LangChain快速入门
LangChain:大模型应用的工业级连接器 LangChain由Harrison Chase于2022年创建,现已成为GitHub明星项目(7万+星),被IBM、AWS等巨头采用。其核心价值在于: 统一模型接口:支持OpenAI、LLaMA等主流模型的无缝切换 精准提示控制:通过模板和示例引导模型输出 可复用任务链:串联多个组件形成自动化流程 智能决策代理:支持工具调用和自主规划 典型应用包括:
文章目录
一、LangChain:LLM应用的工业级连接器
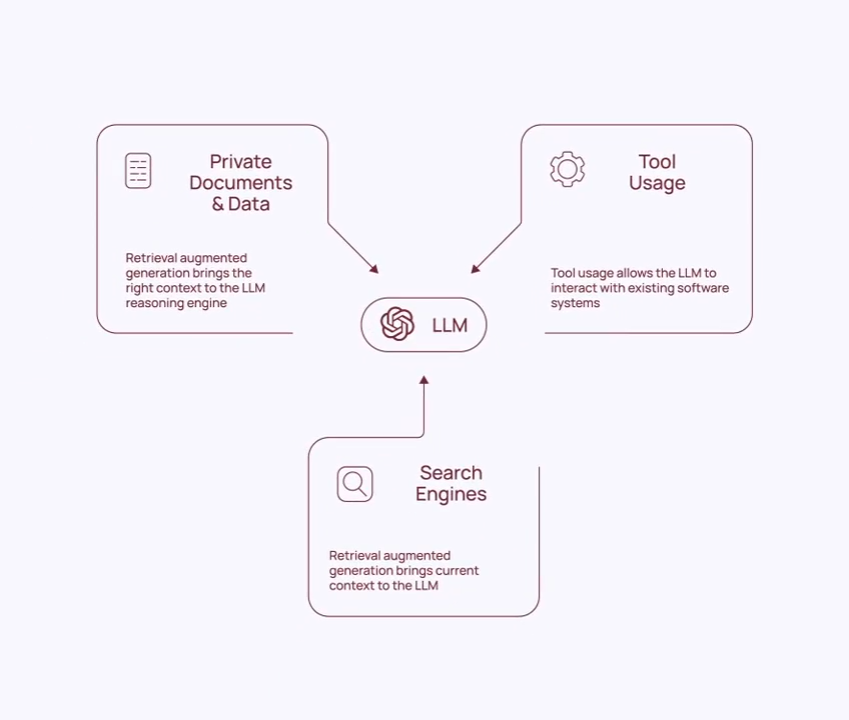
背景与发展
LangChain由前麻省理工学院研究员Harrison Chase于2022年10月创建,现由**LangChain Inc.**公司主导开发。该公司已获得Benchmark领投的3000万美元A轮融资,核心团队包括来自Google Brain、OpenAI和Meta的AI专家。截至2024年,LangChain在GitHub上拥有超过7万颗星,月下载量突破500万次,被IBM、谷歌云、AWS等科技巨头纳入其AI解决方案生态。
应用场景
| 行业 | 典型应用 | 核心价值 |
|---|---|---|
| 金融服务 | 智能投顾报告生成 | 实时市场数据分析+合规报告生成,通过Chains串联数据获取、分析和报告生成流程,利用Indexes管理海量金融文献 |
| 医疗健康 | 电子病历摘要系统 | 长文档处理+医学术语标准化,借助Models调用专业医疗LLM,结合Memory跟踪患者历史诊疗记录 |
| 零售电商 | 个性化推荐引擎 | 用户行为分析+实时商品推荐,通过Agents自主决策是否调用用户数据库或商品库存系统 |
| 教育科技 | 自适应学习助手 | 学习进度跟踪+个性化内容生成,利用Prompts精准控制教学内容难度,通过Memory记录学习轨迹 |
| 智能制造 | 设备故障诊断 | 日志分析+解决方案生成,通过Indexes检索设备维修手册,结合Chains完成故障定位到方案输出的全流程 |
二、核心组件解析
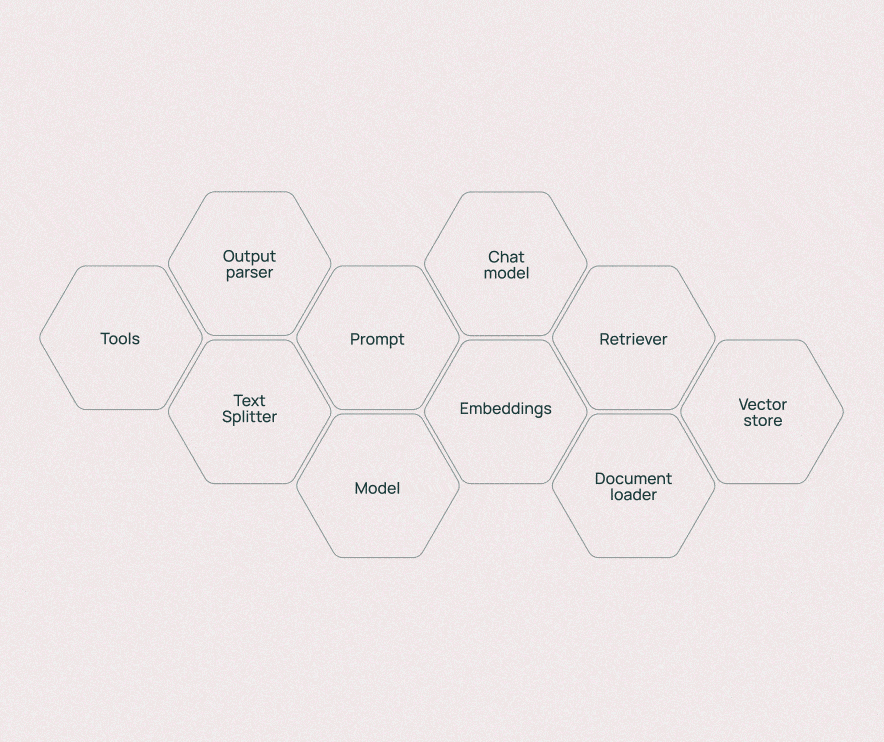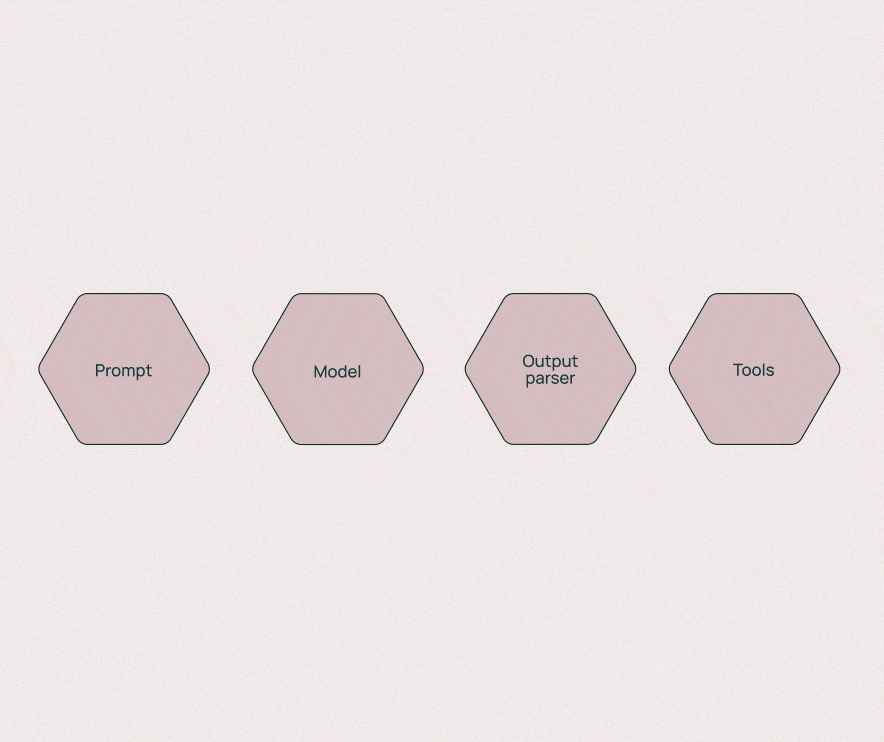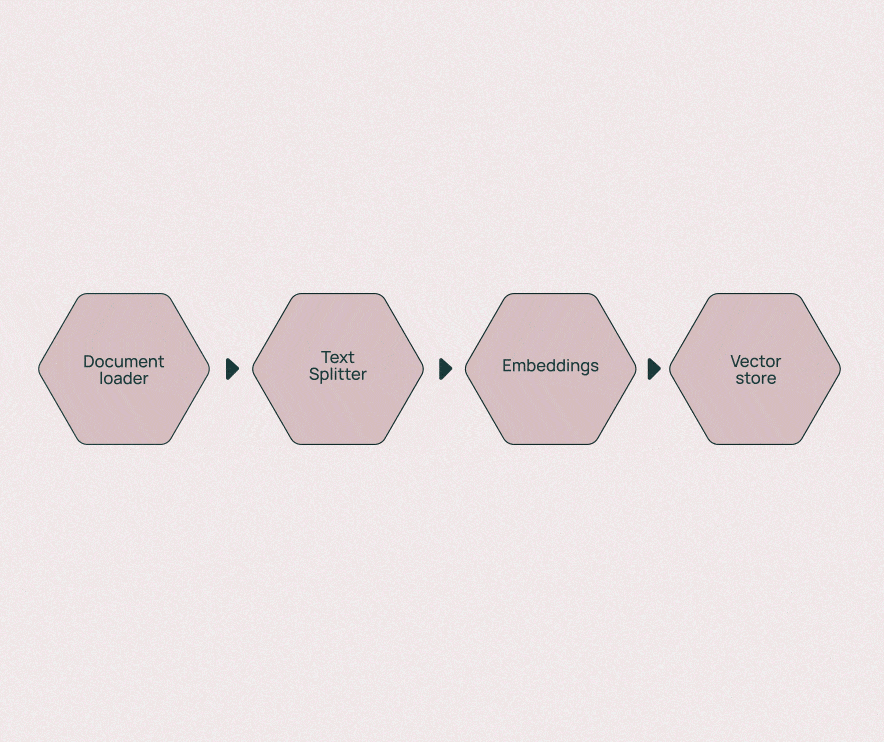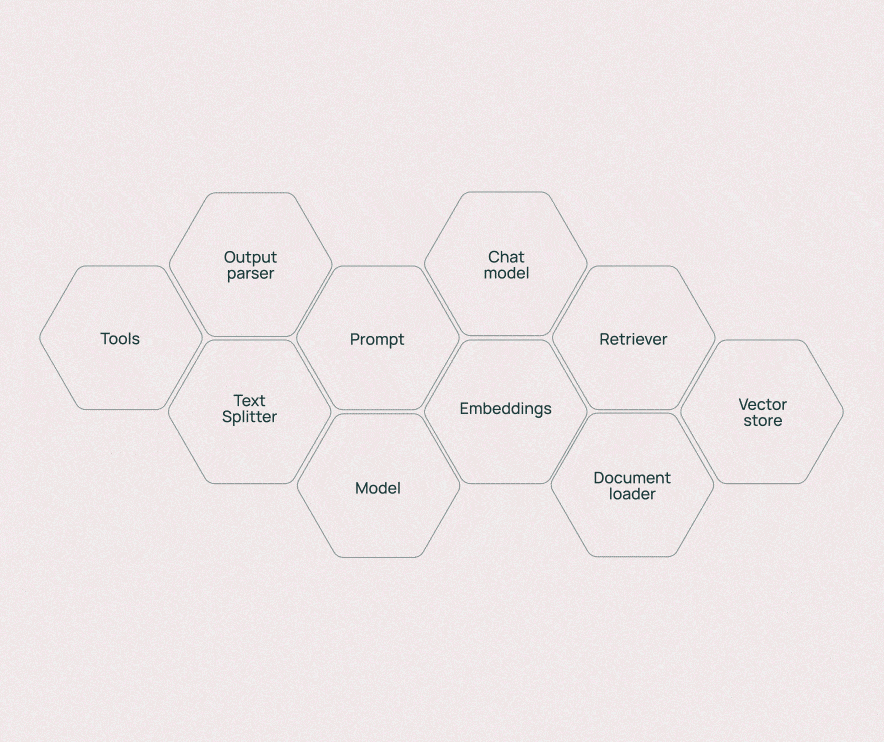
2.1 Models:统一模型接口层
核心作用:作为LLM应用的"大脑",提供统一接口连接各类AI模型(文本生成模型、嵌入模型、聊天模型等),屏蔽不同模型的调用差异,让开发者无需关注底层API细节即可切换模型。
运行原理:
- 通过抽象类定义模型调用的标准方法(如
predict()、generate()) - 针对不同模型(OpenAI、LLaMA、Claude等)实现适配层,统一输入输出格式
