基于 vLLM 的大模型推理服务部署
本文介绍了基于vLLM框架的高效LLM推理服务部署方案,重点针对Qwen2.5-14B-Instruct-GPTQ-Int4模型在智能客服场景的应用。首先详细说明了环境搭建流程,包括CUDA、PyTorch版本匹配,以及通过pip和源码两种方式安装vLLM。其次系统阐述了vLLM的核心参数优化策略,如prefix缓存、KV缓存量化、调度器优化等关键技术。实验结果表明,经过参数调优后,相比原生Tra
基于vllm的环境搭建部署流程(pip install以及vllm源代码部署两种方式),以及框架、参数优化。
0、背景介绍
大型语言模型(LLM)凭借其强大的语言理解和文本生成能力,已成为内容创作等领域的核心驱动力。然而,在实际生产环境中部署LLM服务面临诸多挑战,尤其是高推理延迟和资源消耗巨大的问题,严重制约了其应用效率与用户体验。
vLLM是一个专为高效LLM推理和服务而设计的高性能开源框架。其核心创新在于采用了先进的 PagedAttention 注意力算法,显著优化了显存管理,能够:
- 大幅提升吞吐量(Throughput): 支持更高的并发请求处理能力。
- 显著降低延迟(Latency): 加快单次请求响应速度。
- 高效利用显存(GPU Memory): 更有效地服务更长上下文或更大的模型。
本文将聚焦于使用 vLLM 部署 Qwen2.5-14B-Instruct-GPTQ-Int4 模型,构建智能客服场景下的推理服务。目标是实现高效、低延迟的自动应答功能,替代或辅助人工处理客户投诉等交互任务。
1、环境搭建与模型准备
# 1.0、(推荐)创建 Python 虚拟环境
# 查看cuda版本
nvcc --version
# 安装虚拟环境
pip install virtualenv
# 创建虚拟环境
virtualenv -p python3.10 vllm
# 进入虚拟环境 ---退出虚拟环境 deactivate
source vllm/bin/activate
