五年之约?OpenAI“开源”背后,是良心发现还是精心布局?深度解析
OpenAI时隔五年首度开放模型权重,发布1170亿参数的gpt-oss-small-120b和210亿参数的gpt-oss-base-20b两款模型。采用"开放权重"而非完全开源,既保留核心技术又回应社区需求。此举被视为应对Meta等开源竞争的战略调整,开发者可免费部署本地AI应用。新模型支持链式推理,在性能上接近闭源产品,但存在"幻觉"风险。行业分析认为
8月5日,AI圈迎来了一次不大不小的“地震”。
主角依然是OpenAI,但这次带来的不是万众期待的GPT-5,而是两款“开放权重”模型——gpt-oss-small-120b 和 gpt-oss-base-20b。
消息一出,圈内瞬间沸腾。要知道,这可是自2019年备受争议的GPT-2之后,那个以“闭源”闻名的OpenAI,五年来第一次向世界敞开其模型的核心参数。

这不仅是一次简单的产品发布,更像是一次重大的战略转向。它背后,是来自竞争对手的压力,是社区的呼声,更是一场精心布局的阳谋。
这次的“GPT”不叫GPT
我们先来看看这次的两个主角,它们到底是什么来头。

大块头选手:gpt-oss-small-120b
这是一个拥有1170亿参数的庞然大物,但别被吓到。它采用了一种名为“混合专家(MoE)”的聪明架构,好比一个拥有120位专家的智囊团,但每次回答问题,只需要唤醒其中最相关的几位(约51亿参数)。这极大地提升了效率,让它在单块80GB的Nvidia GPU上就能跑起来。