- 内置参数管理机制,支持温度(temperature)、最大 tokens 等核心参数的标准化配置
API参数详解:
from langchain_community.llms import Ollama
from langchain_community.chat_models import ChatOllama
from langchain_community.embeddings import OllamaEmbeddings
# LLMs参数配置(文本生成模型)
llm = Ollama(
model="qwen2.5:7b", # 模型标识,指定调用的具体模型
temperature=0.7, # 生成随机性(0-1),0表示确定性输出,1表示高度随机
max_tokens=500, # 最大输出长度,控制生成内容的篇幅
top_p=0.9, # 核采样概率,控制生成的多样性
frequency_penalty=0.5 # 重复惩罚系数,减少重复内容的生成
)
# Chat Models配置(对话模型)
chat_model = ChatOllama(
model="llama3:8b-instruct",
system_message="你是一位专业律师", # 系统角色设定,定义模型的行为模式
stop_sequences=["\n\n"] # 停止生成标记,遇到特定字符时停止生成
)
# Embeddings配置(嵌入模型,用于文本向量化)
embeddings = OllamaEmbeddings(
model="mxbai-embed-large",
batch_size=32, # 批量处理大小,优化大规模文本向量化效率
timeout=60 # 超时设置(秒),防止模型调用耗时过长
)
2.2 Prompts:精准控制模型输出
核心作用:作为开发者与模型之间的"翻译官",将自然语言需求转化为模型可理解的指令,通过结构化模板、少样本示例等方式提升模型输出的准确性和一致性。
运行原理:
- 基于模板引擎实现变量替换,支持动态插入用户输入或上下文信息
- 通过前缀(prefix)、后缀(suffix)和示例(examples)构建完整提示逻辑
- 针对聊天场景设计多角色消息结构(系统消息、人类消息、AI消息),模拟真实对话流程
API参数详解:
from langchain_core.prompts import (
PromptTemplate,
FewShotPromptTemplate,
ChatPromptTemplate
)
# 基础提示模板(适用于简单指令)
prompt_template = PromptTemplate(
input_variables=["product", "audience"], # 需要动态替换的变量
template="为{product}写一则针对{audience}的广告文案", # 提示模板内容
