【万字长文】揭秘Transformer!它凭什么统治了整个AI领域?
Transformer架构凭借其创新的自注意力机制,在NLP、CV等领域展现出卓越性能。文章系统解析了Transformer的工作原理:1)通过QKV机制实现序列全局建模;2)多头注意力提升特征表达能力;3)编码器-解码器结构支持seq2seq任务;4)位置编码保留序列顺序信息。相比RNN/LSTM,Transformer具有并行计算、长程依赖建模等优势。文章还对比了GPT(Decoder-onl
在深度学习领域,每种模型架构都有其适合解决的问题,CNN 擅长捕捉图像局部特征,RNN 专注于处理序列依赖。然而 Transformer 架构却在自然语言处理(NLP)、计算机视觉(CV)、图像生成等多个前沿领域都占据核心地位,从机器翻译、文本生成,从图像分类到多模态交互,就连 GPT 等引领行业变革的大模型也将 Transformer 架构作为根基。

一、Transformer 是怎么做到如此全能的?
seq2seq 任务
Transformer 的诞生要从 NLP 的核心—— seq2seq 任务说起,seq2seq 任务是指将一个输入序列数据转换为另一个输出序列数据,不需要两个序列具有相同的长度或结构。
序列数据是指有顺序的数据集合,比如一句话中的文字、一段语音信号等。
典型的 Seq2Seq 问题包括:
-
机器翻译:输入中文句子 "非常感谢",输出英文句子 "Thank you very much"
-
文本摘要:输入一篇长文章,输出简短摘要
-
问答系统:输入一个问题,输出一个答案
-
聊天机器人:输入用户消息,输出回复消息
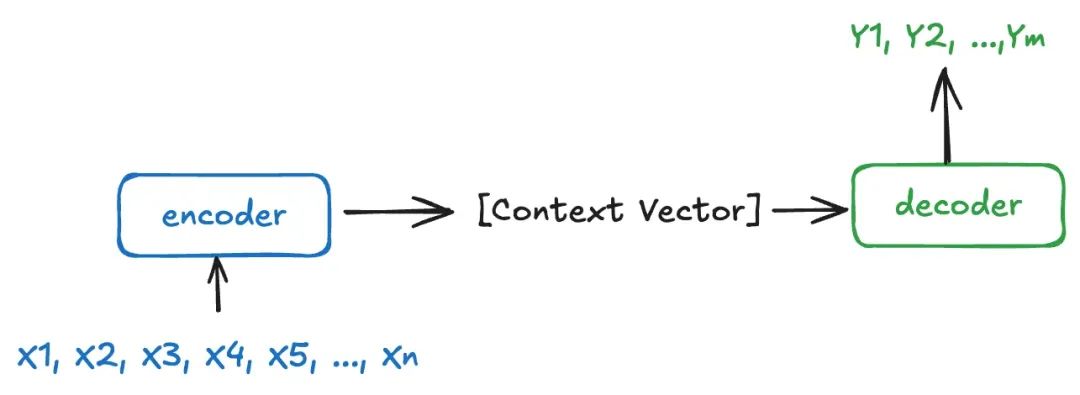
Seq2Seq 模型由两个主要组件组成:编码器(Encoder)和解码器(Decoder),其核心思想是“编码全局信息→解码逐步生成”
-
编码器:负责处理输入序列,将其压缩成一个固定维度的上下文向量(context vector),该向量包含了输入序列的语义信息。
-
解码器:接收编码器产生的上下文向量,并基于此逐步生成目标序列。解码器通常是自回归(Autoregressive)的,即每一步的输出依赖于前面所有步骤的输出。
二、什么是自回归
自回归是指模型在生成系列时候,每一步都依赖于之前已经生成的内容。比如我们要生成一个序列:
![]()
自回归模型的目标是根据前面的词预测下一个词的概率分布:
![]()
因此自回归模型都是逐词生成、输出。
RNN 和 LSTM 的困境
在 Transformer 出现之前,Seq2Seq 编码器和解码器的实现主流方法是循环神经网络(RNN)和长短期记忆网络(LSTM)。
有记忆的序列处理 RNN
循环神经网络(Recurrent Neural Network,RNN)是一种专门设计用于处理序列数据的神经网络结构。与传统的前馈神经网络不同,RNN 引入记忆的概念,能够"记住"之前的信息,并利用这些信息影响下一步的输出。
为什么记忆对于 seq2seq 这么重要呢?举个翻译的例子:
The man, who was wearing a red hat and carrying a black umbrella, walked into the store.那个戴着红帽子、拿着黑伞的男人走进了商店。
输入句子很长 ,包含多个修饰成分,如果模型没有记忆能力,在生成翻译结果时候可能就会忘掉戴帽子或者拿雨伞等细节,导致输出翻译不完整或错误:
一个男人走进了商店。RNN 工作流程
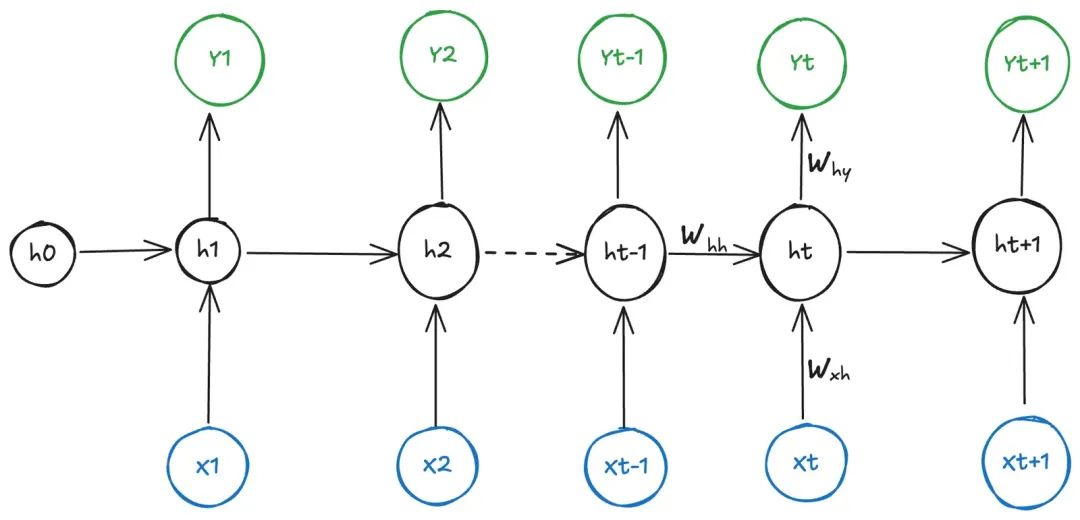
RNN 在普通神经网络的基础上,引入了循环隐藏层(下图中间的圆),其核心特点是通过对序列数据进行逐步处理 。具体来说:
1.逐 token 处理:输入序列按时间步依次处理(如文本中的每个词),每个时间步的输入会与前一时刻的隐藏状态共同计算当前隐藏状态;
2.隐藏状态的记忆功能:隐藏层存储历史信息,每步的隐藏层不仅包含当前输入的特征,还整合了前一步的隐藏状态,形成对序列上下文的动态记忆;
3.输出生成:当前步的输出基于当前隐藏状态计算得出,因此输出结果既依赖于当前输入,也依赖于之前所有输入的历史信息;
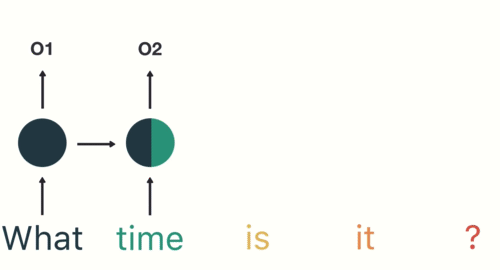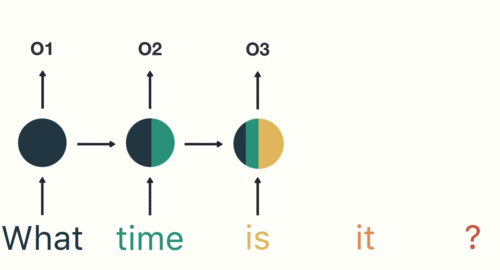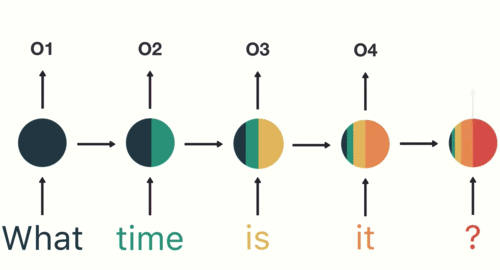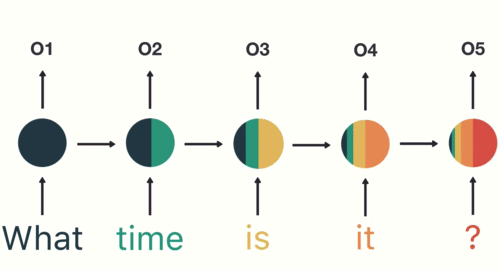
另外两个图来理解 RNN
|
|
|
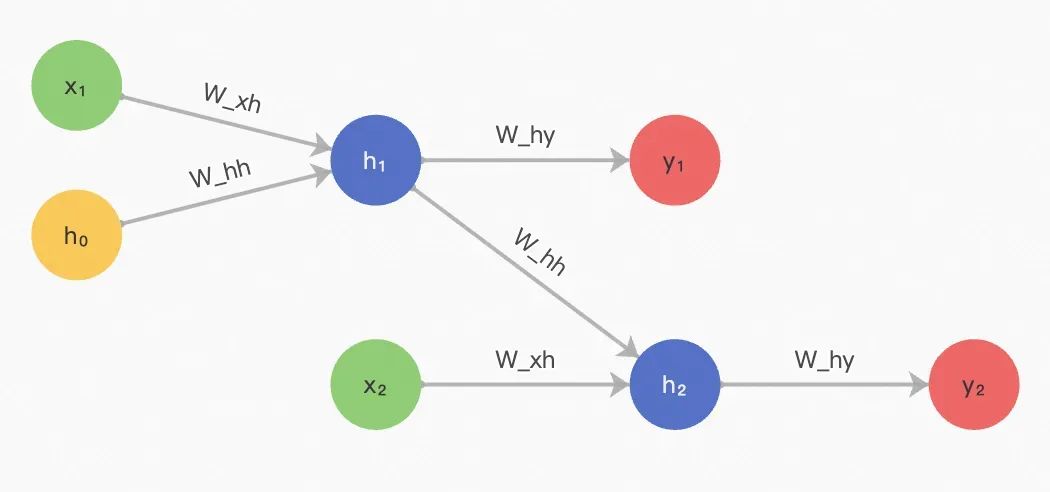