实力如何? 在编程、数学竞赛等多个基准测试中,它的表现已经逼近甚至在某些方面超越了OpenAI自家的闭源模型o4-mini。
轻量级选手:gpt-oss-base-20b
这个模型参数为210亿,主打一个轻巧灵活。它甚至可以在一台配备16GB内存的普通笔记本电脑上流畅运行。
有什么用? 这意味着开发者可以轻松地把它部署在个人设备上,实现一个无需联网、保护隐私的本地AI助手,帮你搜文件、写代码、做总结。
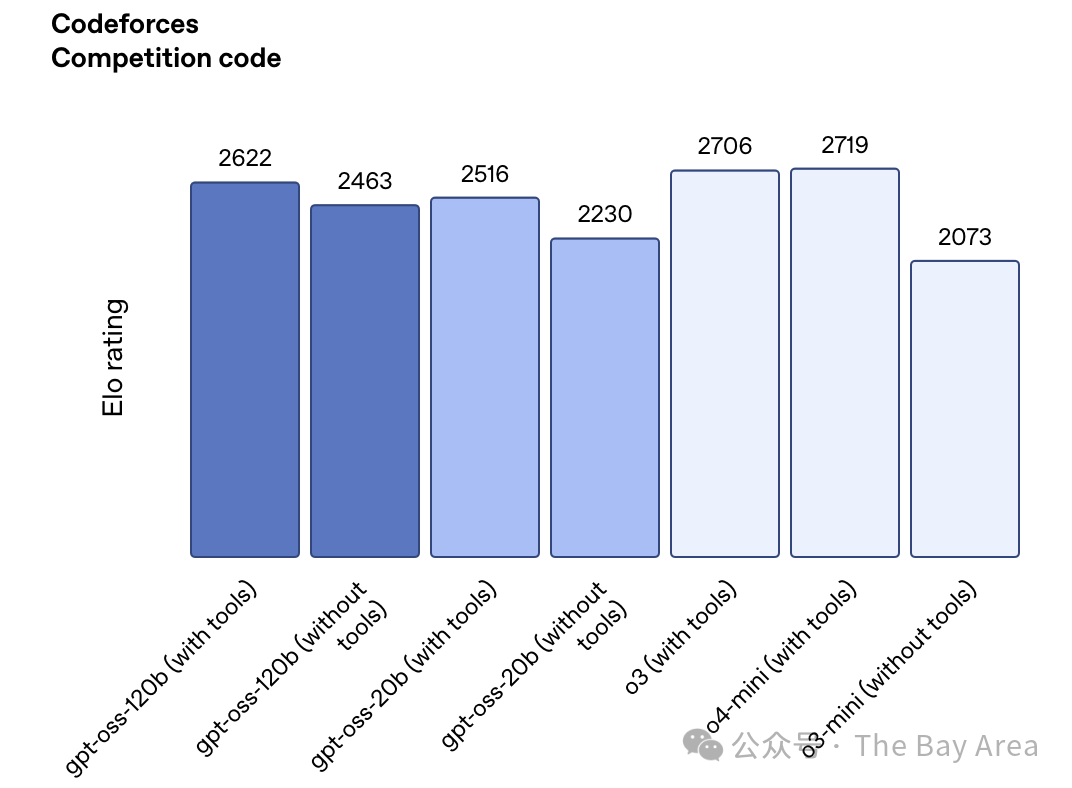
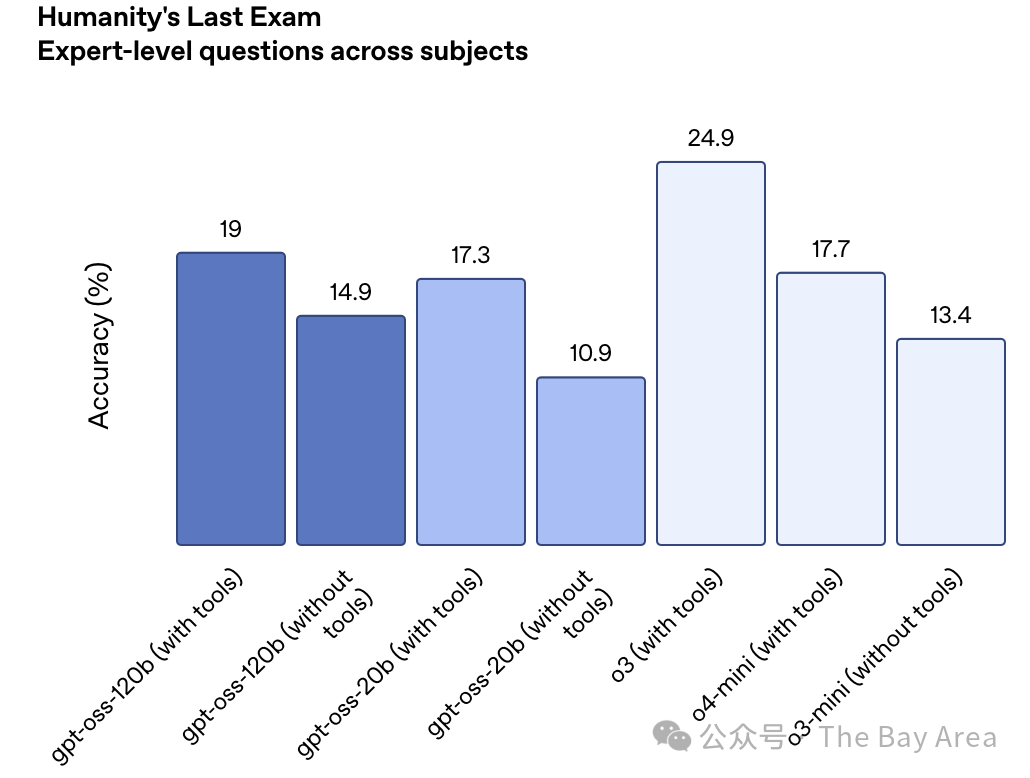
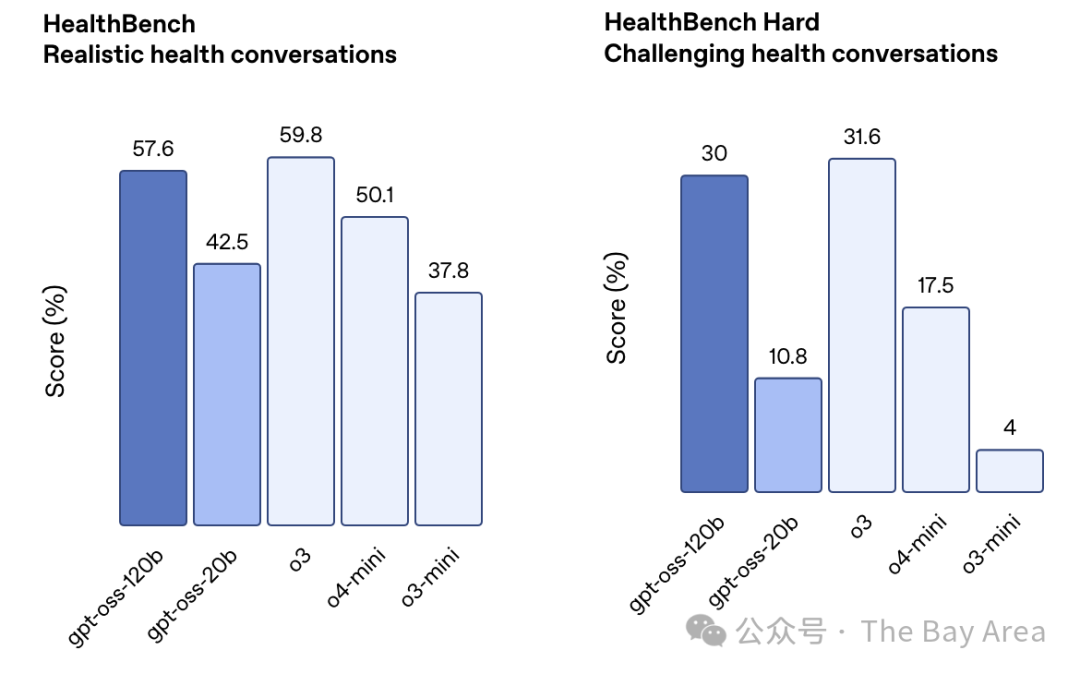
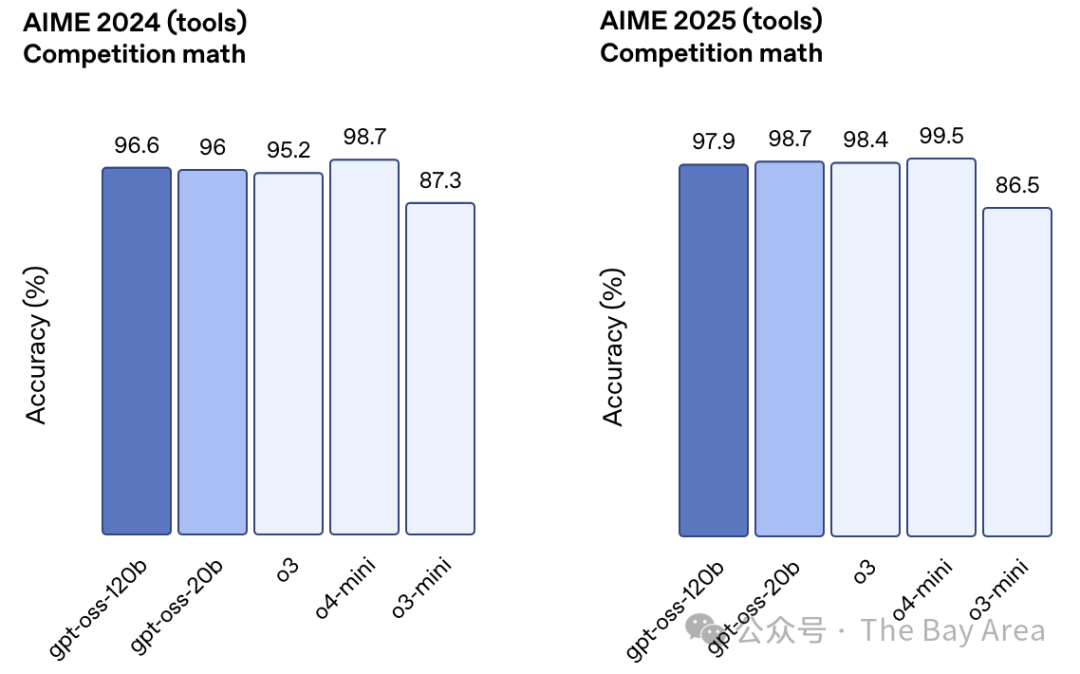
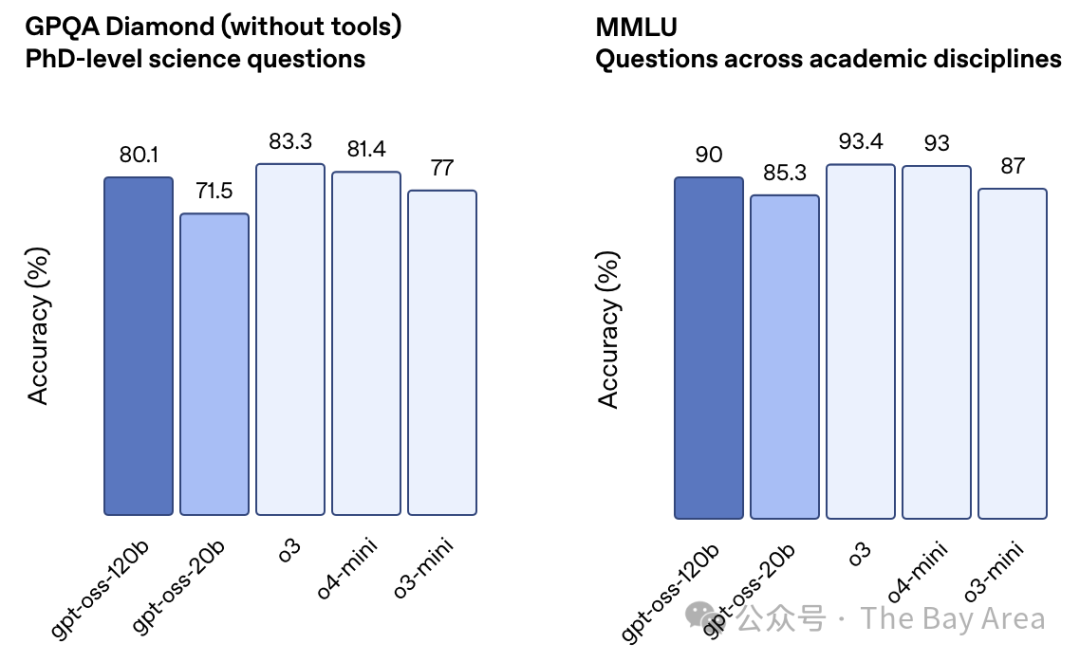
更关键的是,这两个模型都强化了“链式推理(CoT)”能力,能像人一样一步步思考和拆解复杂问题,而不是直接给出一个“黑箱”答案。这无疑增加了AI工作的透明度和可靠性。
读懂关键词:“开放权重”≠“开源”
OpenAI这次用了一个非常精准的词——“开放权重”(Open-Weight),而不是我们更熟悉的“开源”(Open-Source)。
一词之差,天壤之别:
-
