【第四章:大模型(LLM)】04.Transfomer: The foundation of LLM-(3)分词:英文分词与中文分词
本节介绍了 分词(Tokenization) 在自然语言处理中的重要性,并重点分析了 英文分词 与 中文分词 的差异。英文单词天然由空格分隔,但仍存在词形变化、缩写等问题,需要进一步处理。而中文没有显式分隔符,需依赖统计、词典或深度学习模型进行切分。
第四章:大模型(LLM)
第四部分:Transformer: The foundation of LLM
第三节:分词:英文分词与中文分词
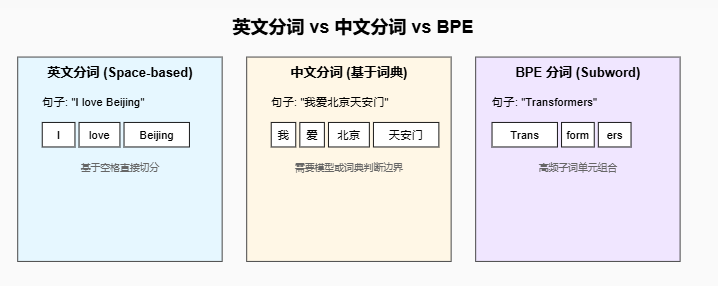
1. 分词的重要性
分词(Tokenization)是自然语言处理(NLP)中的第一步,它将文本划分为模型能够处理的最小单元(Token)。
Transformer 等大模型并不是直接处理原始文本,而是通过 分词器(Tokenizer) 将文本映射到 词向量(Embedding) 空间。
-
英文分词:英文天然有空格分隔词语,传统上分词较为简单,但在模型中往往使用 子词(Subword) 技术(如 BPE、WordPiece)。
-
中文分词:中文没有天然的分隔符,分词需要借助规则或模型来判断词边界。近年来也普遍采用 字符级/子词级分词 以减少歧义。
2. 英文分词
(1) 传统方法
-
空格分隔:简单高效,但无法处理 复合词(New York)、缩写(don’t) 等问题。
-
词典匹配:基于词典进行匹配分词,但无法处理新词。
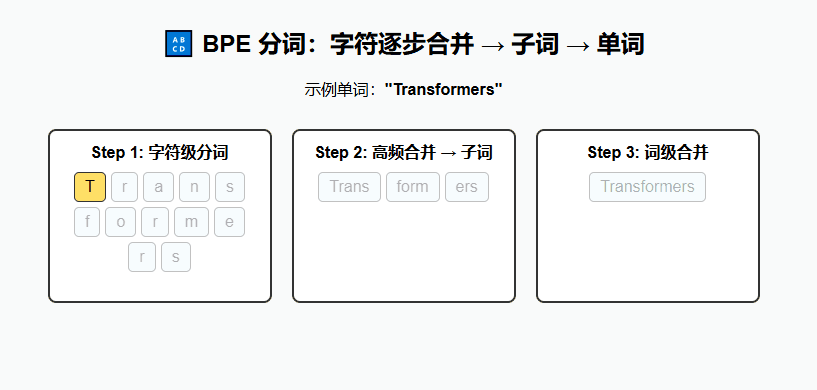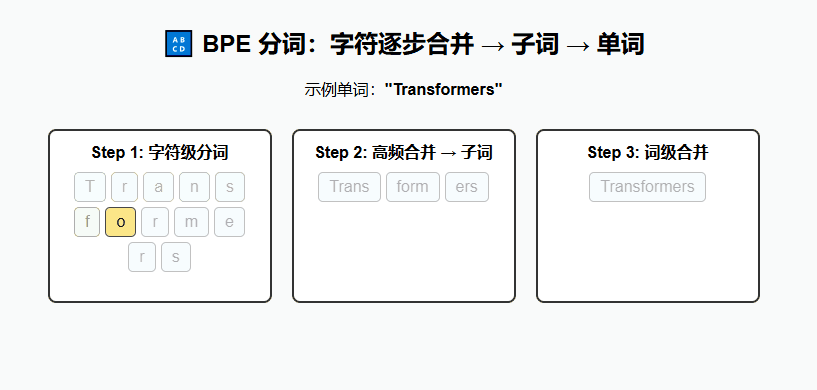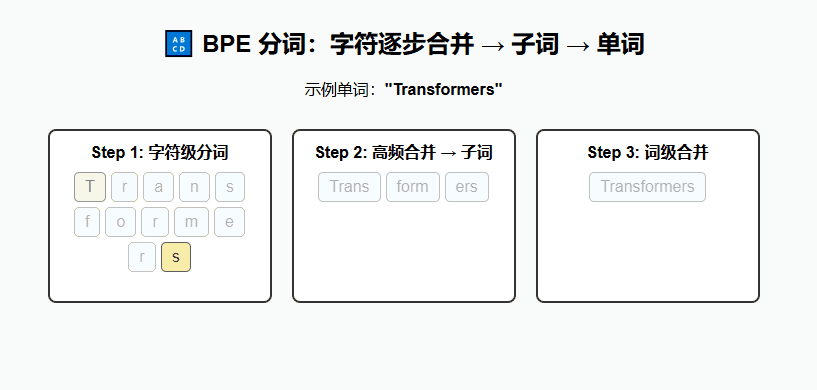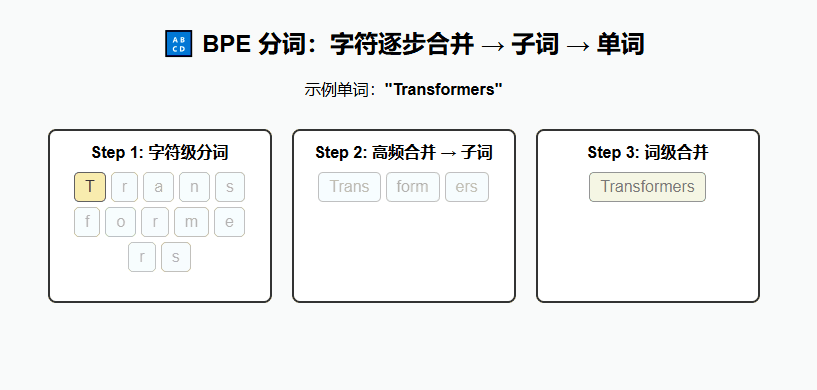
(2) 现代方法(用于 Transformer)
-
BPE(Byte Pair Encoding)
-
通过合并高频字符对生成子词单元,能在词表大小和表示能力之间取得平衡。
-
例:
