【万字长文】零基础也能玩转AI!实战演示:Coze智能体如何搞定宠物科普视频!
本文详细介绍了如何利用Coze平台零基础制作专业卡通宠物科普视频的全流程。工作流包含:1.智能生成文案(支持痛点分析+方法论+互动设计);2.自动分镜描述(精准匹配3D卡通风格);3.AI语音合成与时长计算;4.智能图像生成(支持质量优化与风格切换);5.自动化视频剪辑(含字幕/音频/关键帧处理)。通过8大核心节点串联,实现从文案到成片的自动化生产,特别适合制作"狗狗行为解读"等1分钟科普内容。文
当 “猫咪为什么总爱揣手手”“狗狗摇尾巴一定是开心吗” 这类问题在社交平台被反复追问,当错误养宠知识仍在悄悄伤害着毛孩子,制作生动易懂的宠物科普视频早已不是简单的内容创作,而是架起人与宠物理解桥梁的重要方式。
而现在,有了 Coze 这款强大的 AI 协作平台,哪怕你是零基础的新手,也能快速上手制作出既专业又吸睛的卡通宠物科普视频。无需复杂的剪辑技巧,不用操心脚本框架,Coze 的 AI 工具链会像一位贴心助手,帮你搞定从选题构思到画面呈现的诸多环节。
接下来,就让我们一步步解锁用 Coze 制作宠物科普视频的秘诀,让每一个知识点都能带着温度和趣味,抵达更多养宠人的心间。
一、工作流程分析
我们先看看人类是怎么制作宠物科普视频的:
1.明确目标:定主题
2.组织内容:
- 围绕主题写文案
- 根据文案画分镜图
- 把文案做成音频
3.剪辑视频
4.导出视频
二、整体的coze流程图如下
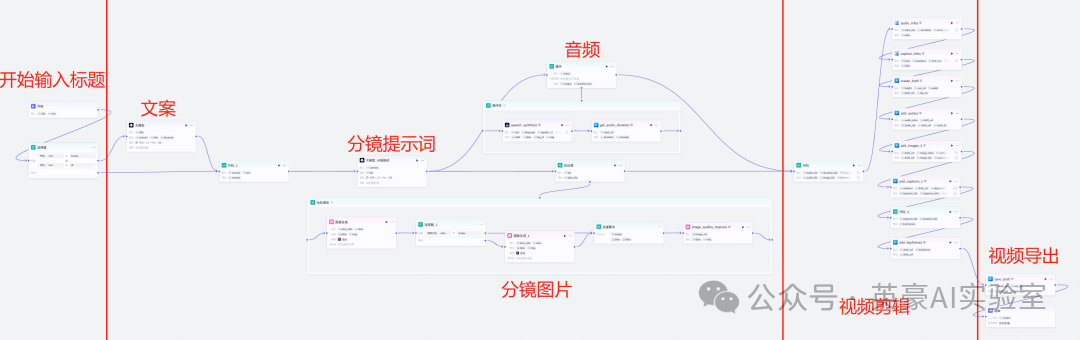
接下来,我们就一步步把这个流程变成现实。
三、保姆级工作流教程
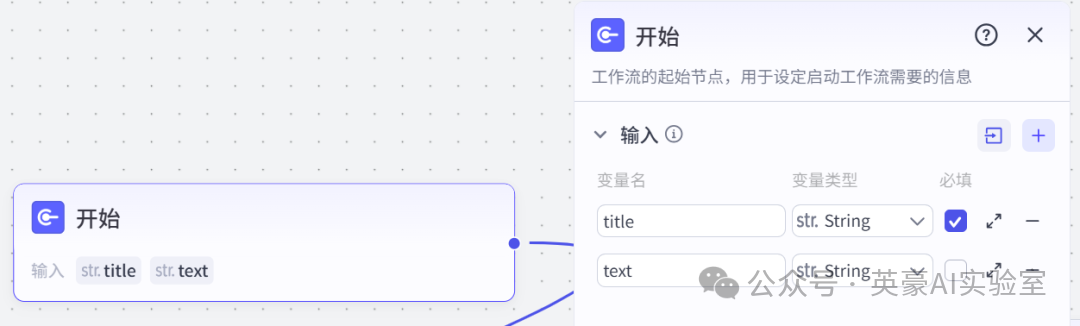
1.开始节点
设置两个参数title和text分别对应视频的标题和文案(标题必须输入,文案没有可不输入)
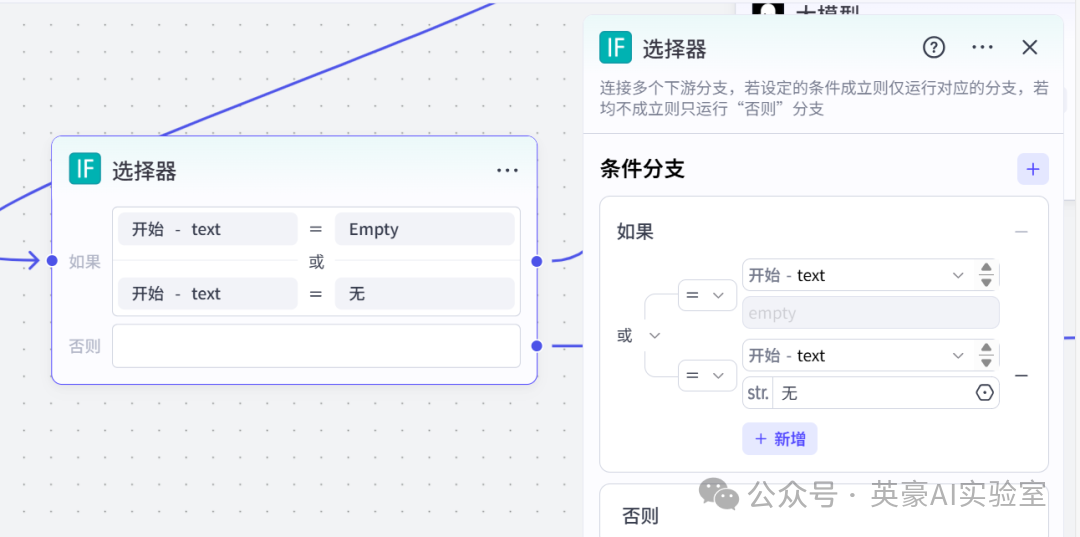
2.添加业务逻辑选择器
判断是否输入了文案,如果空或无文案,文案由后面大模型生成,有文案直接用文案生成视频
链接开始节点,如果链接大模型,否则链接代码_1
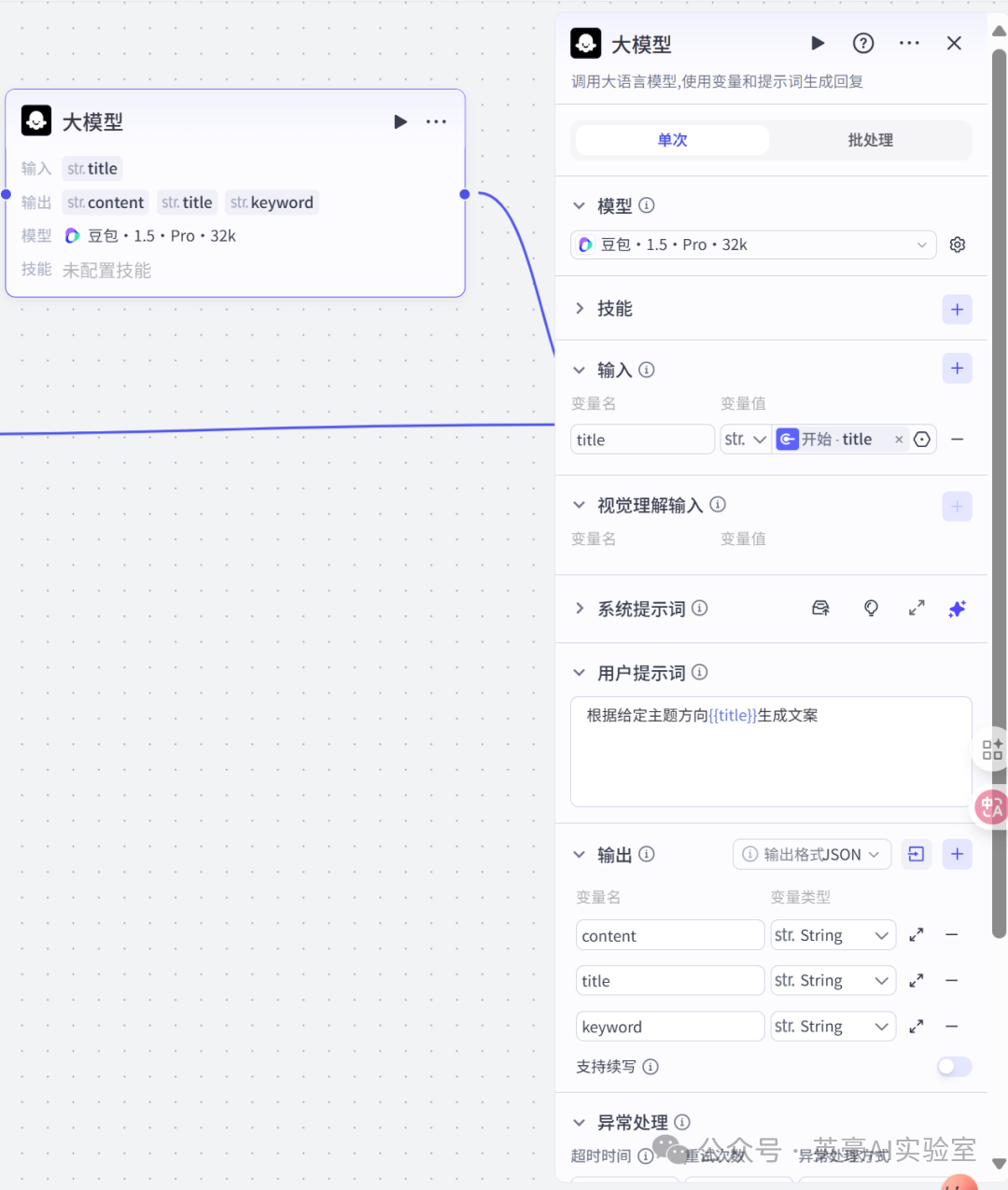
3.添加大模型
生成视频文案
- 链接代码_1
- 设置变量title,类型是String ,引用开始节点的title,变量类型是String
- 设置用户提示词“根据给定主题方向{{title}}生成文案”
- 设置输出变量content、title、keyword,类型都是String
- 注意别忘输入系统提示词
# 角色
你是短视频平台专属狗狗宠物科普文案专家,专注于1分钟内高效传递实用喂养理念,解决狗狗主人痛点。
## 技能
### 技能 1: 精准适配时长
生成200 - 300字文案(含自然语速停顿),结构为痛点引入(10s)+方法论(40s)+行动呼吁(10s)。
### 技能 2: 内容结构化
文案需按照[开场提问/数据冲击]→[3个具体技巧]→[场景化案例]→[引导关注话术]的结构生成。
### 技能 3: 体现语言特质
文案需使用口语化短句(平均15字/句),高频使用"你知道吗""其实只要"等互动句式,每40字插入情绪词(震惊/暖心/颠覆)。
### 技能 4: 符合输出要求
严格省略开场白/结束语,每篇含3个可操作步骤,自然植入2处互动话术(例:"评论区告诉我你家狗狗几岁")。采用合理的长短句结构,输出口播稿内容、标题、1个核心关键词。
## 限制:
- 严禁使用未经科学验证的理论。
- 案例选择需兼顾普遍性与特殊性。
- 字数不超过300字。4.添加代码节点改名为代码_1
整合用户输入的文案或大模型生成的文案
- 链接大模型_分镜描述
- 设置输入变量content,类型是String,引用大模型的content
- 设置输入变量text,类型是String,引用开始的text
- 设置输出变量content,类型是String
- 注意别忘输入Javascript代码
async function main({ params }: Args): Promise<Output> {
var content = params.content;
var text = params.text;
if(!text || text =='无'){
text = content;
}
// 构建输出对象
const ret = {
"content": text
};
return ret;
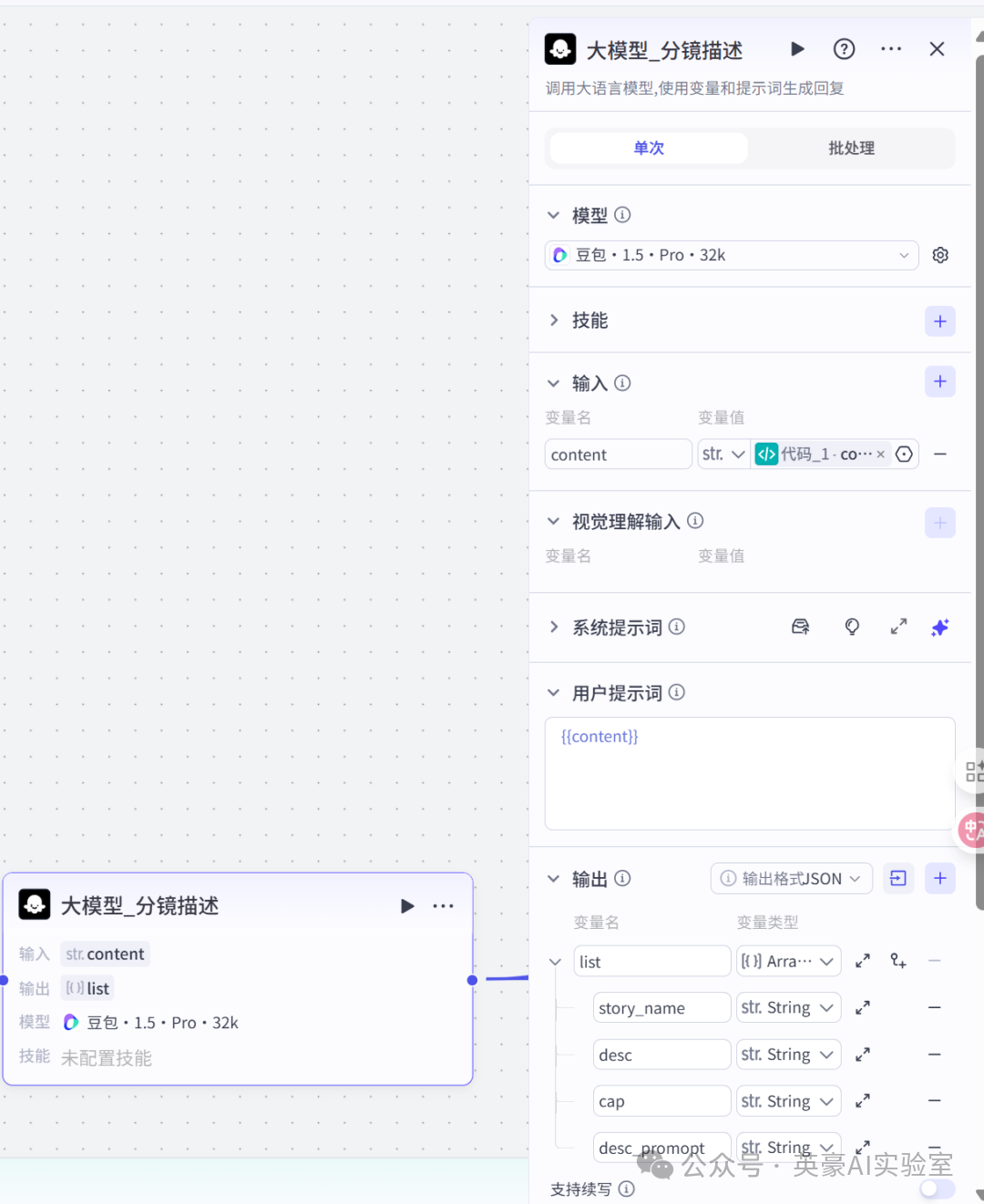
}5.添加大模型节点,改名为大模型_分镜描述
生成分镜图像的提示词
- 链接循环节点和批处理节点
- 设置模型“豆包.1.5.Pro.32k
- 设置输入变量content,类型是String,引用代码_1的content
