AI-03a3.Python深度学习-神经网络入门-多分类问题
这个主题分类问题与前面的影评分类问题类似,二者都是对简短的文本片段进行分类。但这个问题有一个新的限制条件:输出类别从 2 个变成 46 个。输出空间的维度要大得多。])
前言
AI-03a2.Python深度学习-神经网络入门-二分类问题示例介绍了如何用密集连接神经网络将向量输入划分为两个互斥的类别。但如果类别不止两个,要怎么做呢?
本文将构建一个模型,把路透社新闻划分到 46 个互斥的主题中。由于有多个类别,因此这是一个多分类(multiclass classification)问题。由于每个数据点只能划分到一个类别中,因此更具体地说,这是一个单标签、多分类(single-label, multiclass classification)问题。如果每个数据点可以划分到多个类别(主题)中,那就是多标签、多分类(multilabel, multiclass classification)问题。
加载路透社数据集
本文将使用路透社数据集,它包含许多短新闻及其对应的主题,由路透社于 1986 年发布。它是一个简单且广泛使用的文本分类数据集,其中包括 46 个主题。某些主题的样本相对较多,但训练集中的每个主题都有至少 10 个样本。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import keras.layers as layers
from tensorflow import keras
from keras.datasets import reuters
from keras.utils import to_categorical
# 将数据限定为前 10 000 个最常出现的单词
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
print(f"有{len(train_data)}个训练样本,{len(test_data)}个测试样本。")
print(f"训练样本的形状为:{train_data.shape}")
print(f"测试样本的形状为:{test_data.shape}")
print(f"训练标签的形状为:{train_labels.shape}")
print(f"测试标签的形状为:{test_labels.shape}")
print(f"第一个训练样本为:{train_data[0]}")
print(f"第一个训练标签为:{train_labels[0]}")
# 将新闻解码为文本
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswire = " ".join([reverse_word_index.get(i - 3, "?") for i in train_data[0]])
print(f"\n将新闻解码为文本: {decoded_newswire}")
准备数据
将标签向量化有两种方法:既可以将标签列表转换为一个整数张量,也可以使用 one-hot编码。one-hot 编码是分类数据的一种常用格式,也叫分类编码(categorical encoding)。在这个例子中,标签的 one-hot 编码就是将每个标签表示为全零向量,只有标签索引对应的元素为 1 。
Keras 有一个内置方法 tensorflow.keras.utils.to_categorical 可以实现这种编码。
我们可以都使用实验一下。
def vectorize_sequences(sequences, dimension=10000):
""" 用 multi-hot 编码对整数序列进行编码 """
results = np.zeros((len(sequences), dimension), dtype=np.int32)
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1
return results
## 将训练数据向量化
x_train = vectorize_sequences(train_data)
## 将测试数据向量化
x_test = vectorize_sequences(test_data)
## 标签向量化
def to_one_hot(labels, dimension=46):
"""
one-hot 编码是分类数据的一种常用格式,也叫分类编码(categorical encoding)
标签的 one-hot 编码就是将每个标签表示为全零向量,只有标签索引对应的元素为 1
"""
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
# y_train = to_one_hot(train_labels)
# y_test = to_one_hot(test_labels)
# # Keras 有一个内置方法可以实现这种编码
y_train = to_categorical(train_labels, num_classes=46)
y_test = to_categorical(test_labels, num_classes=46)
print("\n准备数据, 用 multi-hot 编码对整数序列进行编码")
print(f"x_train type: {type(x_train)}, shape: {x_train.shape}, dtype: {x_train.dtype}")
