如何让LLM变得又纯又欲——Memorization Sinks: Isolating Memorization during LLM Training 论文阅读笔记
文本是针对 Memorization Sinks: Isolating Memorization during LLM Training 这篇论文的阅读笔记,这篇文章介绍的是一种LLM Unlearning的新方法,同样采取的是记忆区隔离的方法,但在记忆区的选择和隔离上做了自己的优化
Memorization Sinks: Isolating Memorization during LLM Training
一句话总结
这篇文章介绍了一种unlearning的方法,这里为了便于理解,我把unlearning的目标设定为情史,unlearning这个线路的研究多数都抱有这样一个目标:
让一个渣男(LLM)在忘掉所有情史(特定知识,尤其是带版权的)的情况下,不丢失任何撩骚技能(比如指令跟随、推理能力)。
即,不能出现电视剧里一失忆,男主直接变小白的情况。
这篇文章介绍的方法是:
先给模型的MLP参数人工划成两个区域,一半负责撩骚技能,一半专门负责记忆情史,而且给每个聊过的女朋友都配一小片专属记忆区(若干神经元)。
在训练的时候,撩骚技能区始终接收gradient;而情史区中,只有特定女朋友出现的时候,对应的少数神经元才会参与前后向的运算,比如,女朋友A的情史作为训练语料的时候,女朋友A的专属记忆区才会参与前向,并接受gradient。每个女朋友都会随机挑情史区中的一小撮神经元作为自己的专属记忆区。
在unlearning的时候,直接把整个记忆情史的神经元剪掉(所有女朋友的情史全剪掉),留下的就是一个忘却前尘但技能满点的渣男了。
这个专门负责记忆情史以便以后清空的参数区域,被作者称为Memorization Sinks 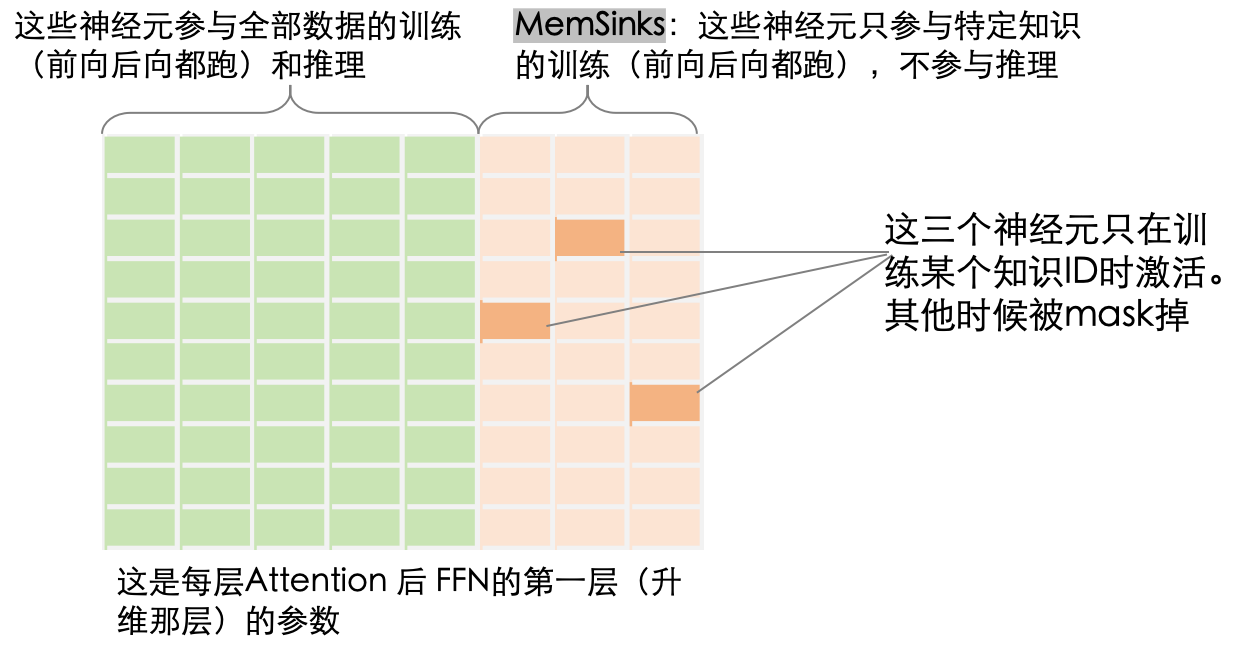
↑图是我画的,各位可以看看作者的原图,能看懂的,我服你是审稿人。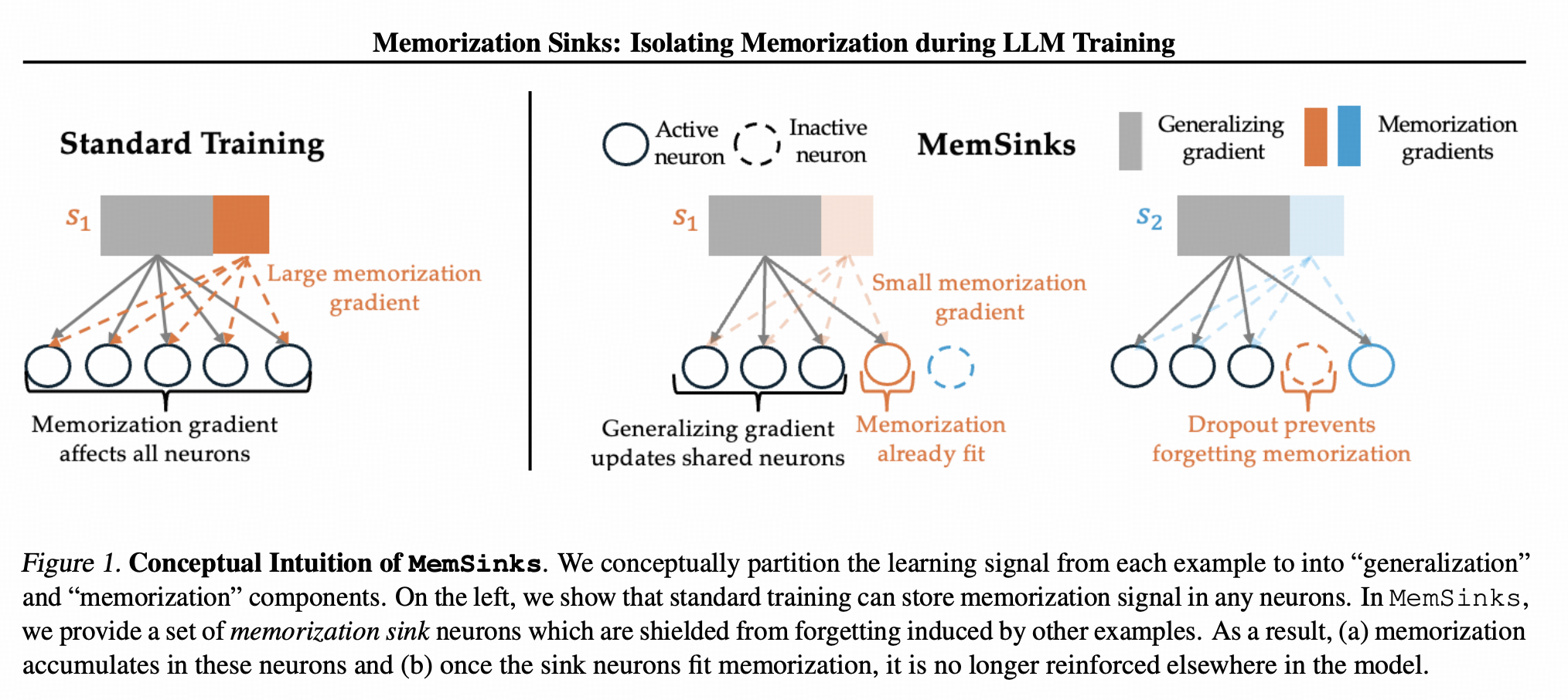
那就不能直接让所有情史都共享Memorization Sinks 吗?