# 1.1、必须操作
# 安装对应的pytorch版本 --查看 pip list | grep torch 卸载 pip uninstall torch,版本可以参考https://zhuanlan.zhihu.com/p/672526561
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --extra-index-url https://download.pytorch.org/whl/cu121
# 安装vllm,0.6.6版本vllm需求的torch版本为2.5.1(此处不要求版本,对应即可)
pip install vllm==0.6.6
# 1.2、模型下载准备 安装modelscope
pip install modelscope
# 下载模型
modelscope download --model qwen/Qwen2.5-14B-Instruct-GPTQ-Int4 --local_dir ./Qwen2.5-14B-Instruct-GPTQ-Int4
# 1.3、后检查 完成以上操作,相关组件的版本应为:
CUDA version 12.2
Torch 2.5.1
Driver Version: 535.183.06
# 1.4、其他可能的问题,python基础环境相关
# 准备基础组件
apt-get update
apt-get install python3.10-dev
1.1、任务说明
为验证 vLLM 在智能客服场景下的效果,我们设定以下具体任务:
- 场景: 处理客户投诉的多轮对话。
- 输入: 用户投诉内容及对话历史。
- 核心要求:
- 整理用户诉求: 精准提炼用户的核心投诉点和需求。
- 按模板回复: 根据预设的客服响应模板,生成符合规范、专业且得体的回复文本。
- 模型: Qwen2.5-14B-Instruct-GPTQ-Int4
- 评估指标:
- 准确率: 使用余弦相似度 (Cosine Similarity) 计算大模型生成的回复与人工客服标准回复之间的语义相似度。设定经验阈值 0.85,相似度 >= 0.85 视为回复正确。
- 响应时间 (Latency): 从请求发出到收到完整回复的平均时间。