print(f"x_test type: {type(x_test)}, shape: {x_test.shape}, dtype: {x_test.dtype}")
print(f"y_train type: {type(y_train)}, shape: {y_train.shape}, dtype: {y_train.dtype}")
print(f"y_test type: {type(y_test)}, shape: {y_test.shape}, dtype: {y_test.dtype}")
模型定义
这个主题分类问题与前面的 影评分类问题 类似,二者都是对简短的文本片段进行分类。但这个问题有一个新的限制条件:输出类别从 2 个变成 46 个。输出空间的维度要大得多。
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(46, activation="softmax")
])
编译模型
对于这个例子,最好的损失函数是 categorical_crossentropy(分类交叉熵)。它衡量的是两个概率分布之间的距离,这里两个概率分布分别是模型输出的概率分布和标签的真实分布。我们训练模型将这两个分布的距离最小化,从而让输出结果尽可能接近真实标签。
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
验证集
从训练数据中留出 1000 个样本作为验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:]
训练模型
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
## 绘制训练损失和验证损失
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
# plt.show()
## 绘制训练精度和验证精度
# plt.clf()
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "ro", label="Training accuracy")
plt.plot(epochs, val_acc, "r", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.title("Training and validation loss / accuracy")
plt.ylabel("Loss / Accuracy")
plt.legend()
plt.show()
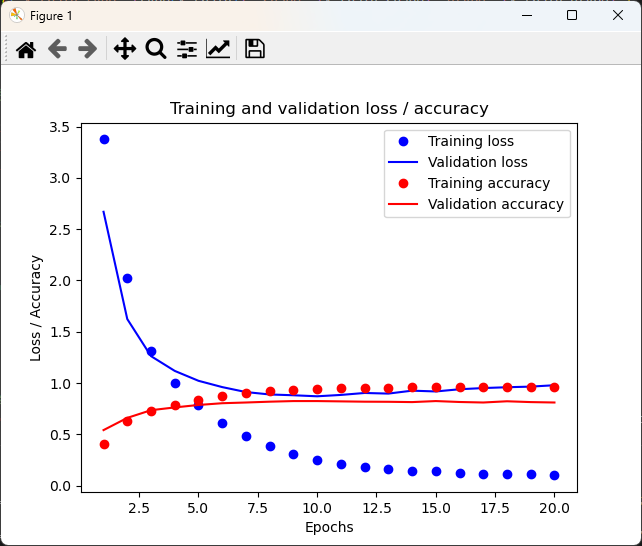
从头开始训练一个模型
模型在 9 轮之后开始过拟合。我们从头开始训练一个新模型,训练 9 轮,然后在测试集上评估模型
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(46, activation="softmax")
])
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
## 模型在 9 轮之后开始过拟合
model.fit(x_train, y_train, epochs=10, batch_size=512)
results = model.evaluate(x_test, y_test)
print(f"\nresults: {results}")
# results: [0.9338052868843079, 0.7960819005966187]
这种方法可以达到约 80% 的精度。对于均衡的二分类问题,完全随机的分类器能达到 50%的精度。但在这个例子中,我们有 46 个类别,各类别的样本数量可能还不一样。那么一个随机基准模型的精度是多少呢?我们可以通过快速实现随机基准模型来验证一下。
## 一个随机基准模型的精度是多少?
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
his_array_mean = hits_array.mean()
print(f"\n一个随机基准模型的精度: {his_array_mean}")
# 一个随机基准模型的精度: 0.188780053428317
可以看到,随机分类器的分类精度约为 19% 。从这个角度来看,我们的模型结果看起来相当不错。
小结
- 如果要对 N 个类别的数据点进行分类,那么模型的最后一层应该是大小为 N 的 Dense 层。
- 对于单标签、多分类问题,模型的最后一层应该使用 softmax 激活函数,这样可以输出一个在 N 个输出类别上的概率分布。
- 对于这种问题,损失函数几乎总是应该使用分类交叉熵。它将模型输出的概率分布与目标的真实分布之间的距离最小化。
- 处理多分类问题的标签有两种方法:
- 通过分类编码(也叫 one-hot 编码)对标签进行编码,然后使用 categorical_crossentropy 损失函数;
- 将标签编码为整数,然后使用 sparse_categorical_crossentropy 损失函数。
- 如果你需要将数据划分到多个类别中,那么应避免使用太小的中间层,以免在模型中造成信息瓶颈。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)