这是作者在Section4 讨论的话题。
先说这个Section的实验配置,这里还是把MLP层分成两片,一片技能区,一片情史区,当然,这个实验里是所有女朋友共享情史区。在训练的时候,如果不在训练情史语料,就有技能区接gradient(前向同时看技能区和情史区);反之,如果训练的是情史语料,就只训练情史区。这就是下图Gradient Mask的意思。
在测试的时候,作者比较了两个训练方案在技能语料上的loss,下图中黄线,是MLP不分区学习的常规训练方案,在技能语料上的loss随着训练展开而下降的趋势。也就是说,这张图上,loss越低说明撩骚技术越强。图上,作者称在技能语料上计算出的loss为validation loss,而不是真的存在一个validation dataset。
紫色<实线>是MLP分区学习方案在测试的时把情史区全部干掉不算(图上的dropout就是这个意思,这个固定区域参数为0,而不是随机dropout)的情况下,撩骚技能的变化趋势;紫色<虚线>则是分区学习方案在测试时不干掉情史区的撩骚技能变化趋势。
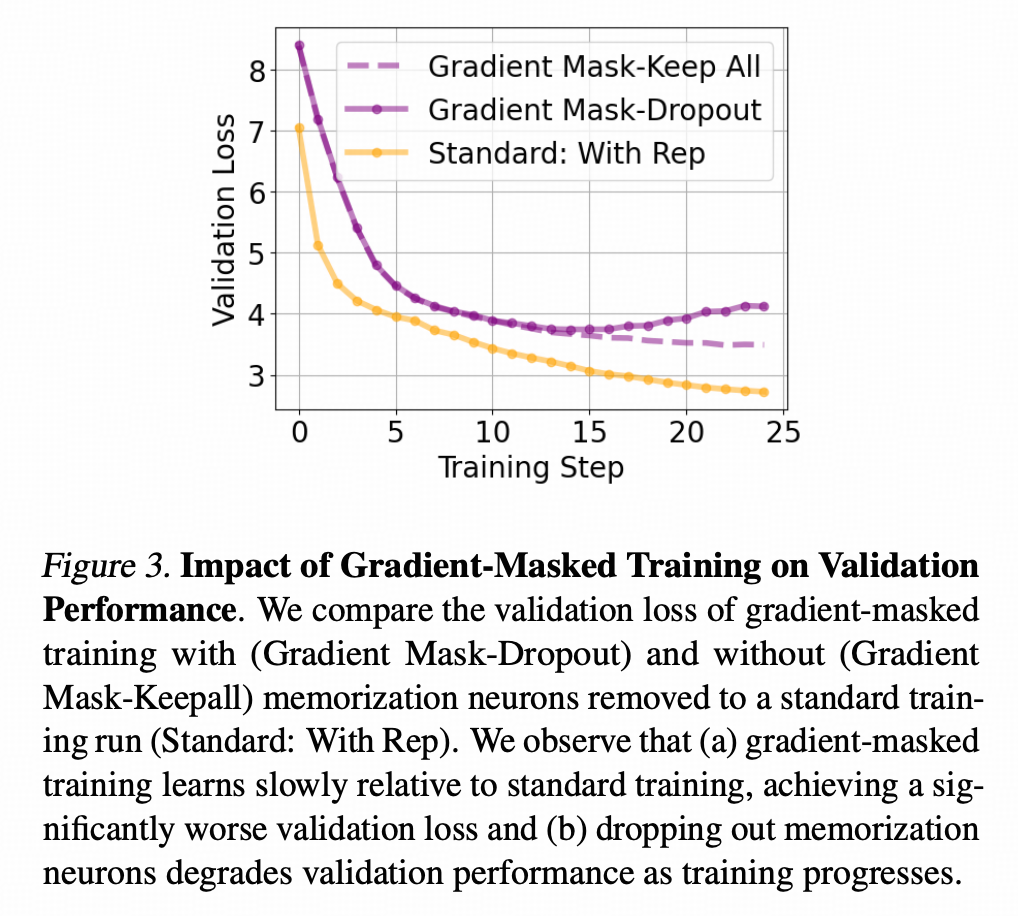
上图能看出来,紫色虚线和黄色实现的loss差距比较大,但如果MLP分区学习不会影响撩骚技能的学习的话,这两根线应该是贴一起的。这两条线分开就说明,分区学习这个方案,即便是在保留所有情史的情况下,也是影响撩骚技能的学习的。
那这是为什么呢?
作者在附录里证明了这个情况,这里只描述个原因:因为技能区和情史区在训练时是同时参与前向的,所以即便情史区不参与技能语料训练,但是作为函数参数的一部分,技能区的参数是在已知情史区长成什么样的情况下学习的,所以学习的过程仍然是互相影响的。
那作者的方法就能work吗?
能。在讲解图之前,我真的想说,这论文保不齐是一作把所有事都做了,就让二作画图,然后一作在大概知道图是个啥样的情况下写正文的。你说说,哪有正文和caption都不讲图例直接说这个图代表什么的?