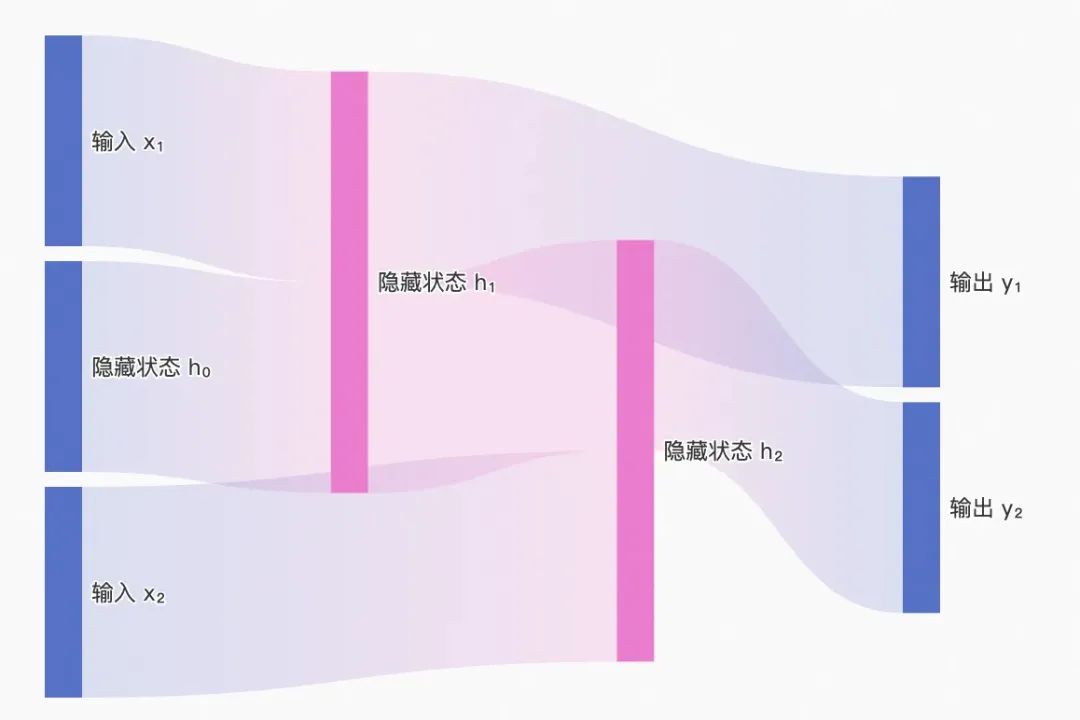
RNN 数学原理
把上图符号化一下,解释下 RNN 的数学原理。
RNN 中输出的计算依赖一个中间过程,称之为隐藏层,就是图中的 h。
输入到隐藏层:当前时间步的输入
与前一时间步的隐藏状态
![]()
会分别通过全连接层进行线性变换,再合并计算新的隐藏状态
![]()
。
![]()

隐藏层到输出层:基于当前时间步的隐藏状态
![]()
生成最终输出
![]()

公式看不懂其实没多大影响,只需要知道 RNN 中需要逐步计算输出,每一次输出的计算依赖上一步的输出。
在 seq2seq 中使用 RNN
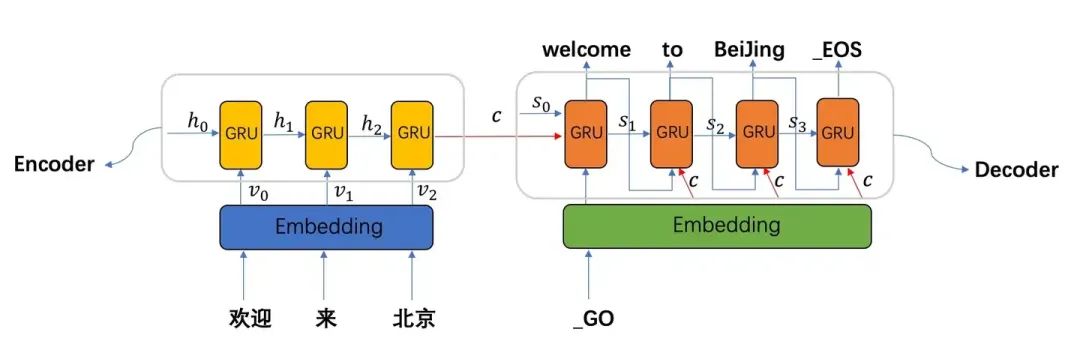
GRU 是 RNN 的变体
在 seq2seq 架构中把 RNN 分别应用到编码器和解码器,如果是翻译任务
-
编码器是一个完整的 RNN 流程。
-
输入:原始文本序列
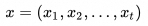
-
输出:包含语义信息的上下文向量
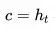
和所有隐藏状态序列
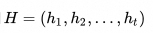
-
解码器同样是一个完整的 RNN 流程。
-
输入
-
编码器生成的
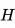
作为解码器初始的隐藏态
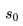
-
Sequence 开始符作为默认输入值,即初始输入为
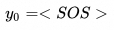
-
后续每次的输入是上次生成的翻译字符
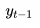
-
输出:
-
每个时间步的输出当前时间步对目标词翻译结果的概率分布
-
逐步生成翻译结果完整序列
-
最终输出 Sequence 结束符 <EOS>
注意:编码器和解码器是两个独立的 RNN,单个 RNN 的输入输出过程并不是翻译的过程。
RNN 的问题
虽然 RNN 的想法很好,但RNN 的隐藏状态需要同时承担多个任务:
-
存储历史信息
-
处理当前输入
-
为未来决策做准备
这种"一个变量承担多重任务"的设计导致信息容易被覆盖。在实际应用中遇到了几个严重问题:
1. 梯度消失和梯度爆炸
RNN 使用链式法则反向传播误差,每一步都乘以权重矩阵的导数,导致梯度随着序列长度迅速衰减或激增。
-
如果权重矩阵的特征值小于 1,梯度会指数级减小 → 梯度消失
-
如果特征值大于 1,梯度会指数级增长 → 梯度爆炸
2. 长距离依赖丢失
因为梯度消失,前面时间步的信息在训练中对当前输出几乎没有影响。
"我出生在北京,在那里度过了快乐的童年,后来搬到上海读书,毕业后在深圳工作了三年,现在回到了我的故乡___"
当 RNN 处理到最后的空白处时,很可能已经"忘记"了开头的"北京"。也就是说 RNN 只能记住短期依赖(Short-term Memory),对长序列中的早期信息几乎“记不住”。
3. 训练效率低
RNN 是顺序处理 的,每个时间步必须等前一个完成才能进行下一步计算,这样训练速度慢,难以利用 GPU 的并行计算优势,不适合大规模数据训练和实时应用。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

LSTM & GRU 的优化
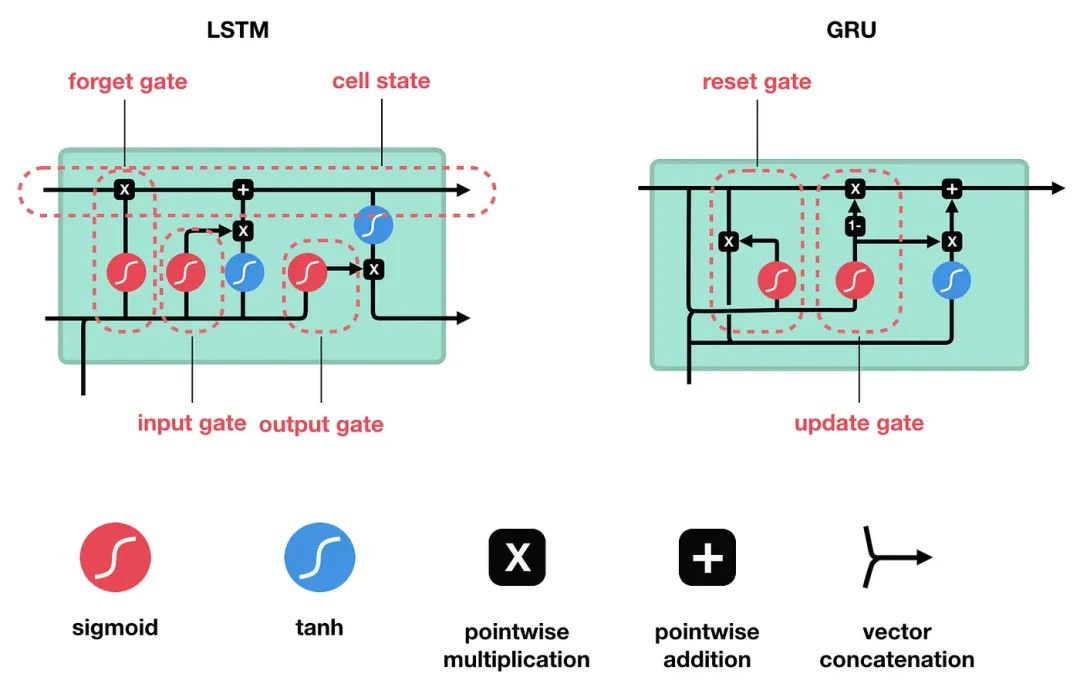
LSTM(Long Short-Term Memory)是 RNN 变体,专门设计用来解决传统 RNN 的长期依赖问题,LSTM 的核心是一个记忆单元(Cell State),通过精心设计的门控机制来控制信息的流动。
-
遗忘门:决定从细胞状态中丢弃哪些信息
-
输入门:决定哪些新信息将被存储到细胞状态中
-
输出门:决定基于细胞状态输出哪些信息
这种设计使 LSTM 能够在长序列中保持重要信息,同时丢弃不相关信息,有效解决了梯度消失问题。
GRU(Gated Recurrent Unit)是 LSTM 的简化版本,合并了 LSTM 的遗忘门和输入门为一个更新门,并引入了重置门,使结构更加简洁。GRU的两个门控机制:
-
更新门:决定保留多少前一状态的信息和添加多少当前信息
-
重置门:决定如何将新输入与前一记忆结合
与 LSTM 相比,GRU 参数更少,训练速度更快,在某些任务上表现相当甚至更好。