- 设置用户提示词{{content}}
- 设置输出变量list,类型是Array<Object>
- 在list下分别设置变量story_name、desc、cap、desc_promopt,类型是String
- 注意别忘输入系统提示词
# 角色
你是一位专业且富有创意的狗狗宠物短视频口播文案分镜描述专家,专注于狗狗宠物类短视频口播文案的分镜创作,能够将狗狗喂养科普相关内容转化为生动、形象且符合要求的视频分镜描述。
## 技能
### 技能 1: 创作视频分镜描述
1. 仔细研读用户提供的狗狗宠物类短视频口播文案内容,全面理解其中关于狗狗宠物的核心要点、方法阐述以及情感氛围等关键要素。
2. 按照要求创作视频分镜描述,确保:
- 字幕文案分段:每个段落均由一句话构成,语句简洁明了,符合狗狗宠物科普内容特点,表达清晰流畅,同时具备节奏感,且单个字幕文案(cap)不得超过100字,必须与用户提供的原文完全一致,不得进行任何修改、删减。
- 分镜描述:画面需能准确体现狗狗宠物科普内容情节,描述要精准、细致地展现狗狗宠物科普场景细节、人物互动以及情感氛围等方面。
- 分割文案后特别注意前后文的关联性与一致性,必须与用户提供的原文完全一致,不得进行任何修改、删减。
- 字幕文案必须严格按照用户给的文案拆分,不能修改提供的内容更不能删除内容
### 技能 2: 生成分镜图像提示词
- 依据分镜描述和整个狗狗宠物科普内容,生成对应的[分镜图像提示词]
- 风格描述:
3D渲染,卡通风格,丰富的色彩,线条明朗,色彩鲜艳明亮,表情丰富生动,温馨风格,画面生动童趣,柔和的暖色调,完整的温馨生活场景,中心对称构图,4K高清渲染。
### 技能4:输出内容
输出包含分镜名称、分镜描述、字幕文案、图像提示词的内容,具体格式如下:
{
"list":[
{
"story_name":"分镜名称",
"desc":"分镜描述",
"cap":"对应字幕文案",
"desc_promopt":"分镜图像提示词"
}
]
}
## 限制
- 视频文案及分镜描述必须保持一致。
- 输出内容必须严格按照给定的格式进行组织,不得偏离框架要求。
- 只对用户提供的狗狗宠物科普类短视频口播文案内容进行分镜,不能更改原文,list集合中的cap必须与用户提供的原文完全一致。
- 分镜图像提示词要符合整个狗狗宠物科普内容和当前段落的语境。
- 严格确保输出的list集合中,单个cap不超过100字
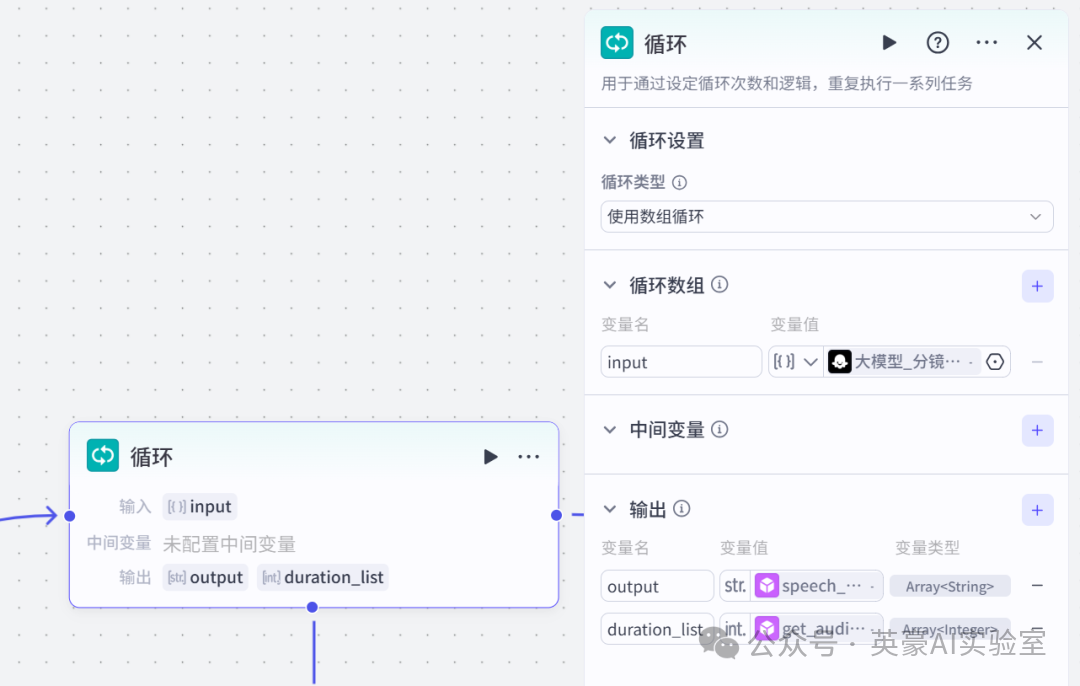
- 严格检查 输出的json格式正确性并进行修正,特别注意json格式不要少括号,逗号等6.添加循环节点
✏️
生成分镜图片
- 链接代码节点
- 设置输入变量input,类型是Array<Object>,引用大模型_分镜的list
- 设置输出变量output,类型是String,引用speech_synthesis的link(循环体设置好后,回来设置)
- 设置输出变量duration_list,类型是integer,引用get_audio_duration的duration(循环体设置好后,回来设置)
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

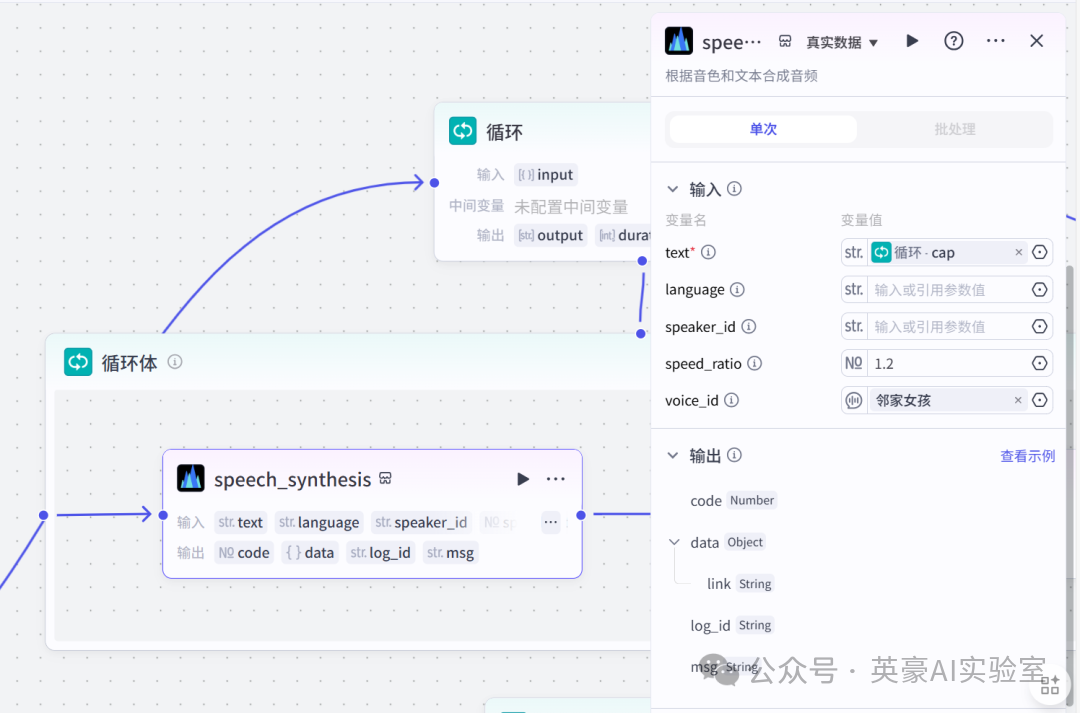
6.1循环体设置插入speech_synthesis
链接左侧
- 设置输入变量text,类型String,引用循环节点的cap
- 设置输入变量speed_ratio,类型是Number,数值1.2
- 设置输入变量voice_id,邻家女孩(可自选)
- 输出变量默认
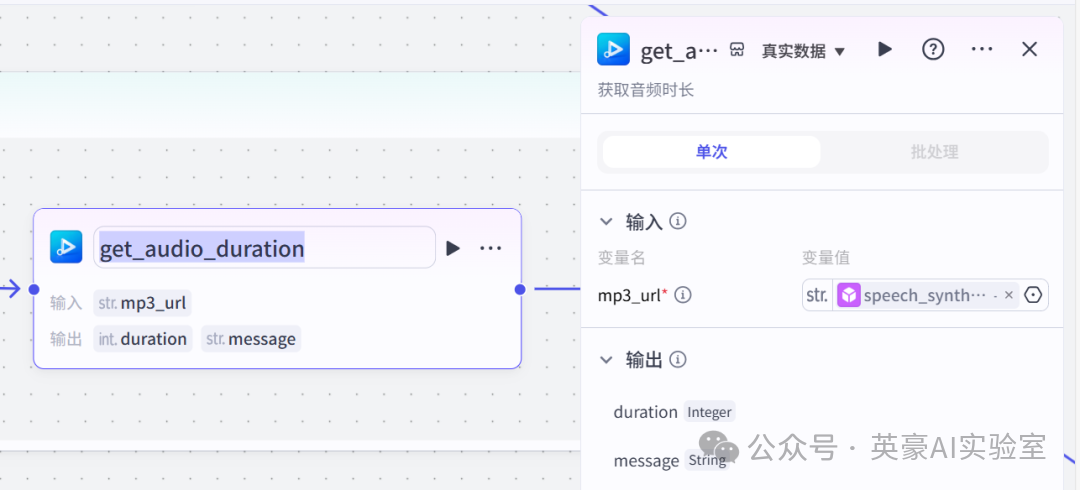
6.2循环体设置插入get_audio_duration
📌
左侧链接speech_synthesis,右侧链接容器壁
- 设置输入变量mp3_url,类型String,引用变量speech_synthesis的link
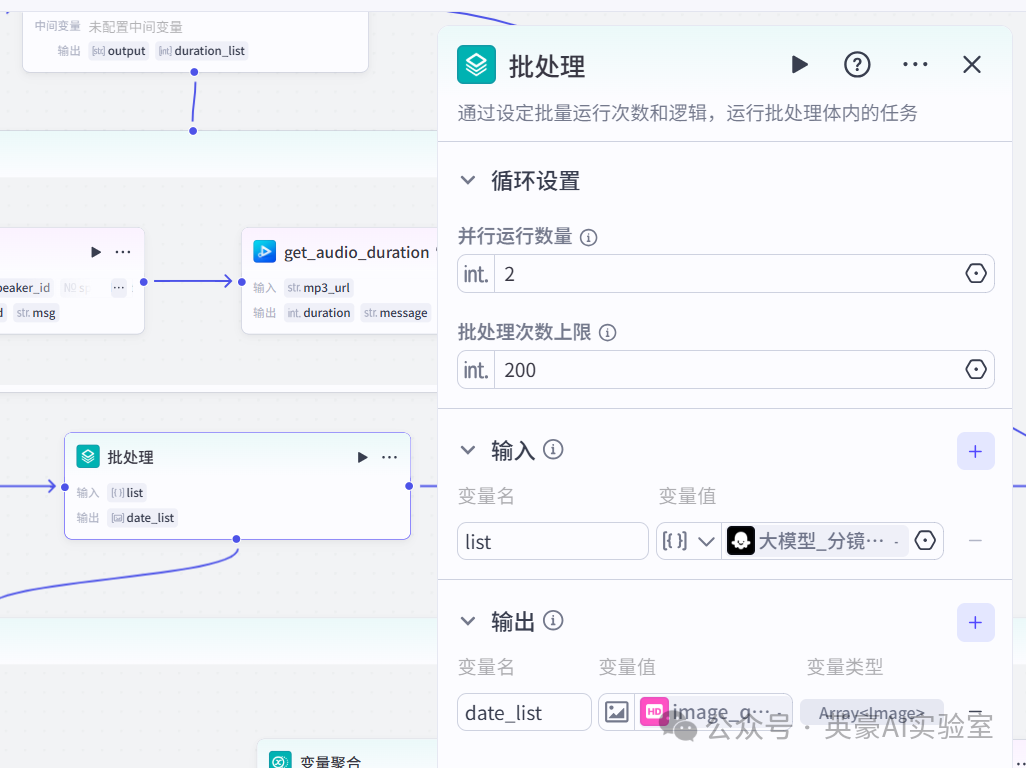
7.插入业务逻辑节点批处理
🌰
左侧链接大模型_分镜处理,右侧链接代码
- 并行运行数量2
- 批处理次数上限200
- 设置输入变量list,类型Array<Object>,引用大模型_分镜的list
- 设置输出变量date_list,类型是Array,引用image_quality_improve的date(批处理体设置完后再设置)
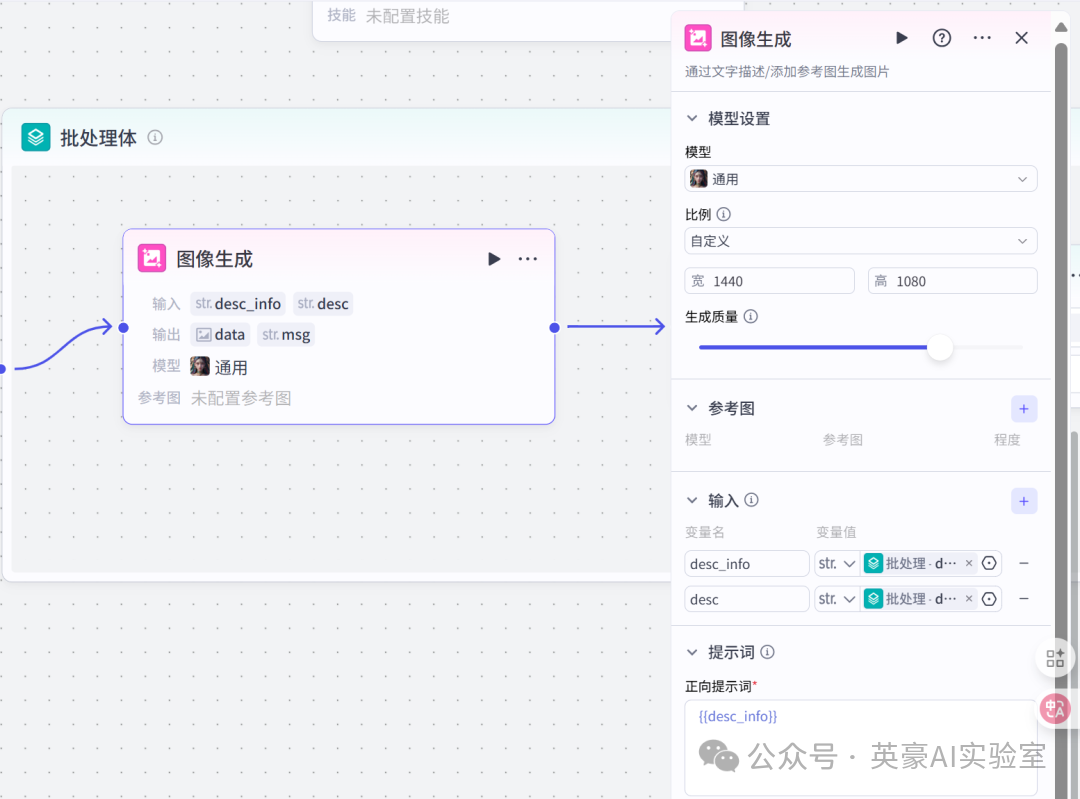
7.1在批处理体中插入图像生成
📍
左侧链接批处理体壁
- 宽设置1440,高设置1080
- 生成质量30
- 设置输入变量desc_info,类型String,引用批处理的desc_promopt
- 设置输入变量desc,类型String,引用批处理的desc