template_format="f-string", # 模板格式,支持f-string或jinja2
validate_template=True # 启用变量验证,防止模板与变量不匹配
)
# 少样本提示(通过示例引导模型输出格式)
few_shot_prompt = FewShotPromptTemplate(
examples=examples, # 示例列表,如[{'input': '手机', 'output': '...'}]
example_prompt=example_prompt, # 示例的模板结构
prefix="你是一位资深营销专家", # 提示前缀,定义模型角色
suffix="产品: {input}\n文案:", # 提示后缀,引导模型输出
input_variables=["input"], # 接收用户输入的变量
example_separator="\n\n" # 示例分隔符,控制示例间的格式
)
# 结构化聊天提示(模拟多轮对话场景)
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一位{topic}专家"), # 系统消息,定义整体行为
("human", "{question}"), # 人类消息,用户的问题
("ai", "{partial_response}"), # AI消息,模型的历史回复
("human", "继续完善:") # 人类消息,进一步引导
])
2.3 Chains:可复用任务流水线
核心作用:作为LLM应用的"流水线",将多个组件(Models、Prompts、Tools等)按逻辑顺序串联,实现复杂任务的自动化执行,避免重复开发相同流程。
运行原理:
- 基于输入输出键(input_key/output_key)实现组件间的数据传递
- 支持线性流程(SequentialChain)、分支流程(RouterChain)等复杂逻辑
- 内置日志和追踪机制,便于调试和优化任务流程
API参数详解:
from langchain.chains import LLMChain, SequentialChain
# 单步链(单一模型+提示的组合)
summary_chain = LLMChain(
llm=llm, # 绑定的语言模型
prompt=prompt_template, # 绑定的提示模板
output_key="summary", # 指定输出键,用于后续组件调用
verbose=True # 显示执行日志,便于调试
)
# 顺序链(多步任务按顺序执行)
analysis_chain = SequentialChain(
chains=[clean_chain, summary_chain, report_chain], # 按顺序执行的子链
input_variables=["raw_data"], # 初始输入变量