虽然 LSTM 和 GRU 在很大程度上缓解了 RNN 的梯度消失和短时记忆问题,但依然是串行处理模式,每一步的计算都依赖于上一步的结果,无法利用 GPU 的并行计算能力加速训练。而且在处理超长序列时,效率和性能仍然受限。
Transformer 工作流程
终于可以轮到主角登场了,2017 年 Google 的研究团队提出了一个大胆的想法:能否完全抛弃循环结构,让模型直接关注序列中任意两个位置之间的关系?这就是 Transformer 的核心创新——自注意力机制(Self-Attention)。
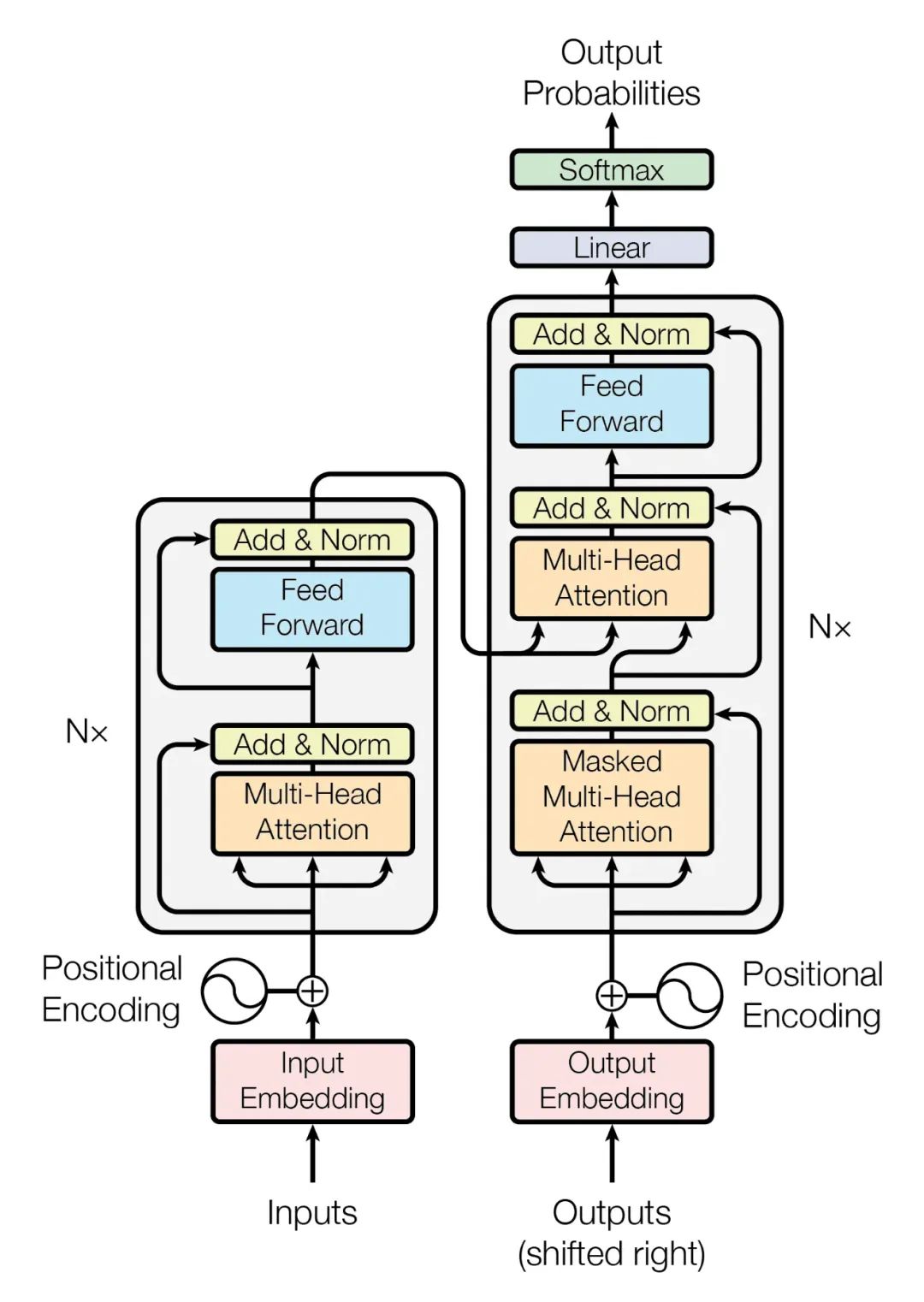
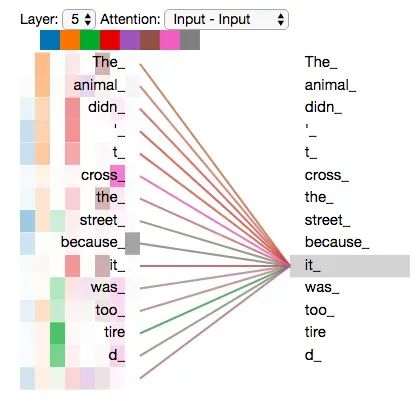
有兴趣阅读本文的同学肯定已经见过这张出自 Attention is all you need 论文的 Transformer 架构图,图中涉及的概念比较多,可以先用下面这个简化的图来理解 Transformer 数据流转过程。
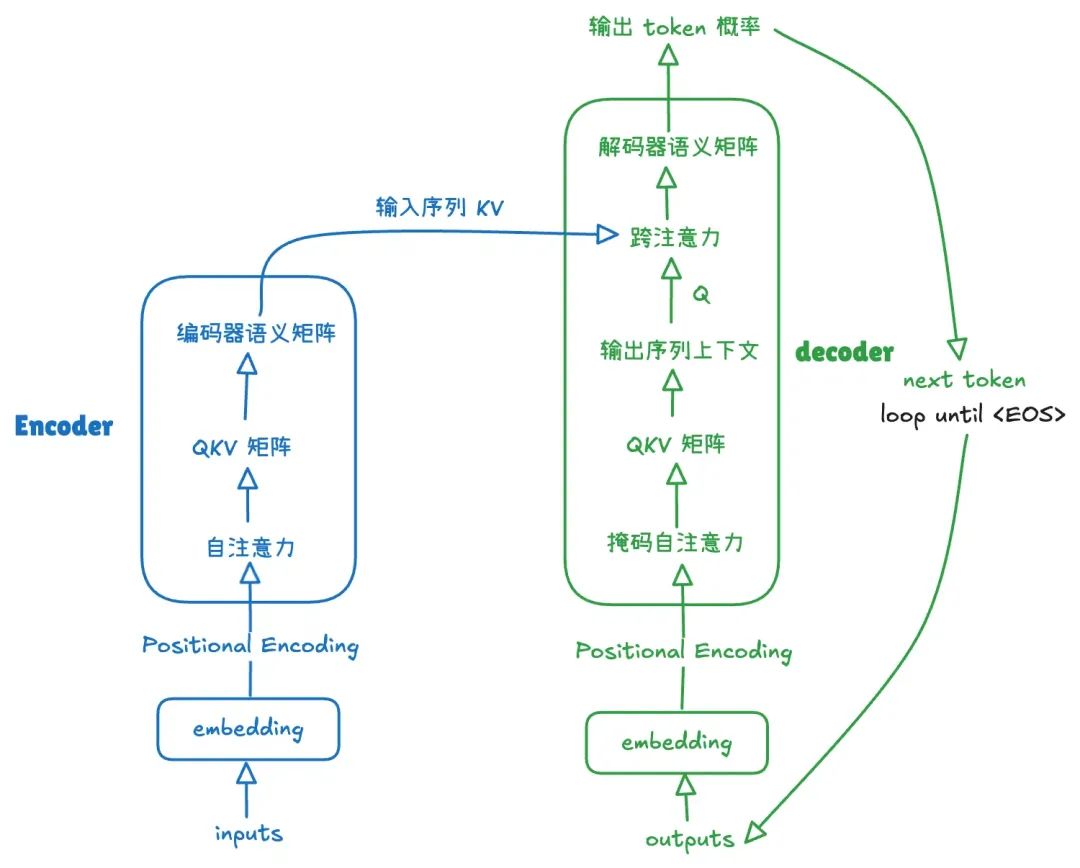
Transformer 和经典 seq2seq 架构一样使用了 Encoder-Decoder 模式,编码器负责理解输入序列,解码器把编码器的输出作为上下文,自回归输出目标序列,同样是一次编码、多次解码生成。
编码器一次编码:
1.输入序列会被转换成对应的词嵌入表示,每个 token 会被映射到一个连续的向量。然后,需要通过添加位置编码来保留输入序列的先后顺序信息,这样模型就能区分 A B 和 B A 的不同含义。
2.输入序列的词嵌入矩阵被送入模型,通过自注意力机制生成 Query(Q)、Key(K)和 Value(V)三个矩阵,这些矩阵是输入序列中各个 token 的特征表示。
3.Q 矩阵负责提出问题(查询),K 矩阵负责提供信息(匹配),V 矩阵包含实际内容。自注意力机制会计算每个 token 对其他 token 的重要性,也就是注意力权重(Attention Weights),用这些权重对 V 矩阵进行加权求和,生成包含输入序列中每个 token 语义的上下文表示。
因为只编码一次,编码器生成的语义矩阵在结果过程中不再变化(KV 也不会变化)。
解码器逐 token 解码:
1.解码器会对历史生成的目标序列进行嵌入映射,将历史生成结果转化为向量表示。为了保留生成序列的顺序信息,还需要加上位置编码。如果是首次解码(没有历史目标序列),则会使用特殊的起始标记 <SOS>。
2.经过嵌入和位置编码后,目标序列被送入掩码自注意力模块。掩码的作用是确保当前时间步只能看到已生成的历史序列,而不能访问未来的 token,严格遵守自回归生成的规则。
3.掩码自注意力会生成一组新的上下文表示矩阵,描述了解码器目前所有生成序列的内部关系,并作为对目标序列的特征提取结果。
4.解码器进一步通过跨注意力模块,与编码器生成的语义矩阵关联以获取来自输入序列的上下文信息
-
解码器使用掩码自注意力的结果,生成用于与编码器交互的查询表示(Query)。这个 Query 表示当前生成序列的需求或问题。
-
编码器的语义矩阵则通过固定的变换生成 Key(键)和 Value(值),表示输入序列中的全局信息。
-
解码器的 Query 会从编码器输出的 Key 中查询相关的信息,同时结合 Value 形成新的跨序列上下文信息。因为信息来自不同序列,这个操作被称为跨注意力。
5.跨注意力模块的输出被进一步处理,生成解码器最终的语义矩阵,这个矩阵用于预测当前时间步目标 token 的分布,通过采样或搜索方法解码器生成下一个单词。
6.最后,生成的新 token 会添加到历史生成序列中,更新为解码器的输入序列。解码器重复以上步骤,直到遇到特殊结束标记 <EOS>,整个目标序列生成完成。
使用 Transformer 架构翻译:The cat sat on the mat=============== 解码器工作 ===============输入: [<SOS>]第1步: 输入[<SOS>] → 生成 "猫"第2步: 输入[<SOS>, "猫"] → 生成 "坐"第3步: 输入[<SOS>, "猫", "坐"] → 生成 "在"...第n步: 输入[<SOS>, "猫", "坐", ...] → 生成 "<EOS>"
三、Transformer 实现
Embeding 与位置编码
Transformer 架构本身不包含序列位置信息,因为自注意力机制对输入序列的顺序是不敏感的,这在很多时候会导致歧义:
It's red too. <---> It's too red.我喜欢张三。 <---> 张三喜欢我。
为了让模型能够利用序列的顺序信息,Transformer 引入了位置编码。位置编码通过为每个位置生成唯一的编码,并与词嵌入(Word Embedding)结合,使模型能够区分相同 token 在不同位置的语义差异。