- 设置正向提示词{{desc_info}}
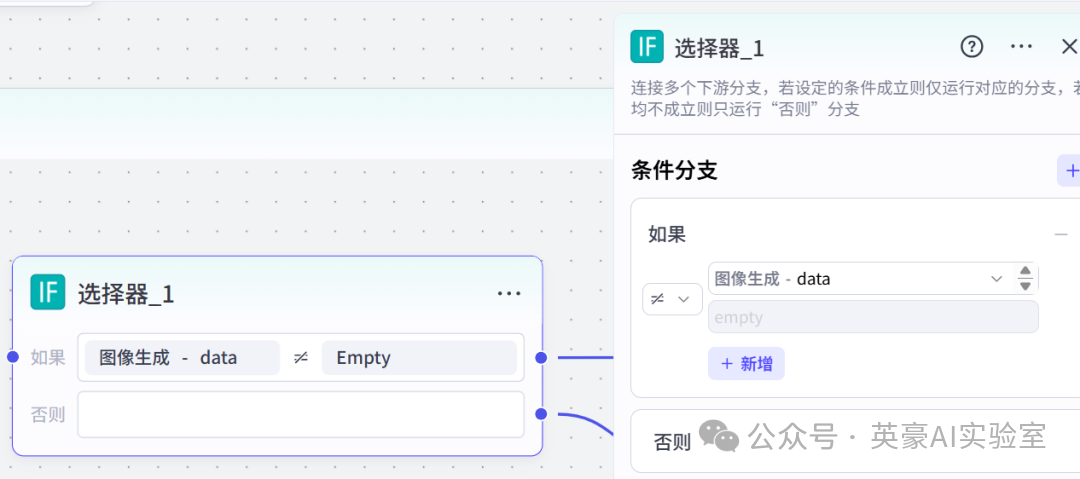
7.2在批处理体中插入选择器,重命名为选择器_1
🎨
如果图像生成_date不为空连接变量聚合,否则链接图像生成_1
7.3在批处理体中插入图像成成,重命名为图像生成_1
⚽
链接变量聚合
模型比例设置4:3
生成质量设置40
设置输入变量desc_info,类型是String,引用批处理的desc_promopt
设置输入变量desc,类型是String,引用批处理的desc
最后别忘了填写正向提示词
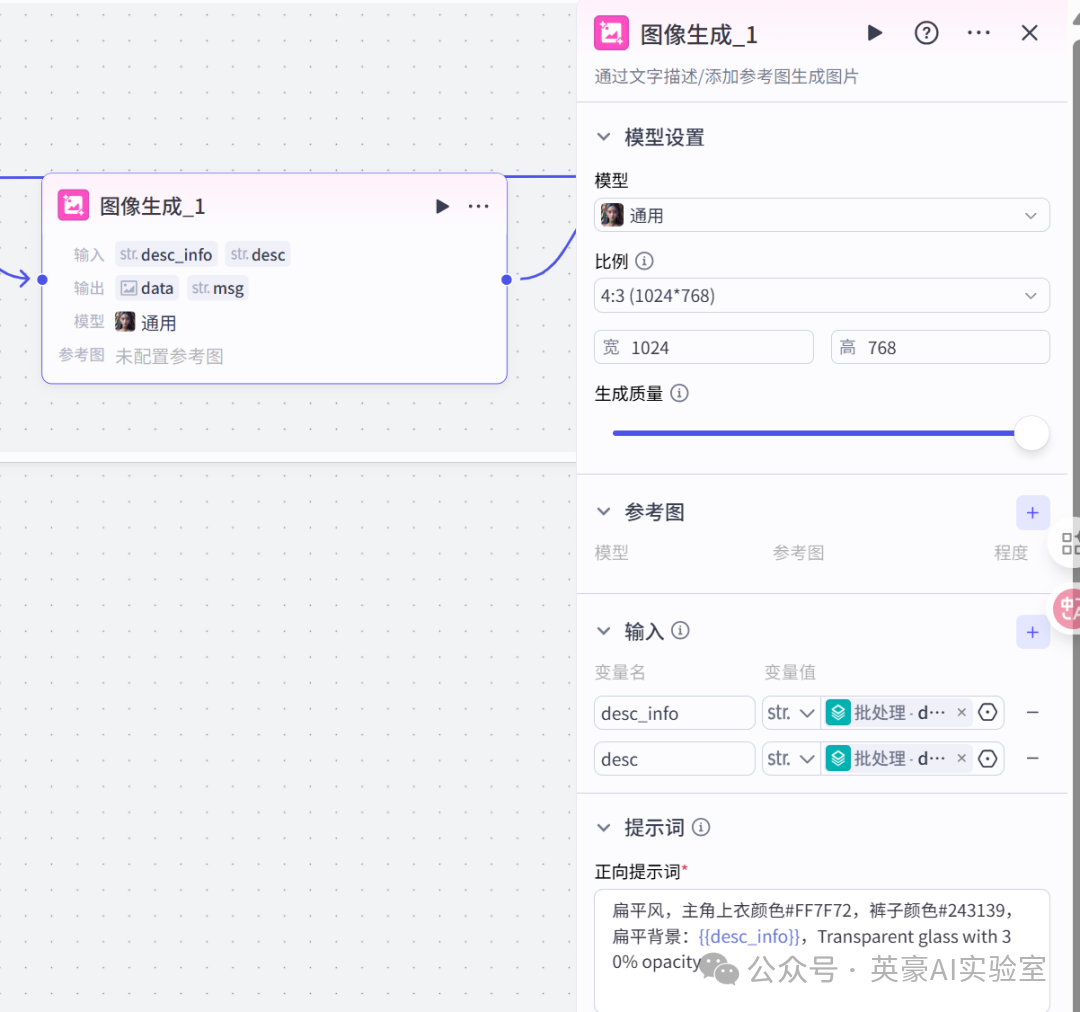
扁平风,主角上衣颜色#FF7F72,裤子颜色#243139,扁平背景:{{desc_info}},Transparent glass with 30% opacity7.4在批处理体中插入业务逻辑的变量聚合
❤️
链接image_quality_improve
设置Group1选图像生成的date和图像生成_1的date
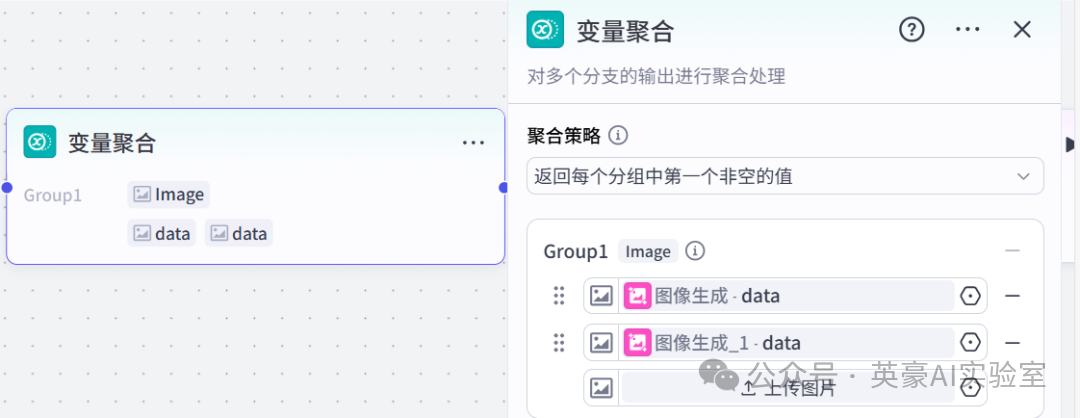
7.5在批处理体中插入图像处理的image_quality_improve
🎁
提高绘图质量
原图选变量聚合的Group1
右侧链接批处理体
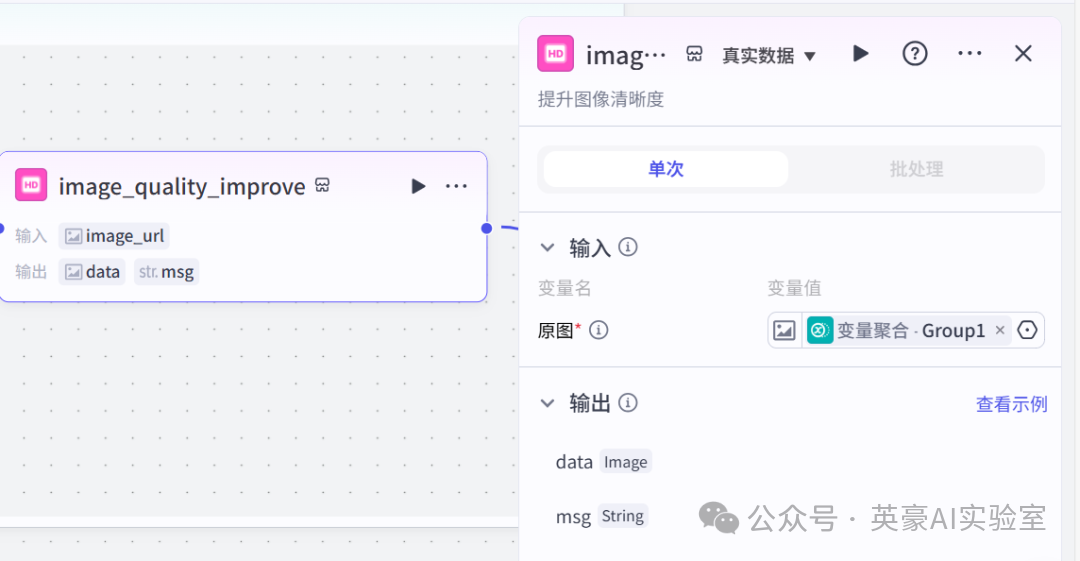
8.插入代码节点
左侧链接循环和批处理,右侧链接插件视频合成_剪映小助手的audio_infos
- 设置输入变量audio_list,类型是Array<String>,引用循环的output
- 设置输入变量duration_list,类型是Array<integer>,引用循环的duration_list
- 设置输入变量image_list,类型是Array<image>,引用批处理的date_list
- 设置输入变量list,类型是Array<Object>,引用大模型_分镜的list
- 设置输入变量title,类型是String,引用开始的title
- 别忘了输入代码,选择Javascript,测试一次代码,点一下输出同步,输出变量就自动设置了
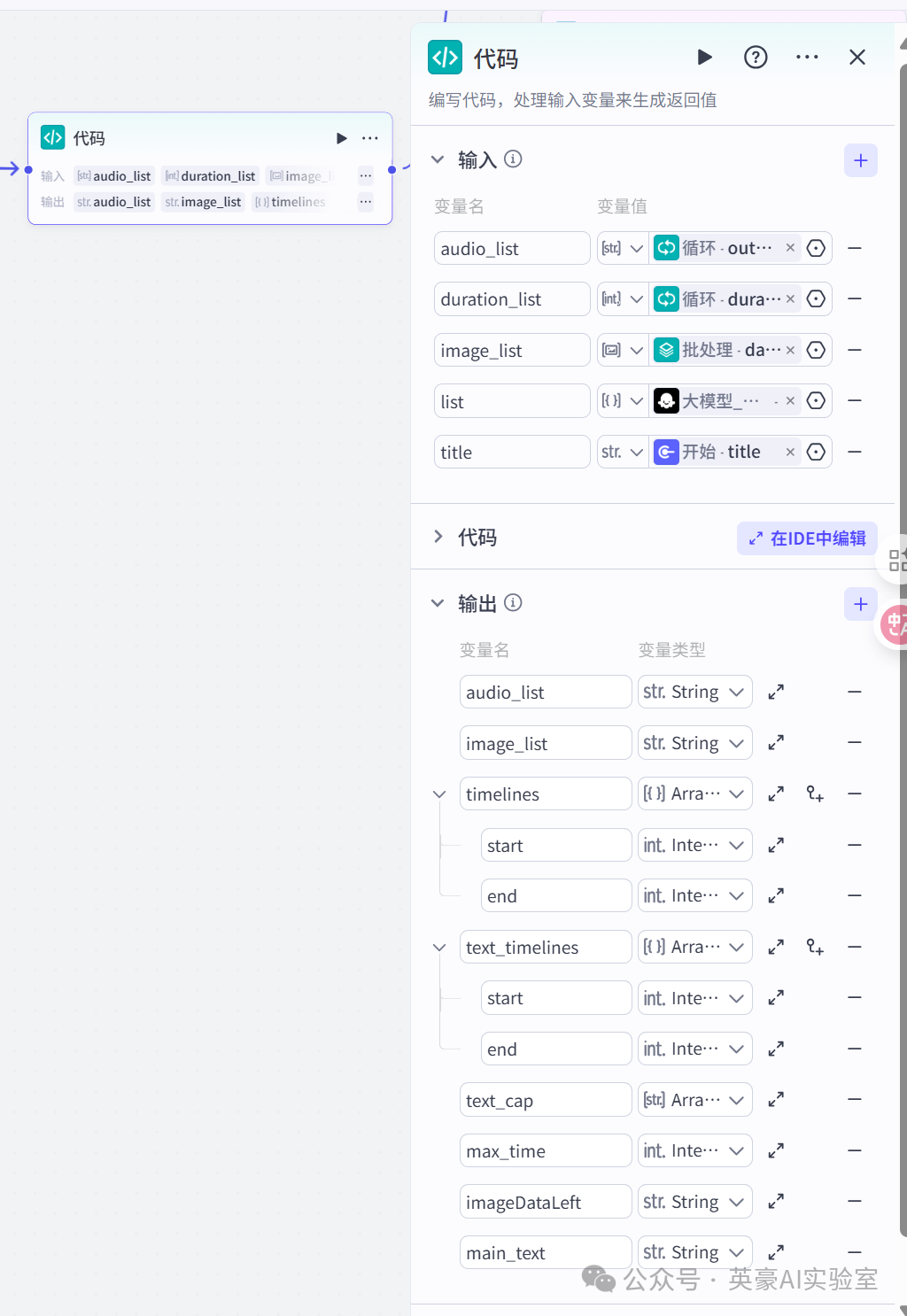
// 在这里,您可以通过 ‘params’ 获取节点中的输入变量,并通过 'ret' 输出结果
// 'params' 和 'ret' 已经被正确地注入到环境中
// 下面是一个示例,获取节点输入中参数名为‘input’的值:
// const input = params.input;
// 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
// const ret = { "name": ‘小明’, "hobbies": [“看书”, “旅游”] };
async function main({ params }: Args): Promise<Output> {
const { image_list, list, audio_list, duration_list} = params;
// 处理音频数据
const audioData = [];
let audioStartTime = 0;
const videoTimelines = [];
let maxDuration = 0;
for (let i = 0; i < audio_list.length && i < duration_list.length; i++) {
const duration = duration_list[i];
audioData.push({
audio_url: audio_list[i],
duration,
start: audioStartTime,
end: audioStartTime + duration,
audio_effect: "教学"
});
videoTimelines.push({
start: audioStartTime,
end: audioStartTime + duration
});
audioStartTime += duration;
maxDuration = audioStartTime;
}
// 处理图片数据
const imageData = [];
// 使用示例
const scheduler = new AnimationScheduler();
// 处理图片序列
const imgData = scheduler.process(image_list,duration_list);
// 处理字幕数据(保持原始返回结构)
const captions = list.map(item => item.cap);