output_variables=["final_report"], # 最终输出变量
return_all_outputs=True # 返回所有中间结果,便于分析
)
# 路由链(根据条件选择不同处理流程)
route_chain = RouterChain(
router_prompt=router_prompt, # 用于判断路由的提示
destination_chains={ # 目标链映射表
"technical": tech_chain, # 技术问题处理链
"general": general_chain # 通用问题处理链
},
default_chain=default_chain # 默认处理链,当路由判断失败时使用
)
2.4 Agents:自主决策的智能体
核心作用:作为LLM应用的"决策者",具备规划能力和工具调用能力,能根据用户需求自主决定执行步骤(如是否调用工具、调用哪个工具、如何处理结果),适用于需要复杂推理的场景。
运行原理:
- 基于"思考-行动-观察"(Thought-Action-Observation)循环实现决策过程
- 通过提示模板引导模型生成工具调用指令(如
Action: {"name": "Search", "parameters": {"query": "..."}}) - 内置工具调用解析器,将模型输出转换为实际工具调用,并获取返回结果
- 支持最大迭代次数、早停机制等,防止无限循环
API参数详解:
from langchain.agents import initialize_agent, Tool
# 工具定义(Agents可调用的外部能力)
search_tool = Tool(
name="WebSearch", # 工具名称,用于模型识别
func=search.run, # 工具执行函数,实际处理逻辑
description="用于搜索实时网络信息", # 工具描述,帮助模型判断是否使用
return_direct=False # 是否直接返回工具结果,False表示需要进一步处理
)
# 智能体初始化
agent = initialize_agent(
tools=[calculator, db_query, search_tool], # 可用工具列表
llm=llm, # 用于决策的语言模型
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, # 智能体类型
verbose=True, # 显示决策过程日志
max_iterations=5, # 最大推理步骤,防止无限循环
early_stopping_method="generate", # 停止条件,"generate"表示生成最终答案
handle_parsing_errors=True # 错误处理,自动处理工具调用解析错误
)
2.5 Memory:上下文管理