基线测试 (Transformers 框架): 使用 Hugging Face transformers 库加载并运行相同的量化模型 (Qwen2.5-14B-Instruct-GPTQ-Int4),保持 temperature 等生成参数一致。在相同的硬件和测试集上,测得基线性能为:
- 平均响应时间: 1.95 秒
- 总准确率 (Cosine Sim >= 0.85): 81.2%
接下来的章节将展示如何利用 vLLM 部署该模型,并对比其在响应速度和推理能力上的优化效果,同时观察准确率的变化。
2、vLLM推理加速与参数调优
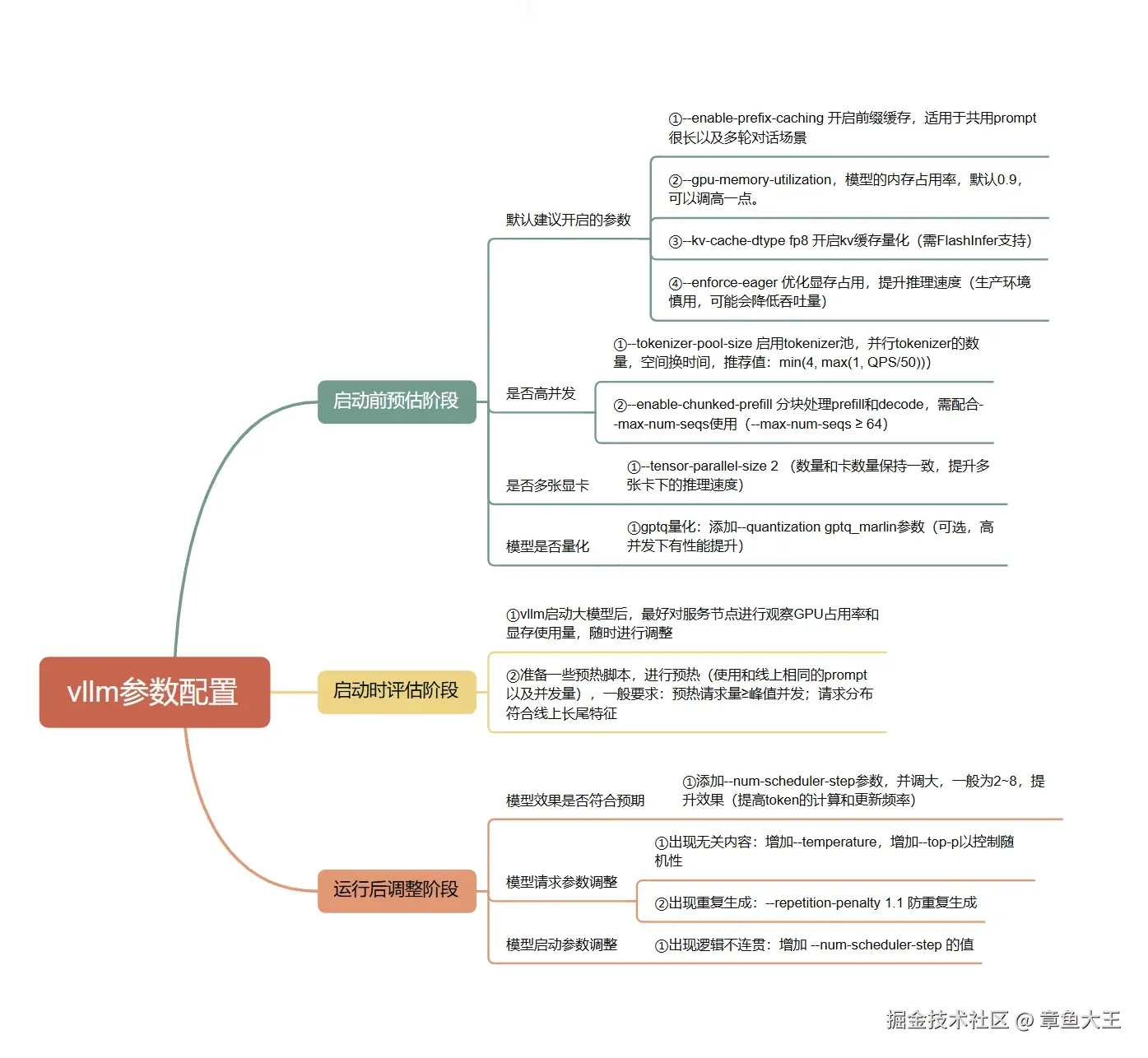
2.1、参数配置导图
配置:vLLM参数遵循 "预估-预部署-监控-迭代" 来进行调整。下方思维导图展示完整配置及优化路径:
# 示例
vllm serve Qwen2.5-14B-Instruct-GPTQ-Int4 --tensor-parallel-size 2 --gpu-memory-utilization 0.95 --enable-prefix-caching --num-scheduler-steps 8 --enforce-eager
2.2、参数说明
2.2.1、--enable-prefix-caching
工作原理:当多个请求共享相同前缀(如系统提示词)时,自动缓存并复用对应的KV缓存块
优势:减少重复计算,提升吞吐量;通过哈希匹配实现跨请求缓存共享
2.2.2、--kv-cache-dtype fp8
工作原理:将KV缓存精度从FP16降至FP8
优势&劣势:可以节省显存,但是可能引入精度损失
具体命令:
# 1、下载
curl -L -O https://github.com/flashinfer-ai/flashinfer/releases/download/v0.1.6/flashinfer-0.1.6+cu121torch2.4-cp310-cp310-linux_x86_64.whl
wget https://github.com/flashinfer-ai/flashinfer/releases/download/v0.1.6/flashinfer-0.1.6+cu121torch2.4-cp310-cp310-linux_x86_64.whl
