Kubernetes部署NVIDIA GPU设备插件完全指南
通过本文介绍的步骤,您已成功在Kubernetes集群中部署了NVIDIA GPU设备插件。现在,您的集群可以运行GPU加速的容器化应用,如机器学习训练、AI推理等任务。如需进一步优化,可参考NVIDIA官方文档,配置高级功能如MIG(多实例GPU)或GPU共享。
https://github.com/NVIDIA/k8s-device-plugin?tab=readme-ov-file#prerequisites
根据这个链接安装 toolkit
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
按照官网操作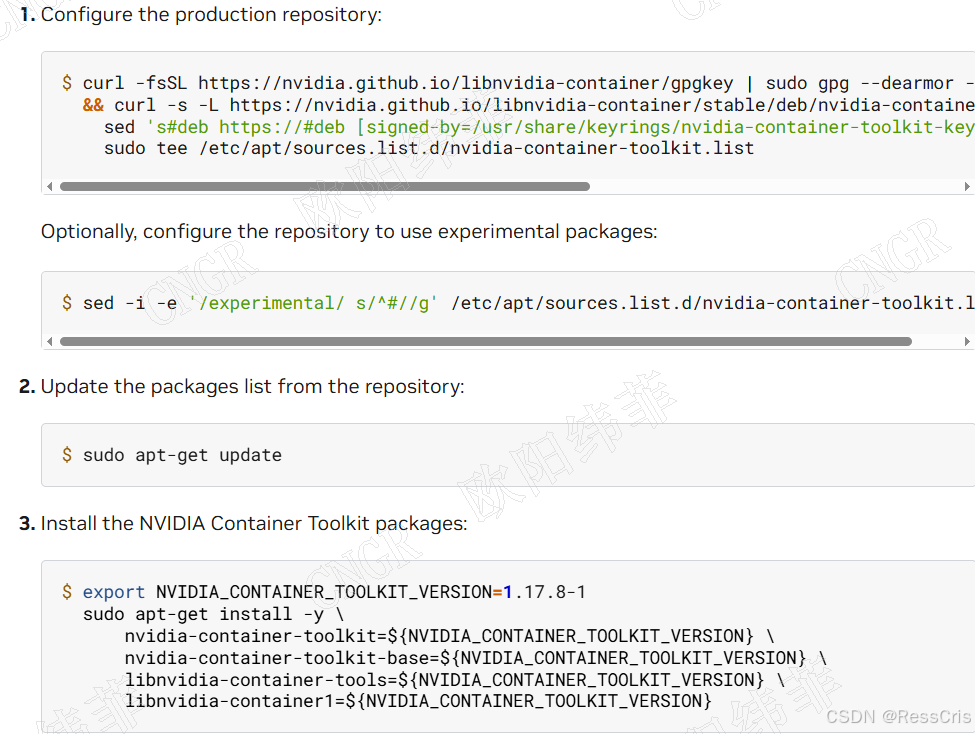
然后配置 containerd ,并重启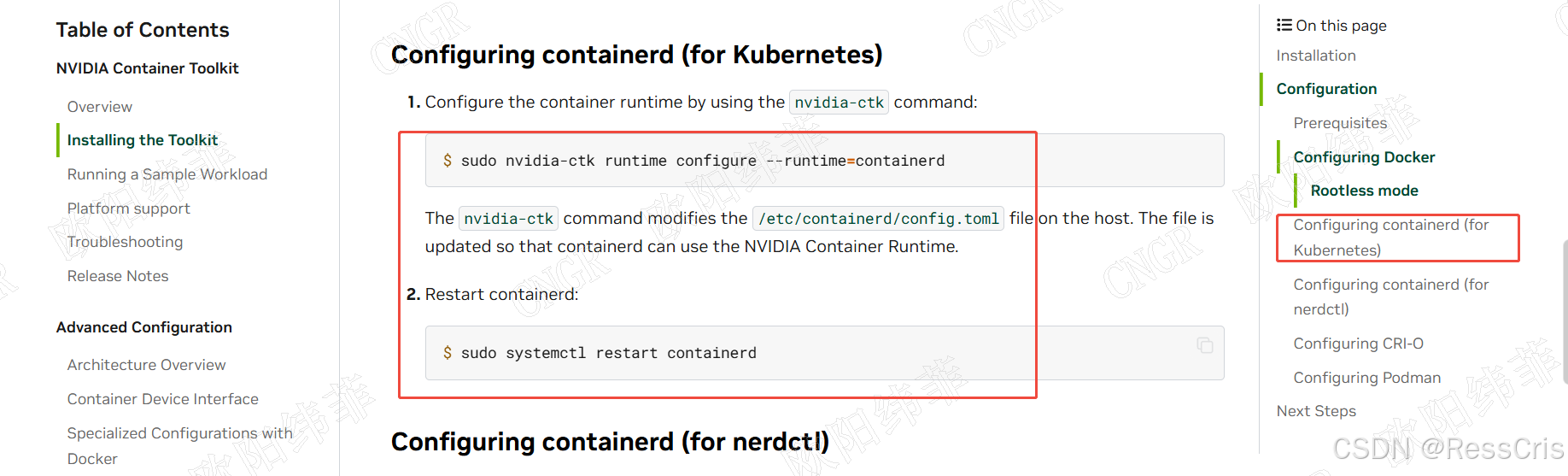
然后
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
也可以先拉好镜像 nvcr.io/nvidia/k8s-device-plugin:v0.17.1
sudo ctr -n=k8s.io images pull nvcr.io/nvidia/k8s-device-plugin:v0.17.1
如果报类似于这种错误
administrator@k8s-master:~$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
Error from server (AlreadyExists): error when creating "https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml": daemonsets.apps "nvidia-device-plugin-daemonset" already exists
administrator@k8s-master:~$
# # 删除现有的 DaemonSet
kubectl delete daemonset -n kube-system nvidia-device-plugin-daemonset
# 重新创建
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
# 查看创建情况
kubectl describe pod -n kube-system -l name=nvidia-device-plugin-ds
# 查看日志
kubectl logs -n kube-system nvidia-device-plugin-daemonset-xxx(从上一条命令可以获取到具体名称)
# 验证是否挂上去
# 检查节点资源
kubectl describe node k8s-master | grep -A 10 "Capacity"
引言
随着AI和机器学习 workload 在Kubernetes集群中的普及,GPU资源的高效管理变得至关重要。NVIDIA提供的k8s-device-plugin允许容器直接访问GPU硬件资源,实现计算任务的加速。本文将详细介绍从环境准备到插件部署、故障排查的完整流程,帮助管理员快速搭建GPU加速的Kubernetes集群。
一、官网链接
https://github.com/NVIDIA/k8s-device-plugin?tab=readme-ov-file#prerequisites
根据这个链接安装 toolkit
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
二、安装NVIDIA Container Toolkit
2.1 添加NVIDIA官方仓库
# 添加NVIDIA GPG密钥
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
# 添加仓库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list > /dev/null
2.2 安装Container Toolkit
# 更新软件包索引
sudo apt-get update
# 安装nvidia-container-toolkit
sudo apt-get install -y nvidia-container-toolkit
2.3 配置Containerd
# 配置nvidia-container-runtime
sudo nvidia-ctk runtime configure --runtime=containerd
# 重启containerd服务
sudo systemctl restart containerd
配置完成后,containerd将使用nvidia-container-runtime作为默认运行时,允许容器直接访问GPU设备。
三、部署NVIDIA k8s-device-plugin
3.1 拉取设备插件镜像(可选)
为避免网络问题导致部署失败,建议提前拉取镜像:
sudo ctr -n=k8s.io images pull nvcr.io/nvidia/k8s-device-plugin:v0.17.1
