干货|从零实现KV缓存,让LLM推理速度提升5倍不是梦!
本文介绍了KV(Key-Value)缓存在大语言模型(LLM)推理中的关键作用。KV缓存通过存储中间生成的Key/Value向量,避免重复计算,将复杂度从O(n²)降至O(n)。文章从概念、实现到性能对比详细解析KV缓存:1)解释了无缓存时的冗余计算问题;2)展示了缓存机制的工作流程;3)提供了从零实现的代码示例;4)实测显示缓存可带来约5倍的推理加速。虽然KV缓存会增加内存占用和实现复杂度,但其
KV(Key-Value)缓存是实现大语言模型(LLM)在生产环境中高效推理的关键技术之一。本文将从概念和代码两个层面出发,通过从零构建、可读性强的实现,详细解释它是如何工作的。
1. 什么是 KV 缓存?
在 LLM 推理(inference)阶段,模型生成每一个 token 时都需要重新计算此前所有输入的 attention 结构,包括 Query、Key、Value 向量。
这是一种冗余操作 —— 因为这些 Key 和 Value 在每轮生成中并未发生改变。
示例说明:
以 prompt 输入 “Time” 为例,模型逐词生成 “Time flies fast”。
•每生成一个新 token,如 "fast",模型需要重新计算前面 "Time" 和 "flies" 的 key/value 向量。•如下图所示:
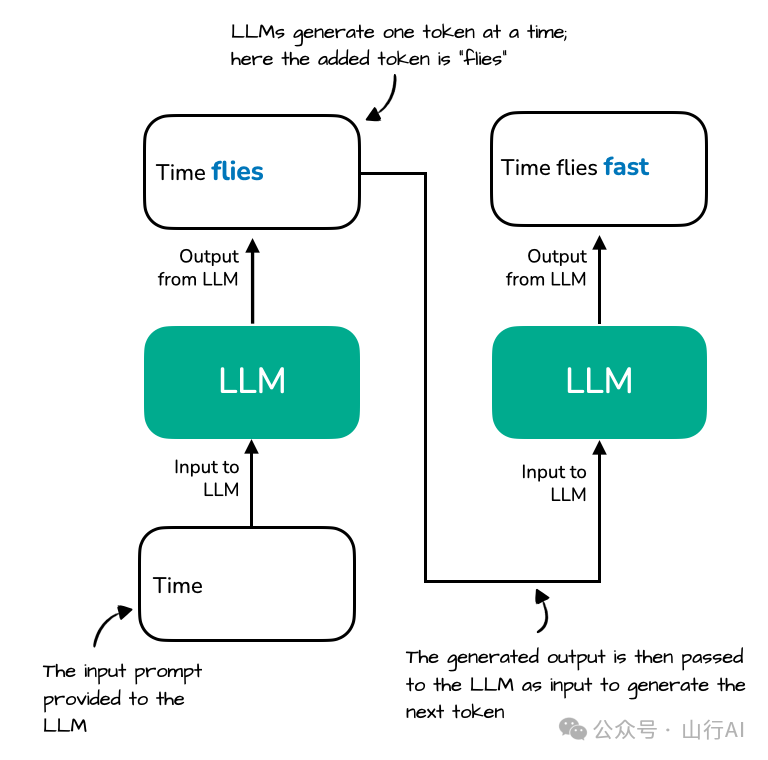
请注意,LLM 文本在生成输出过程中存在一些冗余,如下图所示:
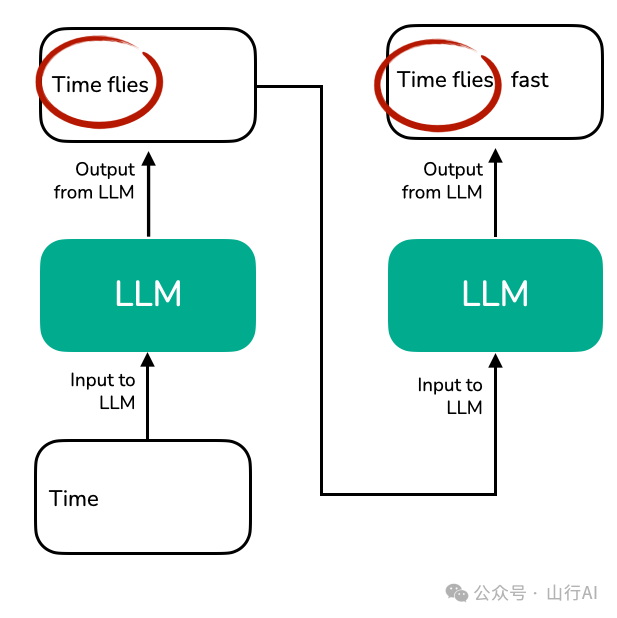
在每一步生成过程中,LLM 都需要重新处理完整的上下文 “Time flies”,才能生成下一个 token(如 “fast”)。由于 未对中间的 key/value 向量进行缓存,模型不得不反复对整个序列进行编码,造成了不必要的计算冗余。
2. KV 缓存的核心思想
为避免重复计算,KV 缓存机制的目标是:
缓存每一步生成的 Key 和 Value 向量,并在后续步骤中复用。
工作流程:
|
步骤 |
有无缓存 |
说明 |
|
第一步 |
计算并缓存当前 token 的 Key/Value |
初始化缓存 |
|
后续步骤 |
复用缓存,仅计算新 token 的 Key/Value |
节省计算资源 |
3. KV 缓存的对比图示
无 KV 缓存:
每次生成新 token,都重新编码之前所有输入。
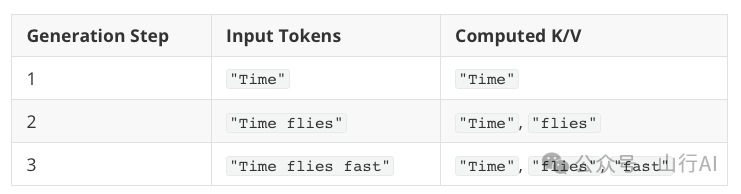
(不断重复 Key/Value 计算)
有 KV 缓存:
只计算当前 token 的 Key/Value,前面的向量从缓存中直接读取。
总结:计算和缓存步骤一览表

4. 从零实现 KV 缓存
参考文件:
•gpt_ch04.py[9]:原始实现,无缓存。•gpt_with_kv_cache.py[10]:新增 KV 缓存逻辑。