# 2.2、安装whl文件
pip install flashinfer-0.1.6+cu121torch2.4-cp310-cp310-linux_x86_64.whl
# 2.3、设置环境变量
export VLLM_ATTENTION_BACKEND=FLASHINFER
2.2.3、--num-scheduler-step
工作原理:调度器优化,控制调度器迭代次数,影响请求处理粒度。较高的调度步骤可能意味着模型在生成每个 token 时会进行更多的计算和更新,从而可能提高生成的质量。增加调度步骤的数量可能会导致模型在生成过程中需要更多的计算资源和内存。每个调度步骤都可能涉及到对模型状态的更新和计算,这在处理大请求时可能会导致内存压力增大。
优势&劣势:提高推理质量,占用更多显存
推荐配置:常规请求:默认值(通常4-8),长文本请求则使用:--num-scheduler-step 1
2.2.4、--tokenizer-pool-size
工作原理:tokenizer并行池
推荐配置:根据并发需求调整
2.2.5、--tensor-parallel-size
工作原理:张量并行,将模型的计算和存储分布在多个 GPU 之间,以提高训练和推理的效率。
推荐配置:根据显卡数量配置
2.2.6、--enable-chunked-prefill
工作原理:prefill是计算密集型,GPU的利用率较高;而decode是存储密集型,GPU的利用率较低,IO消耗大。vLLM会先处理prefill请求,再处理decode请求。chunked prefill将请求分块,同时处理prefill请求和decode请求,并且decode请求优先级高于prefill请求。
推荐配置:高并发场景下推荐打开
2.2.7、--gpu-memory-utilization
工作原理:控制模型的GPU内存比例,默认值0.9。
推荐配置:一般用在单卡部署多个模型的情况下:推荐值 = (模型权重 + KV缓存 + 安全缓冲) / GPU总显存。如果是单卡单模型、多卡单模型部署,则使用默认值或配置成0.95、0.98均可。
