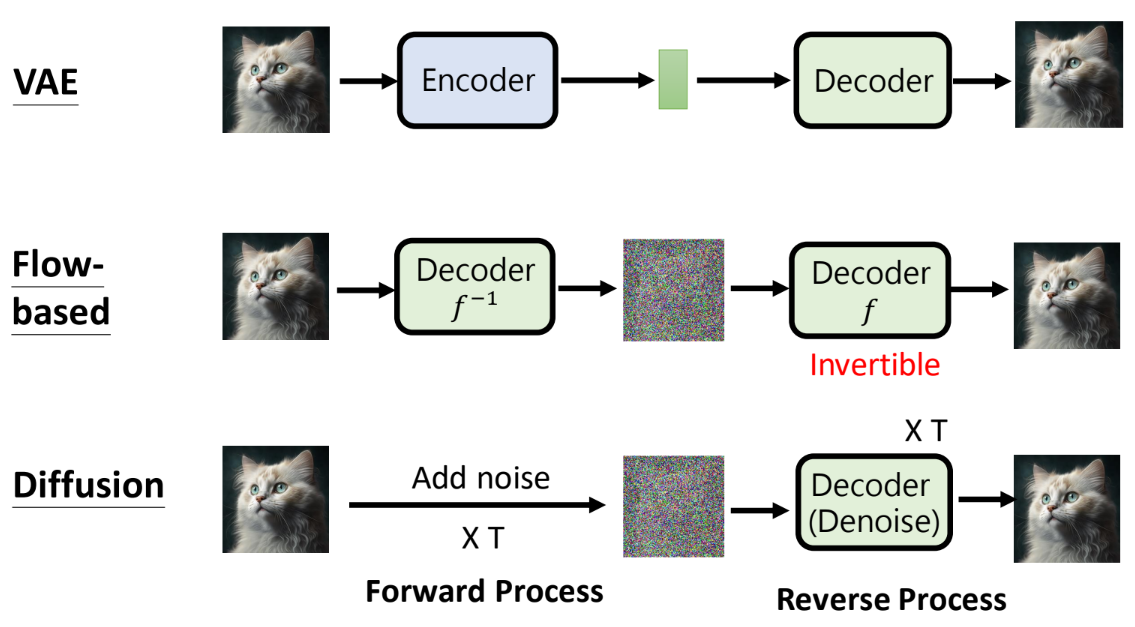
经典影片生成的方法
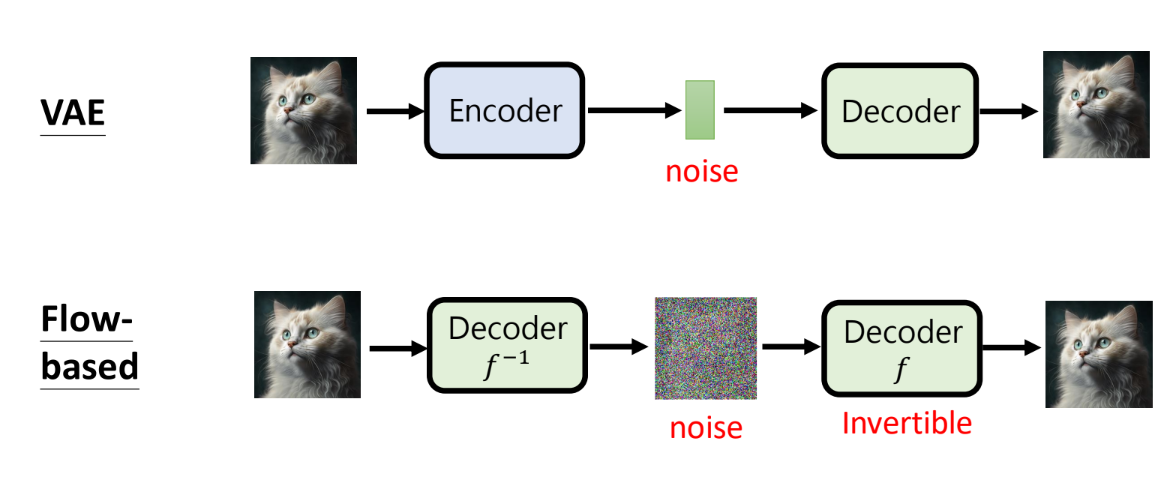
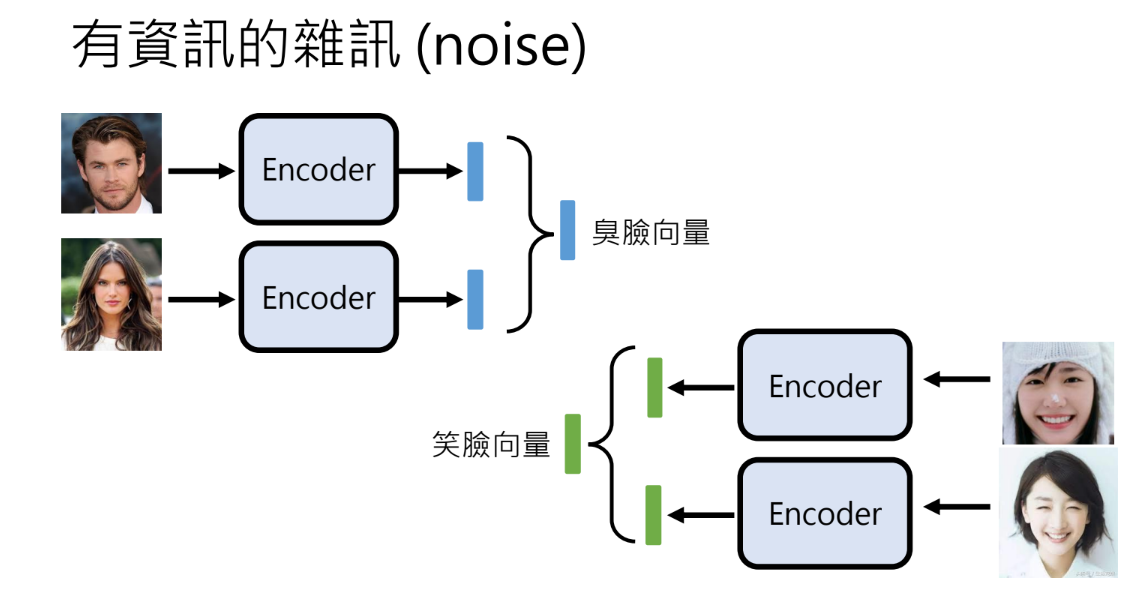
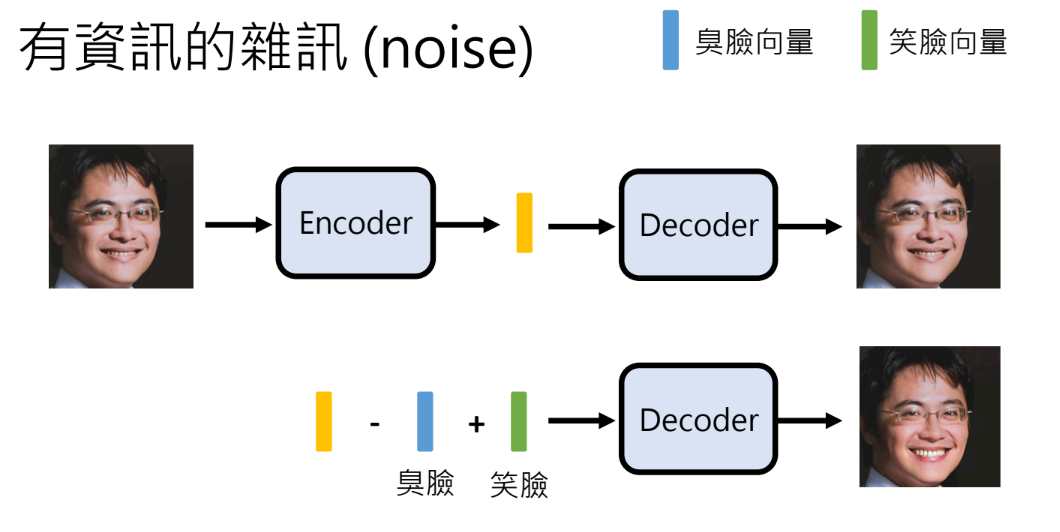
- Variational Auto-encoder(VAE)