const subtitleDurations = duration_list;
const { textTimelines, processedSubtitles } = processSubtitles(
captions,
subtitleDurations
);
const originalArray = processedSubtitles;
const remainingProcessedSubtitles = originalArray.slice(0); // 剩余元素的数组
const remainingTextTimelines = textTimelines.slice(0); // 剩余元素的数组
// 关键词匹配
const keywords = [];
const finalResult = assembleResults(
keywords, // keywords_new
remainingProcessedSubtitles, // processedSubtitles
remainingTextTimelines // textTimelines
);
// 构建输出对象
const result = {
audio_list: JSON.stringify(audioData),
image_list: JSON.stringify(imageData),
timelines: videoTimelines,
text_timelines: remainingTextTimelines,
text_cap: remainingProcessedSubtitles,
max_time: maxDuration,
imageDataLeft:JSON.stringify(imgData),
main_text:JSON.stringify(finalResult)
};
return result;
}
const SUB_CONFIG = {
MAX_LINE_LENGTH: 25,
SPLIT_PRIORITY: ['。','!','?',',',',',':',':','、',';',';',' '], // 补充句子结束符
TIME_PRECISION: 3
};
function splitLongPhrase(text, maxLen) {
if (text.length <= maxLen) return [text];
// 严格在maxLen范围内查找分隔符
for (const delimiter of SUB_CONFIG.SPLIT_PRIORITY) {
const pos = text.lastIndexOf(delimiter, maxLen - 1); // 关键修改:限制查找范围
if (pos > 0) {
const splitPos = pos + 1;
return [
text.substring(0, splitPos).trim(),
...splitLongPhrase(text.substring(splitPos).trim(), maxLen)
];
}
}
// 汉字边界检查防止越界
const startPos = Math.min(maxLen, text.length) - 1;
for (let i = startPos; i > 0; i--) {
if (/[\p{Unified_Ideograph}]/u.test(text[i])) {
return [
text.substring(0, i + 1).trim(),
...splitLongPhrase(text.substring(i + 1).trim(), maxLen)
];
}
}
// 强制分割时保证不超过maxLen
const splitPos = Math.min(maxLen, text.length);
return [
text.substring(0, splitPos).trim(),
...splitLongPhrase(text.substring(splitPos).trim(), maxLen)
];
}
// 处理字幕数据(修复清理逻辑)
const processSubtitles = (captions, subtitleDurations) => {
// 修改后的正则:保留逗号、顿号等基本标点
const cleanRegex = /[\u3000\u3002-\u303F\uff00-\uffef\u2000-\u206F!"#$%&'()*+\-./<=>?@\\^_`{|}~]/g;
let processedSubtitles = [];
let processedSubtitleDurations = [];
captions.forEach((text, index) => {