配置示例: 模型:Qwen2.5-14B模型(如果是Qwen2.5-14B-Instruct-GPTQ-Int4则模型显存需求/4)
显存占用:
①模型:14B * 4字节 = 56 GB;
②kvcache占用(基于batch_size=32, max_seq_len=2048估算):约 54 GB;
③其他安全缓冲:4GB
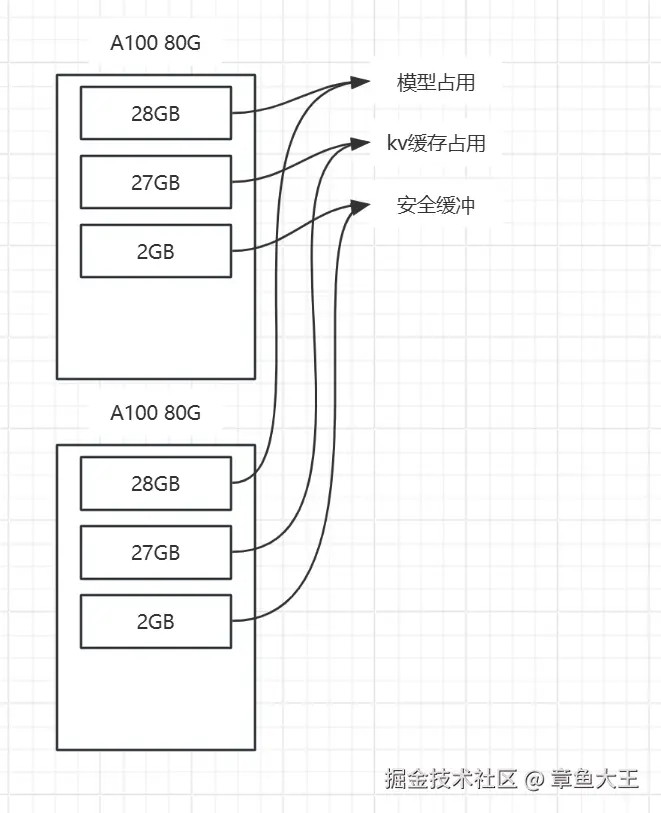
因此每张显卡约占(56+54+4)/2 = 57 GB,因此gpu-memory-utilization的推荐值约为:57/80 = 0.71。
不过,预估值只能是大概的计算方式,因为vllm中除了kv缓存,还有tokenizer缓存等等内容,实际需要多次调试才能得到一个合适的值。
2.2.8、分块优化参数
工作原理:vllm的核心技术-pageAttention,将kv缓存划分成固定大小的块,通过块表管理物理块与逻辑序列的映射,支持不同请求间的块共享。
推荐配置:以下参数需协同配置,且参考业务真实需要进行配置,例如: --max-num-batched-tokens 12288 --max-model-len 12288 --block-size 32 优化分块+并发以提升效率
2.3、vllm源码部署
实际测试的时候还发现,源码编译安装的性能相比于pip安装的性能,有了进一步的提升。猜测的原因可能有:更合适的CUDA工具链、更针对性的编译优化等等,pip预编译的安装包可能使用的是更通用的方案
2.3.1、部署步骤
# 本地构建按照cutlass
git clone https://github.com/NVIDIA/cutlass.git
# 一些必须的软件包
apt-get install cmake
# 如果安装cmake时报错或者版本号不符合要求,使用python环境的安装
pip install cmake
# 然后检查安装
cmake --version
# 构建目录并运行cmake
export CUDACXX=${CUDA_INSTALL_PATH}/bin/nvcc