- Flow-based Mehtod
- Diffusion Method
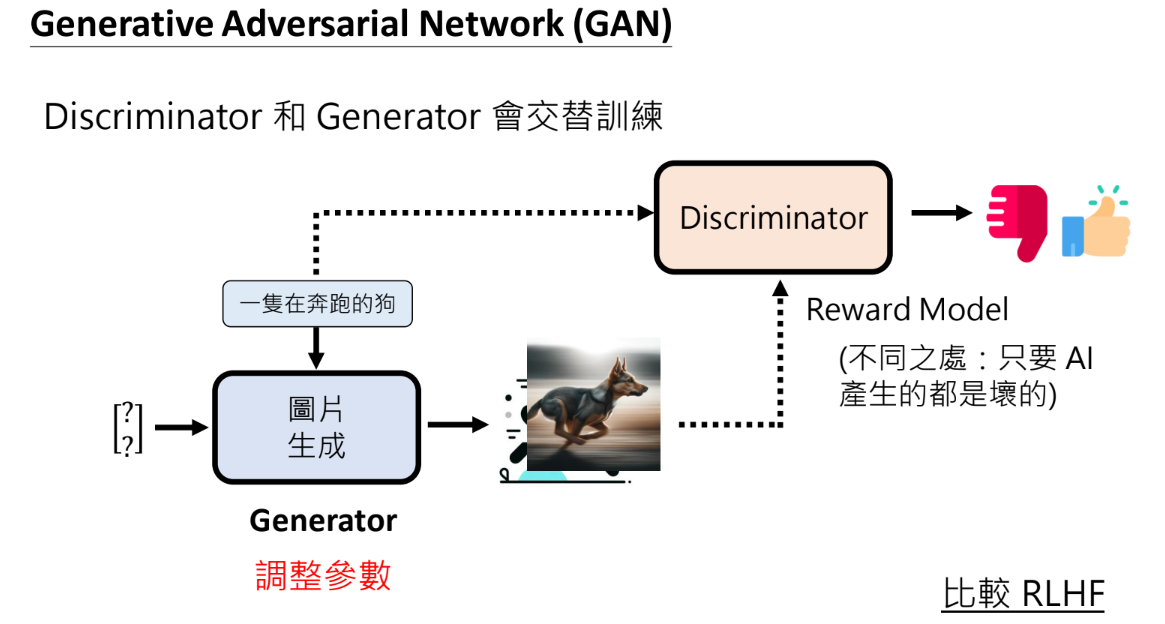
- Generative Adversarial Network(GAN)
Sora 应该是Diffusion model
https://openai.com/index/glow/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)