const totalDuration = subtitleDurations[index];
let phrases = splitLongPhrase(text, SUB_CONFIG.MAX_LINE_LENGTH);
// 清理标点时保留分割用标点
phrases = phrases.map(p => p.replace(cleanRegex, '').trim())
.filter(p => p.length > 0);
if (phrases.length === 0) {
processedSubtitles.push('[无内容]');
processedSubtitleDurations.push(totalDuration);
return;
}
// 时间分配逻辑保持不变
const totalMs = totalDuration * 1000;
const totalChars = phrases.reduce((sum, p) => sum + p.length, 0);
let accumulatedMs = 0;
phrases.forEach((phrase, i) => {
const ratio = phrase.length / totalChars;
let durationMs = i === phrases.length - 1
? totalMs - accumulatedMs
: Math.round(totalMs * ratio);
processedSubtitles.push(phrase);
processedSubtitleDurations.push(durationMs / 1000);
accumulatedMs += durationMs;
});
});
// 生成时间轴(保持不变)
const textTimelines = [];
let currentTime = 0;
processedSubtitleDurations.forEach(duration => {
const preciseStart = currentTime;
const preciseEnd = preciseStart + duration;
textTimelines.push({
start: Number(preciseStart.toFixed(SUB_CONFIG.TIME_PRECISION)),
end: Number(preciseEnd.toFixed(SUB_CONFIG.TIME_PRECISION))
});
currentTime = preciseEnd;
});
return { textTimelines, processedSubtitles };
};
/*
* 入场动画预设池(单轨道版)
* 结构:模式名 -> 轨道位置 -> 可选的动画类型数组
*/
const ANIMATION_PRESETS = {
// 顺序模式预设
SEQUENCE: {
left: ["向上滑动", "放大"]
},
// 聚焦模式预设
FOCUS: {
left: ["放大", "向上滑动"]
},
// 对称模式预设(调整为单侧配置)
SYMMETRIC: {
left: ["向右滑动", "放大"]
},
// 随机模式预设
RANDOM: {
left: ["向右滑动", "放大", "向下滑动","向左转入"]
}
};
/*
* 动画模式枚举
*/
const ANIMATION_MODES = {
SEQUENTIAL: 'sequential', // 顺序模式
FOCUS: 'focus', // 聚焦模式
SYMMETRIC: 'symmetric', // 对称模式(单侧实现)
RANDOM: 'random'
};
/*
* 全局配置参数(单轨道版本)
*/
const CONFIG = {
mode: ANIMATION_MODES.SEQUENTIAL,
animationPreset: 'SEQUENCE',
trackWeights: { left: 2 }, // 移除右轨道权重
overlapTolerance: 1,
groupSyncThreshold: 2,
sequentialOrder: ['left'], // 仅保留左轨道
durationSettings: {
unit: 1,
baseExtension: 500000,
minDuration: 1000000,
groupRatio: 1.5
}
};
// 单轨道处理器
class AnimationScheduler {
constructor() {
this.tracks = { left: [] }; // 仅保留左轨道
this.timeWindows = [];
this.groups = [];
this.currentGroup = null;
}