lower,lowest,low→low+est
-
-
WordPiece
-
Google BERT 使用的分词方式,类似 BPE,但合并策略基于最大化语言模型概率。
-
-
SentencePiece(Unigram Model)
-
直接对字节序列建模,无需分隔符,适用于多语言模型(如 T5、mBERT)。
-
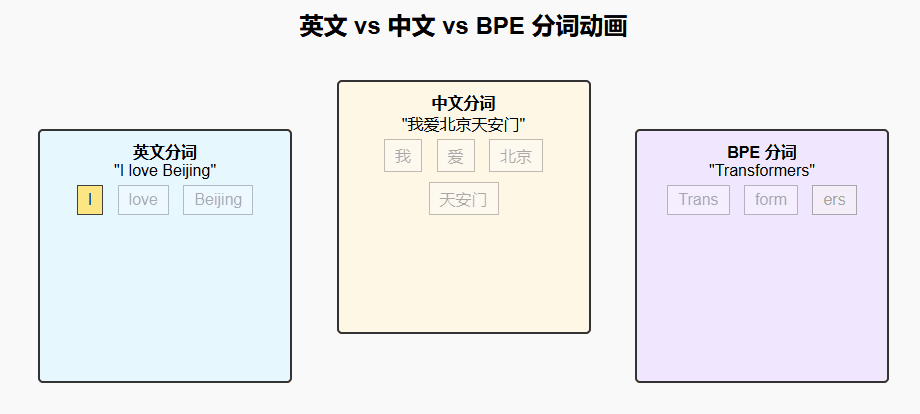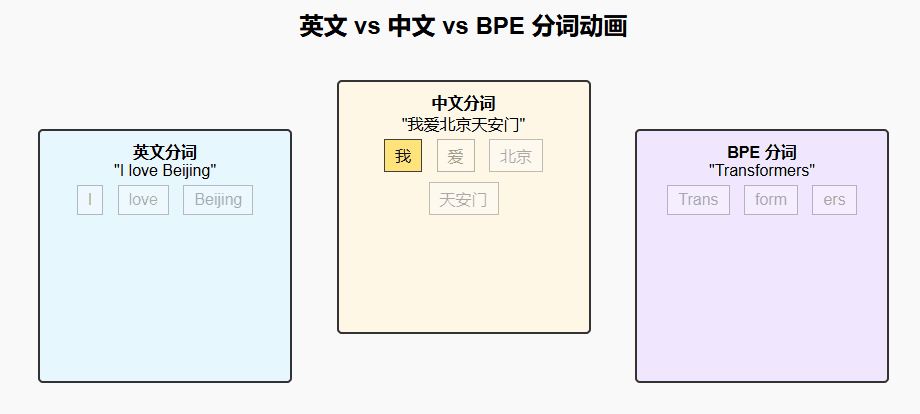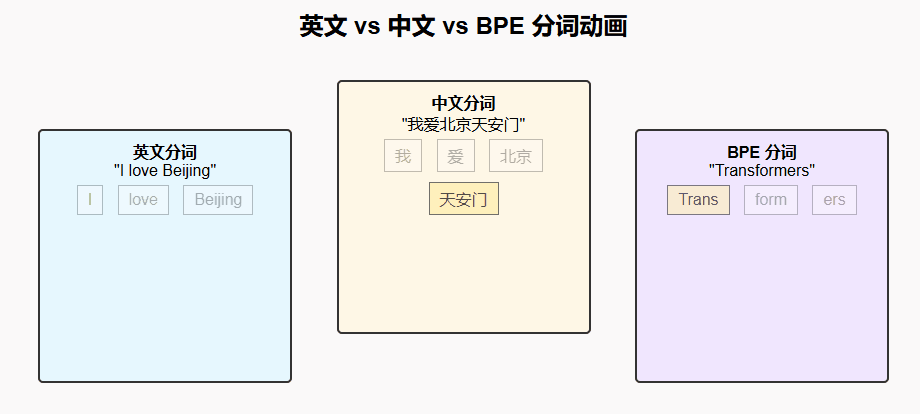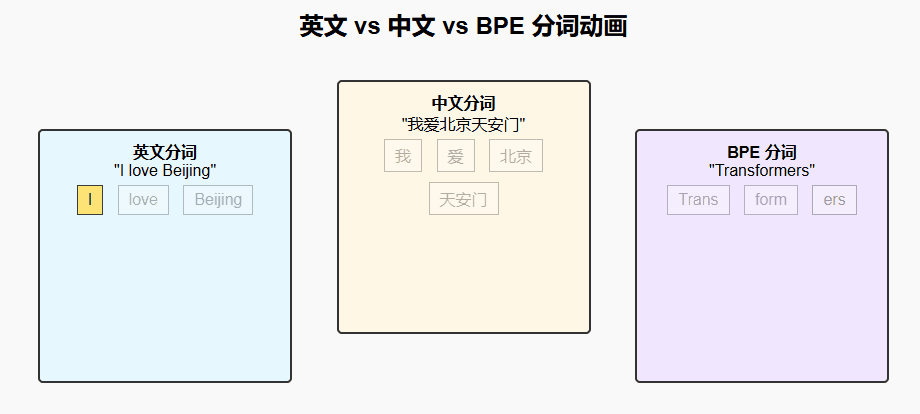
3. 中文分词
(1) 传统方法
-
基于规则:例如 正向最大匹配(MM) 和 逆向最大匹配(RMM)。
-
基于统计:如 隐马尔可夫模型(HMM)、条件随机场(CRF) 进行序列标注。
-
例子:
-
句子:"我爱北京天安门"
-
可能的分词:["我", "爱", "北京", "天安门"]
-
(2) 现代方法
-
字符级建模:直接以单字为 token,避免分词歧义。
-
BPE / SentencePiece:在中文中同样适用,将汉字和子词组合以提升表示能力。
-
示例:
-
"中华人民共和国" →
中华人民共和国 -
或子词化:
中华人民共和国
-
4. 英文 vs 中文分词对比
| 对比项 | 英文分词 | 中文分词 |
|---|---|---|
| 自然边界 | 空格分隔 | 无天然边界 |
| 传统方法 | 基于空格和词典 | 基于规则/统计/词典 |
| 现代方法 | BPE、WordPiece、SentencePiece | BPE、SentencePiece、字符级建模 |
| 挑战 | 复合词、缩写 | 歧义、多词组合、新词检测 |
5. 分词在大模型中的应用
-
Transformer 模型依赖 固定大小的词表(Vocabulary) 和 Embedding Lookup。
-
采用 子词(Subword)技术 能在:
-
处理 未登录词(OOV) 方面表现优异;
-
融合词粒度与字符粒度的优势;
-
支持多语言(如 mBERT, XLM-R)。
-
6. 代码示例
英文分词(使用 HuggingFace Tokenizer)
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text = "Transformers are revolutionizing NLP."
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens:", tokens)
print("Token IDs:", ids)
运行结果
Tokens: ['transformers', 'are', 'revolution', '##izing', 'nl', '##p', '.']
Token IDs: [19081, 2024, 4329, 6026, 17953, 2361, 1012]中文分词(使用 SentencePiece / BERT)
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
text = "我爱北京天安门"
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens:", tokens)
print("Token IDs:", ids)
运行结果
Tokens: ['我', '爱', '北', '京', '天', '安', '门']
Token IDs: [2769, 4263, 1266, 776, 1921, 2128, 7305]本节总结
分词是 NLP 的起点。
-
英文:从空格分割到子词技术,解决 OOV 问题。
-
中文:传统分词面临歧义,现代模型多采用字符级或子词级编码。
-
Transformer 及 LLM 依赖 统一的子词编码(BPE / SentencePiece),以支持多语言和大规模语料训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献95条内容
已为社区贡献95条内容

所有评论(0)