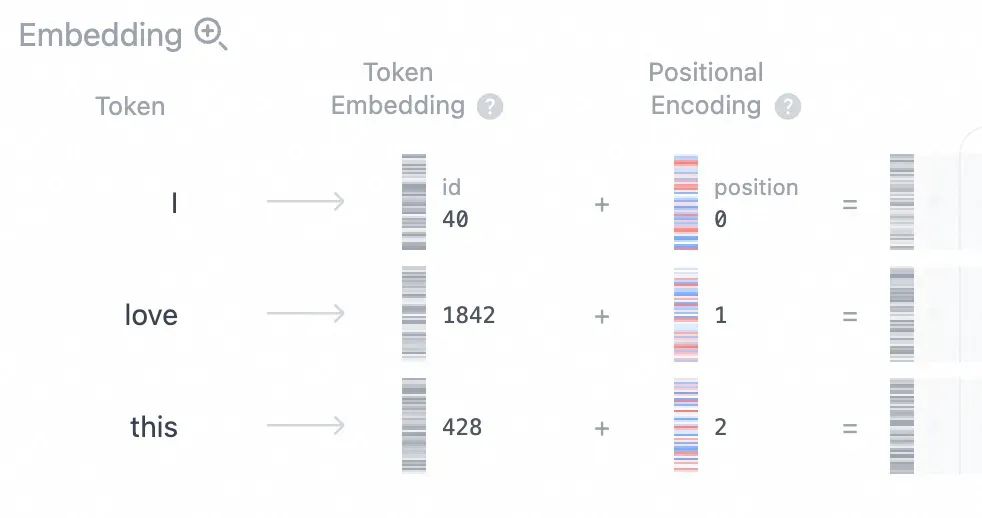
举个例子,我们的输入序列是 "I love this",让 GPT 预测下一个单词,首先对输入序列进行 token embeding 和 position encoding,得到嵌入矩阵。
什么是注意力
注意力机制并不是 Transformer 的发明,人类在阅读时可以利用注意力聚焦某个词的相关上下文,想象你在阅读这样一个句子:
"那只猫坐在垫子上,它看起来很舒服"
当你读到"它"时,你的大脑会自动回到前面找到"它"指代的对象——"猫"。这种能力就是注意力机制的本质:在理解当前词时,关注与其相关的其他词。
注意力并不是 Transformer 发明的概念,其最早由 Bahdanau 等人于2014年提出,用于解决 RNN 在编码器-解码器架构中的长期依赖问题。但传统注意力机制通过逐步传递信息,但受限于距离和计算效率,难以有效捕捉远距离关联。
Transformer 摒弃了 RNN 和 CNN,提出了自注意力机制,对序列中的每个元素(token)与序列中所有其他元素之间的关系进行建模,用于捕获序列内元素之间的依赖关系。换句话说,它让模型在处理某个 token 时,可以动态关注同一序列中其他对其有重要影响的 token。
有点像是句子中的每个 token 是一个神经元节点,重复一遍形成两层,中间做了全连接,连线就是两个token 之间的影响。
注意力的实现 QKV
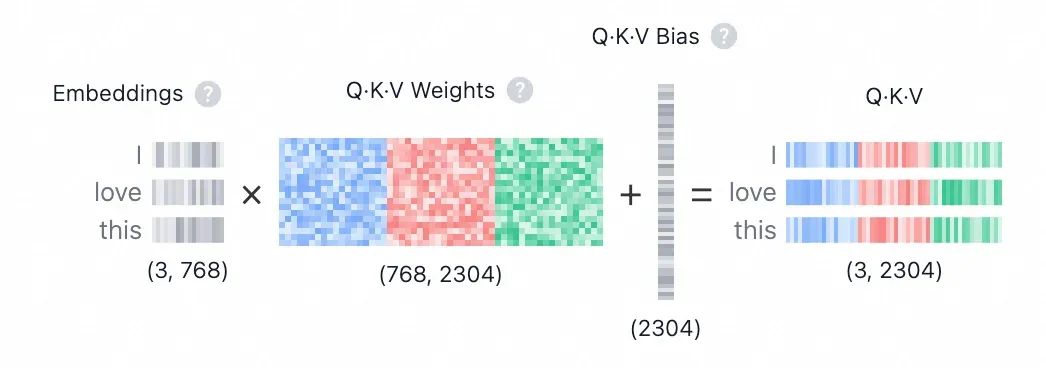
自注意力机制使模型能够关注输入序列 token 之间的相关性,从而使其能够捕捉数据中的复杂关系和依赖。现在我们知道了什么是注意力,但具体是怎么计算的呢?这就要引入 Transformer 的核心创新:QKV 机制。
上文中的嵌入矩阵 H 通过和权重矩阵(
![]()
)线性变换得到三个矩阵:Query (Q)、Key (K)、Value (V)
![]()
这三个矩阵是模型训练时候得到的。
这样就得到了 QKV 矩阵,那么 QKV 有什么作用?
-
Query:是每个 token 提出的“问题”向量,比如一个单词想知道序列中其他单词对其影响。
-
Key:是每个单词的“标签”向量,告诉其他位置,它和哪些 token 是相关的。
-
Value:是每个单词的语义内容,它是最终被注意力加权取回的信息。
想象一下在一个图书馆找一本书:
1.你要找一本书,你的问题是 Query:
-
你会问图书管理员一个关于书的信息,比如:“哪一本书讲关于人工智能的基础知识?”
-
这个问题就是 Query,它描述了你的需求。
2.图书馆的目录卡片是 Key:
-
图书馆里每本书会有一个目录卡片(对应于 Key),这张卡片告诉你这本书包含什么内容。
-
每本书都有自己的 Key,它可以回答:
-
这本书是关于什么的
-
这本书与问题是否相关
3.图书内容是 Value:
-
图书的 Key 告诉你是它关于什么的,而书的内容 Value 是它实际含有的信息。
-
当图书管理员通过目录卡片(Key)找到符合你提问(Query)的书之后,就把这本书的完整内容(Value)提供给你。
注意力的匹配过程:
-
你的问题 (Query) 会与所有书的目录卡片 (Key) 匹配(通过点积计算相关性)。
-
找到最符合你问题的 Key,图书管理员会把相应的图书 (Value) 借给你。
用一个具体例子来理解注意力:
句子:"那只可爱的小猫在阳光下睡觉"当模型处理"睡觉"这个词时:- Query(查询):"睡觉"想知道:谁在睡觉?在哪里睡?- Key(键):每个词都有自己的标签,如"小猫"标签是"动物"- Value(值):每个词的实际含义内容注意力计算发现:- "小猫" 与 "睡觉" 关联度最高(主语关系)- "阳光下" 与 "睡觉" 也有较高关联(地点关系)- "可爱的" 关联度较低(修饰词,与动作关系不大)
从 QKV 到语义表示
QKV 矩阵并不能表示 Token 和其他 Token 的相关性,从 QKV 矩阵到最终语义表示有一个计算过程。
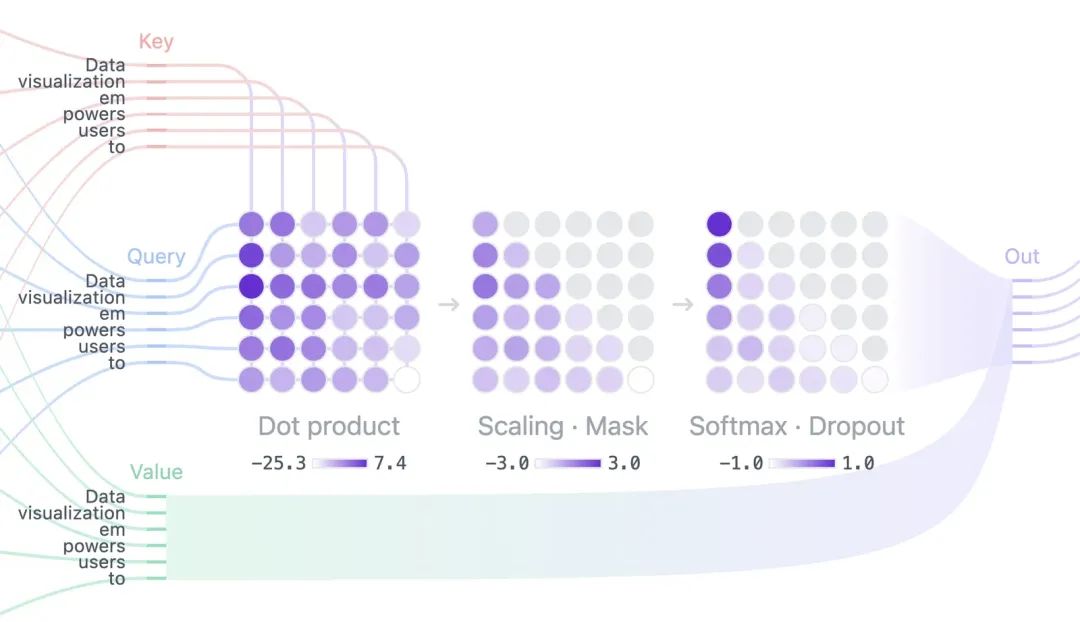
1. 计算 Query 和 Key 的相关性
每个 token 的 Query 和所有 token 的 Key 做矩阵乘法运算,计算出它对其他 token 的相关性。这会生成一个二维矩阵,即注意力分数矩阵(Attention Scores)
在矩阵乘法运算中,要保证行和列的维度匹配,为了与 Query 相乘,Key 必须转置为
![]()
2. 缩放和归一化
为了防止点积值过大造成梯度失控,需要对相似性分数除以