开放权重:好比米其林餐厅公布了他们招牌菜的完整配料表(权重参数)。你可以用这些配料自己去烹饪、去改良,但餐厅不会告诉你他们独家的烹饪技巧、火候掌握(训练方法)以及食材的秘密来源(训练数据)。
-
完全开源:则相当于把配料、菜谱、厨师的训练手册、食材供应链全部公之于众。
OpenAI这步棋走得相当精妙。它既回应了社区对开放的呼唤,让大家能用上并改造它的模型,又牢牢守住了自己最核心的商业机密。这是一种在理想主义和商业现实之间,精心找出的平衡点。
OpenAI为何此时“掉头”?
OpenAI CEO萨姆·奥特曼曾坦言,公司在开源策略上“站在了历史错误的一边”。这次的发布,正是对“错误”的一次高调修正。但为什么是现在?
答案很简单:再不跟进,就要掉队了。
近年来,开源AI的世界风起云涌。Meta的Llama系列、Google的Gemma,尤其是来自中国初创公司DeepSeek的R1模型,以极低的成本实现了惊人的性能,给整个行业带来了巨大冲击。它们共同构建了一个繁荣的开源生态,让开发者有了“除了OpenAI之外”的更多、更便宜的选择。
这无疑动摇了OpenAI的“霸主”地位。
与此同时,最大的竞争对手之一Meta却传出可能因安全问题收缩开源投入。此消彼长之间,一个巨大的市场窗口期出现了。OpenAI选择此时入场,意图非常明显:
-
抢占开发者入口:用免费、强大的模型吸引海量开发者进入自家生态,培养用户习惯,为未来更强大的闭源模型和服务铺路。
-
秀出技术肌肉:证明自己不仅能造出最强的“航母”(GPT-4),也能造出最高效的“快艇”,巩固技术领导者的形象。