核心作用:作为LLM应用的"记忆系统",负责存储和管理对话历史或任务上下文,让模型能够基于历史信息生成连贯的回复,支持多轮对话和长任务处理。
运行原理:
- 基于键值对存储机制管理上下文数据,支持不同粒度的记忆(单轮对话、会话摘要、长期记忆)
- 提供记忆加载和保存接口,可与外部存储(如Redis、数据库)集成
- 支持记忆修剪和摘要,避免上下文过长导致的性能问题
API参数详解:
from langchain.memory import (
ConversationBufferMemory,
ConversationSummaryMemory,
VectorStoreRetrieverMemory,
CombinedMemory
)
# 基础记忆(完整存储对话历史)
buffer_memory = ConversationBufferMemory(
memory_key="chat_history", # 记忆存储键,用于在提示中引用
return_messages=True, # 返回完整消息对象(包含角色信息)
input_key="input" # 输入键,指定哪些输入需要存入记忆
)
# 摘要记忆(对长对话进行摘要压缩)
summary_memory = ConversationSummaryMemory(
llm=llm, # 用于生成摘要的语言模型
memory_key="summary", # 记忆存储键
max_token_limit=1000 # 摘要最大长度,控制记忆占用的tokens
)
# 向量记忆(将对话内容向量化,支持语义检索)
vector_memory = VectorStoreRetrieverMemory(
retriever=vector_db.as_retriever(), # 向量存储检索器
memory_key="vector_mem" # 记忆存储键
)
# 组合记忆(整合多种记忆类型)
composite_memory = CombinedMemory(
memories=[buffer_memory, summary_memory, vector_memory] # 组合的记忆列表
)
2.6 Indexes:知识中枢
核心作用:作为LLM应用的"知识库",负责处理、存储和检索企业私有文档(PDF、Word、网页等),让模型能够基于专业知识生成更准确的回答,解决LLM"知识截止日期"和"私有数据"问题。
运行原理:
- 文档加载:支持多种格式文档的解析和加载
- 文本分割:将长文档拆分为适合模型处理的小块(Chunk),保留上下文关联
- 向量存储:将文本块转换为向量并存储,支持高效的语义检索(如余弦相似度匹配)
- 检索增强:将检索到的相关文档片段作为上下文输入模型,提升回答准确性
API参数详解:
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 文档加载(读取外部文档)
loader = PyPDFLoader(