export CUDACXX=/usr/local/cuda/bin/nvcc
mkdir build && cd build
cmake .. -DCUTLASS_NVCC_ARCHS=90a
# 如果用了虚拟环境,可能需要指定cmake,例如:
/usr/bin/cmake .. -DCUTLASS_NVCC_ARCHS=90a
# 基于命令行启动vllm框架的环境配置上:
git clone https://github.com/vllm-project/vllm.git
cd vllm
python use_existing_torch.py
pip install -r requirements-build.txt
export MAX_JOBS=5
# 进入vllm路径,使用本地cutlass进行编译
VLLM_CUTLASS_SRC_DIR=/path/to/cutlass pip install -e . --no-build-isolation
3、vllm运行原理
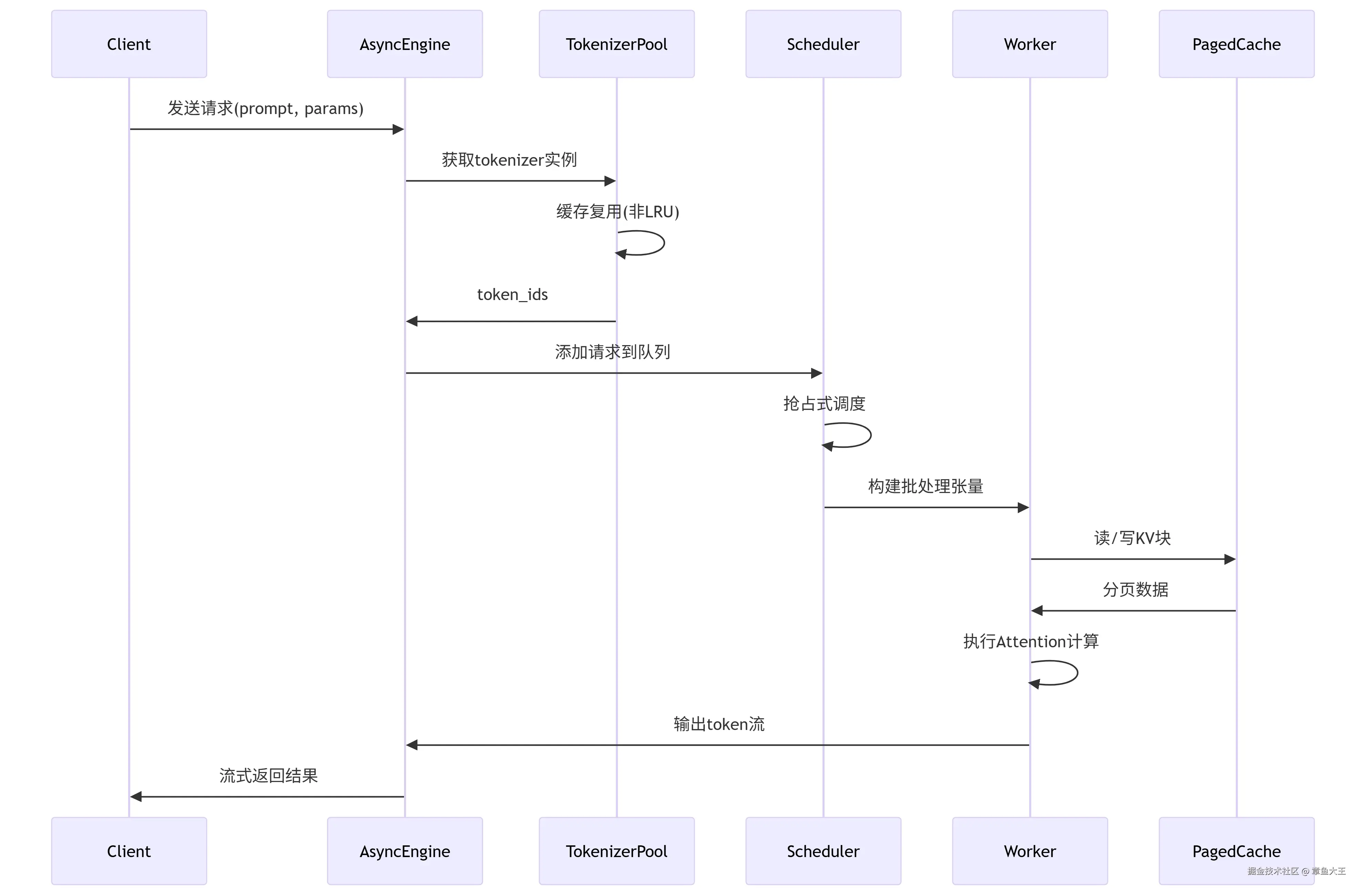
3.1、推理引擎核心
LLMEngine和类AsyncLLMEngine是 vLLM 系统运行的核心,处理模型推理和异步请求处理。
request请求处理时序图:
3.1.1、PagedAttention设计
虚拟内存式管理kv块,且块大小可配(--block-size)、物理块池全局共享、按需分配/释放、自动合并空闲块(碎片整理)、预取机制
在跨请求共享中,提供相同前缀请求共享kv块、多轮对话历史持久化
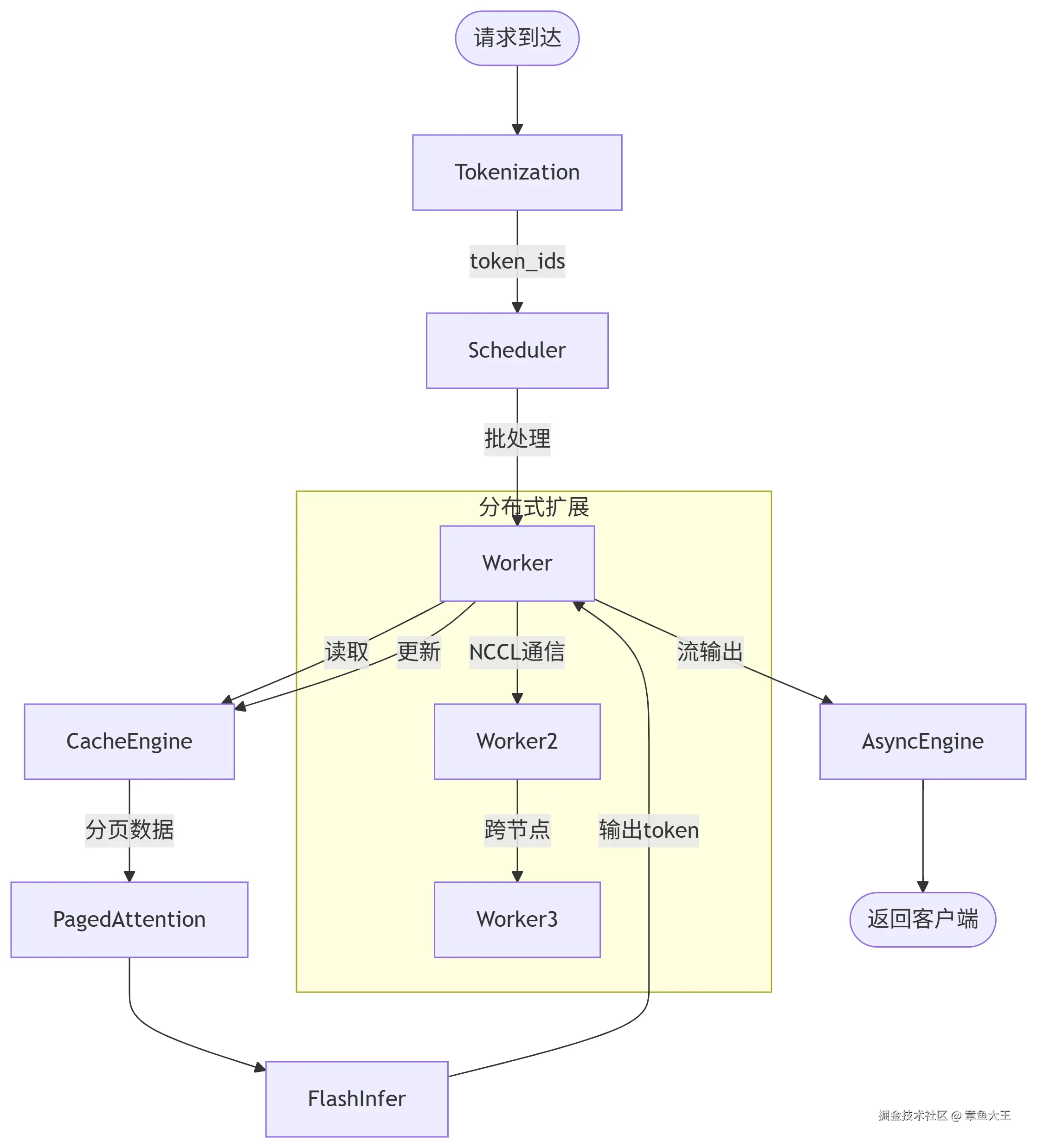
3.1.2、分布式推理引擎
三级并行架构:Tensor并行、pipline并行、数据并行
vllm分布式处理逻辑:
3.2、重要参数
3.2.1、guided_json
guided_json非启动参数,而是推理入参。使用示例:
{
"messages": [{
"role": "system",
"content": "You are a helpful assistant."