-
扛起“民主AI”大旗:在中美AI竞赛的背景下,此举也被视为美国科技界希望引领“基于民主价值观”的开放AI技术创新的重要一步。
一石激起千层浪:对我们意味着什么?
gpt-oss系列的发布,对整个AI生态,尤其是开发者和初创公司来说,无疑是重大利好。
-
门槛大大降低:初创公司和个人开发者不再需要为昂贵的API费用发愁,可以在本地自由地进行实验和应用开发。
-
创新遍地开花:可以预见,一大波基于gpt-oss的定制化应用即将出现,无论是服务特定行业的专业AI,还是更好玩的个人AI工具。
-
推动学术研究:研究人员可以直接“解剖”这些高性能模型,深入理解其工作原理,从而推动整个AI科学的进步。
当然,gpt-oss并非完美。OpenAI也坦诚,模型在推理时仍可能出现严重的“幻觉”(一本正经地胡说八道),需要开发者谨慎使用。此外,如何防止开放的模型被用于恶意目的,也是一个持续的挑战。
但无论如何,OpenAI重返开放赛道,标志着AI行业的一个转折点。它宣告了“越大越好”的单一模型竞赛模式已成过去,一个由超大闭源模型和海量开放模型共同组成的、更加多元和健康的AI新生态正在加速到来。
对于我们每一个人来说,更多的竞争,更多的选择,最终将带来更普惠、更强大的AI。而这场精彩的大戏,才刚刚拉开序幕。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献315条内容
已为社区贡献315条内容

所有评论(0)