![]()
表示 Key 的维度
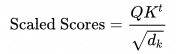
通过 softmax 操作,将缩放后的点积分数转化为一个概率分布(注意力的权重)。这样可以反映每个 token 对其他 token 的关注程度,并确保权重和为 1。
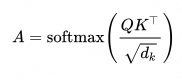
3. 加权求和获得最终语义矩阵
利用注意力权重矩阵 A 对 Value 矩阵进行加权求和,生成最终的上下文表示。这样模型可以根据注意力分数,从其他 token 中提取有用的信息。
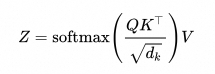
其实不理解这些公式影响也不太大,只需要知道经过一系列的运算,可以得到一个包含了序列中所有 token 的上下文表示矩阵即可。
最终的这个 Z 在不同的语境下有多个名字,先提前混个脸熟
1.隐藏表示(Hidden Representation)
2.隐藏状态矩阵(Hidden State Matrix)
3.上下文表示(Contextual Representation)
4.语义化表示矩阵(Semantic Representation)
5.可学习的特征表示(Learnable Feature Representation)
6.注意力结果(Attention Result)
7.层输出(Layer Output)
8.关键输出(Key Output)
def self_attention(input_seq, W_Q, W_K, W_V):"""简化版自注意力机制参数:- input_seq: 输入序列,shape = [seq_len, d_model]- W_Q, W_K, W_V: 查询、键、值的权重矩阵,shape = [d_k or d_v, d_model]返回:- context_vectors: 注意力加权后的输出,shape = [seq_len, d_v]"""# 步骤1: 创建 Q, K, VQ = linear_transform(input_seq, W_Q) # shape: [seq_len, d_k]K = linear_transform(input_seq, W_K) # shape: [seq_len, d_k]V = linear_transform(input_seq, W_V) # shape: [seq_len, d_v]# 步骤2: 计算注意力分数(Q @ K^T)scores = np.dot(Q, transpose(K)) # shape: [seq_len, seq_len]# 步骤3: 缩放(Scale)d_k = K.shape[-1]scaled_scores = scores / np.sqrt(d_k) # shape: [seq_len, seq_len]# 步骤4: Softmax 归一化attention_weights = softmax(scaled_scores) # shape: [seq_len, seq_len]# 步骤5: 加权求和(Attention weights @ V)context_vectors = np.dot(attention_weights, V) # shape: [seq_len, d_v]return context_vectors
跨注意力与掩码自注意力
自注意力用于计算序列中每个 token 与其他 token 的关系——即实现序列内部的依赖关系建模。简单来说,每个 token 都可以“关注”同一输入序列的其他 token,从所有 token 中提取有用的信息并重新生成上下文敏感特征。
跨注意力是 Transformer 解码器的一部分,与自注意力不同,跨注意力的信息来自于不同的序列——用于结合输入序列(来自编码器的 KV)和目标序列(来自解码器的 Q)的信息。
掩码自注意力是一种限制版的自注意力机制,用来解决目标序列的因果性(causality)问题。在解码器生成目标序列时,模型需要严格遵循时间步的自回归逻辑,确保生成当前 token
时,只能访问之前的 token
![]()
,而不能看到未来 token
![]()
。
仔细想想这不是多此一举吗,还没生成未来的 token,怎么能看得到?其实这个 mask attention 主要作用在模型训练阶段,防止解码器偷看还未生成的训练数据作弊,造成模型过拟合。
在生成阶段虽然理论上没有未来 token,掩码自注意力仍然使用,可以维持模型训练和生成过程逻辑的一致性,同时可以支撑批量化生成过程中可能同时计算多个时间步的需求。
重新看一下架构图
这次我们尽量用公式解释一下。
编码器一次编码:
1.输入序列首先被转换为词嵌入向量,然后添加位置编码以保留序列顺序信息
![]()
2.输入的嵌入序列经过自注意力机制,生成 QKV 矩阵
![]()
3.对 QKV 矩阵进行一系列操作,最终得到输入序列的语义矩阵,每一行是输入序列中对应 token 的语义表示:
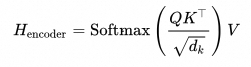
解码器逐词解码:
1.目标系列嵌入
-
对解码器历史输出序列进行词嵌入,并添加位置编码,生成初始表示
![]()
-
如果是第一次解码,则用特殊标记 <SOS> 作为历史序列
2.掩码自注意力
-
解码器对目标序列的上下文进行提取,通过掩码自注意力机制生成目标序列的特征表示
![]()
-
计算注意力特征表示
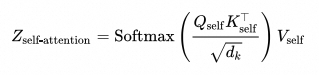
3.跨注意力:解码器结合编码器的语义矩阵,通过跨注意力机制提取输入序列的上下文信息。
-
跨注意力的 Query 来自掩码自注意力的输出运算
![]()
-
编码器提供 Key 和 Value
![]()
-
结合 Query、Key 和 Value 计算跨注意力特征表示
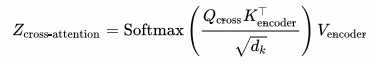
4.预测下一个 Token
-
解码器将跨注意力的输出转化为词表上的概率分布,预测下一个 token
![]()
-
通过采样或搜索算法选择一个新的

;
5.循环生成
-
生成的新 token 会添加到历史输出序列中,形成新的输入
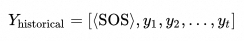
-
重复以上步骤,直到生成结束标记 <EOS>,目标序列生成完成。
多头注意力
单个注意力已经很强大了,但 Transformer 的设计者们想:如果同时用多个"大脑"从不同角度理解同一句话会怎样?这就是多头注意力(Multi-Head Attention)——输入序列被分到多个子空间,每个子空间独立计算自己的注意力表示。
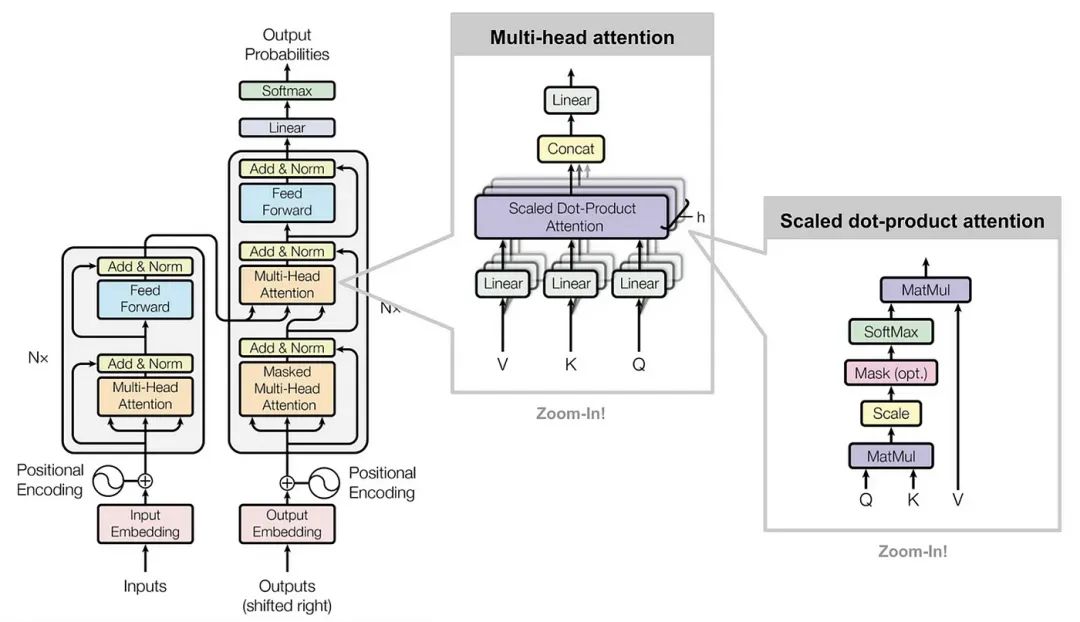
多头注意力的核心思想是并行地在多个子空间中计算注意力表示,每个头独立学习特定的关系模式,并在最后通过拼接融合生成最终的上下文特征
1.每个头分别计算自己的注意力:生成
![]()
;
2.拼接这些注意力输出:
![]()
;
3.最后通过线性变换
![]()
得到最终上下文表示;
为什么要这么麻烦呢?模式使用多头注意力后有几个明显的优点:
1.丰富表征能力:不同的注意力头独立计算,捕获多样化的语义、语法关系。
2.高效的计算:并行化支持多头计算,同时降低复杂度。
3.增强模型稳定性:通过冗余和分散化处理,降低单点故障的影响。
遗漏的关键步骤
数据流转过程中的一些关键步骤没有提到,但不影响对 Transformer 整体思路理解
-
前馈网络:对每个 token 的特征表示进行进一步的非线性变换和特征提取
-
残差连接与归一化:稳定梯度流并加速模型收敛
-
残差连接:将模块的输入和输出相加,形成新的表示
-
归一化:对每层的输出进行归一化处理,使得数据分布更加稳定,便于后续层的处理
-
多层堆叠:编码器堆叠多层(6 层或 12 层),每一层包括自注意力机制、前馈网络和残差连接与归一化。每一层的输出作为下一层的输入,经过逐层处理最终得到编码器的全局语义表示。
重新审视一下 Transformer 架构图
这次貌似可以看明白了,Nx 表示堆叠了 N 层,每一层的输入是上一层的输出。
-
编码器堆叠 N 层:多层次处理输入序列,通过堆叠逐步捕获更深的上下文信息,使得输入序列的特征向量更表达语义和语法。
-
解码器堆叠 N 层:在生成序列时,每层逐渐从已生成的序列中综合更多的上下文信息,同时将目标序列与编码器输出对齐,真正实现高质量的跨语言/跨序列建模。
Transformer 的优势
Transformer 相较于传统的 RNN(包括 LSTM 和 GRU)为基础的 Seq2Seq 模型,在多个方面具有显著的优势:
1.并行运算
-
RNN 的设计是循环递归的,每个时间步的计算依赖于前一个时间步的输出。这种顺序计算方式阻碍了模型在长序列上的并行化处理,导致训练和推理过程速度较慢。
-
Transformer 完全摒弃了递归计算,使用掩码自注意力机制在训练阶段能够同时对整个序列进行处理,加速模型训练过程。
2.长距离依赖
-
RNN 越往后传播,模型的隐藏状态可能丢失早期输入的信息,尽管 LSTM、GRU 等通过“门控机制”稍微缓解了这个问题,但在捕获长距离依赖时仍显乏力。
-
Transformer 通过自注意力机制,每个 token 都能直接与整个序列中的所有 token 建立联系,全局感知能力极大提高了对长序列上下文的理解能力。