核心改动如下:
4.1 注册缓存变量
self.register_buffer("cache_k",None, persistent=False)self.register_buffer("cache_v",None, persistent=False)
4.2 前向传播添加 use_cache 参数
def forward(self, x, use_cache=False):# 新 Key/Valuekeys_new =self.W_key(x)values_new =self.W_value(x)if use_cache:# 初始化或拼接缓存...else:keys, values = keys_new, values_new
4.3 清空缓存
def reset_cache(self):self.cache_k,self.cache_v =None,None
4.4 顶层模型中添加位置跟踪 current_pos
if use_cache:pos_ids = torch.arange(self.current_pos,...)self.current_pos += seq_len
4.5 文本生成逻辑
def generate_text_simple_cached(model, idx, max_new_tokens, use_cache=True):...logits = model(next_idx, use_cache=True)
5. KV 缓存的性能对比
实验结果:(Mac mini + 1.2亿参数小模型)
|
模式 |
总时间 |
提速倍数 |
|
无缓存 |
13.7 秒 |
- |
|
有缓存 |
2.8 秒 |
约 5 倍提升 |
(插图:KV 缓存 vs 非缓存耗时对比图)
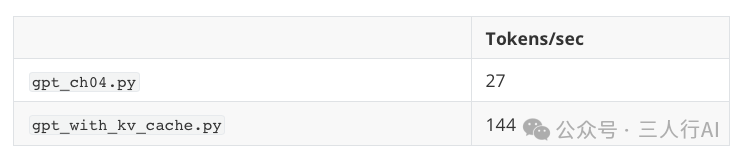
模型输出一致,说明实现正确。
6. KV 缓存的优缺点
优点
•显著加速:复杂度从 O(n²) 降至 O(n)•推理阶段表现优越
缺点
•占用更多显存(随序列长度增长)•实现更复杂,需要管理状态
7. KV 缓存的优化技巧
Tip 1:预分配内存
cache_k = torch.zeros((B, H, L, D), device=device)Tip 2:滑动窗口缓存
cache_k = cache_k[:,:,-window_size:,:]避免 GPU 内存暴涨,适用于长上下文生成任务。
8. 结语:权衡与实用性
虽然 KV 缓存增加了实现复杂度和内存占用,但它带来的推理效率提升是实实在在的,尤其在实际部署 LLM 时。
9.AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献286条内容
已为社区贡献286条内容

所有评论(0)