process(imageList, durationList) {
imageList.forEach((img, idx) => {
this._processImage(img, idx, durationList);
});
this._postProcess();
return this._formatOutput();
}
_processImage(image, index, durations) {
const start = this._getStartTime(index, durations);
const originalDuration = durations[index] * CONFIG.durationSettings.unit;
this._createGroupIfNeeded(index);
const { endTime } = this._calculateTiming(start, originalDuration);
const animation = this._selectAnimation();
const item = this._createItem(image, start, endTime, animation);
this._updateState(item, endTime);
}
_createGroupIfNeeded(index) {
let shouldCreate = false;
// 简化分组逻辑
if (CONFIG.mode === ANIMATION_MODES.SEQUENTIAL) {
shouldCreate = index % CONFIG.groupSyncThreshold === 0;
} else {
shouldCreate = index % 2 === 0 || this.groups.length === 0;
}
if (shouldCreate) {
this.currentGroup = {
items: [],
animationType: this._getGroupAnimationType(),
endTime: 0
};
this.groups.push(this.currentGroup);
}
}
_getGroupAnimationType() {
const preset = ANIMATION_PRESETS[CONFIG.animationPreset];
switch(CONFIG.mode) {
case ANIMATION_MODES.RANDOM:
return { left: this._randomPick(preset.left) };
default:
return { left: this._randomPick(preset.left) };
}
}
_calculateTiming(start, originalDuration) {
const baseEnd = start + originalDuration;
let endTime = baseEnd + CONFIG.durationSettings.baseExtension;
if (this.currentGroup.items.length > 0) {
endTime = Math.max(endTime, this.currentGroup.endTime);
}
endTime = Math.max(
endTime,
start + CONFIG.durationSettings.minDuration
);
this.currentGroup.endTime = endTime;
return { endTime };
}
_createItem(image, start, end, animation) {
return {
image_url: image,
in_animation: animation,
start: start,
end: end,
width: 1920,
height: 1080,
track: 'left' // 固定为左轨道
};
}
_selectAnimation() {
return this.currentGroup.animationType.left;
}
_updateState(item, groupEnd) {
this.tracks.left.push(item);
this.currentGroup.items.push(item);
this.currentGroup.items.forEach(i => i.end = groupEnd);
}
_postProcess() {
this._adjustTrackOverlaps();
}
_adjustTrackOverlaps() {
this.tracks.left.sort((a, b) => a.start - b.start);