下图的Val Loss 指的仍然是在情史区以外的语料上计算的loss(横轴都是训练‘步数’,有可能是千步,有可能是epoch数,反正作者没写清楚)
下图中,最左侧a子图中的黄色实线是正常训练方案(不分区)在没训练过情史(Rep)的情况下的最终技能loss,黄色虚线是正常训练方案在训练过情史的情况下的最终技能loss。黄色虚线比实线要更低,说明→_→学习情史有助于磨炼撩骚技能,即学习一些知识性的语料有利于提升模型的泛化能力。
图上的绿线是作者方法MemSinks随着训练的展开,技能loss的下降情况。相比上一节的图我们可以看出来,MemSinks确实获得了更高的技能点。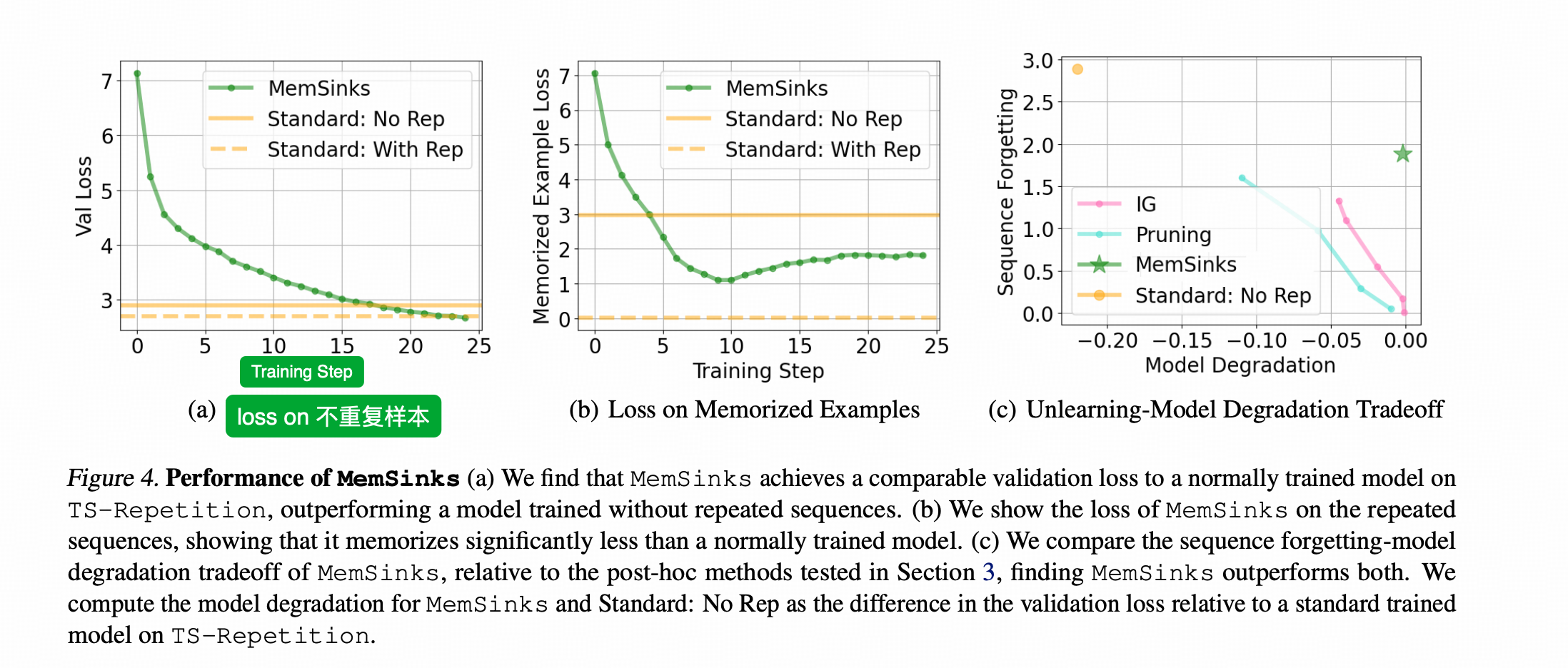
上图中间的b图,是MemSinks在情史语料上的loss。因为黄线是完全没有学习过情史的情况下的loss,所以越好的遗忘水平,loss就应该越接近黄实线。
为什么MemSinks效果更好?
上面两节比较的是<所有女朋友共享情史区>和<每个女朋友占随机几个情史区的神经元>也就是作者MemSinks这个方法的差异。相较于所有女朋友共享情史区的做法,由于每次训练情史的时候,模型训练的神经元组合都不固定,整个情史区其实很可能没有形成比较固定的子空间。每次共同前向的时候,技能区看情史区都像看一团混沌,所以技能区参数受到的影响反而更小。
为什么在训练后期,MemSinks在情史上的loss会涨?