3.丰富的特征表示
-
RNN 的隐藏状态是单一维度的时间步相关表示,难以建模复杂的句法和语义模式。
-
多头注意力机制让 Transformer 可以从多角度捕获语义特征,更全面地表示复杂的信息依赖。
Transformer 在计算效率、长距离依赖建模、特征表示能力和任务泛化性等方面全面优于 RNN Seq2Seq,彻底颠覆了序列建模的传统方式,成为现代 NLP 和更广泛任务中的核心架构。
常见 Transformer 架构模型
T5:Transformer 正统
T5(Text-to-Text Transfer Transformer)是由谷歌提出的一种采用 Encoder-Decoder 结构的 Transformer 模型。其核心思想是通过将所有 NLP 任务统一建模为“文本到文本(text-to-text)”问题,将输入视为自然语言文本,将输出作为目标文本序列。例如:
-
输入一个问题文本,模型输出答案文本;
-
输入原文,输出其摘要、翻译或分类标签。
T5 使用经典的 Transformer 架构:输入 → [Encoder] → 语义表示 → [Decoder] → 输出。由于其架构严格遵循 Transformer 的标准设计逻辑,因此可以称之为“Transformer 正统”模型。
T5 能适配翻译、摘要、问答和分类等多种任务类型,尤其擅长处理输入与输出存在明确语义映射关系的任务。
GPT:Decoder-Only
架构
在 Transformer 架构中,Encoder 的主要任务是编码输入序列(如文本、图像等数据),通过堆叠多层注意力机制提取输入的深层语义表示。它将输入数据压缩为固定格式的语义表示,供 Decoder 解读。
GPT(Generative Pre-trained Transformer)任务核心是从给定的上下文中预测下一步的内容,并不涉及对额外输入的深度理解。因此 GPT 只使用了 Transformer 的 Decoder 部分,输入的序列会直接进入 Decoder,作为“历史输出”的一部分(标准 Transformer Decoder 初始输入序列是 <SOS>),参与注意力计算和生成下一步 Token,通过多头注意力机制对输入序列解析和建模上下文,然后自回归生成,这使得 GPT 架构极其简单、高效。
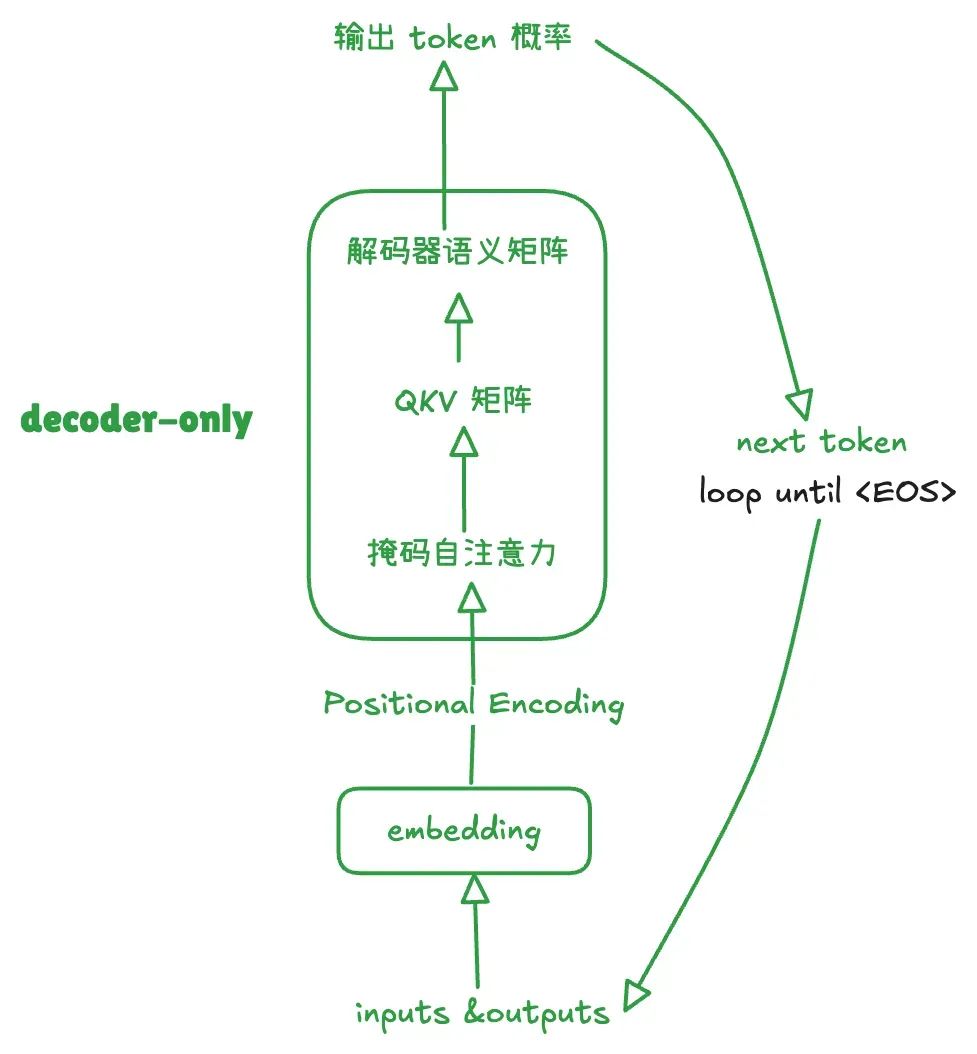
在 GPT 中没有了编码器,首先会把用户输入当做初始化的历史输出,使用掩码注意力机制生成 QKV 矩阵,然后预测下一个 token,直到遇到结束符 <EOS>,这就是 GPT 的单向注意力。
这个机制也正是 GPT 类模型幻觉相对严重,擅长生成而不擅长理解的原因。
工作流程
如果我们要求 GPT 根据 "Once upon a time, in a magical forest, there lived a brave little rabbit." 生成一个童话故事,简化版的工作流程是这样的:
1.输入准备:
-
将输入序列分词为小单位(Token),转化为向量表示,并加入位置信息。
2.初始化上下文:
-
模型将开头提示作为上下文,视为“历史输出”,用于开始生成后续内容。
3.单向注意力处理:
-
模型通过自注意力机制分析输入,并使用遮掩机制仅关注当前和之前的内容,确保生成过程是从左到右的。
4.前馈网络计算:
-
注意力处理后的结果通过前馈神经网络进行进一步特征提炼,输出更新后的上下文表示。
5.预测下一个词:
-
模型基于上下文预测下一个词的概率分布,例如可能是
"The","rabbit","explored","a", 等选项。
-
根据生成规则(如 Greedy Search 或采样),选择最优词,例如
"explored"。
6.循环生成:
-
将生成的词
"explored"添加到上下文,重复上述过程,生成后续内容,例如:"Once upon a time, in a magical forest, there lived a brave little rabbit. The rabbit explored a hidden cave full of treasures."
7.结束生成:
-
模型会继续生成,直到遇到结束符
<EOS>,或达到最大生成长度。
8.输出完整故事:
-
最终生成的词序列被解码为自然语言:
"Once upon a time, in a magical forest, there lived a brave little rabbit. The rabbit explored a hidden cave full of treasures and discovered a magical wand..."