}, {
"role": "user",
"content": "请你生成一首描写春天的七言绝句"
}],
"model": "Qwen2.5-14B-Chat",
"temperature": 0,
"guided_json": {
"properties": {
"title": { "title": "Title", "type": "string" },
"content": { "title": "Content", "type": "string" }
}, "required": ["title", "content"],
"title": "Poem",
"type": "object"
}
}
参数原理:
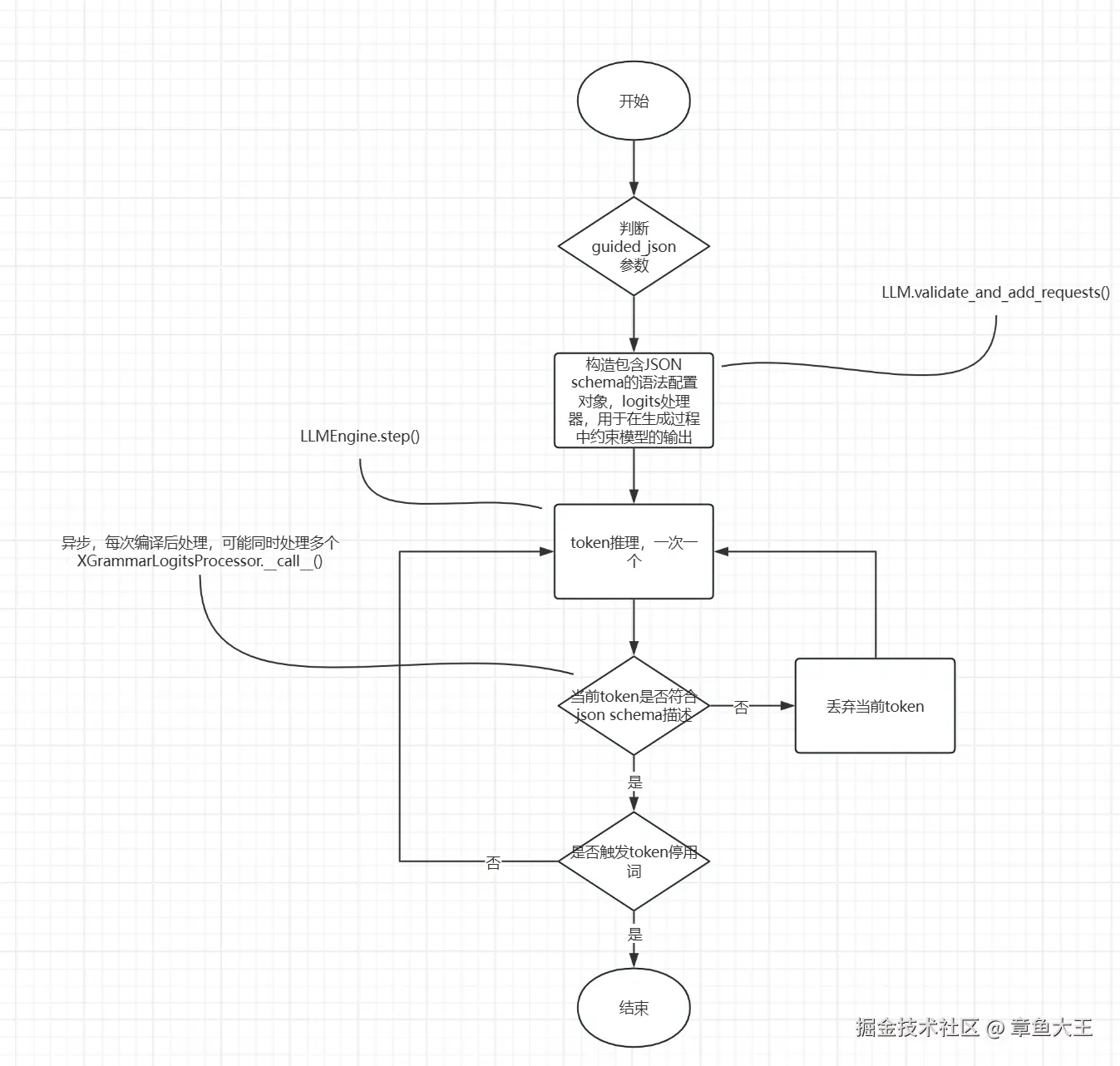
性能,以下是一些其他人经过测试得出的性能结果:
测试:显卡:H100 80GB;model:qwen1.5-14B-chat;数据:token长度 512 的随机提问的请求
| 并发 | token生成速度 | 平均首响时间 | |
|---|---|---|---|
| Guided_json | 100 | 70tokens/s | 1700 毫秒 |
| 非guided_json | 100 | 800tokens/s | 75 毫秒 |
结论:
1、json解码逻辑处理器不支持异步解码,vllm的启动参数中num_scheduler_steps必须为1;
2、受json解码逻辑处理器的影响,推理后的token解码阶段性能受处理器影响较大;但是相同JSON Schema共享编译结果(基于tokenizer哈希),工程上可以对相同json schema的请求先进行预热。
3、首响耗时的延迟主要受JSON Schema复杂度的影响
4、结果
4.1、任务优化结果
基于两张4090 24GB显卡部署Qwen2.5-14B-Instruct-GPTQ-Int4模型执行任务,测试vllm框架