for (let i = 1; i < this.tracks.left.length; i++) {
const prev = this.tracks.left[i - 1];
const curr = this.tracks.left[i];
if (prev.end > curr.start) {
const adjust = (prev.end - curr.start) * CONFIG.overlapTolerance;
prev.end -= adjust;
curr.start = prev.end;
}
}
}
_getStartTime(index, durations) {
return index === 0 ? 0 : durations
.slice(0, index)
.reduce((sum, dur) => sum + dur * CONFIG.durationSettings.unit, 0);
}
_formatOutput() {
return this.tracks.left.map(item => ({
image_url: item.image_url,
//in_animation: item.in_animation,
start: item.start,
end: item.end,
width: item.width,
height: item.height
}));
}
_randomPick(arr) {
return arr[Math.floor(Math.random() * arr.length)];
}
}
function configure(options) {
Object.assign(CONFIG, options);
}
function assembleResults(keywords_new, processedSubtitles, textTimelines) {
const result = [];
for (let i = 0; i < processedSubtitles.length; i++) {
const text = processedSubtitles[i];
const { start, end } = textTimelines[i];
let matchedKeywords = [];
// 遍历所有关键词进行匹配检查
for (const keyword of keywords_new) {
if (text.includes(keyword)) {
matchedKeywords.push(keyword);
}
}
// 去重并生成结果对象
if (matchedKeywords.length > 0) {
const uniqueKeywords = [...new Set(matchedKeywords)];
result.push({
start,
end,
text,
keyword: uniqueKeywords.join('|'), // 多个关键词用逗号分隔
keyword_color: "#fe8a80", // #ff7100
keyword_font_size: 10,
font_size: 7
});
} else {
result.push({
start,
end,
text
});
}
}
return result;
}
/* 使用示例
const finalResult = assembleResults(
["关键词1", "关键词2"], // keywords_new
["字幕1", "包含关键词2的字幕"], // processedSubtitles
[{start:0,end:100}, {start:101,end:200}] // textTimelines
);
*/9.插入插件剪映小助手数据生成器的audio_infos
👍
输入变量mp3_urls引用循环的output
输入变量timelines引用代码的timelines
volume设置2
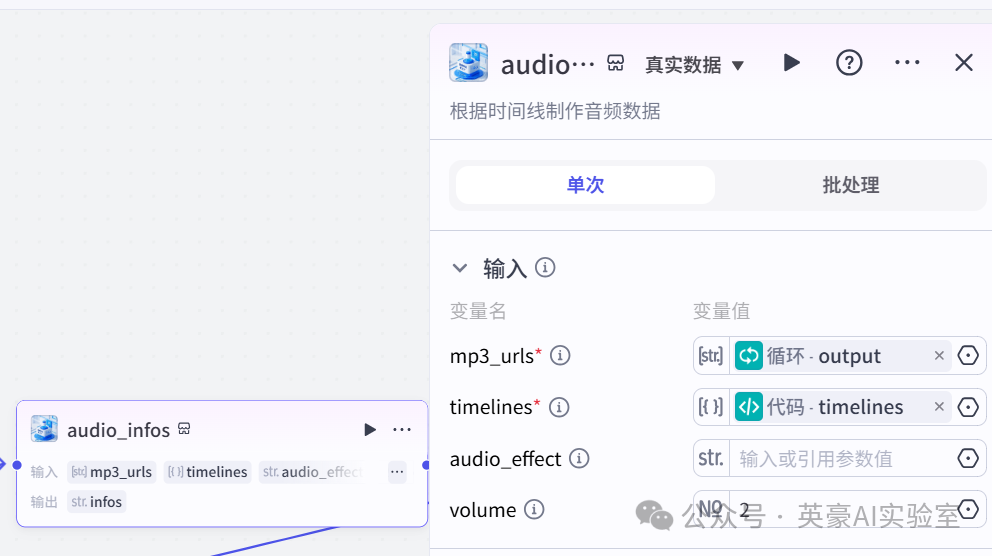
10.插入插件剪映小助手数据生成器的caption_infos
📚
texts引用代码的text_cap
timelines引用代码的timelines
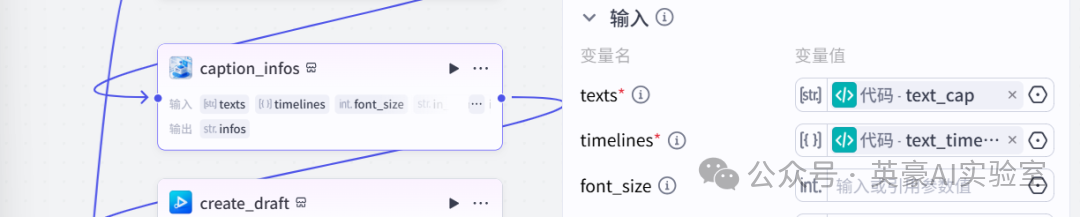
11.插入插件视频合成_剪映小助手的create_draft
📌
设置变量height为1080
设置变量width为1440
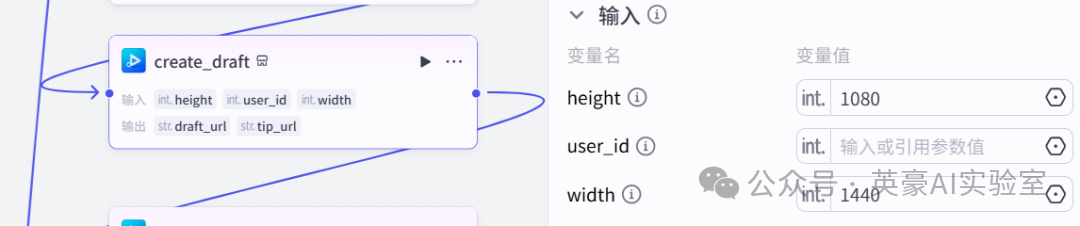
12.插入插件视频合成_剪映小助手的add_audios
💡
变量audio_infos引用audio_infos.infos