这是 GPT 的完整架构,相对于经典的 Transformer 确实比较简单
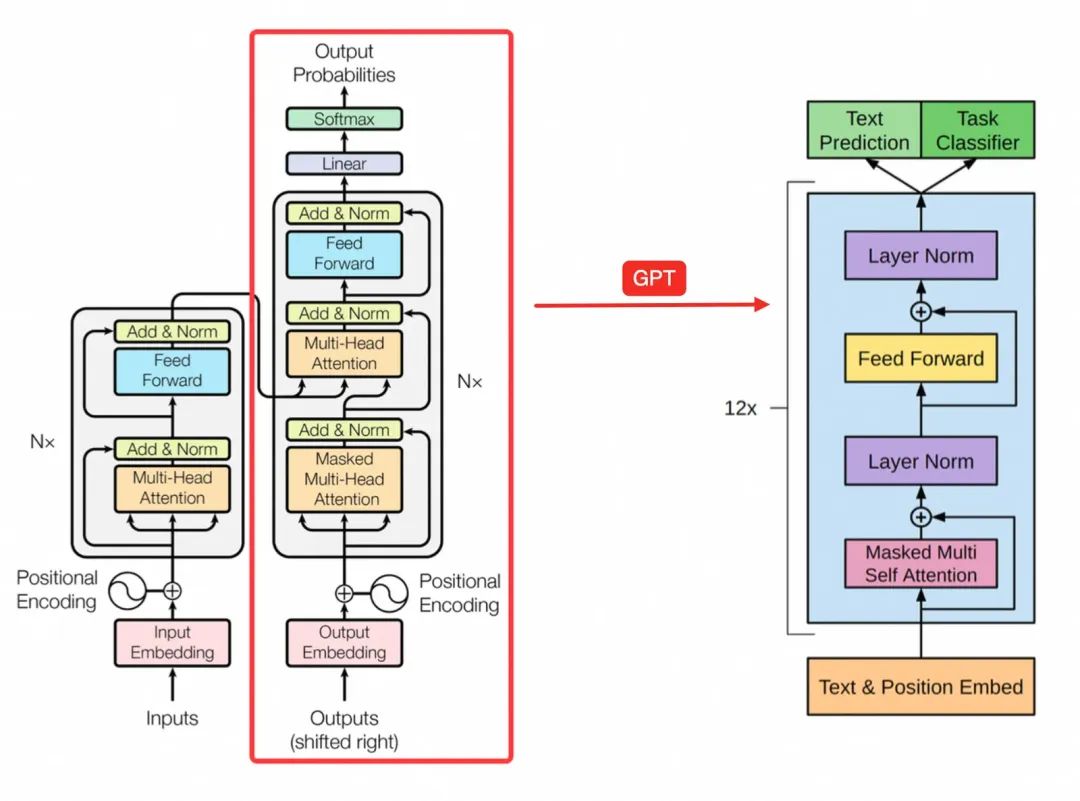
优势与局限
Decoder-only 模型的核心是单向注意力机制(Causal Attention)。这意味着模型在生成序列中的当前词时,只能关注其前面的词,而不能看到其后面的词。这种设计非常适合生成任务,因为生成文本本质上是一个从左到右、逐步预测下一个词的过程。模型通过学习前面词的模式来预测后续词,从而连贯地生成文本。
然而,这种单向性限制了模型对文本整体语境的理解。在理解任务(如情感分析、问答、文本摘要等)中,通常需要模型能够同时考虑文本的上下文信息,包括当前词前后的所有词。例如,要理解一句话的情感,模型需要同时分析正向和负向的关键词,以及它们在句子中的排列方式。单向注意力机制使得模型难以像人类一样“通读”并全面把握文本的含义。
BERT:Encoder-Only
BERT(Bidirectional Encoder Representations from Transformers)是由谷歌提出的一种专注于自然语言理解(NLU)的 Encoder-Only 架构的 Transformer 模型。BERT 的核心目标是:将输入文本通过双向编码器形成深层语义表示,用于丰富地捕捉上下文依赖关系。
BERT 的双向注意力在计算每个单词的表示时,同时结合了句子中左侧和右侧的上下文信息,对比单向模型(如 GPT),BERT 能理解更加全面的语义关系。
架构特点
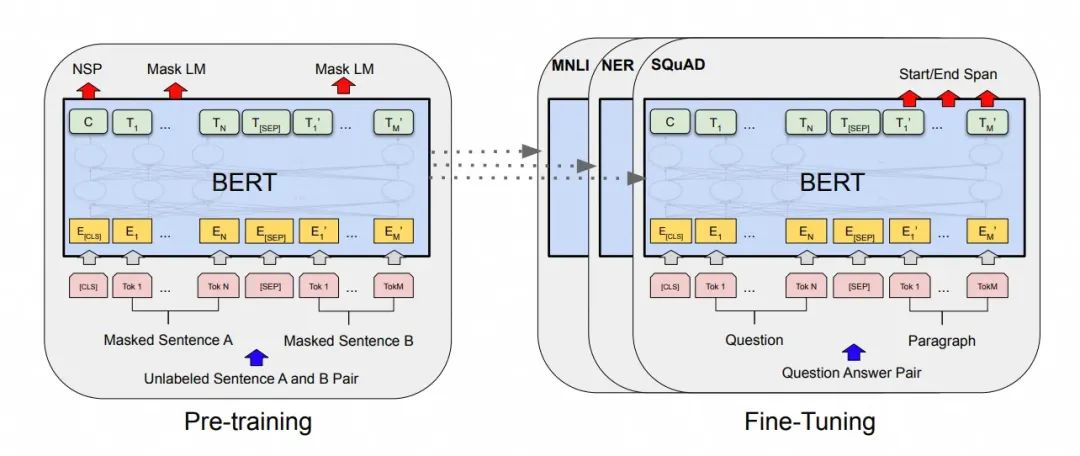
[CLS] 是添加在每个输入示例前面的特殊符号,[SEP] 是一个特殊分隔符(例如分隔问题/答案)。
BERT 只使用了 Transformer 的 Encoder 部分,摒弃了生成式任务相关的 Decoder。其参数通过大规模预训练进行优化,输入 → [双向 Encoder] → 深层语义表示。
话说普通的 Transformer 编码器中任意 Token 会和序列中所有 Token 建模,本身就是双向的,为什么 BERT 要强调其双向注意力?
BERT 特别强调“双向注意力” 的原因,并不仅仅是使用 Encoder 部分的自注意力机制,而是它对模型的训练方式和设计目标进行了特殊优化。BERT 在大规模无标签语料上进行预训练,采用了两个创新的预训练目标:
(1) Masked Language Modeling(MLM):掩码语言模型
在训练阶段,随机遮掩(Mask)输入序列中的部分单词(用 [MASK] 替换),然后让模型同时关注该词的左侧上下文和右侧上下文来预测掩码的词,这种方式使 BERT 学会结合双向建模。
例:The cat sat on the [MASK]. → The cat sat on the mat.
(2) Next Sentence Prediction(NSP):下一句预测
给定两个句子 A 和 B,让模型判断 B 是否是 A 的下一句。这有助于学习句子之间的逻辑关系。
任务例子:
-
正例:
[A: The cat sat on the mat.] [B: It was purring softly.]
-
负例:
[A: The cat sat on the mat.] [B: Dogs are very loyal animals.]
擅长领域
由于 BERT Encoder-Only 架构 和强大的语义建模能力,BERT 特别擅长理解类任务,主要应用于以下领域:
(1) 自然语言理解任务
-
文本分类:情感分析、主题分类等。
-
文本相似性:句子对分类任务(如自然语言推断NLI、问句匹配)。
-
问答系统:基于上下文提取答案(机器阅读理解任务,例如 SQuAD)。
-
信息检索(IR):根据用户查询从文档中提取相关内容。
(2) 语言学相关任务
-
核心语义分析:例如语法关系解析、命名实体识别(NER)。
-
样本不足任务:通过预训练语义表示在小数据集下迁移学习。
ViT:无 CNN 视觉任务处理
ViT(Vision Transformer) 是一个将 Transformer 架构成功应用于图像处理的模型,由谷歌研究团队在论文“An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”中提出。
传统的 CNN 在图像处理上采用卷积操作(Convolution)来提取局部特征。而 ViT 则完全摆脱了卷积操作,通过使用 Transformer 的 自注意力机制(Self-Attention),直接对图像进行全局建模。
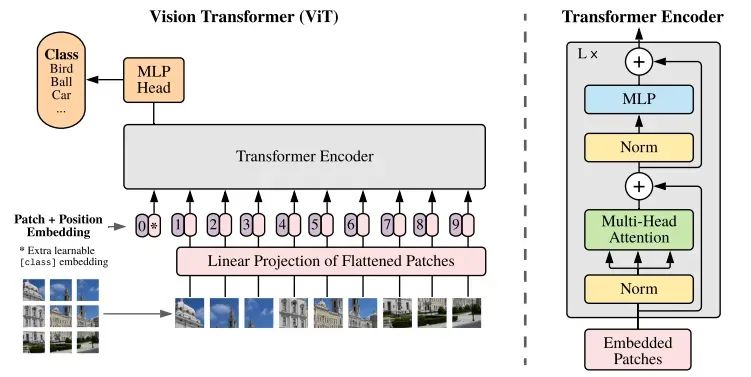
ViT 的核心想法是将图像处理任务(如分类)转化为像文本处理一样的“序列任务”,即通过将图像分成小块(patches)并线性展平,作为序列输入到经典的 Transformer 中进行处理。它颠覆了传统的卷积神经网络(CNN)在图像领域占主导地位的局面,是视觉任务的重要突破。
如果对视觉、图像感兴趣还可以看看
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献286条内容
已为社区贡献286条内容

所有评论(0)