| 方法 | 并发 | 平均响应时间 | 准确率 | 备注 |
|---|---|---|---|---|
| transformers框架 | 1 | 1.95s | 81.2% | 对照组 |
| vllm框架,无参启动 | 1 | 1.87s | 81.5% | |
| vllm框架,无参启动 | 2 | 2.42s | 81.7% | |
使用--enable-prefix-caching参数 |
1 | 1.72s |
81.5% | |
使用flashinfer推理引擎,搭配--kv-cache-dtype fp8参数使用 |
1 | 1.836s | 82% | |
使用--num-scheduler-step 8参数 |
1 | 1.72s |
81.9% | |
使用--tokenizer-pool-size 2参数 |
1 | 1.86s | 82.2% | 1、该参数设置过大会报错,2张4090的配置下最多设置成2; 2、对性能无影响,主要是对资源占用率的优化,可能会降低运行时对显存的占用(实测不明显) |
使用--tensor-parallel-size 2参数 |
1 | 1.87s | 81.9% | 对性能无影响,可能会降低运行时对显存的占用 |
| 使用以上所有参数 | 1 | 1.60s |
81.8% | |
| 使用以上所有参数 + vllm源码部署启动 | 1 | 1.55s |
82% | 最大提升推理速度约20% |
todo 后续补充高并发场景数据。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取(扫下方二v码即可100%领取)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 40
40 0
0- 0



 已为社区贡献174条内容
已为社区贡献174条内容

所有评论(0)