首先要重复一下,这篇文章的方向是unlearning,就是把情史忘了的情况下,不伤害撩骚技能才是更好的方法。作者在跑测试的时候,跑的是把情史区神经元干掉不参数与运算的情况下的loss。图上绿线在训练早期下降代表的是这个模型的技能区的参数也在逐步记忆情史中的相关内容,到训练后期loss逐渐上涨,恰恰说明了技能区把学到的情史相关的记忆忘了。
事实上,在研究模型灾难性遗忘的文章中也明确分析过“训练数据之间的影响会放大遗忘现象” (详见REPLAY CAN PROVABLY INCREASE FORGETTING)
这篇文章的作者也给出了这样一张图↓他跟踪了一个每40步会出现一次的样本的loss的情况,比较了正常训练和MemSink方法针对这个样本的训练loss(即没有把情史区剪掉的前向运算的loss)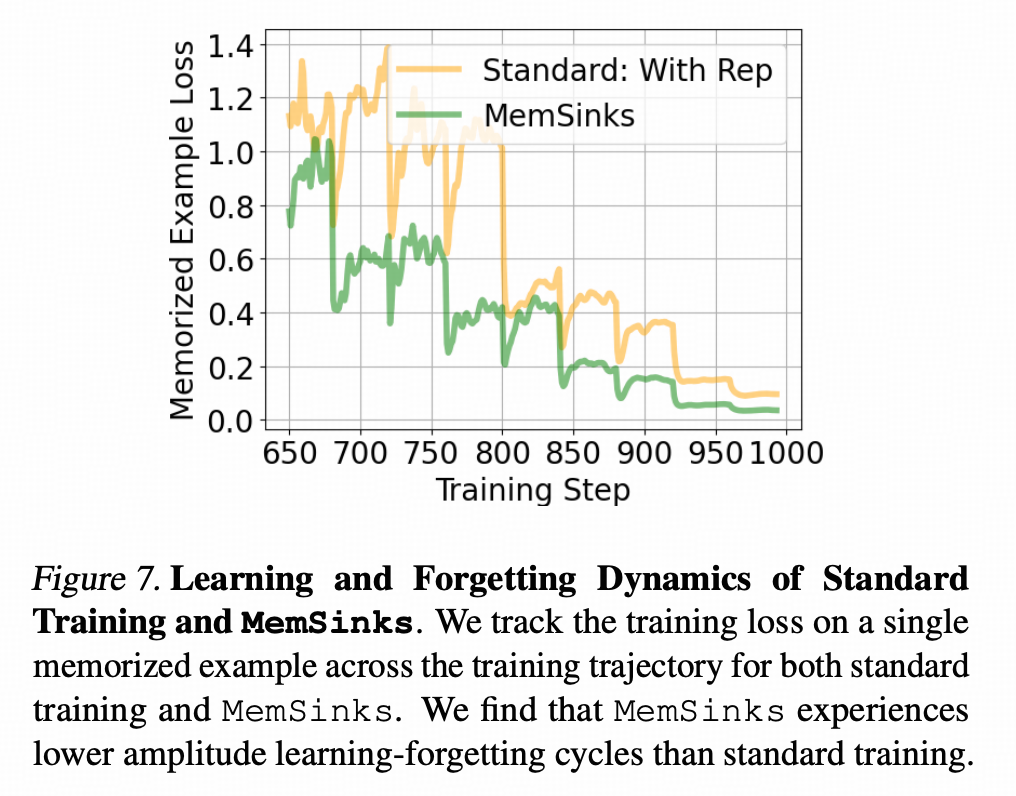
上图可以清楚的看到loss的波动在接近40左右的周期上起伏 ,即模型学习这个样本的时候loss会下降,不学的时候,就会逐渐忘却。
感想
对unlearning这样跟我工作没啥关系的方向,我基本上大半年才找一两篇学习跟进一下。我的体感上,这篇工作算是设计上比较巧的方案,也就是——走位不算太骚,不会导致实践的时候很难和其他方案和需求配合。不过实现这个训练方案还是要在pipeline上做一定的改造。
另外,重复学习部分知识有助于提高模型对应方向的泛化能力,这个认知比较重要,脱离这个文章的场景可能也有借鉴意义。
我还挺服这篇文章的审稿人的,基本还是挑重点技术问题问,没批一通作者的画图和文章布局。这篇文章的布局把几个陪我读论文的大模型都绕沟里去了。自己核心的做法在Section 5(这也太靠后了吧,而且非常碎),想自己看作者怎么做的朋友,拉到文章Appendix的最末 Appendix I,你相信吗,重要的实现细节出现在所有页数的最后。(〝▼皿▼)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)