file_path="report.pdf", # 文档路径
password="secret" # 加密PDF支持
)
documents = loader.load() # 加载文档内容
# 文本分割(处理长文档)
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 块大小,每个文本块的字符数
chunk_overlap=200, # 块重叠,相邻块的重叠字符数(保持上下文)
length_function=len, # 长度计算函数,默认按字符数
add_start_index=True # 保留原位置,记录每个块在原文档中的位置
)
chunks = splitter.split_documents(documents) # 分割文档
# 向量存储(构建可检索的知识库)
vector_db = FAISS.from_documents(
documents=chunks, # 分割后的文本块
embedding=embeddings, # 嵌入模型,用于文本向量化
index_name="financial_reports" # 索引命名,便于管理
)
# 混合检索(结合多种检索方式)
retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever], # 检索器列表
weights=[0.7, 0.3] # 权重分配,控制各检索器的影响
)
三、总结
LangChain作为当前具影响力的LLM应用开发框架,通过“连接”理念重新定义了大语言模型的工业化应用模式。其核心价值在于打破了模型、数据、工具之间的壁垒,让开发者能以组件化方式快速搭建从简单对话到复杂智能系统的各类应用。
从技术架构看,七大核心组件形成了完整的能力闭环:
- Models作为“大脑”,统一了各类AI模型的调用接口,让切换模型如更换零件般简单;
- Prompts作为“语言转换器”,通过结构化模板和少样本示例,将人类需求精准传递给模型;
- Chains作为“流水线”,串联起多步骤任务,实现从输入到输出的自动化处理;
- Agents作为“决策者”,赋予模型自主调用工具的能力,突破了纯文本生成的局限;
- Memory作为“记忆系统”,让模型具备上下文感知能力,支撑连贯的多轮交互;
- Indexes作为“知识库”,解决了LLM知识截止和私有数据利用问题,通过检索增强大幅提升输出准确性。
从应用价值看,LangChain已深度渗透到金融、医疗、零售等多行业:在金融领域,它能串联市场数据检索与合规报告生成;在医疗场景,可解析电子病历并生成标准化诊断建议;在零售行业,能结合用户行为数据生成个性化推荐。这种跨行业适配能力,源于其模块化设计带来的灵活性——开发者无需重复开发底层逻辑,只需根据场景组合组件即可。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)