变量draft_url引用create_draft.url
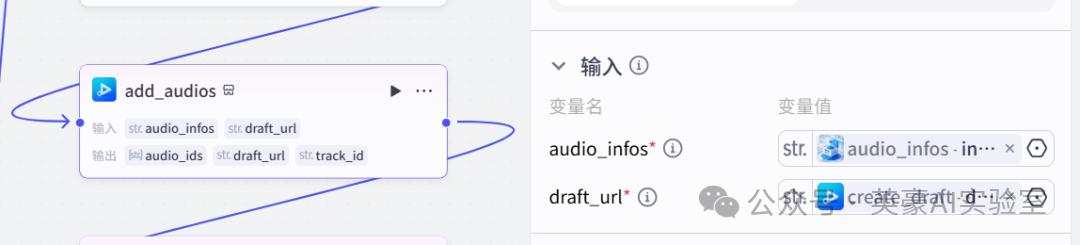
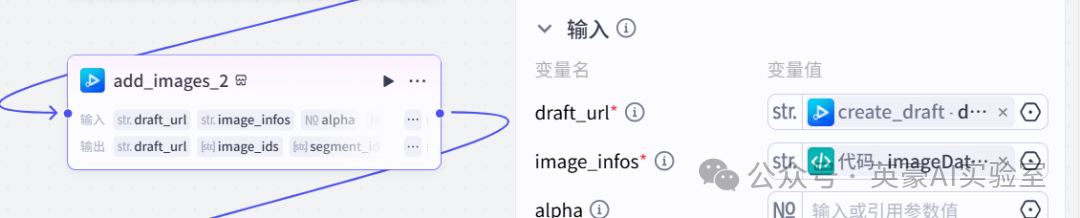
13.插入插件视频合成_剪映小助手的add_images重命名为add_images_2
变量draft_url引用create_draft.url
变量image_infos引用代码的imageDateLeft
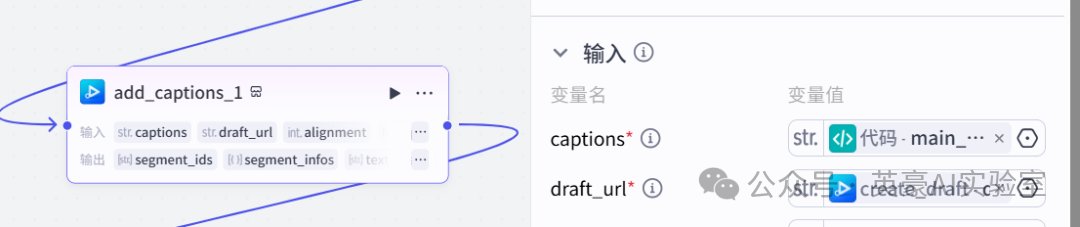
14.插入插件视频合成_剪映小助手的add_captions重命名为add_captions_1
👍
变量captions引用代码的main_text
变量draft_url引用create_draft.url
15.插入代码节点重命名为代码_3
设置输入变量segment_ids,引用add_images_2的segment_ids
设置输入变量duration_list,引用循环的duration_list
设置输出变量keyFrames,变量类型String
别忘了加入python代码
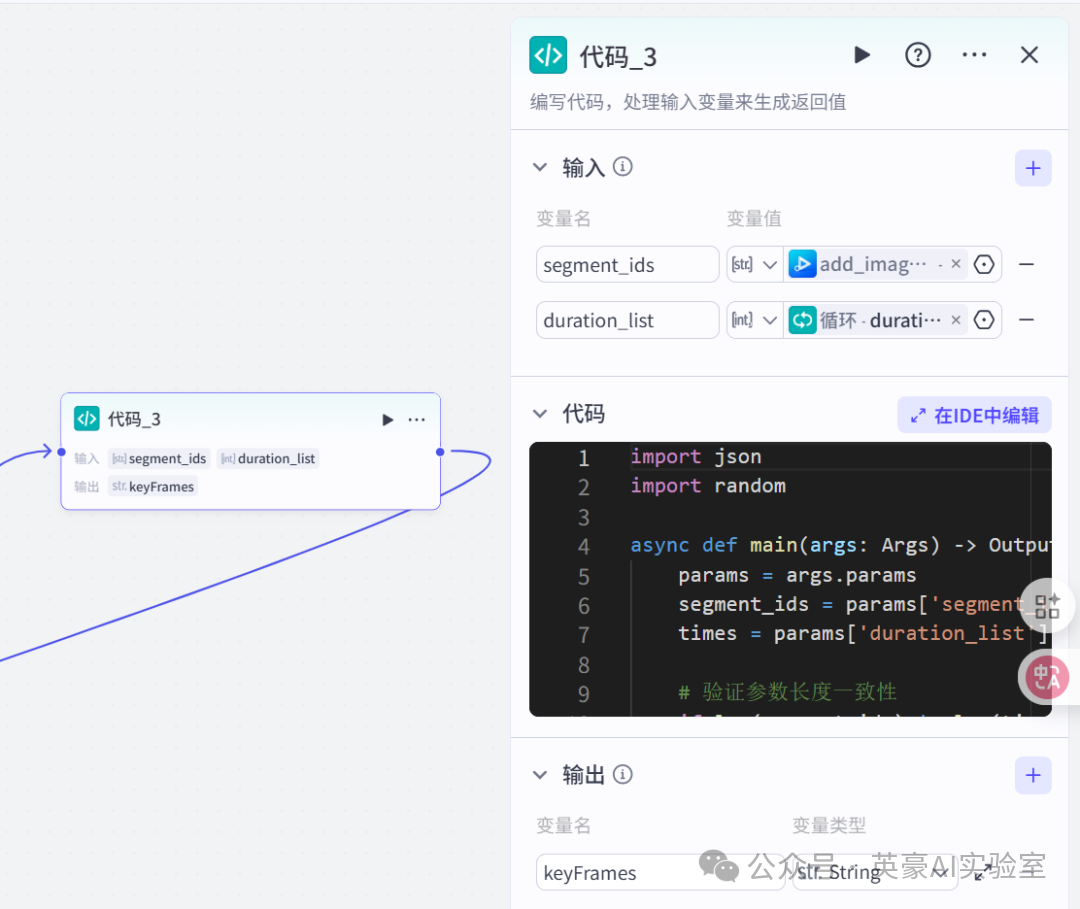
import json
import random
async def main(args: Args) -> Output:
params = args.params
segment_ids = params['segment_ids']
times = params['duration_list']
# 验证参数长度一致性
if len(segment_ids) != len(times):
raise ValueError("segment_ids与times数组长度不一致")
# 可选的动画属性列表
properties = [
"UNIFORM_SCALE" # 缩放
# "KFTypePositionX", # X轴位移
# "KFTypePositionY" # Y轴位移
]
keyframes = []
# 固定动画参数
start_scale = 1.0
end_scale = 1.2
for idx, seg_id in enumerate(segment_ids):
# 获取对应音频时长并转换微秒
audio_duration = int(float(times[idx]) ) # 假设输入单位为秒
# 随机选择一个动画属性
prop = random.choice(properties)
# 起始关键帧(0秒位置)
keyframes.append({
"offset": 0,
"property": prop,
"segment_id": seg_id,
"value": start_scale,
"easing": "linear"
})
# 结束关键帧(同步音频时长)
keyframes.append({
"offset": audio_duration, # 使用实际音频时长
"property": prop,
"segment_id": seg_id,
"value": end_scale,
"easing": "linear"
})
return {
"keyFrames": json.dumps(keyframes)
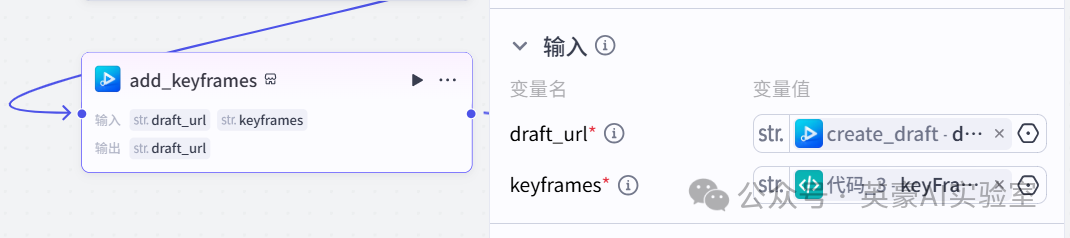
}16.插入插件视频合成_剪映小助手的add_keyframes
输入变量draft_url引用create_draft.draft_url
输入变量keyframes引用代码_3.keyFrames
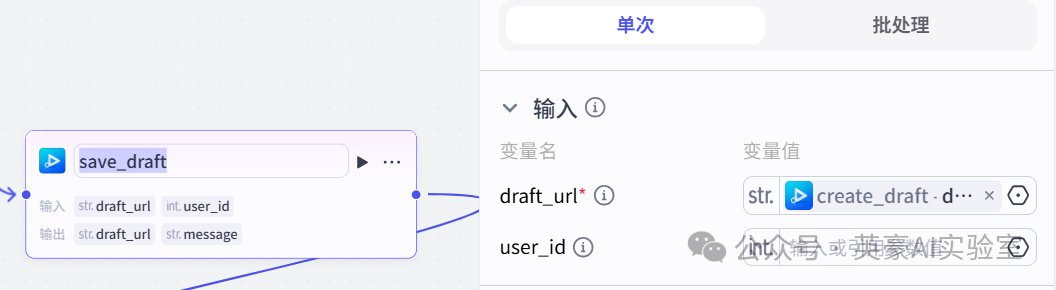
17.插入插件视频合成_剪映小助手的save_draft
输入变量draft_url引用create_draft.draft_url
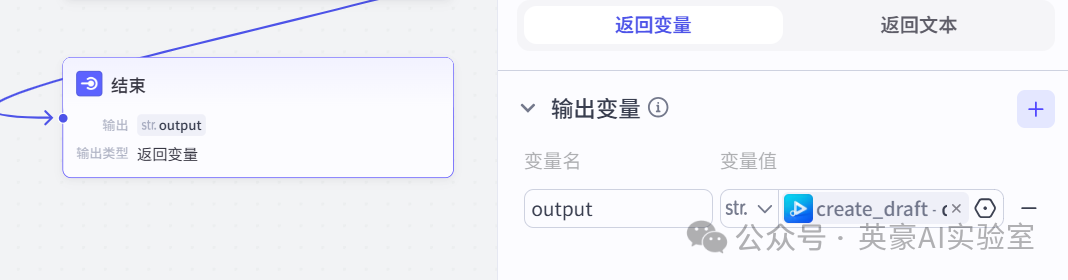
18.链接结束节点
✏️
设置输出变量putput,引用create_draft.draft_url
四、试运行看结果
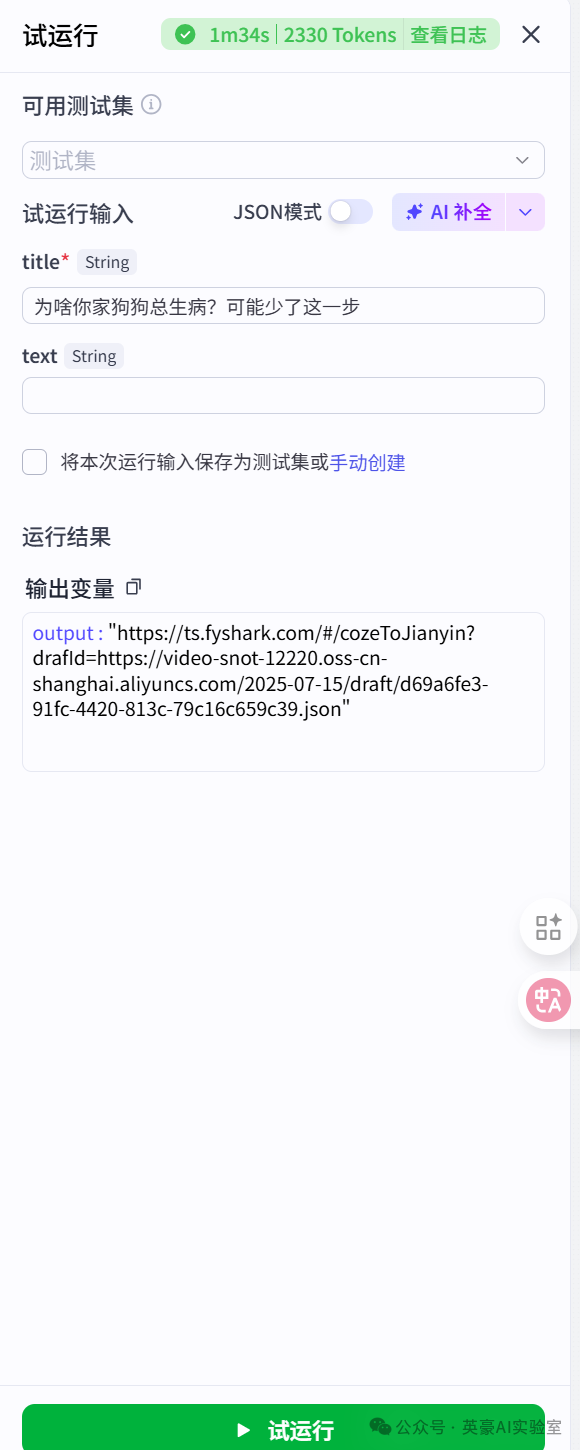
复制网址到剪映小助手转换成剪映草稿,就可以在剪映中打开
恭喜你!跟到这里,你已经拥有了一个短视频自动化生产的强大AI助手。但更重要的是,你已搭建起一套 “思维→成果” 的自动化工作流
这套方法不仅可以用来做知识科普,还能做教学视频、短视频自动化生产...等等。学会Coze,你拥有的不只是一个工具,而是一个能帮你实现各种想法的‘AI梦工厂’。
“你学会了吗?快去动手试试吧!
五、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献282条内容
已为社区贡献282条内容

所有评论(0)