3.2 创建DaemonSet
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
四、常见问题与解决方案
4.1 DaemonSet已存在错误
错误信息:
Error from server (AlreadyExists): error when creating "https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml": daemonsets.apps "nvidia-device-plugin-daemonset" already exists
解决方案:
# 删除现有的DaemonSet
kubectl delete daemonset -n kube-system nvidia-device-plugin-daemonset
# 重新创建
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
4.2 验证部署状态
# 查看创建情况
kubectl describe pod -n kube-system -l name=nvidia-device-plugin-ds
# 查看日志(替换xxx为实际pod名称)
kubectl logs -n kube-system nvidia-device-plugin-daemonset-xxx
kubectl get pods -n kube-system -l name=nvidia-device-plugin-ds
验证GPU资源未正确挂载
验证命令:
# 检查节点资源
kubectl describe node k8s-master | grep -A 10 "Capacity"
预期输出:
Capacity:
cpu: 8
ephemeral-storage: 104857596Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32792572Ki
nvidia.com/gpu: 1 # 确保出现此行,表示GPU资源已识别
pods: 110
五、部署验证与测试
5.1 创建测试Pod
创建gpu-test.yaml文件:
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
containers:
- name: gpu-test
image: nvidia/cuda:11.6.2-base-ubuntu20.04
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1
执行测试:
kubectl apply -f gpu-test.yaml
# 查看测试结果
kubectl logs gpu-test
# 其他常用命令
kubectl describe nodes | grep -A 10 "Allocatable" | grep -E "cpu|memory|nvidia.com/gpu"
# 查看 daemon pod
kubectl get pods -n kube-system | grep nvidia
kubectl logs -n kube-system <nvidia-device-plugin-pod>
5.2 预期输出
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| 30% 32C P8 11W / 250W | 0MiB / 11264MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
六、最佳实践与注意事项
6.1 版本兼容性矩阵
| Kubernetes版本 | 设备插件版本 | Container Toolkit版本 |
|---|---|---|
| 1.24-1.26 | v0.14.x | 1.11.x |
| 1.27-1.29 | v0.15.x-v0.17.x | 1.12.x-1.14.x |
6.2 升级策略
- 先升级驱动,再升级插件
- 使用滚动更新避免集群中断:
kubectl set image daemonset/nvidia-device-plugin-daemonset \ -n kube-system nvidia-device-plugin=nvcr.io/nvidia/k8s-device-plugin:v0.17.1
6.3 监控与维护
-
定期检查设备插件状态:
kubectl get pods -n kube-system -l name=nvidia-device-plugin-ds -
设置资源限制:为设备插件Pod设置资源限制,避免影响其他系统组件。
-
建立日志收集:配置EFK或Prometheus+Grafana监控GPU使用情况。
七、总结
通过本文介绍的步骤,您已成功在Kubernetes集群中部署了NVIDIA GPU设备插件。现在,您的集群可以运行GPU加速的容器化应用,如机器学习训练、AI推理等任务。如需进一步优化,可参考NVIDIA官方文档,配置高级功能如MIG(多实例GPU)或GPU共享。
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)